一种基于机器学习的岩土材料离散元自动建模方法
本发明涉及离散元建模技术领域,主要涉及一种基于机器学习的岩土材料离散元自动建模方法。
背景技术:
岩土体在宏观上相对连续,而在微观上是由一系列颗粒、孔隙和裂隙组成的系统结构。离散元法通过堆积和胶结颗粒来构建模型,能够天然地模拟岩土体的非连续性和不均匀性,为探索岩土体宏观力学性质的微观机制提供了一个有效的方法。离散元堆积模型的力学性质受颗粒性质、堆积过程和胶结情况等多种因素的共同作用,通常无法直接得到指定力学性质的离散元模型。目前获取特定力学性质模型的方法主要有两类,第一类为试错法,通常依赖于繁琐的参数调整和力学性质测试操作,使得离散元模型的宏观力学响应达到理想状态或与室内试验结果一致。第二类为经验公式法,由基于模拟或者试验结果,统计分析宏观力学性质和微观参数的相互关系。如何快速准确建立具有特定力学性质的岩土材料模型仍是急需解决的问题。
技术实现要素:
发明目的:为了解决上述背景技术中存在的问题,本发明提供了一种基于机器学习的岩土材料离散元自动建模方法。通过对实际力学性质进行数值实验、训练、验证和测试操作,实现具有特定力学性质岩土材料快速建模。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于机器学习的岩土材料离散元自动建模方法,包括以下步骤:
步骤s1、基于线弹性接触理论建立岩石离散元模型,所述模型包括依次堆叠的上压力板、试样和下压力板;通过重力沉积过程建立紧密堆积模型;
步骤s2、对所述紧密堆积模型赋予砂岩的宏观力学性质,并且根据转换公式和力学性质扩大比例系数计算对应的微观力学参数,自动赋予每个单元;平衡模型,并且通过数值模拟试验获取模型的输入力学性质;
步骤s3、基于步骤s2中数值模拟试验步骤,建立一定数量的岩石离散元模型;所述岩石离散元模型的尺寸粒径均相同;对每个岩石离散元模型赋予不同的宏观力学性质,依次经数值模拟试验后得到相应的输入力学性质,最终生成相应数量的样本,作为训练样本数据集;
步骤s4、将输入力学性质作为特征,实际力学性质作为标签数据,采用皮尔逊相关系数在样本数据训练前对特征和标签数据进行初步相关性分析,计算输入力学性质和实际力学性质间的相关系数;
步骤s5、对收集的样本数据集进行处理,采用xgboost算法进行训练,建立输入力学性质与实际力学性质之间的定量关系,获取训练好的xgboost模型;
步骤s6、采用皮尔逊相关系数对训练结果所得特征和标签数据进行相关性分析,并与训练前的相关系数进行对比,获取训练的数据集样本量对训练结果的影响,发现随着训练样本数量的增加,平均误差和误差标准差逐渐下降,预测精度越来越高,训练结果越来越稳定。;
步骤s7、根据训练完成的xgboost训练模型进行自动建模,获取最终的离散元模型。
进一步地,所述步骤s2中通过数值模拟试验获取模型的输入力学性质具体步骤包括:
步骤s2.1、对所述紧密堆积模型进行第一次单轴压缩试验,通过应力应变曲线计算得到杨氏模量e;通过监测压缩过程中模型竖向压缩量和侧向膨胀量计算得到模型的泊松比ν;
步骤s2.2、对所述岩石离散元模型进行第二次单轴压缩试验,测试岩石离散元模型单轴抗压强度,通过峰值应力得到岩石离散元模型的单轴抗压强度cu;
步骤s2.3、对所述岩石离散元模型进行单轴拉伸试验,测试岩石离散元模型单轴抗拉强度tu;
步骤s2.4、通过紧密堆积模型的质量除以体积获取岩石密度ρ;内摩擦系数μi的输入值和实际值相同。
进一步地,所述步骤s5中具体训练流程包括:
步骤s5.1、加载步骤s3中生成的训练样本数据集,所述训练样本数据集包含特征和标签数据,实际杨氏模量、泊松比、抗拉强度和抗压强度4个标签分别与输入的杨氏模量、泊松比、抗拉强度和抗压强度4个特征相对应,每行为一条样本;
步骤s5.2、分别对特征和标签数据进行0~1归一化处理;将归一化处理后的样本数据集按行进行随机分割,选取其中10%的行作为测试集,10%的行作为验证集,80%作为训练集;加载xgboost训练模型,针对泊松比、杨氏模量、抗压强度、抗拉强度进行训练;
步骤s5.3、使用均方根损失函数进行训练中评价;当验证集误差连续10次训练没有下降时,训练结束;判断训练误差是否收敛于预设阈值;当误差不收敛于预设阈值时,重新选取算法参数n_estimators、max_depth和learning_rate,并返回步骤s5.2进行训练;当误差收敛于预设阈值时,获得训练好的xgboost模型。
进一步地,所述步骤s7中获取最终离散元模型的具体步骤包括:
步骤s7.1、加载训练程序;
步骤s7.2、输入目标离散元模型的实际力学性质,包括杨氏模量,泊松比,抗拉强度和抗压强度;
步骤s7.3、将实际力学性质赋给中间变量;对杨氏模量、泊松比、抗拉强度和抗压强度进行预测,内摩擦系数和密度保持不变,得到预测力学性质;
步骤s7.4、当预测力学性质与实际力学性质相差大于预设的收敛阈值时,通过设定准则更新中间变量的值,并重新预测,直至预测力学性质与实际力学性质相差小于等于预设收敛阈值;
步骤s7.5、获取岩石离散元模型的输入力学性质;在建模时输入该数据,即可得到目标力学性质的离散元模型。
有益效果:
本发明提供了一种基于机器学习的岩土材料离散元自动建模方法,借助机器学习算法强大的数据挖掘能力,探究岩石样本实际力学性质和数值模型输入力学性质间的定量关系。提出一种基于机器学习算法的岩土材料离散元建模方法,通过对实际力学性质进行数值实验、训练、验证和测试操作,实现具有特定力学性质岩土材料快速建模。
附图说明
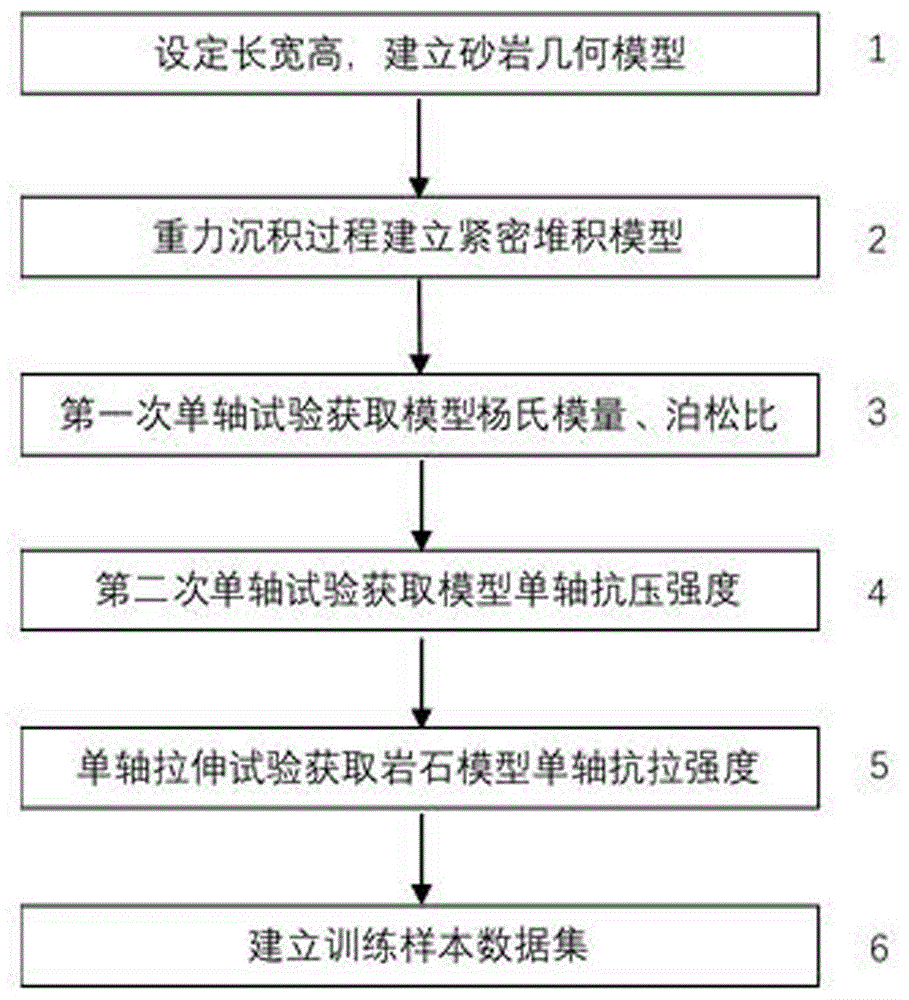
图1是本发明提供的建立训练样本数据集的流程图;
图2是本发明提供的xgboost训练模型训练过程示意图;
图3是本发明提供的自动建模流程示意图;
图4是本发明提供的岩石离散元模型及粒径分布示意图;
图5是本发明实施例中训练前输入力学性质与实际力学性质相关系数示意图;
图6是本发明实施例中预测结果输入力学性质与实际力学性质相关系数示意图;
图7是本发明训练样本误差随样本数量变化情况示意图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
一种基于机器学习的岩土材料离散元自动建模方法,包括以下步骤:
步骤s1、通过matdem软件基于线弹性接触理论建立岩石离散元模型。模型为长50mm,宽50mm,高120mm的长方体。所述模型包括依次堆叠的上压力板topplaten、试样sample和下压力板botplaten。对模型施加随机的速度和重力,进而模拟重力沉积过程建立紧密堆积模型;通过重力沉积过程建立紧密堆积模型。
步骤s2、对所述紧密堆积模型赋予砂岩的宏观力学性质,并且根据转换公式和力学性质扩大比例系数计算对应的微观力学参数,自动赋予每个单元;平衡模型,并且通过数值模拟试验获取模型的输入力学性质。具体地,
步骤s2.1、对所述紧密堆积模型进行第一次单轴压缩试验,通过应力应变曲线计算得到杨氏模量e;通过监测压缩过程中模型竖向压缩量和侧向膨胀量计算得到模型的泊松比ν;
步骤s2.2、对所述岩石离散元模型进行第二次单轴压缩试验,测试岩石离散元模型单轴抗压强度,通过峰值应力得到岩石离散元模型的单轴抗压强度cu;
步骤s2.3、对所述岩石离散元模型进行单轴拉伸试验,测试岩石离散元模型单轴抗拉强度tu;
步骤s2.4、通过紧密堆积模型的质量除以体积获取岩石密度ρ;内摩擦系数μi的输入值和实际值相同。
步骤s3、基于步骤s2中数值模拟试验步骤,建立一定数量的岩石离散元模型;所述岩石离散元模型的尺寸粒径均相同;对每个岩石离散元模型赋予不同的宏观力学性质,依次经数值模拟试验后得到相应的输入力学性质,最终生成相应数量的样本,作为训练样本数据集;
在本实施例中,建立12000个岩石离散元模型,组成训练样本集。每个模型的尺寸粒径均相同,将每个模型赋予不同的宏观力学性质,杨氏模量分布在0.1-402gpa之间;泊松比分布在0.01-0.2之间;抗拉强度分布在0.11-206mpa之间;抗压强度分布在27-1456mpa之间;内摩擦系数分布在0.3-2之间;密度分布在1750-2934kg/m3之间。
步骤s4、将输入力学性质作为特征,实际力学性质作为标签数据,采用皮尔逊相关系数在样本数据训练前对特征和标签数据进行初步相关性分析,计算输入力学性质和实际力学性质间的相关系数。
本实施例中采用皮尔逊相关系数表示两个变量之间的线性相关程度具体如下表示:
其中x,y表示两变量,cov为协方差,var为方差。r的取值为[-1,1],小于0表示负相关,大于0表示正相关,越接近于0相关性越小。根据上式计算输入力学性质和实际力学性质间的相关系数,并绘制了表示相关性的散点图,如图5所示,可见实际杨氏模量、泊松比、抗拉强度和抗压强度与输入杨氏模量、泊松比、抗拉强度和抗压强度的相关系数分别为0.76、0.9、0.91和0.94,表现出较好正相关。
步骤s5、对收集的样本数据集进行处理,采用xgboost算法进行训练,建立输入力学性质与实际力学性质之间的定量关系,获取训练好的xgboost模型。具体训练过程如图2所示:
步骤s5.1、加载步骤s3中生成的训练样本数据集,所述训练样本数据集包含特征和标签数据,实际杨氏模量、泊松比、抗拉强度和抗压强度4个标签分别与输入的杨氏模量、泊松比、抗拉强度和抗压强度4个特征相对应,每行为一条样本;
步骤s5.2、分别对特征和标签数据进行0~1归一化处理;将归一化处理后的样本数据集按行进行随机分割,选取其中10%的行作为测试集,10%的行作为验证集,80%作为训练集;加载xgboost训练模型,针对泊松比、杨氏模量、抗压强度、抗拉强度进行训练;
步骤s5.3、使用均方根损失函数进行训练中评价;当验证集误差连续10次训练没有下降时,训练结束;判断训练误差是否收敛于预设阈值;当误差不收敛预设阈值时,重新选取算法参数n_estimators、max_depth和learning_rate,并返回步骤s5.2进行训练;当误差收敛于预设阈值时,获得训练好的xgboost模型。
本实施例中,设定收敛阈值4%,判断训练结束时训练误差是否收敛于设定阈值,若不收敛,返回步骤11,重新选取合适的xgboost参数并训练。若收敛即得到训练好的xgboost模型;
步骤s6、对训练结果所得特征和标签数据进行相关性分析,并与训练前的相关系数进行对比,并探究训练的数据集样本量对训练结果的影响,发现随着训练样本数量的增加,平均误差和误差标准差逐渐下降,预测精度越来越高,训练结果越来越稳定,验证机器学习算法对于建模准确性的提升。
在模型训练后所得特征和标签数据进行相关性分析,得到如图6所示的相关性散点图。与图5中训练前输入力学性质和实际力学性质间的相关系数作比较,发现图6中预测值均沿y=x分布,经训练后4组预测值与实际值的相关系数r均等于0.99,表现出极高的正相关性,证明机器学习xgboost算法在离散元建模中的有效性,说明该方法可以准确建立确定力学性质的岩石离散元模型。
模型训练后得到如下表1所示的实际抗压强度、抗拉强度、泊松比和杨氏模量的测试集预测的结果。用平均误差表示总体的精准程度,误差标准差表示预测数据的分布状况。
表1实际力学性质预测误差
4组力学性质预测值平均误差均小于设定收敛阈值,误差分布足够稳定,平均误差均小于4%,误差标准差均小于10%。泊松比与抗压强度平均误差小于2%,误差标准差小于5%。实际抗压强度预测平均误差最小,泊松比的预测结果最稳定,实际抗拉强度预测误差最大。在保证建模精度的情况下极大地提高了离散元建模效率,避免繁琐的调参过程,证明了xgboost算法在离散元建模中的有效性,使用机器学习方法可以快速准确地建立具有特定力学性质的岩石离散元模型。
在机器学习过程中,训练的数据集样本量对训练结果有明显的影响,在模型训练过程中对不同数据量的数据集进行训练,同样抽取其中10%作为测试集,10%作为验证集,其余80%作为训练集,按照相同步骤进行训练,得到测试集误差随样本数量变化结果,图7为训练误差随样本数量变化情况。当样本数大于10000条时,对于4组力学性质的平均训练误差均小于7%。样本数在12000条平均训练误差均小于4%。可见随着训练样本数量的增加,平均误差和误差标准差逐渐下降,预测精度越来越高,训练结果越来越稳定。
步骤s7、根据训练完成的xgboost训练模型进行自动建模,获取最终的离散元模型。具体如图3所示:
步骤s7.1、加载训练程序。
本发明提供一种实施例,使用python语言和numpy、xgboost、sklearn算法包编写训练程序。具体参数如下:
(1)普通参数:
booster:基本模型的选择,有线性模型(gblinear)和树模型(gbtree)两种选择,默认为gbtree。
silent:控制训练过程的输出,为0时不输出,为1时输出训练过程,默认为0。
nthread:控制线程数,默认使用全部cpu进行计算。
num_feature:训练过程中用到的特征个数,默认选择全部特征。
(2)模型参数:
n_estimatores:决策树的数量,即基本分类器的个数。
early_stopping_rounds:当验证集的误差连续t次计算没有减小时认为训练完成,提前结束训练,可以防止过拟合。
max_depth:决策树的最大深度,深度越大,模型越复杂,越容易过拟合,默认深度为6。
min_child_weight:叶子结点的最小权重,可以避免模型陷入局部最优解,默认为1。
subsample:对每个特征进行抽样的比例,每次随机抽取部分特征数据,可以防止过拟合,默认值为1。
colsample_bytre:训练时使用特征的比例,可以防止过拟合,默认为1。
(3)学习参数:
learning_rate:学习率,控制每次迭代计算时权重更新的步长,值越小计算越慢,最优解越精确;值越大计算越快,默认为0.3。
objective:训练任务的目标函数,包括回归训练reg:linear、reg:logistic,二分类训练binary:logistic和多分类训练multi:softmax等。
eval_metric:训练测评函数,回归问题中常用均方根误差(rmes),分类任务常用曲线下面积(auc--roc)。
gamma:惩罚系数,当损失函数下降值大于gamma时进行分裂。
alpha:l1正则化系数,默认为1。
lambda:l2正则化系数,默认为1。
步骤s7.2、输入目标离散元模型的实际力学性质,包括杨氏模量,泊松比,抗拉强度和抗压强度;
步骤s7.3、将实际力学性质赋给中间变量;对杨氏模量、泊松比、抗拉强度和抗压强度进行预测,内摩擦系数和密度保持不变,得到预测力学性质;
步骤s7.4、当预测力学性质与实际力学性质相差大于预设的收敛阈值时,通过设定准则更新中间变量的值,并重新预测,直至预测力学性质与实际力学性质相差小于等于预设收敛阈值;
步骤s7.5、获取模型的输入力学性质;在建模时输入该数据,即可得到目标力学性质的离散元模型。
在本实施例中,输入目标离散元模型的实际力学性质t0,即杨氏模量,泊松比,抗拉强度,抗压强度;将实际力学性质赋给中间变量t,t为最终得到的需要输入模型的宏观力学性质。加载训练好的xgboost模型,分别对杨氏模量、泊松比、抗拉强度和抗压强度进行预测,得到预测的实际力学性质t1;判断预测力学性质是否收敛,预测的力学性质与实际力学性质相差大于设定收敛阈值时,通过准则t=(t0/t1)×t0更新t的值,继续预测,直至收敛为止;收敛后输出t,得到模型的输入力学性质t,即对离散元模型输入t,可以得到实际力学性质为t0的离散元模型。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!