基于通道注意力导向时间建模的视频行为识别方法及系统
1.本发明涉及视频行为识别技术领域,尤其涉及一种基于通道注意力导向时间建模的视频行为识别方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.视频行为识别作为计算机视觉的一个重要研究领域,由于其在视频监控、视频理解、人体行为分析等方面的广泛应用,近年来受到了越来越多的关注。与仅利用空间信息的基于图像的视觉任务相比,时间结构建模对于视频行为识别至关重要,因为视频数据是高维的,单张图像不足以表达整个行为的信息。因此,视频行为识别高度依赖于有效的空间和时间特征学习,其中空间特征描述视频中的视觉外观和场景配置信息,而时间特征捕获人体随时间变化的运动动态。
4.随着深度学习在图像分类方面取得的巨大成功,深度卷积神经网络(cnns)已被广泛应用于视频识别任务,并逐渐成为主流方法。视频行为识别的一个重大挑战是时域建模。传统2d cnn是视频行为识别的常用骨干网络,但它只能提取视频的空间信息,不能直接学习视频帧之间的时间关系。因此,许多基于2dcnn的方法都是单独学习视频中的时间结构,最后通过结合空间和时间线索来识别动作。其中最典型的结构是双流cnn,它从rgb图像中提取外观信息,从堆叠光流中提取运动信息,分别进行空间和时间特征的学习。但是光流计算耗时长,且需要足够大的存储空间。另一种具有代表性的视频行为识别方法是cnn+rnn网络结构,cnn用于从图像帧中提取空间特征,rnn用于学习高级卷积特征中的时间关系。
5.基于3dcnn的方法通过在时间维度上扩展2d卷积核,可以对空间和时间特征进行联合编码。它们在视频行为识别方面取得了很好的效果,但同时也带来了大量的模型参数,导致繁重的计算负担。因此,现有技术提出将3d卷积核分解为2d空间核和1d时间核来解决这个问题,然而,由于1d卷积的使用,这些方法仍然存在计算量大的问题。
6.总的来说,虽然行为识别已经取得了很大的进展,但是如何高效灵活地对视频中复杂的时间结构进行建模仍然是一个关键的技术问题。
技术实现要素:
7.为了解决上述问题,本发明提出了一种基于通道注意力导向残差时间建模的视频行为识别方法及系统,能够在注意力机制的指导下学习关键特征通道的时间信息,从而实现高效的行为识别。
8.在一些实施方式中,采用如下技术方案:
9.一种基于通道注意力导向时间建模的视频行为识别方法,包括:
10.获取输入行为视频的卷积特征图;
11.生成通道注意力权值,并对输入视频卷积特征图进行调整;
12.选择注意力权值高于设定值的特征通道进行残差时间建模,计算相邻帧在这些通道中空间特征的残差来建立它们之间的时间相关性模型,通过捕捉人体动作随时间变化的运动动态来学习视频的时间关系,进而得到更具辨识力的视频特征表示;
13.基于得到的特征表示进行视频行为识别。
14.作为进一步的方案,生成通道注意力权值,并对输入视频卷积特征图进行调整,具体过程包括:
15.给定输入视频的卷积特征图;
16.对每个特征通道中t帧特征图的空间信息进行时间聚合;
17.在时间聚合后的视频特征图上应用全局空间平均池化来压缩空间信息以获得通道描述子;
18.基于所述通道描述子,进行通道注意力计算,得到视频级的通道注意力得分,作为不同特征通道的权重;
19.基于所述权重对原始输入卷积特征图进行调整,得到通道注意力校准后的视频卷积特征图。
20.作为进一步的方案,选择注意力权值高于设定值的特征通道进行残差时间建模,具体过程包括:
21.将特征通道的注意力得分按照从高到低的顺序进行通道重要性排序;
22.将校准后的视频卷积特征图沿着排序后的通道维度分成高注意力得分通道组和低注意力得分通道组;
23.仅对高注意力得分通道组进行残差时间建模,通过捕捉人体动作随时间变化的运动动态来学习视频时间依赖性,进而生成更具辨识力的特征表示;对于低得分通道组不作处理以保留静态场景空间信息。
24.作为进一步的方案,对于高注意力得分通道组,通过计算相邻帧空间特征图的差值来建立它们之间的时间关系模型。
25.作为进一步的方案,对于高注意力得分通道组,同时使用前向和后向残差时间建模,以赋予当前帧更丰富的时空信息;
26.将t时刻前向时间建模和后向时间建模分别获得的特征图沿通道维度进行级联操作,得到t时刻的运动特征;
27.将所有帧的运动特征沿时间轴级联,构造高得分通道组双向时间建模的输出张量;所述输出张量与高得分通道组原始输入特征图进行残差连接,得到高注意力得分通道组应用双向残差时间建模后输出的卷积特征;
28.所述卷积特征与低得分通道组的卷积特征沿通道维度进行组合,得到通道注意力导向残差时间建模调整后的视频特征表示。
29.作为进一步的方案,为了保持时间尺度不变,对于前向时间建模,将最后时刻的特征设为零;对于后向时间建模,将初始时刻的特征设为零。
30.在另一些实施方式中,采用如下技术方案:
31.一种基于通道注意力导向时间建模的视频行为识别系统,包括:
32.数据获取模块,用于获取输入行为视频的卷积特征图;
33.通道注意力生成(channel attention generation,cag)模块,用于获取通道权
值,并对原始输入视频卷积特征图进行调整;
34.残差时间建模(residual temporal modeling,rtm)模块,用于选择注意力权值高于设定值的特征通道进行残差时间建模,计算相邻帧在这些通道中空间特征的残差来建立它们之间的时间相关性模型,通过捕捉人体动作随时间变化的运动动态来学习视频的时间关系,进而得到更具辨识力的视频特征表示;
35.视频行为识别模块,用于基于得到的特征表示进行视频行为识别。
36.作为进一步的方案,所述通道注意力生成模块和残差时间建模模块共同构成通道注意力导向残差时间建模(channel attention
‑
guided residual temporal modeling,cartm)模块;
37.将所述通道注意力导向残差时间建模模块嵌入到任一2d网络中构建cartm网络,使其具备时间建模的能力;
38.基于所述cartm网络来进行视频行为识别。
39.在另一些实施方式中,采用如下技术方案:
40.一种终端设备,其包括处理器和存储器,处理器用于实现各指令;存储器用于存储多条指令,所述指令适于由处理器加载并执行上述的基于通道注意力导向时间建模的视频行为识别方法。
41.与现有技术相比,本发明的有益效果是:
42.本发明提出了一种新的视频级通道注意力方法,以区分不同特征通道的学习能力,通过对生成的通道注意力得分进行排序,使用关键特征通道来引导残差时间建模模块(rtm)的时序建模。
43.本发明提出了残差时间建模模块(rtm),采用双向时间建模,通过捕获视频序列中相邻帧空间特征的差异来建模时间依赖性。
44.本发明提出的通道注意力导向残差时间建模模块(cartm)在通道注意力的引导下基于视频特征图选择性地建模时间关系,可以灵活地被嵌入到现有的2d网络架构中赋予其时间建模的能力。
45.本发明在四个数据集上进行了大量丰富的实验来评估cartm网络,结果表明,所提方法在时间相关的ntu rgb+d数据集上取得了优越的识别性能,在其余三个场景相关的行为数据集上也取得了具有竞争力的识别结果,证明了所提方法的有效性。
46.本发明的其他特征和附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本方面的实践了解到。
附图说明
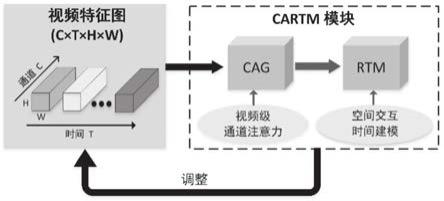
47.图1为本发明实施例中基于通道注意力导向时间建模的视频行为识别方法示意图;
48.图2为本发明实施例中通道注意力导向残差时间建模模块工作过程示意图;
49.图3为本发明实施例中cartm网络的总体架构示意图;
50.图4为本发明实施例中输入cartm模块前后的特征图可视化示意图。
具体实施方式
51.应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本发明使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
52.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
53.实施例一
54.在一个或多个实施方式中,公开了一种基于通道注意力导向时间建模的视频行为识别方法,参照图1,包括以下过程:
55.(1)获取输入行为视频的卷积特征图;
56.(2)生成通道注意力权值,并对输入视频卷积特征图进行调整;
57.(3)选择注意力权值高于设定值的特征通道进行残差时间建模,计算相邻帧在这些通道中空间特征的残差来建立它们之间的时间相关性模型,通过捕捉人体动作随时间变化的运动动态来学习视频的时间关系,进而得到更具辨识力的视频特征表示;
58.(4)基于得到的特征表示进行视频行为识别。
59.具体来说,给定一个输入视频的卷积特征图,首先在通道注意力生成(channel attention generation,以下简称cag)部分设计了一种新的视频级通道注意力方法,以探索不同特征通道的区分性,从而有效地提高深层网络的表达能力。cag利用通道权值对原始视频特征图进行校准,能够聚焦于具有强区分性的特征通道。
60.残差时间建模(residual temporal modeling,以下简称rtm)串接在cag后面,通过计算相邻帧空间特征的残差来学习视频的时间关系。将cag调整后的视频特征图的输出通道按照通道权重从高到低分成两组,权重较高的一组特征通道具有更加强大的分辨力,用于前向/后向残差时间建模,而其余权重较低的通道组则不进行时间建模处理。
61.这样,rtm可以实现高效、低计算量的时空交互建模,而不需要处理所有的特征通道。通道注意力导向残差时间建模(以下简称cartm)模块通过整合cag和rtm部分,在通道注意力引导下对时间结构进行建模,以获得更具辨识度的cnn视频特征表示。cartm模块可以灵活地嵌入到许多流行的2d网络中,以非常有限的额外计算代价生成cartm网络,能够在保持与2d cnn相似复杂度的情况下,实现非常有竞争力的行为识别性能。
62.通道注意力导向残差时间建模模块(cartm)由一个用于强调特征通道差异性的通道注意力生成(cag)部分和一个通过进行空间信息交互实现时间建模的残差时间建模(rtm)部分构成,图2给出了cag和rtm的具体构造过程。cartm模块能够在通道注意的指导下对视频特征图进行调整,实现有效的时序建模,生成更具辨识力的视频特征表示。
63.本实施例中,通道注意力生成(cag)部分具体如下:
64.注意力机制可以被看作是从输入信号中提取信息量最大的成分的一种指导。对于cnn卷积特征图,每个通道都是一个独特的特征检测器,提取某种具体的特征线索来描述输入信号。通道注意力探索了不同特征通道的学习能力,有效地增强了深层网络的表征能力。近年来,越来越多的研究将通道注意力应用到cnn中,在图像相关的视觉任务以及视频理解
任务中获得了更好的性能。cnn特征中的不同通道将捕获不同的空间信息,其中一部分通道关注静态背景信息,而另一部分通道则描述与视频行为相关的显著外观和运动动态。因此,学习特征通道的不同辨识能力有利于提高视频行为识别的性能。然而,目前绝大多数通道注意力方法的实现都是基于图像级cnn特征,对于视频输入忽略了时间相关性。为了研究基于视频级卷积特征的通道依赖性,本实施例提出了一种新的通道注意力生成(cag)方法,同时从空间和时间两个维度计算通道权值。
65.cag部分的结构如图2左半部分所示。给定输入视频的卷积特征图f∈r
c
×
t
×
h
×
w
,其中c是通道数目,t是时间维度,h和w是空间分辨率。首先对每个通道t帧特征图的空间信息进行时间聚合,其公式如下:
[0066][0067]
其中,c、t、i、j分别表示通道、时间、卷积特征图空间尺寸的高度和宽度。是时间聚合后的视频特征图。然后,在上应用全局空间平均池化来压缩空间信息以获得通道描述子u:
[0068][0069]
基于压缩后的1d通道特征u∈r
c
,通道注意力计算如下:
[0070]
α=f(w
u
δ(w
d
u))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0071]
这里应用了两个1
×
1的2d卷积层。w
d
是第一个卷积层的权值参数,它将通道维数减少了r倍。w
u
是第二个卷积层的权值参数,它将通道维数增加了r倍。在后面的实验中,参数r被设置为16。δ(
·
)表示relu激活函数,f(
·
)表示sigmoid激活函数。通过这种方法,得到视频级的通道注意力得分α∈r
c
,它为不同的特征通道分配不同的权重,以突出关键通道信息。α对原始输入特征图f进行调整,得到通道注意力校准后的视频卷积特征图f
cag
:
[0072]
f
cag
=α
⊙
f
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0073]
⊙
表示元素级相乘,f
cag
∈r
c
×
t
×
h
×
w
作为cag调整后的卷积特征图,是一个更加具有辨识力的视频特征表示,增强了关键特征通道所包含的空间信息。
[0074]
残差时间建模部分(rtm)具体如下:
[0075]
如图2右半部分所示,给定cag调整后的视频卷积特征图f
cag
∈r
c
×
t
×
h
×
w
,我们首先将c个特征通道的注意力得分按照从高到低的顺序进行通道重要性排序。然后,将f
cag
沿着排序后的通道维度分成两组,分别是高注意力得分通道组和低注意力得分通道组β=c1/c表示高得分通道组所占的比例。注意力得分高的通道可能更关注运动特征,而得分低的通道可能更关注静态背景信息。为了更有效地对视频行为的时间信息进行建模,所提出的时间建模方法rtm仅对高注意力得分通道组进行时间建模,以捕捉人体动作随时间变化的运动动态,生成更具辨识力的特征表示。对于低得分通道组不作处理以保留静态场景信息。
[0076]
具体来说,对于高得分通道组我们通过计算相邻帧空间特征图的差值来建立它们之间的时间关系模型。在这里,我们同时使用前向和后向时间建模
(每个方向各占1/2的通道),以赋予当前帧更丰富的时空信息。图2中只给出了单向时间建模的流程图。以时间t为例,前向和后向时间建模分别表示为(5)和(6):
[0077][0078][0079]
其中,∪{
·
}表示沿通道轴的级联操作。为了保持时间尺度不变,对于前向时间建模,将最后时刻的特征设为零;对于后向时间建模,将初始时刻的特征设为零。然后,将和沿通道维度使用∪{
·
}进行级联,得到时间t的运动特征,表示如下:
[0080][0081]
通过与相邻帧进行交互,同时包含了前向和后向运动信息,使当前帧具有更加丰富的空间运动和时间动态信息。将所有帧在时间维度上的运动特征图串联起来,构造高得分通道组双向时间建模的输出张量串联起来,构造高得分通道组双向时间建模的输出张量此外,为了保留输入特征图的原始空间信息,rtm部分采用了残差连接:
[0082][0083]
是高注意力得分通道组应用残差时间建模输出的卷积特征图,与低得分通道组的卷积特征沿通道维度进行组合:
[0084][0085]
f
cartm
∈r
c
×
t
×
h
×
w
是cartm模块调整后的视频输出特征,能够捕获具有区分力的时空信息进行视频行为识别。
[0086]
作为一种简单而有效的时间建模方法,cartm模块可以显著提高视频行为识别的性能,其优越性主要体现在以下两个方面。首先,据我们所知,所提出的cartm模块是第一个将时间建模与通道注意力相结合的工作。cartm模块在通道注意力的指导下,对更加关注视频行为运动特征的高注意力得分通道组进行时间建模,无需对所有特征通道进行时间建模处理,具有高效、计算量小的优势。其次,cartm通过计算相邻帧空间特征的差值来捕获它们之间的时间相关性,对当前帧应用双向时间建模与相邻帧进行信息交换,赋予它丰富的时空信息,实现空间交互时间建模,而不引入额外新的参数。
[0087]
所提出的cartm可以灵活地被嵌入到任何现有的2d网络中,使其具备时间建模的能力。本实施例以resnet架构为例,将cartm嵌入到第一个1x1 2d卷积层之后的标准残差块中,来生成cartm块,如图3底部所示的结构图。为了实现高效的行为识别,综合考虑准确度和速度的情况下,采用2d resnet50作为主干网络,通过使用cartm块替换网络中所有的残差块来构建cartm网络,网络的总体架构如图3所示。
[0088]
视频被平均分割成t个片段,从每个片段中随机采样一帧以生成t帧输入视频序列;采用2d resnet50作为主干网络,将其中的残差块全部替换为cartm块来构造cartm网络;最后应用平均聚合来得到整个视频的最终预测得分。
[0089]
实验验证部分
[0090]
本实施例在ntu rgb+d数据集上进行了大量的消融实验,以评估模块不同组件的有效性。最后,将四个数据集的实验结果分别与现有方法进行比较,并给出了详细的分析。
[0091]
本实施例在四个具有挑战性的公共人体行为数据集上评估cartm网络的性能:kinetics400、ucf101、hmdb51和ntu rgb+d。前三个是单模态数据集,只包含rgb行为视频。这三个数据集中的大多数视频行为被识别高度依赖于静态帧中的物体和背景信息,时间关系贡献较小。通过在这三个常用的rgb行为识别数据集上进行实验,验证所提方法的有效性和泛化能力。
[0092]
相比之下,ntu rgb+d数据集提供了行为样本的多种数据模态,包含不同类型的行为类,如人
‑
物交互、人
‑
人交互。该数据集还包括一些时序相关的行为,如“穿夹克”和“脱夹克”等。因此,时间建模对于识别该数据集中的行为类具有十分重要的意义。本文在ntu rgb+d数据集上进行了大量的实验,以研究cartm模块的不同方面。在此基础上还测试了cartm网络对多模态视频数据(rgb和depth)的学习能力。
[0093]
kinetics400有大约240k个训练视频和20k个验证视频,这些视频都是从原始youtube视频中裁剪得到的。数据集总共包含400个行为类。视频持续时间约为10秒。ucf101和hmdb51是两个小规模行为数据集,其中ucf101包含101个动作类,13320个视频。hmdb51包含51个动作类,6766个视频。这两个数据集提出三种不同的训练/测试集划分方法,计算三个划分后的验证集的top
‑
1平均分类精度作为行为识别的结果。这三个数据集上的实验使用单一数据模态(rgb视频)。
[0094]
ntu rgb+d数据集是一个具有挑战性的大规模rgbd数据集,包含56880个行为变化丰富的视频样本。使用3台微软kinect v.2摄像机同时记录40名受试者的60种行为类(日常、交互、与健康相关的行为)。视频时长为1~7秒。数据集定义了两个评估标准:交叉人(cross subject,cs)和交叉视角(cross view,cv)。在cs评估标准中,20名受试者的视频样本作为训练集,其余20名的视频样本作为测试集。在cv评估中,摄像机2和3采集的视频作为训练集,摄像机1采集的视频用作测试集。
[0095]
在训练过程中,使用稀疏采样策略生成8帧视频序列作为网络的输入。首先调整输入帧较短边的尺寸为256,然后将其裁剪为224
×
224的大小,得到视频输入尺寸为3
×8×
224
×
224。采用多尺度裁剪和随机水平翻转进行数据扩充。除非另有规定,本文采用在image net上预训练的2d resnet50作为主干网络,在4个gpu上设置批尺寸为32来训练cartm网络。采用随机梯度下降法学习网络权值,动量为0.9、权值衰减为0.0001。冻结除第一个batch norm(bn)层外的其余所有bn层。对于kinetics400,总迭代次数为100,初始学习率设为0.001,在迭代次数为40,60,80时分别衰减10倍。对于ntu rgb+d数据集,以0.001的初始学习率开始训练,每15次迭代减少10倍,50次迭代后停止训练。对于ucf101和hmdb51,使用kinetics400预训练的网络模型进行初始化,初始学习率为0.001,每10次迭代衰减10倍,训练总次数为50次。
[0096]
在测试阶段,对于kinetics400、ucf101和hmdb51数据集,采用准确性评估协议,每个视频抽取10个片段,并对它们各自的分类分数进行平均化处理,得到最终的预测结果。将全分辨率图像帧较短边的尺寸缩放到256,选取3个256
×
256的裁剪区域进行评估。对于ntu rgb+d数据集,采用效率评估协议,每个视频提取1个片段,将图像帧中心裁剪为224
×
224的
尺寸进行评估。
[0097]
使用交叉人(cs)协议在ntu rgb+d数据集上进行消融研究,以评估所提cartm模块在不同配置下的性能。所有实验均采用8帧视频输入,对基于2d resnet50的cartm网络进行训练。除了最后一个实验同时使用rgb和深度数据来探索cartm网络对不同数据模态的时间建模能力外,其余实验均只使用rgb数据模态进行评估。
[0098]
1)单向rtm与双向rtm。rtm定义了两种时序建模方法,即前向时间建模和后向时间建模。这里,我们比较了单向rtm和双向rtm在通道比β设为1/2时的性能,即通道注意力得分由高到低排序后,取前1/2通道的视频卷积特征作为高得分通道组。具体来说,对于单向rtm,对高得分通道组的视频特征只进行前向或后向时间建模,而在双向rtm中则同时采用前向和后向时间建模,每个方向占比1/4。比较结果如表1所示,可以看到双向rtm采用1/4前向时间建模和1/4后向时间建模,获得了最高识别精度89.71%。因此,rtm采用双向时间建模用于后面的实验。
[0099]
表1单向rtm和双向rtm的比较结果.
[0100][0101]
2)双向rtm中参数β的选择。对所有特征通道按照注意力得分进行排序后,双向rtm只对高得分通道组进行前向和后向时间建模,以提高模型的效率。通道比率β表示高得分通道组所占的比例,是一个与cartm模块性能密切相关的关键参数。该部分通过对参数β的不同设置进行实验,寻找最优值,同时研究通道比例对时序建模的影响。此外,我们还给出了当β设置为1时,在所有特征通道上应用双向rtm的识别结果。表2展示了不同β的比较结果,可以看出β=1/4时性能最好,top
‑
1准确率为90.28%,top
‑
5准确率为99.00%。对于其他设置,我们发现较大和较小的通道比都会降低识别性能,分析可能原因是较大的通道比会损害空间特征信息,而较小的通道比可能缺乏足够的时间建模能力。因此,本文实验中双向rtm的参数β=1/4。
[0102]
表2参数β不同取值的比较结果.
[0103][0104]
3)cartm块的位置和数量。cartm块替换2d resnet50的conv2到conv5中所有残差块来构建cartm网络。在该实验中,我们探讨了cartm块不同位置和数量的影响,如表3所示。考虑到resnet50后面的卷积层具有更大的感受野来捕捉时空信息,因此,首先将最后一个卷积层(conv5)的残差块替换为cartm块,而其他卷积层不作处理;然后逐步在resnet50主干网络中插入更多的cartm块。我们发现将resnet50网络中conv2到conv5的残差块全部替换成cartm块,可以达到90.28%的最佳识别效果。因此,本文最终使用这种策略来构建
cartm网络。
[0105]
表3 cartm块不同位置和数量的比较结果.
[0106][0107]
4)通道注意力的影响。所提出的cartm模块在通道注意力的指导下对视频特征进行时序建模。通道注意力关注信息丰富的特征通道,基于这些关键通道建模时间相关性能够实现更具辨识力的视频行为识别。该实验将所提方法与其他两个基准进行比较,来评估通道注意力在cartm模块中的作用,如表4所示。具体而言,基准rtm是将cag部分去掉,仅在β=1/4的输入视频特征图上应用双向时间建模。基准cartm
without ca guidance
保留了cag部分,但去掉了通道注意得分排序的操作,也就是说,在没有通道注意引导的情况下,直接将双向时间建模应用于cag调整后的视频特征中。从表4可以看出,所提方法相比于rtm提高了1.75%,比cartm
without ca guidance
提高了0.98%,这表明通道注意指导下的时间建模对于提高行为识别的性能是有效的。
[0108]
表4通道注意力的性能评估结果.
[0109][0110]
5)不同数据模态的评估。该实验评估了cartm网络对彩色(rgb)和深度两种不同数据模态下的视频序列的识别性能。两种数据模态均使用8帧视频片段作为输入,识别结果见表5,可以看出,rgb视频的结果优于深度视频,top
‑
1精度提升了1.54%,top
‑
5精度提升了0.21%。这可能是因为与深度视频相比,rgb视频提供了丰富的场景和物体颜色和纹理特征,增强了网络模型的空间特征学习能力。尽管如此,深度数据模态下的识别结果仍然十分具有竞争力,这也证明了所提方法能够有效捕捉不同数据模式下视频中的时间关系。
[0111]
表5不同数据模态的比较结果.
[0112][0113]
为了验证所提出的cartm模块用于时间建模的有效性,我们将cartm网络与2d resnet50主干网络在四个数据集中进行了比较,如表6所示。这两个模型之间的唯一区别是有无cartm。采用稀疏采样策略生成8帧rgb视频输入。ucf101和hmdb51采用kinetics400预训练的网络模型。该实验只统计了top
‑
1识别精度,对于ntu rgb+d数据集,使用交叉人协议进行评估。从表6可以看出,2d resnet50由于缺乏时间建模能力,在四个数据集中都无法获得很好的视频行为识别性能,但是嵌入cartm后,识别精度就有了显著的提高。更具体地说,与2d resnet50相比,cartm网络在ntu rgb+d数据集上带来了约12%的显著精度提升,在kinetics400、ucf101和hmdb51数据集上也分别获得了5.35%、6.72%和8.89%的精度改
善。这表明,所提出的cartm具有很强的时间建模能力,可以与2dcnn结构相结合来实现有效的行为识别。此外,我们发现kinetics400、ucf101和hmdb51数据集的精度改善远低于ntu rgb+d数据集,可能原因是在这三个数据集中,对大多数行为的识别依赖于静态背景和物体信息,而时序关系的影响较小;然而,ntu rgb+d数据集包含有大量时间相关的行为类,因此,具有时间建模能力的cartm网络可以在该数据集上获得显著的性能提升。
[0114]
表6 cartm网络和2d resnet50网络在四个数据集上的比较结果.
[0115][0116]
将本实施例所提出的cartm模型与四个常用具有挑战性的行为识别数据集上的先进算法进行比较,以证明所提方法的有效性和通用性。除了8帧(8f)rgb视频输入,我们还使用了16帧(16f)rgb输入来训练cartm网络。实验结果如表7~表9所示。
[0117]
表7
[0118]
ntu rgb+d数据集上与先进方法的精度比较。
[0119]
cs表示交叉人评估协议;cv表示交叉视角评估协议。
[0120][0121][0122]
表8
[0123]
kinetics400数据集上与先进方法的精度比较
[0124][0125]
表9
[0126]
ucf101和hmdb51数据集上与先进方法的精度比较。
[0127]
kinetics表示kinetics400数据集.
[0128][0129][0130]
ntu rgb+d数据集中的大多数行为类是时间相关的,包括一些时序相反的人体行为,因此时间信息对于识别该数据集的行为类发挥着重要的作用。所提方法在ntu rgb+d数据集上进行测试,以验证其时间建模能力。实验结果如表7所示,可以看出,cartm网络使用8f输入的性能已经超越了大多数现有的方法,在cs和cv设置下的准确率分别为90.28%和95.14%。当使用16f输入时,所提方法在cs和cv下均达到了最好的识别结果,精度分别被提升到91.80%和96.43%。具体来说,16f模型在cs和cv设置中的性能相比于所有单模态方法
具有很大幅度的提升。此外,仅基于rgb数据,它超越了该数据集上当前最先进的方法,该方法同时应用两种输入数据模式(rgb和姿势图)进行行为识别,其中cs设置下的精度提升为0.1%,cv设置下的精度提升为1.23%。因此,所提方法在ntu rgb+d数据集上实现了优越的识别性能,证实了cartm高效的时间建模能力。
[0131]
在kinetics400数据集的比较结果如表8所示,可以看出,无论是8f还是16f输入,所提方法在top
‑
1和top
‑
5精度上都达到了比较好的性能。当采用更高的时间分辨率(16帧)时,cartm模型获得了75.23%的top
‑
1精度和92.02%的top
‑
5精度;与8f输入相比,性能有所提高。从比较结果中,我们可以总结出以下结论:首先,与基准方法tsn相比,16f cartm模型具有显著的性能提升,证明了所提时间建模方法的有效性;其次,所提方法也优于同时以rgb和光流作为输入的方法,如r(2+1)d双流和tsn双流;与其他有效时间建模方法相比,16f cartm具有比tsm和stm更优的性能,与tea接近的性能,但稍逊色于设计局部和全局分支以通过不同视图捕捉时间结构的tam。nl i3d在3d cnn上添加了非局部操作来捕获长时依赖性,其性能也比所提方法高出1.27%的top
‑
1精度和0.58%的top
‑
5精度。nl slowfast在kinetics400数据集上具有当前最佳的性能,其中top
‑
1精度为79.0%,top
‑
5精度为93.6%,分别比我们的方法高出3.8%和1.6%,可能原因是nl slowfast采用了更深的主干网络(resnet101),同时也利用了非局部操作。
[0132]
表9列出了所提方法在ucf101和hmdb51的比较结果,这里只统计了top
‑
1识别准确度。16f cartm模型在ucf101和hmdb51上分别达到96.92%和73.47%的准确率,优于现有的大多数方法。i3d two
‑
stream基于3dcnns并使用光流作为附加数据模式,在两个数据集上获得了最佳性能。然而,由于引入了光流,它会带来更多的计算负担。16f cartm模型在hmdb51上的识别精度低于3d网络r(2+1)d和s3d
‑
g,但是在ucf101上具有比它们更加优越的性能。
[0133]
将cartm网络中的特征图可视化,以验证所提cartm模块的有效性。使用ntu rgb+d数据集中的两段视频进行实验,如图4所示,左侧为“脱外套”行为,右侧为“推他人”行为。由于空间限制,我们从每段视频中抽取6帧具有代表性的图像来说明cartm模块的显著影响。图4的顶行是两个视频的输入图像序列,取cartm网络中第一个卷积层的第一个cartm块进行测试,第2、3、5行分别展示了数据输入cartm模块之前的一个低得分通道和两个高得分通道的特征图。可以看到,不同的特征通道可以捕捉不同的信息,低得分通道1或61更关注静态背景,而高得分通道主要关注视频中需要进行时间建模的运动信息。因此,所提出的双向时间建模cartm模块只应用于高得分通道,以实现更加高效准确的行为识别。在图4中,第1行:ntu rgb+d数据集两个视频的输入图像序列。第2行:输入cartm模块之前的低得分通道特征图。第3/5行:输入cartm模块之前的高得分通道特征图。第4/6行:分别应用前向和后向时间建模之后的高得分通道特征图。
[0134]
对于每个行为样本,第4行展示了一个高得分通道使用前向时间建模后的特征图,第6行给出了另一个高得分通道使用后向时间建模的特征图。基于第3、4行和第5、6行的比较结果可以看出,使用cartm模块后的特征图可以更好地编码视频行为的时空动态,实现与相邻帧的时间交互。具体来说,在应用前向时间建模后,当前帧的特征图序列可以捕捉到下一个时间步的动作,如第4行中用红框标记的区域。当应用后向时间建模时,当前帧的特征图序列可以反映上一个时间步的动作,如第6行中的红框所示。以上实验结果表明,cartm模
块增强了特征图的运动信息,并能对相邻帧间的时间相关性进行有效建模。
[0135]
实施例二
[0136]
在一个或多个实施方式中,公开了一种基于通道注意力导向时间建模的视频行为识别系统,其特征在于,包括:
[0137]
数据获取模块,用于获取输入行为视频的卷积特征图;
[0138]
通道注意力生成(cag)模块,用于获取通道权值,并对原始输入视频卷积特征图进行调整;
[0139]
残差时间建模(rtm)模块,用于选择注意力权值高于设定值的特征通道进行残差时间建模,计算相邻帧在这些通道中空间特征的残差来建立它们之间的时间相关性模型,通过捕捉人体动作随时间变化的运动动态来学习视频的时间关系,进而得到更具辨识力的视频特征表示;
[0140]
视频行为识别模块,用于基于得到的特征表示进行视频行为识别。
[0141]
其中,通道注意力生成模块和残差时间建模模块共同构成通道注意力导向残差时间建模模块;
[0142]
将所述通道注意力导向残差时间建模模块嵌入到任一2d网络中构建cartm网络,使其具备时间建模的能力;
[0143]
基于所述cartm网络来进行视频行为识别。
[0144]
需要说明的是,上述各模块的具体实现方式已经在实施例一中进行说明,不再赘述。
[0145]
实施例三
[0146]
在一个或多个实施方式中,公开了一种终端设备,包括服务器,所述服务器包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现实施例一中的基于通道注意力导向时间建模的视频行为识别方法。为了简洁,在此不再赘述。
[0147]
应理解,本实施例中,处理器可以是中央处理单元cpu,处理器还可以是其他通用处理器、数字信号处理器dsp、专用集成电路asic,现成可编程门阵列fpga或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0148]
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存储设备类型的信息。
[0149]
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。
[0150]
实施例一中的基于通道注意力导向时间建模的视频行为识别方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。
[0151]
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元即算法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是
软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
[0152]
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1