一种基于深度强化学习的日程安排推荐方法
本发明涉及人工智能和强化学习技术领域,特别是一种基于深度强化学习的日程安排推荐方法。
背景技术:
城市的快速发展使得能够满足人们日常需求的poi(pointofinterest,兴趣点)具有数量多,分布广且无规律等特征。必不可少地,在日常生活中人们每天都会考虑自己的日常安排来满足自己的需求。比如,用户在一天内的需求包括先去理发店里理发,再去餐馆里吃饭,最后去超市购物。然而,人们在制定这个日程安排时通常都会思考这些问题。比如,我应该去哪个地方理发?我应该先去理发店理发,还是先去超市购物呢?不同的日程安排产生的结果也是不同的,如需要行走的距离长,交通拥堵,或享受到的poi服务质量低等。推荐合理的日程安排,人们会节省大量的时间和距离且得到更好的服务。因此,对于人们在城市生活中的日程安排,开发独特的技术来为人们提供便利是非常重要的。
强化学习描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化的问题,其具有状态、动作、状态转移、奖励和策略等要素。由于强化学习是一个无监督方法,因此基于强化学习框架训练深度活动因素权衡网络,并设计了一个强化学习深度活动因素权衡模型来为用户推荐合理的日程安排。
(1)日程安排推荐
参考文献1“aninteractivemulti-tasklearningframeworkfornextpoirecommendationwithuncertaincheck-ins”(l.zhang,z.sun,j.zhang,y.lei,c.li,z.wu,h.kloedenandf.klanner,proceedingsofthe29thinternationaljointconferenceonartificialintelligence,pp.3551-3557,2020)和参考文献2“travelrecommendationviafusingmulti-auxiliaryinformationintomatrixfactorization”(l.chen,z.wu,j.cao,g.zhuandy.ge,acmtransactionsonintelligentsystemandtechnology2020,pp.1-24,2020)分别为用户推荐下一个poi和旅游行程。日程安排推荐与下一个poi推荐和旅游行程推荐的区别包括如下几点:第一,下一个poi推荐每次只推荐一个poi,而日程安排推荐通常一次推荐多个poi。第二,日程安排推荐会满足用户的需求,而下一个poi推荐和旅游行程推荐可能不会满足用户的需求。第三,日程推荐的时间区间是1天,下一个poi推荐是1或2天,而旅游日程安排则涉及到更多的天数。第四,日程安排会对推荐的多个poi进行排序,而旅游日程安排很少对多个poi排序。下一个poi推荐不需要对poi排序,因为其每次只推荐一个poi。因此,下一个poi推荐和旅游行程推荐的方法不适用于推荐日程安排,并且现有日程推荐的相关研究还很少。
(2)强化学习的应用
参考文献3“adeepreinforcementlearning-enableddynamicredeploymentsystemformobileambulances”(s.ji,y.zheng,z.wangandt.li,proceedingsoftheacmoninteractive,mobile,wearableandubiquitoustechnologies,pp.1-20,2019)和参考文献4“drn:adeepreinforcementlearningframeworkfornewsrecommendation”(g.zheng,f.zhang,z.zheng,y.xiang,n.yuan,x.xieandz.li,proceedingsofthe2018worldwidewebconference,vol.7,pp.167-176,2018)分别利用深度强化学习解决了动态救护车部署问题和新闻推荐问题。从这些方法我们可以得出,深度强化学习利用深度学习的表征能力来解决强化学习问题,其在许多序列决策操作问题中取得了显著的成功。因此,深度强化学习也被用来解决现实生活中的问题。
技术实现要素:
本发明的目的是提供一种基于深度强化学习的日程安排推荐方法。
实现本发明的技术方案如下:
一种基于深度强化学习的日程安排推荐方法,包括训练日程安排模型的步骤:
步骤1:根据用户当前位置的坐标和用户需求列表nl,从poi数据集中读取距离用户当前位置最近的kn个候选poi的id;其中,k表示用户需求列表nl中的用户需求类别数,n表示为用户提供同一需求类别的poi个数;
步骤2:根据用户当前位置和kn个候选poi的id,从poi特征数据集中读取kn个候选poi的特征,并对每个候选poi的每个特征进行归一化;所述poi的特征为向量
其中,#distance表示用户当前位置与候选poi之间的距离,或在kn个候选poi中任意两个poi之间的距离;#walking-distance表示用户从当前位置到任一个候选poi需要步行的距离,或在kn个候选poi中用户从一个poi到另一个poi需要步行的距离;#cost表示用户从当前位置到任一个候选poi需要支出的费用,或在kn个候选poi中用户从一个poi到另一个poi需要支出的费用;#expedite表示用户当前位置与候选poi之间交通状态为畅通的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为畅通的路段在整个路段的占比;#slow-moving表示用户当前位置与候选poi之间交通状态为缓行的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为缓行的路段在整个路段的占比;#congestion表示用户当前位置与候选poi之间交通状态为拥堵的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为拥堵的路段在整个路段的占比;#unknown表示用户当前位置与候选poi之间交通状态为未知的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为未知的路段在整个路段的占比;#duration用户从当前位置到任一个候选poi需花费的时间,或在kn个候选poi中用户从一个poi到另一个poi需花费的时间;#rating表示用户对kn个候选poi的服务评分;
步骤3:设置最大训练次数为e;
步骤4:将用户在时间步t的状态st输入到活动因素权衡网络dafb中,得到所有候选poi的概率分布;
其中,st=<nlt,dst,xt>,nlt是用户在时间步t的需求列表,dst是用户在时间步t的日程安排,xt包含了用户在时间步t可选的
在候选poi的概率分布中,每个poi被选中的概率为:
其中,
所述
输入层a,包括第一输入、第二输入和第三输入;其中,第一输入包括特征#distance、#walking-distance和#cost;第二输入包括特征#expedite、#slow-moving、#congestion、#unknown和#duration;第三输入包括特征#rating;
线性层b,包括分别对应输入层a的第一输入、第二输入和第三输入的三个隐藏单元;
融合层,包括连接层c、线性层d和线性层e;三个隐藏单元通过融合层得到每个poi的初始概率;
通过连接层f将kn个poi的初始概率进行连接后,使用softmax函数得到所有候选poi的概率分布;
步骤5:按候选poi的概率分布随机抽样出动作at;
步骤6:根据动作at,将状态st转换到下一个时间步t+1的状态st+1,
其中,t是状态转移函数,poit是在时间步t选择的poi,qt表示与poit提供的服务对应的需求,
步骤7:根据当前状态st和动作at,计算标量奖励r(st,at),并将时间步t的标量奖励r(st,at)存储到奖励集合r中;其中,
r(st,at)=δ*(1-#cost)+(1-δ)*#rating,δ是平衡因子;
步骤8:重复执行步骤4、5、6和7,直到需求列表nlt为空;
步骤9:根据日程安排dst和奖励集合r计算损失函数l(θ),
其中,
步骤10:利用梯度下降的方法更新参数:
θt+1=θt+α▽θl(θ)
其中,θt+1和θt分别表示在时间步t+1和时间步t的参数;α表示学习率;▽θ表示对参数θ进行求导;
步骤11:跳转到步骤3,直到训练次数等于e;
还包括,推荐日程安排的步骤,具体为:
2.1以步骤1、步骤2相同的方法处理用户实时数据;
2.2以步骤4相同的方法,将用户在时间步t的状态st输入到活动因素权衡网络dafb中,得到所有候选poi的概率分布;
2.3按候选poi的概率分布抽样出概率最高的动作at;
2.4以步骤6相同的方法,根据动作at将状态st转换到下一个时间步t+1的状态st+1;
2.5重复执行2.2、2.3和2.4,直到需求列表nlt为空,得到为用户推荐的日程安排dst。
本发明的有益效果在于,提出的强化学习深度活动因素权衡模型可以有效地融合影响用户选择poi的多种因素,实现为用户推荐合理的日程安排,使得用户可以节省大量时间并享受到质量高的服务。
附图说明
图1是本发明的框架结构示意图。
图2是蒙特卡罗抽样过程示意图。
图3是候选poi的特征存储空间压缩示意图。
图4(a)和图4(b)分别为在两个真实数据集上与多个日程安排推荐基准方法进行性能对比的结果。
图5(a)和图5(b)分别为在两个真实数据集上候选poi个数对所提出方法的性能影响结果。
图6(a)和图6(b)分别为在两个真实数据集上用户的需求个数对所提出方法的性能影响结果。
具体实施方式
以下结合附图对本发明进一步说明。
一、多个活动因素融合:
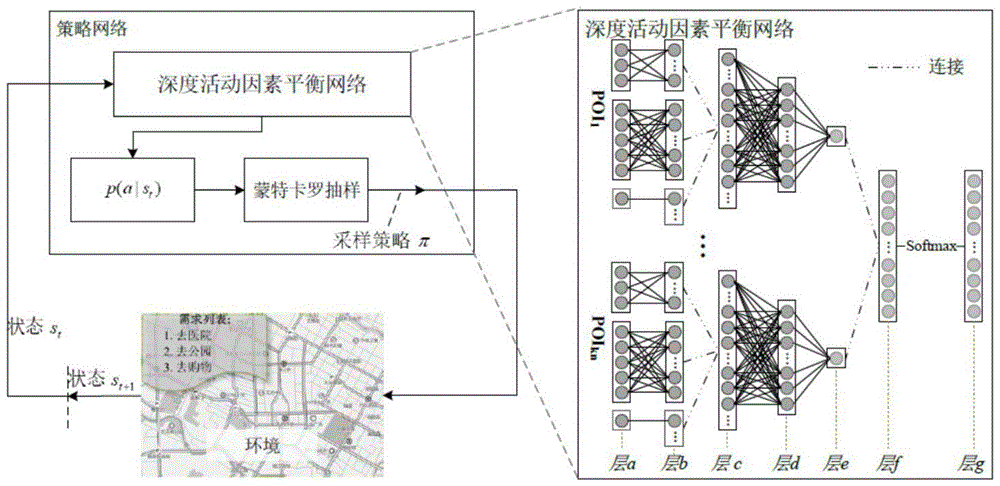
本发明的整体框架结构如图1所示,即强化学习活动因素权衡模型。它使用一个基于策略梯度的强化学习框架来学习活动因素权衡网络的参数。它的优点在于其可以训练没有poi标签的活动因素权衡网络的参数,而监督学习算法则不能。强化学习活动因素权衡模型由强化学习框架和活动因素权衡网络组成。
通过定义五个关键的要素,即状态、动作、迁移、奖励和策略构建基于日程安排的强化学习模型。五个关键要素的详细定义如下:
状态(state)。在时间步t的状态为一个三元组st=<nlt,dst,xt>,nlt是用户在时间步t的需求列表,dst是用户在时间步t的日程安排,xt包含了用户在时间步t可选的
动作(action)。在每个时间步t,我们指定用a(st)表示智能体能选择的动作的集合,每个动作对应一个来自xt的poi。
转移(transition)。从状态st转换到状态st+1的详细转换过程如下所示:
其中,t是状态转移函数,poit是在时间步t选择的poi,qt表示和poit提供的服务对应的需求,
奖励(reward)。根据当前的状态st和选择的动作at,计算标量奖励来估计所获得的日程安排的质量。标量奖励的公式为:
r(st,at)=δ*(1-#cost)+(1-δ)*#rating
其中δ是一个平衡因子。
策略(policy)。策略π(st,at)将状态st作为输入并输出选择的动作at。其中,π(st,at)是一个概率函数,描述在给定当前状态st下选择at的概率。
活动因素权衡网络如图1所示。输入层(第a层)有三个输入,第一个输入包括三个特征#distance,#walking-distance,#cost,第二个输入包括五个特征#expedite,#slow-moving,#congestion,#unknown,#duration,第三个输入包括一个特征#rating;相应地,隐藏层(第b层)也包括三个模块;接着,使用一个融合层把这三个模块合并到一起(第e层);融合层由连接层(第c层)和线性层组成(第d层);在第e层,我们得到每个poi的一个初始概率;通过第f层将kn个poi的概率进行连接,并使用softmax函数得到所有poi(动作)的概率分布(第g层)。针对日程安排问题得到一个最优的策略,使得在该策略下获得的奖励最大。
二、多轮蒙特卡罗抽样:
使用蒙特卡罗抽样对同一个用户进行循环多次采样,每一次采样都会生成同样数量的状态-动作对(s,a)和状态-动作值q(s,a)。蒙特卡罗抽样的过程如图2所示。在每一轮的采样中,首先根据用户的位置给定初始状态s0;然后通过策略网络抽样一个动作a0;接着,状态s0会转移到下一个状态s1,并以同样的方式采样另一个动作a1;这个过程持续直到状态st中的nlt为空,即此时这里没有需求了。通过一轮的采样,我们将获取到状态-动作对和状态-动作值。状态-动作值q(s,a)是预期长期折现奖励,如图2所示。γ是未来奖励的折扣率。
三、特征存储空间压缩:
每个候选poi的特征向量包括九个特征元素。通常,使用一个大小为kn*(kn+1)的矩阵来存储这些特征。其中,k表示需求个数,n表示对应一个需求的n个poi。当游戏开始时(t=0),以当前用户的位置作为起点,则具有kn个候选poi。当在时间步t=1时,用户的位置为上一步选择的poi的位置,则具有(k-1)*n个候选poi。因此,用户的初始位置和所有poi的特征关联以及所有poi之间的特征都需要进行存储,其特征存储空间大小为kn*(kn+1)。然而,对应同一个需求的n个poi不会同时被选中,因此这些poi的特征关联不需要被存储。而且,两个poi相互到达的特征是相同的,不需要重复存储。因此,我们对特征存储矩阵进行压缩,如图3所示。通过特征存储空间压缩,特征存储空间的大小从kn*(kn+1)压缩为
实施例:
一种基于深度强化学习的日程安排推荐方法,包括:
训练阶段:
步骤1:输入用户当前的位置坐标(经度和纬度)和用户需求类别数为k的需求列表nl,从poi(pointofinterest,兴趣点)数据集中读取距离用户当前位置最近的kn个候选poi的id(identitydocument,唯一标识),其中n表示为用户提供同一需求类别的poi个数;
步骤2:根据用户当前的位置和kn个候选poi的id,从poi特征数据集中读取这kn个poi的特征,其中poi的特征用一个向量表示,即:
其中,#distance表示用户当前位置与候选poi之间的距离,或在kn个候选poi中任意两个poi之间的距离;#walking-distance表示用户从当前位置到任一个候选poi需要步行的距离,或在kn个候选poi中用户从一个poi到另一个poi需要步行的距离;#cost表示用户从当前位置到任一个候选poi所需要支出的费用,或在kn个候选poi中用户从一个poi到另一个poi所需要支出的费用;#expedite表示用户当前位置与候选poi之间交通状态为畅通的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为畅通的路段在整个路段的占比;#slow-moving表示用户当前位置与候选poi之间交通状态为缓行的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为缓行的路段在整个路段的占比;#congestion表示用户当前位置与候选poi之间交通状态为拥堵的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为拥堵的路段在整个路段的占比;#unknown表示用户当前位置与候选poi之间交通状态为未知的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为未知的路段在整个路段的占比;#duration用户从当前位置到任一个候选poi所需花费的时间,或在kn个候选poi中用户从一个poi到另一个poi所需花费的时间;#rating表示用户对kn个候选poi的服务评分。然后,对所有poi的每一个特征各自进行归一化。
步骤3:设置最大训练次数为e。
步骤4:将时间步t的状态st输入到活动因素权衡网络(deepactivityfactorbalancingnetwork,dafb)中,输出候选poi的概率分布。其中,用户在时间步t的状态st=<nlt,dst,xt>,nlt是用户在时间步t的需求列表,dst是用户在时间步t的日程安排(在初始时间步t=0,ds0是一个空集),xt包含了用户在时间步t可选的
活动因素权衡网络的结构如下所示:输入层(第a层,inputlayer)有三个输入,第一个输入包括三个特征#distance,#walking-distance,#cost,第二个输入包括五个特征#expedite,#slow-moving,#congestion,#unknown,#duration,第三个输入包括一个特征#rating;相应地,线性层(第b层,linearlayer)包括对应三个输入的三个隐藏单元;接着,使用一个融合层把这三个隐藏单元的输出合并到一起(第e层);融合层由连接层(第c层,concatlayer)和线性层组成(第d层,linearlayer);在第e层(linearlayer),我们得到每个poi的初始概率;通过第f层(concatlayer)将kn个poi的概率进行连接,并使用softmax函数得到所有poi的概率分布(第g层)。
在候选poi的概率分布中,每个poi被选中的概率为:
其中st表示在时间步t的状态,at是一个表示用户在时间步t选择了一个poi的动作,
步骤5:按候选poi的概率分布随机抽样出动作at。
步骤6:根据选择的动作at,状态st转换到下一个时间步t+1的状态st+1。从状态st转换到状态st+1的详细转换过程如下所示:
其中,t是状态转移函数,poit是在时间步t选择的poi,qt表示与poit提供的服务对应的需求,
步骤7:根据当前的状态st和选择的动作at,通过以下公式来计算标量奖励:
r(st,at)=δ*(1-#cost)+(1-δ)*#rating
其中δ是一个平衡因子。然后,将时间步t的标量奖励r(st,at)存储到奖励集合r中。
步骤8:重复执行步骤4、5、6和7,直到需求列表nlt为空。
步骤9:根据日程安排dst和奖励集合r计算损失函数l(θ):
步骤10:为了获得更高的标量奖励,利用梯度下降的方法更新参数:
θt+1=θt+α▽θl(θ)
其中,θt+1和θt分别表示在时间步t+1和时间步t的参数。α表示学习率。▽θ表示对参数θ进行求导。
步骤11:跳转到步骤3,直到训练次数等于e。
应用阶段:
步骤1:输入用户当前的位置坐标(经度和纬度)和用户需求类别数为k的需求列表nl,从poi(pointofinterest,兴趣点)数据集中读取距离用户当前位置最近的kn个候选poi的id(identitydocument,唯一标识),其中n表示为用户提供同一需求类别的poi个数;
步骤2:根据用户当前的位置和kn个候选poi的id,从poi特征数据集中读取这kn个poi的特征,其中poi的特征用一个向量表示,即:
其中,#distance表示用户当前位置与候选poi之间的距离,或在kn个候选poi中任意两个poi之间的距离;#walking-distance表示用户从当前位置到任一个候选poi需要步行的距离,或在kn个候选poi中用户从一个poi到另一个poi需要步行的距离;#cost表示用户从当前位置到任一个候选poi所需要支出的费用,或在kn个候选poi中用户从一个poi到另一个poi所需要支出的费用;#expedite表示用户当前位置与候选poi之间交通状态为畅通的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为畅通的路段在整个路段的占比;#slow-moving表示用户当前位置与候选poi之间交通状态为缓行的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为缓行的路段在整个路段的占比;#congestion表示用户当前位置与候选poi之间交通状态为拥堵的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为拥堵的路段在整个路段的占比;#unknown表示用户当前位置与候选poi之间交通状态为未知的路段在整个路段的占比,或在kn个候选poi中任意两个poi之间交通状态为未知的路段在整个路段的占比;#duration用户从当前位置到任一个候选poi所需花费的时间,或在kn个候选poi中用户从一个poi到另一个poi所需花费的时间;#rating表示用户对kn个候选poi的服务评分。然后,对所有poi的每一个特征各自进行归一化。
步骤3:将时间步t的状态st输入到活动因素权衡网络(deepactivityfactorbalancingnetwork,dafb)中,输出候选poi的概率分布。其中,用户在时间步t的状态st=<nlt,dst,xt>,nlt是用户在时间步t的需求列表,dst是用户在时间步t的日程安排(在初始时间步t=0,ds0是一个空集),xt包含了用户在时间步t可选的
步骤4:按候选poi的概率分布抽样出概率最高的动作at。
步骤5:根据选择的动作at,状态st转换到下一个时间步t+1的状态st+1。从状态st转换到状态st+1的详细转换过程如下所示:
其中,t是状态转移函数,poit是在时间步t选择的poi,qt表示与poit提供的服务对应的需求,
步骤6:重复执行步骤3、4和5,直到需求列表nlt为空。最终,输出为用户推荐的日程安排dst。
仿真实验
为了验证本发明方法的有效性,使用两个真实世界的数据集(#u200chengdu和#u182beijing)进行了实验,并与现有七个基准方法做了比较,即随机选择方法(randomselect,rs),基于距离的贪心算法(greedy-#distance,g-#distance),基于交通情况的贪心算法(greedy-#expedite,g-#expedite),基于评分的贪心算法(greedy-#rating,g-#rating),基于最短距离的k近邻方法(k-nearestneighborwithshortestdistance,knn-sd),最多服务方法(mostservices,ms)和空间感知位置偏好自编码(spatial-awarelocationpreferenceauto-encoder,slp-a)。评估指标包括平均路径距离(averageroutingdistance,ard),平均花费时间(averageexecutiontime,aet)和平均服务评分(averageratingscore,ars)。
实验一
为了验证所提出的强化学习深度活动因素权衡模型(rl-dafb)的有效性,我们与七个基准方法进行对比和分析。在实验过程中,每个特征都进行了归一化预处理。表1展示了不同方法在两个真实世界数据集上的实验结果。
表1不同基准方法的定量对比结果
从表1可以很明显的看出,rs方法的随机性较大且不具有稳定性。因此,很难推荐合理的日程安排。g-#distance方法具有较低的ard和aet,表明其为用户推荐的poi都距离用户当前位置较近。然而,这些推荐的poi的服务评分都较低。g-#expedite方法和g-#distance方法相比,g-#expedite方法推荐的poi距离用户当前位置相对更远。高的ars表示g-#rating方法推荐的poi都具有较好的服务,但是相对于用户当前位置,这些poi都具有较远的距离。knn-sd方法在三个评估机制都表现不好。其原因是将poi的k个最近邻居的最短距离和作为日程安排推荐的特征是不合理的。ms方法能够推荐距离较近的poi,然而这些poi具有较低的ars。此外,ms方法在ard和aet两个评估指标上表现不稳定。和其他方法相比,slp-a方法在ars上表现相对较好,在ard和aet上表现相对较弱。rl-dafb方法推荐的poi具有最好的服务,其次这些poi的距离和所需时间都相对较小。因此,rl-dafb方法能够推荐更合理的日程安排。
实验二
为了更清楚地定量对比不同的方法,我们将ard和ars两个评估标准合并成一个值。我们将ard和1-ars看作为一个直角坐标系中的坐标点,并设计了两种方法来合并ard和ars。第一种融合方法是基于面积的方法。具体地,以坐标点(ard,1-ars),坐标原点(0,0)和坐标点(ard,0)构成的三角形的面积作为融合后的值s。当ard或1-ars小时,s小,这表示日程推荐方法具有好的性能。第二种融合方法是基于距离的方法。具体地,以坐标点(ard,1-ars)和坐标原点(0,0)之间的欧式距离作为融合后的值d。当ard或1-ars小时,d小,这表示日程推荐方法具有好的性能。
对比的结果如图4所示,rl-dafb方法在s和d上都是最好的。对于g-#distance方法,虽然在s上具有好的性能,但是其在d上表现不好。因此,该方法只侧重于特征#distance,而忽略了其它影响因素。相应地,g-#rating方法只关注特征#rating,导致其在s上表现不好。因此,所提出的rl-dafb在日程安排推荐上具有最优的性能。
实验三
日程安排的推荐过程中,我们为用户的每个需求分配了n=10个备选的poi。考虑到备选的poi的个数能影响推荐的结果,我们分别设置n为4,6,8,10和12进行了实验。实验结果如图5所示。当n=4时,poi和用户的距离较近,因此rad和aet相对较小。然而,由于可选择的poi较少,因此很难推荐服务评分高的poi,这导致ars小。当n=6时,rl-dafb可以推荐服务评分更高的poi,因此相对于n=4时,ars更高。随着n的增大,更多具有短距离和高服务评分的poi可以被选择,这使得推荐的日程安排在rad,aet和ars都表现好。然而,随着n的增大,模型训练的时间也越长。因此,选择合适的备选poi个数(如n=10)可以使得日程安排推荐的性能更好。
实验四
本文提出的rl-dafb方法能够推荐需求个数不同的日程安排。显然,需求个数越多,备选的poi越多,日程安排推荐的复杂性也越高。为了研究需求个数对日程安排推荐结果的影响,我们分析了不同需求个数下的日程安排推荐结果。我们将数据按需求个数(k分别为2,3,4,5,6和7)划分为六个部分,然后在每个部分中选择相同数量的数据进行实验。实验的结果如图6所示。我们可以得出所提出的rl-dafb方法在ard,aet和ars上都具有较好的性能,这表明了模型的强健性,其不会受到需求个数的变化而性能变得很差。此外,随着k的增大,ard和aet稍微增大。这表明了日程安排推荐的复杂性随着k的增大而增大,因为rl-dafb方法会探索距离更远的一些poi以获得更优的日程安排。然而,rl-darb在ars依然保持着好的结果。因此,所提出的rl-dafb方法在需求个数不同的情况下同样具有好的性能。
- 还没有人留言评论。精彩留言会获得点赞!