本发明涉及知识图谱实体链接领域,具体地,涉及一种基于上下文语义关系和文档一致性约束的实体链接方法。
背景技术:
近年来,随着人工智能技术的迅猛发展,如何通过自然语言处理技术(nlp)让机器实现人类语言理解受到众多学者的关注。而如何训练计算机识别文本中的实体,并将实体正确无误的链接到数据库中,这是让计算机理解人类语言的关键步骤。实体链接(entitylinking,el)是指挖掘人类语言文本出现的潜在实体关系,并链接到所在的知识图谱实体上,解决实体间存在歧义性(即一词多义)和多样性(即多词一义)的任务。常用于知识图谱的构建、信息事件抽取和智能问答等应用中。目前传统的实体链接模型往往依赖于海量的文本标注,存在着需要消耗大量人工、大量时间、大量金钱的问题、且存在受限于语言和无法快速规模化的困难。如何利用自然语言处理技术、机器学习技术(ml)和深度学习技术(dl)等前沿方法,自动或者高效进行实体关系的链接,成为了当前亟需攻克的问题。因此,实体链接的方法研究得到了世界范围内研究人员的广泛关注。
技术实现要素:
本发明为了解决现有技术中的不足,依托上下文语义关系以及文档一致性匹配模型,提出了一种基于上下文语义关系和文档一致性约束的实体链接方法。
一种基于上下文语义关系和文档一致性约束的实体链接方法:所述方法包括以下步骤:
a、数据预处理:对实验数据集中选择未标记的文档和维基百科数据进行预处理,因为当使用多个数据集时候,会存在以下两个问题:多个数据集的数据组织格式不统一;部分数据集的实体标注不完整;
b、候选实体生成:因为本步骤最初所选择的候选实体集合的锚定实体信息都来源于维基百科,所以通过维基百科来产生弱监督,通过将候选实体生成分为两个候选实体,来筛选得到高召回率的候选实体集:先使用ganeaandhofmann预处理技术进行粗召回,再创建连接图进行精召回;
c、候选实体消歧:将步骤b获得的候选实体消歧,本步骤不仅需要考虑实体与其局部上下文之间的关系,而且还要考虑在文档中实体与实体之间的连贯性;从这两个方面进行建模,根据得分高的作为候选实体集合中的正确选项。
进一步地,所述步骤a包括以下步骤:
a1、针对实体标注不完整数据进行补全:针对原始的conll2003数据集包含的英语部分,将对语言无关的命名实体进行识别并剔除;通过实体嵌入,使用deep-ed预训练技术的word2vec来提取300维词向量;
a2、部分数据集的实体标注不完整,需要通过wikipedia、yago、freebase知识图谱进行实体标注。
进一步地,所述步骤b包括以下步骤:
b1、使用ganeaandhofmann预处理技术进行粗召回:
将步骤a得到的候选列表进行过滤,ganeaandhofmann预处理技术使用一个模型,来衡量在嵌入空间中实体e、指代跨度m、及其周围的上下文窗口c中的单词w之间的相似度q为;
是对实体e和单词w的外部词嵌入,p为实验结合准确率,则有根据pwiki(e|m)提取前4个分数最高的候选,nq=4;根据qwiki(e|m,c)选择3个分数最高的候选nq=3,此时召回率r为97.2%;
最少需要两个候选实体集合列表才能保持高的召回率;
b2、使用wikipedia链接统计进一步减少候选实体列表,创建一个连接图进行精召回,实体作为所述连接图中的顶点;所述连接图定义了概率图模型的结构,本步骤用该连接图来对候选实体列表进行排名;本步骤只为每个指代实体选择最高的候选实体,并且仍然保持较高的召回率;
b21、进行无向图构建,从wikipedia中构建无向图,图中的顶点为wikipedia实体;链接顶点eu和ev,需要满足如下条件:
(1)d为wikipedia的文章描述,且eu和ev同时出现在文章中mi;
(2)d包含eu和ev,且eu和ev的距离小于l个实体;
b22、进行模型优化,考虑未标记(非维基百科)的文档;因此本步骤在优化训练文档的同时,也在测试时优化新的未贴标签的文档;
因此,为文档d中的每个指代实体mi最多生成nq+np个候选者,将文档d中的实体定义一个概率模型:
如果ei和ej在连接图中被链接,则否认为大于0的正数;因为该模型根据分配中未链接实体对的数量评分实体e1,...,en;使用lbp的max-product版本来产生近似边际:.
候选数量的一个根据rwiki(ei|d)排序的函数;将候选集从nq+np=7到nw=2保持了93.9%的召回率;这个遗留的nq+np-nw实体被作为负样本ei去训练消歧模型。
进一步地,所述步骤c包括以下步骤:
c1、计算实体上下文得分,通过实体上下文得分进行候选实体与文章局部相关性筛选;选择得分较高的候选实体;
mi为指代实体,ci为围绕该指代实体的上下文窗口,ξ(ei,ej)是成对的兼容性评分即相似性,αij是注意力权重,衡量位置j处的实体相对于预测实体ei的相关性,其中本地分数φ与ganeaandhofmann预处理技术中使用的分数相同,兼容性分数计算公式为:
c2、计算实体相关性得分,通过实体相关性计算实体与全文的匹配度关系,选择得分较高的候选实体,xei和xej∈rde是外部实体嵌入,使用外部的词嵌入得到,是对角矩阵;注意力权重计算公式:
其中,a属于是一个对角矩阵,函数h(mi,ci)将文档指代的实体与上下文映射到空间,选择得分较高的候选实体作为候选实体集合中的正确选项。
本发明有益效果
(1)本发明将候选实体生成任务采用wikipedia创建一个连接图,并进行候选实体召回。
(2)本发明候选实体消歧的目标设定为不仅需要考虑实体与其局部上下文之间的关系,而且还要考虑在文档中实体与实体之间的连贯性。
(3)本发明通过弱监督学习的方法减少人工标注,降低成本。
附图说明
图1为本发明的基于上下文语义关系和文档一致性约束的实体链接方法的流程图;
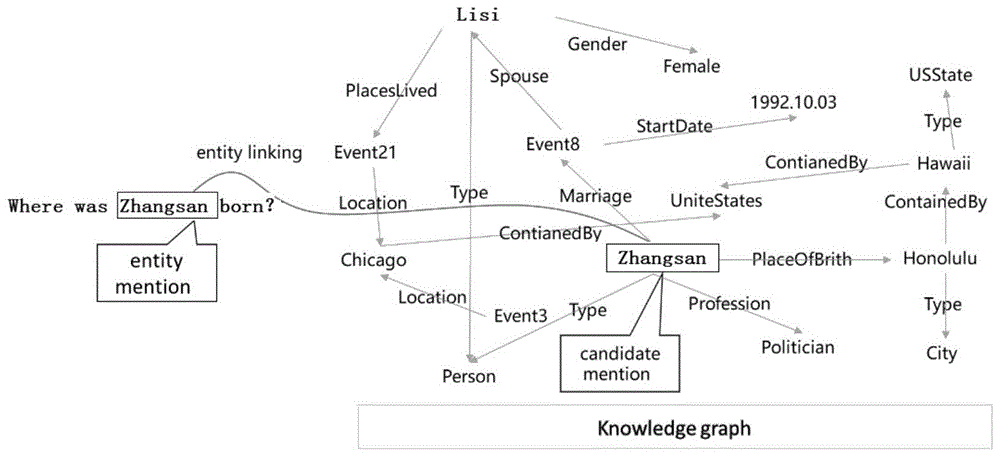
图2为实体连接在知识图谱问答系统中回答关于“obama”问题的应用;
图3为本发明的无向连接图构建示意图;
图4为本发明的候选列表个数与召回率关系图;
图5为本发明的候选实体消歧算法示意图;
图6为本发明中h(mi,ci)生成方式示意图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
以实体链接技术在知识图谱问答场景下的一个示例,来介绍其具体的研究场景和应用价值。如图2所示,针对问答场景下的问题“wherewaszhangsanborn?”实体链接系统将问题单词“zhangsan”作为一个实体指代,并将“zhangsan”映射到知识图谱“barackzhangsan”上。
一种基于上下文语义关系和文档一致性约束的实体链接方法:所述方法包括以下步骤:
a、数据预处理:对实验数据集中选择未标记的文档和维基百科数据进行预处理,因为当使用多个数据集时候,会存在以下两个问题:多个数据集的数据组织格式不统一;部分数据集的实体标注不完整;
b、候选实体生成:因为本步骤最初所选择的候选实体集合的锚定实体信息都来源于维基百科,所以通过维基百科来产生弱监督,通过将候选实体生成分为两个候选实体,来筛选得到高召回率的候选实体集:先使用ganeaandhofmann预处理技术进行粗召回,再创建连接图进行精召回;
c、候选实体消歧:将步骤b获得的候选实体消歧,本步骤不仅需要考虑实体与其局部上下文之间的关系,而且还要考虑在文档中实体与实体之间的连贯性;从这两个方面进行建模,根据得分高的作为候选实体集合中的正确选项。
所述步骤a包括以下步骤:
a1、针对实体标注不完整数据进行补全:针对原始的conll2003数据集包含的英语部分,将对语言无关的命名实体进行识别并剔除;通过实体嵌入,使用deep-ed预训练技术的word2vec来提取300维词向量;
a2、部分数据集的实体标注不完整,需要通过wikipedia、yago、freebase知识图谱进行实体标注。
所述步骤b包括以下步骤:
b1、使用ganeaandhofmann预处理技术进行粗召回:
将步骤a得到的候选列表进行过滤,ganeaandhofmann预处理技术使用一个模型,来衡量在嵌入空间中实体e、指代跨度m、及其周围的上下文窗口c中的单词w之间的相似度;
是对嵌入空间中实体e和单词w的外部词嵌入,根据pwiki(e|m)提取前4个分数最高的候选,nq=4;根据qwiki(e|m,c)选择3个分数最高的候选nq=3,此时召回率为97.2%;
因为小的候选实体集合缺乏足够的约束力,无法约束潜在分配的空间推动实体歧义消除模型进行特征学习,所以小的候选实体合集对于弱监督学习是无效的;
因此进行粗召回之后,候选实体集合的列表必须保持相当大,最少需要两个候选实体集合列表才能保持较高的召回率;
b2、使用wikipedia链接统计进一步减少候选实体列表,创建一个连接图进行精召回,实体作为所述连接图中的顶点;所述连接图定义了概率图模型的结构,本步骤用该连接图来对候选实体列表进行排名;本步骤只为每个指代实体选择最高的候选实体,并且仍然保持较高的召回率;
b21、进行无向图构建,从wikipedia中构建无向图,图中的顶点为wikipedia实体;链接顶点eu和ev,需要满足如下条件:
(1)d为wikipedia的文档描述,且eu和ev同时出现在文档中mi;
(2)d包含eu和ev,且eu和ev的距离小于l个实体。
如图3所示,在文档中“brexit”,模型将实体brexit连接到所有其他实体上,但是模型未将unitedkingdom和greekwithdrawalfromeurozone连接起来,原因是它们的距离超过了l个实体。
b22、进行模型优化,考虑未标记(非维基百科)的文档;因此本步骤在优化训练文档的同时,也在测试时优化新的未贴标签的文档;
因此,为文档d中的每个指代实体mi最多生成nq+np个候选者,将文档d中的实体定义一个概率模型:
如果ei和ej在连接图中被链接,则否认为大于0的正数;因为该模型根据分配中未链接实体对的数量评分实体e1,...,en;使用lbp的max-product版本来产生近似边际:.
如图4所示,绘制了在aidaconll验证集上,候选数量的一个函数(根据rwiki(ei|d)排序);可以看到把候选集从nq+np=7到nw=2保持了93.9%的召回率;这个遗留的(nq+np-nw)实体被作为负样本ei去训练消歧模型。
所述步骤c包括以下步骤:
c1、计算实体上下文得分,通过实体上下文得分进行候选实体与文章局部相关性筛选;选择得分较高的候选实体;
mi为指代实体,ci为围绕该指代实体的上下文窗口,ξ(ei,ej)是成对的兼容性评分即相似性,αij是注意力权重,衡量位置j处的实体相对于预测实体ei的相关性,其中本地分数φ与ganeaandhofmann预处理技术中使用的分数相同,兼容性分数计算公式为:
c2、计算实体相关性得分,通过实体相关性计算实体与全文的匹配度关系,选择得分较高的候选实体,xei和xej∈rde是外部实体嵌入,使用外部的词嵌入得到,是对角矩阵;注意力权重计算公式:
其中,a属于是一个对角矩阵,函数h(mi,ci)将文档指代的实体与上下文映射到空间,选择得分较高的候选实体作为候选实体集合中的正确选项。
以上对本发明所提出的一种基于上下文语义关系和文档一致性约束的实体链接方法,进行了详细介绍,本文中应用了数值模拟算例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。