基于FCOS算法的胃镜图片病灶识别方法及装置与流程
【
技术领域:
】本申请涉及一种基于fcos算法的胃镜图片病灶识别方法及装置,属于医学图像智能处理
技术领域:
。
背景技术:
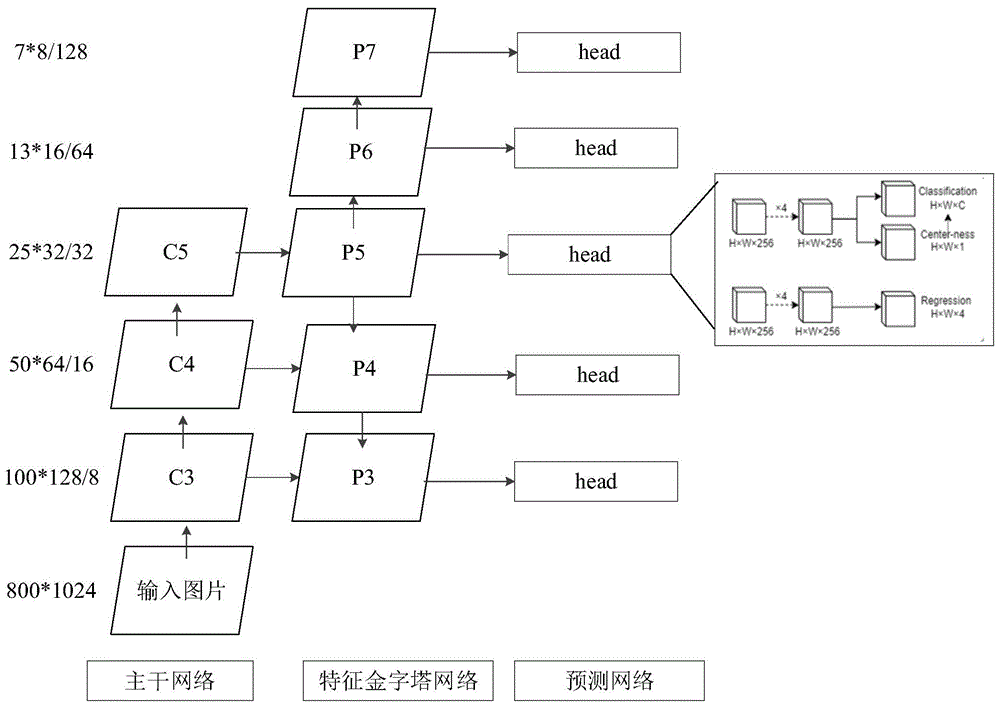
:胃癌是一种起源于胃黏膜上皮的恶性肿瘤,在我国的各类恶性肿瘤中发病率处于首位。由于胃镜技术在胃癌诊断方面效果显著,已被推荐为胃癌的主要诊断方法。具体来说,胃镜检查可以直接探及胃内的病变组织区域,以供医疗人员作出相应的诊断,在胃镜下可以做组织活检对早期的胃癌前疾病或者是癌前病变的诊断及鉴别良性恶性溃疡都有重要作用。但是,由于人为因素例如医生的经验水平不一致,或者疏忽等特殊特殊情况会直接影响最后的胃癌诊断情况,同时人眼观察胃镜图片也会耗费大量的时间,导致病灶识别的效率较低的问题。另外,由于大多目标检测算法无法同时具有良好的精准度和时间性能,因此,无法应用于对精度和时间性能具有较高要求的胃镜图片病灶识别领域。技术实现要素:本申请提供了一种基于fcos算法的胃镜图片病灶识别方法,可以使用压缩后的网络模型进行胃部病灶识别,且具有良好的识别精准度和时间性能,可以实现胃镜图片的自动诊断。本申请提供如下技术方案:第一方面,提供一种基于fcos算法的胃镜图片病灶识别方法,所述方法包括:获取多组训练数据,每组训练数据包括胃镜图片和所述胃镜图片的病灶类别和病灶区域;使用所述多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度;基于贪婪算法按照所述识别精度对所述fcos模型进行模型压缩,得到压缩后的模型结构,所述压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类。可选地,所述使用所述多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练之前,还包括:对所述胃镜图片进行预处理,预处理后的胃镜图片用于输入所述fcos模型进行训练;其中,所述预处理包括以下几种中的至少一种:缩放裁剪处理、去均值处理和归一化处理。可选地,所述fcos模型包括主干网络、与主干网络相连的特征金字塔网络、以及与特征金字塔网络相连的预测网络;所述使用所述多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度,包括:保持所述主干网络结构不改变,依次在所述特征金字塔网络对应的多层特征图中选择保留一个特征图,并对边界框内的每一个像素点进行位置回归。可选地,所述多层特征图包括p3层,p4层,p5层,p6层和p7层;其中,p3层由主干网络的特征图c3经过1×1卷积核卷积得到;p4层由主干网络的特征图c4经过1×1卷积核卷积得到;p5层由主干网络的特征图c5经过1×1卷积核卷积得到;p6层由p5层的输出结果经过一个步长为2的卷积层得到;p7层由p6层的输出结果经过一个步长为2的卷积层得到。可选地,所述基于贪婪算法按照所述识别精度对所述fcos模型进行模型压缩,得到压缩后的模型结构,包括:基于贪婪算法对分离后的层次再次进行组合,得到识别精度大于期望精度的层次组合,得到压缩后的模型结构;压缩后的模型结构的层数小于压缩前的fcos模型的层数。可选地,所述基于贪婪算法对分离后的层次再次进行组合,得到识别精度大于期望精度的层次组合,得到压缩后的模型结构,包括:将各个训练后的层次按照识别精度进行降序排列;选择最优的某一层次结构作为开始时的基础层次结构,并把这一层的识别精度作为当前的最优识别精度;依据分层训练的精度排序表,在基础结构上增加次优的层次结构形成一个层次组合,训练并记录此层次组合的识别精度;若此层次组合的识别精度低于当前的最优识别精度,则停止压缩过程,将组合前的层结构作为压缩结果;若此层次组合的识别精度高于当前的最优识别精度,则再次增加下一个层次,直至增加层次不再提升识别精度或所有层次都被添加完毕时停止。可选地,在训练过程中使用的损失函数通过下述公式表示:其中,px,y是像素点类别输出,是类别标签,tx,y是像素点的回归输出,是回归标签,lcls是类别误差,采用焦点损失focalloss计算,lreg是回归误差,采用iou损失计算,npos表示正样本的数量,是指示器,当时等于1,否则等于0。可选地,所述基于贪婪算法按照所述识别精度对所述fcos模型进行模型压缩,得到压缩后的模型结构之后,还包括:将测试集中的待识别胃镜图片输入所述压缩后的模型结构,得到多个预测框;利用非极大值抑制算法对所述预测框进行筛选,得到预测结果;使用所述预测结果对所述压缩后的模型结构进行测试。可选地,所述使用所述预测结果对所述压缩后的模型结构进行测试,包括:使用所述预测结果计算基于平均精度均值指标,得到所述压缩后的模型结构的识别精度;使用所述预测结果计算每秒传输帧数,得到所述压缩后的模型结构的识别速度。第二方面,提供一种基于fcos算法的胃镜图片病灶识别装置,所述装置包括:数据获取模块,用于获取多组训练数据,每组训练数据包括胃镜图片和所述胃镜图片的病灶类别和病灶区域;分层训练模块,用于使用所述多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度;模型压缩模块,用于基于贪婪算法按照所述识别精度对所述fcos模型进行模型压缩,得到压缩后的模型结构,所述压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类。本申请的有益效果至少包括:通过获取多组训练数据,每组训练数据包括胃镜图片和胃镜图片的病灶类别和病灶区域;使用多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度;基于贪婪算法按照识别精度对fcos模型进行模型压缩,得到压缩后的模型结构,压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类;可以解决人工进行胃部病灶识别时效率较低、且现有目标检测模型不适用于胃部诊断场景的问题;通过压缩后的模型结构可以提高胃镜图片病灶识别的时间性能,同时又有较高的精度水平。另外,在识别过程中不需要人工参与,减少人为因素的同时,可以为医生提供高效的诊断参考,辅助医生工作,提高诊断效率。上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,并可依照说明书的内容予以实施,以下以本申请的较佳实施例并配合附图详细说明如后。【附图说明】图1是本申请一个实施例提供的fcos的网络结构示意图;图2是本申请一个实施例提供的基于fcos算法的胃镜图片病灶识别方法的流程图;图3是本申请一个实施例提供的分类模型的训练过程的示意图;图4是本申请一个实施例提供的压缩后的模型结构的示意图;图5是本申请一个实施例提供的基于fcos算法的胃镜图片病灶识别装置的框图。【具体实施方式】下面结合附图和实施例,对本申请的具体实施方式作进一步详细描述。以下实施例用于说明本申请,但不用来限制本申请的范围。首先,对本申请涉及的若干名词进行介绍。一阶全卷积目标检测(fullyconvolutionalone-stageobjectdetection,fcos):是一种基于全卷积神经网络(fullyconvolutionalnetworks,fcn)的逐像素目标检测算法,实现了无锚点(anchor-free)、无提议(proposalfree)的解决方案,并且提出了中心度(center—ness)的思想,在召回率等方面表现接近甚至超过主流的基于锚框目标检测算法。fcos不依赖预先定义的锚框或者提议区域,是一种用于目标检测的逐像素预测方法,类似于语义分割。几乎所有最先进的目标检测算法,例如retinanet,ssd,yolov3等都采用了预先设定好的锚框,而fcos是无锚框的。因为不需要预先定义锚框序列,所以fcos完全避免了与锚框相关的复杂的计算,例如训练过程中的重叠面积的计算。不仅如此,fcos还避免了设置与锚框相关的超参数,而这些超参数通常对最终的预测结果有一定影响。在后处理方法仅使用非极大值抑制(non-maximumsuppression,nms)和resnet-50作为基础模型的情况下,fcos可以达到44.7%的准确率,比以往的单阶段目标检测方法更准确更高效。参考图1所示的fcos模型,根据图1可知,fcos模型包括主干网络(backbone)、与主干网络相连的特征金字塔网络、以及与特征金字塔网络相连的预测网络。其中,主干网络基于卷积神经网络(convolutionalneuralnetworks,cnn)建立,主干网络包括多个卷积层,多个卷积层包括c3层、c4层和c5层。特征金字塔网络包括多个特征层,对应不同尺寸的特征图,多个特征层包括p3层、p4层、p5层、p6层和p7层。每个卷积层映射至特征金字塔网络中的一个特征层,根据图1可知,c3层映射至特征金字塔的p3层、c4层映射至特征金字塔的p4层、c5层映射至特征金字塔的p5层。具体地,p3层由主干网络的特征图c3经过1×1卷积核卷积得到;p4层由主干网络的特征图c4经过1×1卷积核卷积得到;p5层由主干网络的特征图c5经过1×1卷积核卷积得到;p6层由p5层的输出结果经过一个步长为2的卷积层得到;p7层由p6层的输出结果经过一个步长为2的卷积层得到。预测网络包括与特征金字塔网络中每层特征层对应相连的预测层。每个预测层包括三个分支,分别为:类别分支、中心度(center—ness)分支和回归分支。类别分支采用c个二分类,共输出c个预测值。c为正整数。center—ness分支用于抑制由于偏离目标中心的位置所预测的低质量检测框。center-ness分支预测一个值,即当前位置与要预测的物体中心点之间的归一化距离,值在[0,1]之间。回归分支预测4个值(l,t,r,b),l表示目标框内某个点离框的左边的距离、t表示目标框内某个点离框的上边的距离、r表示目标框内某个点离框的右边的距离、b表示目标框内某个点离框的下边的距离。贪婪算法:是指在对问题求解时,总是做出在当前看来是最好的选择。贪婪算法不从整体最优上加以考虑,所做出的仅是在某种意义上的局部最优选择。使用贪婪策略要注意局部最优与全局最优的关系,选择当前的局部最优并不一定能推导出问题的全局最优。在利用贪婪策略解题时要确定问题是否具有贪婪选择性质,然后制定贪婪策略,以达到问题的最优解或较优解。要确定一个问题是否适合用贪婪算法求解,必须证明每一步所作的贪婪选择最终导致问题的整体最优解。证明的大致过程为:首先考察问题的一个整体最优解,并证明可修改这个最优解,使其以贪婪选择开始,做了贪婪选择后,原问题简化为规模更小的类似子问题。然后用数学归纳法证明通过每一步做贪婪选择,最终可得到问题的整体最优解。可选地,本申请以各个实施例的执行主体为具有图像处理能力的电子设备为例进行说明,该电子设备可以为终端或服务器,该终端可以为计算机、笔记本电脑、平板电脑、医疗诊断设备等,本实施例不对终端的类型和电子设备的类型作限定。本申请中,图1中fcos模型,首先将fcos模型中的p3,p4,p5,p6,p7分离并单独训练,然后利用贪婪算法的思想对模型进行压缩,最终得到压缩后的网络模型,以进行胃部病灶的识别。图2是本申请一个实施例提供的基于fcos算法的胃镜图片病灶识别方法的流程图。该方法至少包括以下几个步骤:步骤201,获取多组训练数据,每组训练数据包括胃镜图片和胃镜图片的病灶类别和病灶区域。训练前,首先准备数据集,并将该数据集划分为训练集和测试集。训练集包括多组训练数据,以进行网络训练;测试集包括多组测试数据,以进行网络测试。比如:对600张胃镜图片进行标注,利用矩形框标出每张胃镜图片的病灶区域及相应的病灶类别。然后,划分出400张图片作为训练集,其中,包括200张胃癌类别和200张胃溃疡类别,余下的200张图片作为测试集使用。在实际实现时,训练集和测试集的划分方式也可以为其它划分方式,本实施例在此不再赘述。可选地,病灶类别包括但不限于以下几种中的至少一种:胃癌、胃溃疡、胃炎、胃糜烂等,在实际实现时,病灶类别还可以包括更多或更少的分类,或者,对每种分类按照严重程度进一步划分的类别,本实施例不对病灶类别的设置方式作限定。病灶区域用于标识胃镜图片中病灶所在的位置,该病灶区域通常通过矩形框标注。步骤202,使用多组训练数据对fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度。可选地,由于训练数据中的胃镜图片可能不符合fcos模型的输入标准。因此,使用多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练之前,还包括:对胃镜图片进行预处理,该预处理后的胃镜图片用于输入fcos模型进行训练;其中,预处理包括以下几种中的至少一种:缩放裁剪处理、去均值处理和归一化处理。缩放裁剪处理用于将输入图片处理成统一的尺寸。去均值处理是指在图片的rgb未读上减去数据对应维度的统计平均值,以消除公共的部分、凸显个体之间的特征和差异。归一化处理是指将模型输入的数值限制在[0,1]之间,以加快模型收敛速度。fcos模型包括主干网络、与主干网络相连的特征金字塔网络、以及与特征金字塔网络相连的预测网络;使用多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度,包括:保持主干网络结构不改变,依次在特征金字塔网络对应的多层特征图中选择保留一个特征图,并对边界框内的每一个像素点进行位置回归。其中,多层特征图包括p3层,p4层,p5层,p6层和p7层;其中,p3层由主干网络的特征图c3经过1×1卷积核卷积得到;p4层由主干网络的特征图c4经过1×1卷积核卷积得到;p5层由主干网络的特征图c5经过1×1卷积核卷积得到;p6层由p5层的输出结果经过一个步长为2的卷积层得到;p7层由p6层的输出结果经过一个步长为2的卷积层得到。传统的fcos中每个层次会直接限制边界框的回归范围,特征图上的每个位置会计算回归目标,l*,t*,r*,b*,如果某像素位置满足max(l*,t*,r*,b*)>mi或max(l*,t*,r*,b*)<mi-1,它会被设为负例,不会用于边界框的回归。其中,m是每个层次特征图最大的回归距离,分别设置为0,64,12,256,512,+inf。由于胃镜图片中病灶部位重叠的情况极少发生,因此,本实施例中,可以对fcos的多层次模型进行简化,将fcos的每一层次结构进行分离,单独训练。具体来说,保持主干cnn网络结构不改变,依次在p3,p4,p5,p6,p7共5个特征图中选择保留一个特征图,并放开对保留层回归距离的限制,让边界框内的每一个像素点进行位置回归。比如:参考图3所示的仅保留p4层时的模型结构,对该模型进行训练后,得到训练后的网络模型,以及该网络模型对应的识别精度。其中,模型训练过程包括:将训练集中的图片预处理后输入网络模型,得到特征图上每个像素点的预测信息,包括类别信息和预测框位置;将预测信息和病灶类别输入损失函数中,进行训练。可选地,在训练过程中使用的损失函数通过下述公式表示:其中,px,y是像素点类别输出,是类别标签,tx,y是像素点的回归输出,是回归标签,lcls是类别误差,采用焦点损失focalloss计算,lreg是回归误差,采用iou损失计算,npos表示正样本的数量,是指示器,当时等于1,否则等于0。假设在各组训练过程中,采用相同的超参数,批大小为12,初始学习率为0.002,并放开对保留层回归距离的限制,让边界框内的每一个像素点进行位置回归。在其它实施方式中,不同组网络训练时对应的超参数也可以不同,批大小和初始学习率也可以为其它值,本实施例不对训练过程中的各个参数取值作限定。以图3为例进行说明,在训练过程中,处理后的图片输入模型后,主干网络会对输入图片进行多次卷积,从中抽取出c4特征图,其大小为50*64,然后再使用一个1*1的卷积核对c4进行卷积操作得到p4,p4最后再经过head部分处理,其中包括两个分支,第一个分支用于输出每个像素点的类别和此像素点距离边界的远近程度值,第二个分支用于输出预测框的位置信息。在取得输出后,与真实的标签构建误差函数,利用随机梯度下降算法训练模型,反复迭代直至模型收敛,取得误差值最低的模型参数并保存下来。假设p3层,p4层,p5层,p6层,p7层对应的5组训练结果参考下表一所示。表一:保留特征层p3p4p5p6p7map0.340.400.210.450.0其中,map为基于平均精度均值(meanaverageprecision),map用于评估模型的识别精度。步骤203,基于贪婪算法按照识别精度对fcos模型进行模型压缩,得到压缩后的模型结构,压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类。其中,病灶定位是指输出胃镜图片中病灶所在的位置。如:通过矩形框标注病灶所在的位置。病灶分类是指输出病灶对应的类型。在一个示例中,基于贪婪算法按照识别精度对fcos模型进行模型压缩,得到压缩后的模型结构,包括:基于贪婪算法对分离后的层次再次进行组合,得到识别精度大于期望精度的层次组合,得到压缩后的模型结构;压缩后的模型结构的层数小于压缩前的fcos模型的层数。其中,基于贪婪算法对分离后的层次再次进行组合,得到识别精度大于期望精度的层次组合,得到压缩后的模型结构,包括:将各个训练后的层次按照识别精度进行降序排列;选择最优的某一层次结构作为开始时的基础层次结构,并把这一层的识别精度作为当前的最优识别精度;依据分层训练的精度排序表,在基础结构上增加次优的层次结构形成一个层次组合,训练并记录此层次组合的识别精度;若此层次组合的识别精度低于当前的最优识别精度,则停止压缩过程,将组合前的层结构作为压缩结果;若此层次组合的识别精度高于当前的最优识别精度,则再次增加下一个层次,直至增加层次不再提升识别精度或所有层次都被添加完毕时停止。比如:对p3,p4,p5,p6,p7层单独训练后的识别精度进行降序排序,然后选择最优的p6特征层作为开始时的基础层次结构,并把0.45作为当前的最优识别精度。接着,在基础模型上增加次优的p4特征层形成一个层次组合,利用训练集反复训练此层次组合直至模型收敛,测试此组合的识别精度为0.495,大于当前最优识别精度0.45,因此,继续反复此过程,直至增加层次不再提升识别精度或所有层次都被添加完毕。假设压缩后的模型结构参考图4所示。可选地,基于贪婪算法按照识别精度对fcos模型进行模型压缩,得到压缩后的模型结构之后,还包括:将测试集中的待识别胃镜图片输入压缩后的模型结构,得到多个预测框;利用非极大值抑制算法对预测框进行筛选,得到预测结果;使用预测结果对压缩后的模型结构进行测试。其中,使用预测结果对压缩后的模型结构进行测试,包括:使用预测结果计算map指标,得到压缩后的模型结构的识别精度;使用预测结果计算每秒传输帧数(framespersecond,fps),得到压缩后的模型结构的识别速度。参考下表二所示的压缩后的模型和未压缩的模型在速度和精度两方面的对比结果。根据表二可以看出,经过压缩后的模型取得了与未压缩模型几乎相同的识别精确度,而在模型的速度方面,未压缩的模型每秒只能处理4.6张胃镜图片,而压缩后的模型可以处理10张胃镜图片,较未压缩模型提高一倍。可见,本发明提高了胃镜图片病灶识别的时间性能,同时又保留了原有的精度水平。表二:未压缩模型压缩模型map0.5010.495fps4.610综上所述,本实施例提供的基于fcos算法的胃镜图片病灶识别方法,通过获取多组训练数据,每组训练数据包括胃镜图片和胃镜图片的病灶类别和病灶区域;使用多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度;基于贪婪算法按照识别精度对fcos模型进行模型压缩,得到压缩后的模型结构,压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类;可以解决人工进行胃部病灶识别时效率较低、且现有目标检测模型不适用于胃部诊断场景的问题;通过压缩后的模型结构可以提高胃镜图片病灶识别的时间性能,同时又有较高的精度水平。另外,在识别过程中不需要人工参与,减少人为因素的同时,可以为医生提供高效的诊断参考,辅助医生工作,提高诊断效率。图5是本申请一个实施例提供的基于fcos算法的胃镜图片病灶识别装置的框图。该装置至少包括以下几个模块:数据获取模块510、分层训练模块520和模型压缩模块530。数据获取模块510,用于获取多组训练数据,每组训练数据包括胃镜图片和所述胃镜图片的病灶类别和病灶区域;分层训练模块520,用于使用所述多组训练数据对一阶全卷积目标检测fcos模型中的指定特征层进行分层次训练,得到每个训练后的层次对应的识别精度;模型压缩模块530,用于基于贪婪算法按照所述识别精度对所述fcos模型进行模型压缩,得到压缩后的模型结构,所述压缩后的模型结构用于对输入的胃镜图片进行病灶定位和分类。相关细节参考上述方法实施例。需要说明的是:上述实施例中提供的基于fcos算法的胃镜图片病灶识别装置在进行基于fcos算法的胃镜图片病灶识别时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将基于fcos算法的胃镜图片病灶识别装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的基于fcos算法的胃镜图片病灶识别装置与基于fcos算法的胃镜图片病灶识别方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。可选地,本申请还提供有一种计算机可读存储介质,所述计算机可读存储介质中存储有程序,所述程序由处理器加载并执行以实现上述方法实施例的基于fcos算法的胃镜图片病灶识别方法。可选地,本申请还提供有一种计算机产品,该计算机产品包括计算机可读存储介质,所述计算机可读存储介质中存储有程序,所述程序由处理器加载并执行以实现上述方法实施例的基于fcos算法的胃镜图片病灶识别方法。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1