一种基于圆周率PI的中文数据压缩和同步加密方法及系统与流程
本发明涉及数据压缩加密技术领域,具体涉及一种基于圆周率pi的中文数据压缩和同步加密方法及系统。
背景技术:
目前,商业软件提供的zip压缩并不能满足同步加密的需求,zip格式加密能力始终受到质疑,而软件运行中产生的大量数据需要进行运营分析;而且随着计算机技术的发展,高性能的压缩比也是数据安全存储首要考虑的因素,但是目前商业化压缩软件的压缩效率并不是特别高。
因此提供一种高效的中文数据专用压缩同步加密方案已成为许多特种行业数据存储、数据传输以及数据安全的关键。
技术实现要素:
针对上述问题,本发明的一个目的是提供一种基于圆周率pi的中文数据压缩和同步加密的方法,该方法实现了压缩和同步加密,引入圆周率对中文进行重新编码映射,相较于中文unicode编码,基于圆周率的编码显著减少了编码的长度,实现数据高效率压缩的目的。
本发明的第二个目的是提供一种基于圆周率pi的中文数据压缩和同步加密的系统。
本发明所采用的第一个技术方案是:一种基于圆周率pi的中文数据压缩和同步加密方法,包括以下步骤:
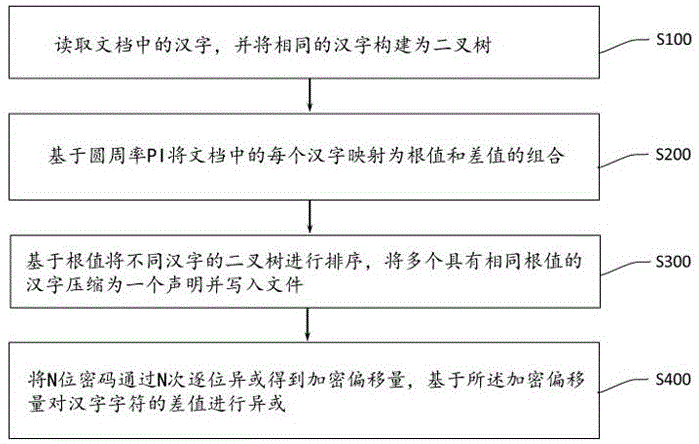
s100:读取文档中的汉字,并将相同的汉字构建为二叉树;
s200:基于圆周率pi将文档中的每个汉字映射为根值和差值的组合;
s300:基于根值将不同汉字的二叉树进行排序,将多个具有相同根值的汉字压缩为一个声明并写入文件;
s400:将n位密码通过n次逐位异或得到加密偏移量,基于所述加密偏移量对汉字字符的差值进行异或。
优选地,所述二叉树通过以下步骤构建:
s110:计算文档中相同汉字字符出现的位置;
s120:基于相同汉字出现的初始位置创建二叉树根部节点;
s130:基于相同汉字字符出现的位置依次计算当前汉字字符位置到前一相同汉字字符位置的偏移,当偏移大于设定阈值时,则所述二叉树根部节点终止,并创建第一左节点;
s140:当所述第一左节点中当前汉字字符位置到前一相同汉字字符位置的偏移大于所述设定阈值时,则所述第一左节点终止并创建第一右节点;当所述第一右节点中当前汉字字符位置到前一相同汉字字符位置的偏移大于设定阈值时,则所述第一右节点终止并创建第二左节点;
s150:重复所述步骤s140,直至将相同的汉字全部构建为二叉树。
优选地,所述设定阈值小于或等于256。
优选地,所述根值通过以下公式得到:
sqr=pow(5*charset/pi,0.5)(1)
式中,sqr为根值;pow为java取幂公式;charset为汉字的unicode编码;pi为圆周率。
优选地,所述差值通过以下公式得到:
offset=charset-pi*pow(sqr,2)/5(2)
式中,offset为差值;charset为汉字的unicode编码;pi为圆周率;pow为java取幂公式;sqr为根值。
优选地,步骤s300中所述将多个具有相同根值的汉字压缩为一个声明包括:
写入一次根值,在根值后依次写入具有相同根值汉字的差值,由相同根值不同差值的二叉树组成根值树。
优选地,步骤s300中所述写入文件包括以下步骤:
s310:记录当前汉字的根值;
s320:写入当前汉字的差值;
s330:写入当前汉字的初始位置;
s340:依次写入当前汉字二叉树中每一字符距离上一字符的偏移量,直至当前汉字的二叉树结束;
s350:重复所述步骤s320-s340,写入与上一汉字相同根值的其他汉字的二叉树,直至根值树结束。
优选地,步骤s400中的所述加密偏移量通过以下子步骤获得:
s410:获取用户输入的n位密码,并定义n位密码中第一位密码的初始偏移量;
s420:将第一位密码与第一位密码的初始偏移量进行异或,得到第一结果;
s430:将所述第一结果循环右移一位得到第二结果,将所述第二结果作为第二位密码的初始偏移量;
s440:重复所述步骤s430-s440进行逐位异或,直至得到第n位密码的初始偏移量;
s450:将第n位密码与所述第n位密码的初始偏移量进行异或,得到第三结果;
s460:将所述第三结果循环右移一位得到加密偏移量。
优选地,步骤s400中基于加密偏移量通过以下公式对汉字字符的差值进行异或:
moffset=offsetxorbyteoffset(3)
式中,moffset为加密差值;offset为差值;xor为异或;byteoffset为加密偏移量。
本发明所采用的第二个技术方案是:一种基于圆周率pi的中文数据压缩和同步加密的系统,包括二叉树构建模块、映射模块、压缩模块和加密模块;
所述二叉树构建模块用于读取文档中的汉字,并将相同的汉字构建为二叉树;
所述映射模块用于基于圆周率pi将文档中的每个汉字映射为根值和差值的组合;
所述压缩模块用于基于根值将不同汉字的二叉树进行排序,将多个具有相同差值的汉字压缩为一个声明并写入文件;
所述加密模块用于将n位密码通过n次逐位异或得到加密偏移量,基于所述加密偏移量对汉字字符的差值进行异或。
上述技术方案的有益效果:
(1)本发明公开了一种比目前商业化压缩效率更高的中文数据压缩方法,该方法引入圆周率对中文进行重新编码映射,相较于中文unicode编码,本发明基于圆周率的编码显著减少了编码的长度,实现数据高效率压缩的目的。
(2)本发明公开的基于圆周率pi中文数据压缩和同步加密方法实现了压缩和同步加密,具有安全性高的特点,实现了中文数据的简洁、安全、高效的压缩加密。
附图说明
图1为本发明的一个实施例提供的一种基于圆周率pi的中文数据压缩和同步加密方法的流程示意图;
图2为本发明一个实施例提供的二叉树的结构示意图;
图3为本发明的一个实施例提供的一种基于圆周率pi的中文数据压缩和同步加密系统的结构示意图。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例的详细描述和附图用于示例性地说明本发明的原理,但不能用来限制本发明的范围,即本发明不限于所描述的优选实施例,本发明的范围由权利要求书限定。
在本发明的描述中,需要说明的是,除非另有说明,“多个”的含义是两个或两个以上;术语“第一”“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性;对于本领域的普通技术人员而言,可视具体情况理解上述术语在本发明中的具体含义。
实施例一
图1为本发明的一个实施例提供的一种基于圆周率pi的中文数据压缩和同步加密的方法,包括以下步骤:
s100:读取文档中的每个汉字,将相同的汉字构建为二叉树;
计算文档中各相同汉字字符出现的位置,每个汉字在其出现的第一字符位置(初始位置)处创建二叉树根部节点,依次计算相同汉字中当前汉字字符位置到前一相同汉字字符位置的偏移,当偏移大于设定阈值时,则二叉树根部节点终止,并创建第一左节点;当第一左节点中当前汉字字符位置到前一相同汉字字符位置的偏移大于设定阈值时,则第一左节点终止并创建第一右节点;当第一右节点中当前汉字字符位置到前一相同汉字字符位置的偏移大于设定阈值时,则第一右节点终止并再次创建第二左节点,依此类推,直至将相同的汉字全部构建为二叉树;二叉树记录了文档中所有相同汉字字符出现的位置和偏移量;设定阈值小于或等于256,优选255或256。
例如《资治通鉴》文档中共出现“而”字15493处,如图2所示,第一处出现在170字符处,即第一字符位置为170,在170字符处为“而”建立二叉树根部节点,4704处字符“区区而有胜敌之名”出现的“而”字距离上一处“而卜相,果”中出现的相同“而”字偏移(距离相差)300字符,超过256字符,不能继续添加到二叉树根部节点中,因此二叉树根部节点终止,并建立左节点;二叉树根部节点终止于4364字符处,树长度为80;
每支二叉树能单独用格式表示为:字符--初始位置--偏移量,例如以“而”|170树为例:
字符----而;
初始位置---170;
偏移量依次记为:
0=0
1=101
2=149
3=9
4=14
5=17
6=106
7=47
8=32
....;
其中通过pos表示字符出现位置,offset表示当前字符偏移上一处位置的偏移量;通过“字符--初始位置--偏移量”这种格式能将二叉树写为字码表;例如“而”字的二叉树根部节点中的字码表具体为:
0="(pos=170,offset=0)";1="(pos=271,offset=101)";2="(pos=420,offset=149)";
3="(pos=429,offset=9)";4="(pos=443,offset=14)";5="(pos=460,offset=17)";
6="(pos=566,offset=106)";7="(pos=613,offset=47)";8="(pos=645,offset=32)";
9="(pos=658,offset=13)";10="(pos=689,offset=31)";11="(pos=705,offset=16)";
12="(pos=720,offset=15)";13="(pos=733,offset=13)";14="(pos=744,offset=11)";
15="(pos=904,offset=160)";16="(pos=924,offset=20)";17="(pos=939,offset=15)";
18="(pos=1043,offset=104)";19="(pos=1048,offset=5)";20="(pos=1059,offset=11)";
21="(pos=1071,offset=12)";22="(pos=1121,offset=50)";23="(pos=1183,offset=62)";
24="(pos=1195,offset=12)";25="(pos=1205,offset=10)";26="(pos=1230,offset=25)";
27="(pos=1239,offset=9)";28="(pos=1251,offset=12)";29="(pos=1259,offset=8)";
30="(pos=1413,offset=154)";31="(pos=1426,offset=13)";32="(pos=1514,offset=88)";
33="(pos=1553,offset=39)";34="(pos=1628,offset=75)";35="(pos=1679,offset=51)";
36="(pos=1773,offset=94)";37="(pos=1842,offset=69)";38="(pos=1887,offset=45)";
39="(pos=1987,offset=100)";40="(pos=1993,offset=6)";41="(pos=2061,offset=68)";
42="(pos=2214,offset=153)";43="(pos=2259,offset=45)";44="(pos=2411,offset=152)";
45="(pos=2434,offset=23)";46="(pos=2448,offset=14)";47="(pos=2488,offset=40)";
48="(pos=2513,offset=25)";49="(pos=2570,offset=57)";50="(pos=2626,offset=56)";
51="(pos=2658,offset=32)";52="(pos=2706,offset=48)";53="(pos=2721,offset=15)";
54="(pos=2734,offset=13)";55="(pos=2741,offset=7)";56="(pos=2798,offset=57)";
57="(pos=2864,offset=66)";58="(pos=2892,offset=28)";59="(pos=2958,offset=66)";
60="(pos=3047,offset=89)";61="(pos=3069,offset=22)";62="(pos=3090,offset=21)";
63="(pos=3116,offset=26)";64="(pos=3140,offset=24)";65="(pos=3175,offset=35)";
66="(pos=3273,offset=98)";67="(pos=3397,offset=124)";68="(pos=3527,offset=130)";
69="(pos=3561,offset=34)";70="(pos=3654,offset=93)";71="(pos=3766,offset=112)";
72="(pos=3770,offset=4)";73="(pos=3857,offset=87)";74="(pos=3941,offset=84)";
75="(pos=4105,offset=164)";76="(pos=4115,offset=10)";77="(pos=4168,offset=53)";
78="(pos=4174,offset=6)";79="(pos=4364,offset=190)";
构建左节点后继续添加,左节点中的字码表为:
0="(pos=4704,offset=0)";1="(pos=4749,offset=45)";
2="(pos=4833,offset=84)";3="(pos=4846,offset=13)";
添加至位于5275处“闻而往哭之”中的“而”字时,其偏移量为429字符,超过256字符,因此该左节点结束;创建右节点;5275字符处的“而”字作为右节点的开始;右节点中的字码表为:
0="(pos=5275,offset=5275)";1="(pos=5358,offset=83)";
以此类推,基于二叉树记录文档中所有“而”字出现的位置和偏移量;计算后文档中相同的字符数量为6466,文档中二叉树的数量为6466,文档中所有节点的数量为1461487。
本发明基于二叉树来记录文档中相同汉字出现的位置和偏移量,实现用1个字节(设定阈值小于等于256)来表示每一个汉字字符的位置。
s200:基于圆周率pi将文档中的每个汉字映射为根值和差值的组合;
以中文unicode进行编码时,标准汉字编码范围在0x4e00-0x9f5a之间,每个汉字需要16位,即2个字节;本发明通过以下公式将0x4e00-0x9f5a之间的所有汉字进行重新映射得出所有汉字的根植;
sqr=pow(5*charset/pi,0.5)(1)
式中,sqr为根值;pow为java取幂公式;charset为汉字的unicode编码;pi为圆周率。
同时利用以下公式得到0x4e00-0x9f5a之间所有汉字的差值;
offset=charset-pi*pow(sqr,2)/5(2)
式中,offset为差值;charset为汉字的unicode编码;pi为圆周率;pow为java取幂公式;sqr为根值。
根值和差值均为1个字节,本发明将0x4e00-0x9f5a之间的所有汉字采用“根值差值”这两个字节表示。
例如“而”字的unicode编码为0x800c(十进制时为32780),将“而”字的unicode编码输入公式(1)newdouble(pow(5*32780/pi,0.5)).intvalue()中,得出“而”字的根值为228,此处newdouble表示这个数值是double类型,intvalue将double类型的数值转到integer类型,取整数部分,舍弃小数部分;同时,利用公式(2)newdouble(charset-pi*pow(228,2)/5).intvalue(),得出“而”字的差值为118(“而”字unicode编码为32780,32780-32662=118);以“228118”来表示“而”字,即将“而”字重新映射为2个字节“228118”(十进制),其16进制表示为0xe40x76,相应二进制表示为:1110010001110110。
任何数字都可以被圆周率表示,本发明基于圆周率将中文0x4e00-0x9f5a之间字符进行重新编码为“根值差值”,即基于圆周率将0x4e00-0x9f5a之间的所有汉字进行重新映射;其中,0x4e00-0x9f5a之间所有汉字的差值部分取值范围为1-255,故差值能用一个字节表示,根值部分取值范围为177-255,故根值也能用一个字节表示;0x4e00-0x9f5a之间所有汉字的根值部分取值范围为177-255,因此不同的汉字会拥有相同的根值。
s300:基于根值将不同汉字的二叉树进行排序,将多个具有相同根值的汉字压缩为一个声明,并以固定的文档格式写入文件;
通过以下步骤将多个具有相同根值的汉字压缩为一个声明:
写入一次根值,在根值后依次写入具有相同根值汉字的差值,由相同根值不同差值的二叉树组成根值树。
以固定的文档格式写入文件包括:
(1)记录当前汉字的根值;
(2)写入当前汉字的差值;
(3)写入当前汉字的初始位置;优选通过4个字节记录字符的初始位置,特大型文档在文件开始位置定义枚举变量,变为8字节或者16字节
(4)依次写入当前汉字二叉树中每一字符距离上一字符的偏移量,直至当前汉字的二叉树结束;重复上述步骤写入具有与上一汉字相同根值的其他汉字的二叉树,直至根值树结束。
将相同根值的汉字排列在一起,排序以二叉树的字符根值为索引;这个排序并不会使文档发生偏转,排序不影响索引字符的初始位置和偏移量;例如排序为:
82="(charstring=耀,charset=32768,sqr=228,offset=106)"
83="(charstring=老,charset=32769,sqr=228,offset=107)"
84="(charstring=考,charset=32771,sqr=228,offset=109)"
85="(charstring=耄,charset=32772,sqr=228,offset=110)"
86="(charstring=者,charset=32773,sqr=228,offset=111)"
87="(charstring=耆,charset=32774,sqr=228,offset=112)"
88="(charstring=耇,charset=32775,sqr=228,offset=113)"
89="(charstring=而,charset=32780,sqr=228,offset=118)"
90="(charstring=耍,charset=32781,sqr=228,offset=119)"
91="(charstring=耎,charset=32782,sqr=228,offset=120)"
92="(charstring=耐,charset=32784,sqr=228,offset=122)"
93="(charstring=耒,charset=32786,sqr=228,offset=124)"
94="(charstring=耕,charset=32789,sqr=228,offset=127)"
95="(charstring=耗,charset=32791,sqr=228,offset=129)"
96="(charstring=耘,charset=32792,sqr=228,offset=130)"
97="(charstring=耜,charset=32796,sqr=228,offset=134)"
98="(charstring=耦,charset=32806,sqr=228,offset=144)"
99="(charstring=耨,charset=32808,sqr=228,offset=146)"
100="(charstring=耳,charset=32819,sqr=228,offset=157)"
101="(charstring=耶,charset=32822,sqr=228,offset=160)"
102="(charstring=耸,charset=32824,sqr=228,offset=162)"
103="(charstring=耻,charset=32827,sqr=228,offset=165)"
104="(charstring=耽,charset=32829,sqr=228,offset=167)"
105="(charstring=耿,charset=32831,sqr=228,offset=169)"
106="(charstring=聂,charset=32834,sqr=228,offset=172)"
107="(charstring=聃,charset=32835,sqr=228,offset=173)"
108="(charstring=聊,charset=32842,sqr=228,offset=180)"
109="(charstring=聋,charset=32843,sqr=228,offset=181)"
110="(charstring=职,charset=32844,sqr=228,offset=182)"
111="(charstring=聒,charset=32850,sqr=228,offset=188)"
112="(charstring=联,charset=32852,sqr=228,offset=190)"
113="(charstring=聘,charset=32856,sqr=228,offset=194)"
114="(charstring=聚,charset=32858,sqr=228,offset=196)"
115="(charstring=聩,charset=32873,sqr=228,offset=211)"
116="(charstring=聪,charset=32874,sqr=228,offset=212)"
117="(charstring=聿,charset=32895,sqr=228,offset=233)"
118="(charstring=肃,charset=32899,sqr=228,offset=237)"
119="(charstring=肄,charset=32900,sqr=228,offset=238)"
120="(charstring=肆,charset=32902,sqr=228,offset=240)"
121="(charstring=肇,charset=32903,sqr=228,offset=241)"
122="(charstring=肉,charset=32905,sqr=228,offset=243)"
123="(charstring=肋,charset=32907,sqr=228,offset=245)"
124="(charstring=肌,charset=32908,sqr=228,offset=246)"
125="(charstring=肓,charset=32915,sqr=228,offset=253)"
162="(charstring=翕,charset=32725,sqr=228,offset=63)"
163="(charstring=翘,charset=32728,sqr=228,offset=66)"
164="(charstring=翙,charset=32729,sqr=228,offset=67)"
165="(charstring=翚,charset=32730,sqr=228,offset=68)";
上述charstring表示汉字字符,charset表示unicode编码,sqr表示根值,offset表示当前字符偏移上一处位置的偏移量;可见上述汉字字符都拥有相同的根值228,写入文件的时候将其写在一起,只需要声明一次根值即可。
以“而”字二叉树的170处为例,通过以下方法以固定的文档格式写入文件:
0xff//开始;
0xe4//记录“而”字根值为228,如果差值超过256的,则跳过这个字节,直接写0x00;
0x00//树开始;
0x76//写入“而”字差值,如果是0xff0x00则表明是原unicode码,读取两个字节;
0x000x000x000xaa//写入170,通过4个字节记录字符的初始位置,特大型文档可以在文件头定义枚举变量,变为8字节或者16字节;
0x650x090x0e0x110x6a0x66..//记录二叉树中每一字符距离上一字符的偏移量,重复记录偏移量,直到二叉树结束;
0x00//当前二叉树结束,下一相同根值的二叉树开始;
0xff//根值树结束。
写入过程中需要对0xff、0x00进行转义,例如如果文档中出现0xff、0x00需要记录时,则连续写入4次字符,即写为0xff0xff0xff0xff或0x000x000x000x00,以便于和0xff//开始、0xff//根值树结束、0x00//二叉树开始以及0x00//当前二叉树结束进行区分。
本发明写入压缩文件时每个中文汉字用差值部分表示,以根值建立索引二叉树,相同根值的汉字就被压缩为一个声明,实现了中文文档的高效压缩。
s400:将n位密码通过n次逐位异或得到加密偏移量,基于加密偏移量对每一个汉字字符的差值进行异或;
通过以下方法实现将任意长度的密码通过n次逐位异或得到加密偏移量:
1)将用户输入的n位密码输入char数组,并遍历数组中的char数据;
2)定义n位密码中第一位密码的初始偏移量;
3)将第一位密码与第一位密码的初始偏移量进行异或,得到第一结果;
4)将第一结果循环右移一位得到第二结果,将第二结果作为第二位密码的初始偏移量;
5)重复上述步骤2)-3),得到第三位密码的初始偏移量;
6)重复上述步骤2)-3)进行逐位异或,直至得到第n位密码的初始偏移量;
7)将第n位密码与第n位密码的初始偏移量进行异或,得到第三结果;
8)将第三结果循环右移一位得到加密偏移量;
基于加密偏移量通过以下公式对每一个汉字字符的差值进行异或得到加密差值,写入压缩文件:
moffset=offsetxorbyteoffset(3)
式中,moffset为加密差值;offset为差值;xor为异或;byteoffset为加密偏移量。
例如密码使用9876543210abcdefabcdef(十进制),则密码可以表示为0x390x380x370x360x350x340x330x320x310x300x610x620x630x640x650x660x410x420x430x440x450x46(十六进制);通过哈希加密算法sha256将上述密码表示为71de1d123038b2552888286ff1e71016f9157e16a8d0855de67ee4cb713ad7e6,解压时首先校验用户输入的密码与这个值是否一致;
定义第一位密码0x39的初始偏移量为0x00,第一位密码0x39异或(xor)第一位密码的初始偏移量0x00,得到第一结果为0x39;将第一结果0x39循环右移一位得到第二结果为0x9c,将第二结果作为第二位密码的初始偏移量;重复上述步骤进行逐位异或,直至得到最后一位密码的初始偏移量,将最后一位密码与最后一位密码的初始偏移量进行异或并循环右移一位得到加密偏移量0x15(二进制为00010101),即加密偏移量byteoffset=0x15;
将一个汉字字符的差值0x76与加密偏移量0x15进行异或,通过公式(3)计算得到加密差值为0x63。
解压时首先通过上述步骤1)-8)得到加密偏移量;根据压缩文件格式恢复所有的二叉树;采用以下公式得到实际汉字字符的差值为0x76,即得到所有二叉树对应的汉字的差值,从而得到中文编码(根值差值);基于二叉树中的字码表(汉字的初始位置和偏移量)将中文编码置换为标准unicode编码,文档即可解压恢复;
offset=moffsetxorbyteoffset=0x63xor0x15=0x76(4)
式中,offset为差值;moffset为加密差值;xor为异或;byteoffset为加密偏移量。
本发明将汉字的差值部分与加密偏移量进行异或操作(xor),差值部分就被加密,实现了数据的压缩与同步加密;而且由于这种加密方式与语言本身的特性脱离,所以其很难被破解,提高了数据的安全性。
下面结合具体算例分析本发明的实际效果:
以txt文档《资治通鉴》3123576字的为例,未压缩前文件为6126kb,zip格式压缩后的文件为3615kb,通过本发明公开的压缩方法进行压缩后文件为3066kb,可见,通过本发明的压缩方法进行压缩后的文件大小远低于通过zip格式压缩后的文件大小,本发明显著地提高了压缩效率。
本发明公开了一种比目前商业化压缩效率更高的中文数据压缩方法,该方法引入圆周率对中文进行重新编码映射,相较于中文unicode编码,本发明基于圆周率的编码显著减少了编码的长度,实现数据高效率压缩的目的。
本发明公开的基于圆周率pi中文数据压缩和同步加密方法实现了压缩和同步加密,具有安全性高的特点,实现了中文数据的简洁、安全、高效的压缩加密。
实施例二
图3为本发明的一个实施例提供的一种基于圆周率pi的中文数据压缩和同步加密的系统,包括二叉树构建模块、映射模块、压缩模块和加密模块;
二叉树构建模块用于读取文档中的每个汉字,并将相同的汉字构建为二叉树;
映射模块用于基于圆周率pi将文档中的每个汉字映射为根值和差值的组合;
压缩模块用于基于根值将不同汉字的二叉树进行排序,将多个具有相同差值的汉字压缩为一个声明并写入文件;
加密模块用于将n位密码通过n次逐位异或得到加密偏移量,基于加密偏移量对汉字字符的差值进行异或。
本领域普通技术人员可以意识到,结合本发明实施例中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
在本申请所提供的实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!