基于机器学习和FFT的盲源分离信源数目并行估计方法
本发明属于混合声信号盲源分离中的信源估计技术领域,具体地说,涉及一种基于机器学习和fft的盲源分离信源数目并行估计方法。
背景技术:
盲源分离是在未知任何有关源信号和混合过程的先验信息的情形下,仅根据混合信号有效恢复出源信号的过程。盲源分离实现有效分离的重要前提之一是源信号数目预先已知或准确估计。而在实际情况中,难以预先已知信源数目;因此,在进行盲源分离前,必须准确估计源信号数目。
常用的估计信源数目的方法是将信号简单去噪以后,利用fft将信号变换到频域,然后肉眼观察频域的幅值,幅值较大的点是对应的源信号,有几个点则对应几个源信号。左超华提出一种欠定混合情形下的信源数目盲估计方法,该方法对接收信号去噪后,基于经验模态分解,结合协方差矩阵的奇异值分解,采用拉氏逼近的贝叶斯选择原理来估计源信号数目,但是该方法跟信号的去噪效果有关,在去噪效果较差情况下算法准确率不高;冷巨昕提出利用高阶累积量来估计信源数目的方法,通过利用高阶累积量的扩展特性提高估计的分辨性能,并将优化方法用于基于高阶累积量的源数目估计中,但是该方法鲁棒性较差,易受信源模型、传播环境等多个因素的影响从而性能下降。
总体来看,当前信源估计方法仍然存在鲁棒性差的问题,容易受环境影响造成重大误差,从而影响信源数目估计的准确性。
技术实现要素:
本发明提出了一种基于机器学习和fft的盲源分离信源数目并行估计方法,以解决上述问题。
为实现上述发明目的,本发明采用下述技术方案予以实现:
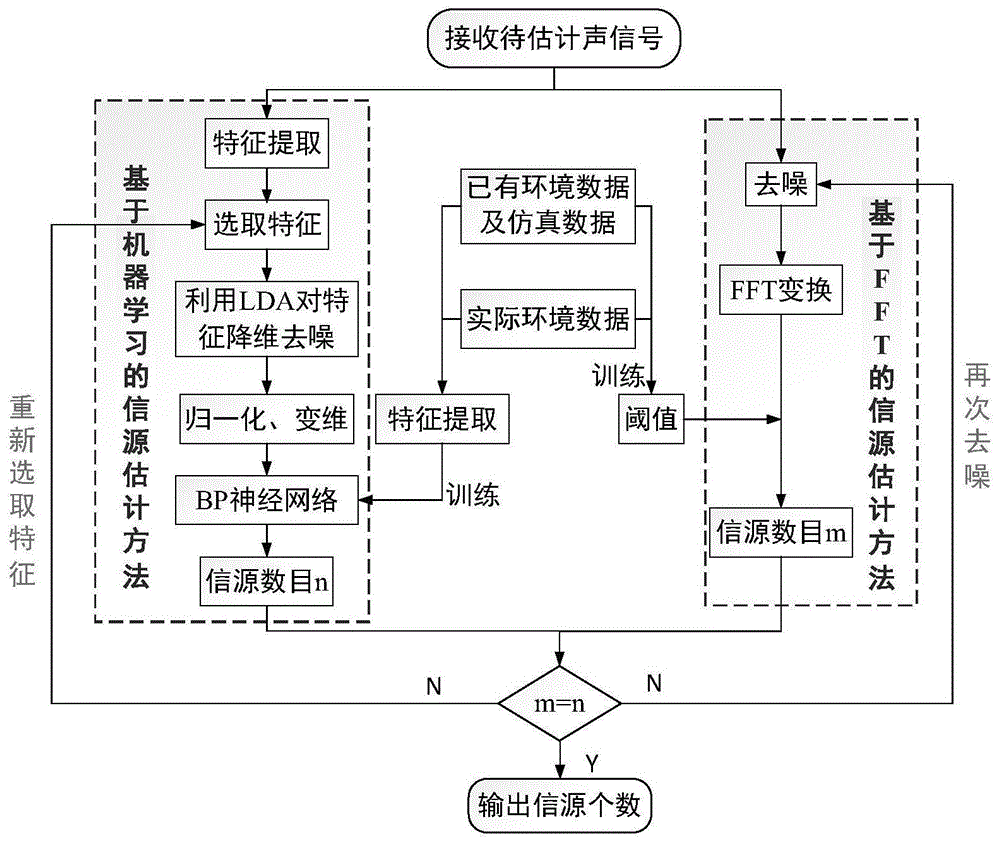
一种基于机器学习和fft的盲源分离信源数目并行估计方法,包括以下步骤:
s1:接收待估计的信号数据,同时提取m个信号相关特征和对信号进行去噪;
s2:在s1提取的m个信号特征中随机选取t个特征(其中1≤t≤m),对该t个信号特征进行降维;
s3:提取已有环境数据、仿真数据和实际环境数据的特征来训练bp神经网络和判断阈值;
s4:对s2降维后的信号特征进行归一化和变维后输入bp神经网络,训练后的神经网络根据特征进行分类,最后输出类别为估计的信源数目c1;
s5:对s1去噪后的信号进行快速傅里叶变换(fft),利用判断阈值来估计信源得到信源数目c2;
s6:通过判断c1和c2值,若c1和c2相等时,即输出该信源数目;若两者不相等,重新估计c1和c2值,直至相等,输出。
进一步的,所述s1具体如下:
s1-1:提取所述相关信号特征:
信号香农熵和指数熵、相位谱香农熵和指数熵、频谱香农熵和指数熵、信号均差香农熵和指数熵、小波能量香农熵和指数熵、功率谱香农熵和指数熵、奇异谱香农熵和指数熵、信号绝对值的方差与均值之比、零中心归一化瞬时幅度的谱密度的最大值、零中心归一化瞬时幅度绝对值的标准偏差、信号绝对值的方差等;
s1-2:利用softsure阈值规则对接收信号进行去噪。
进一步的,所述s2具体如下:
s2-1:选取信号特征:
在m个信号相关特征中随机选取t(其中1≤t≤m)个特征作为输入bp神经网络的特征分量;
s2-2:利用线性判别分析法(lda)对上述信号特征进行降维,降维后的样本有更好的分类性能。
更进一步的,线性判别分析法(lda)对上述信号特征进行降维的具体步骤为:
输入:数据集d={(x1,y1),(x2,y2),...,(xm,ym)},其中任意样本xi为n维向量,yi={c1,c2,...,ck},k表示共有k类样本;降维到的维度d。
输出:降维后的样本集d'
1)计算类内散度矩阵sω;
2)计算类间散度矩阵sb;
3)计算矩阵sω-1sb;
4)计算sω-1sb的最大的d个特征值和对应的d个特征向量(ω1,ω2,...,ωd),得到投影矩阵w;
5)对样本集中的每一个样本特征xi,转化为新的样本zi=wtxi;
6)得到输出样本集d'={(z1,y1),(z2,y2),...,(zm,ym)}。
进一步的,所述s3具体如下:
s3-1:提取已有环境数据、仿真数据和实际环境数据的特征来训练bp神经网络;
s3-2:提取已有环境数据、仿真数据和实际环境数据的特征来确定判断阈值。
进一步的,所述s6具体如下:比较比较和c2大小,如果c1=c2,输出信源数目c=c1(或c=c2);如果c1≠c2,则返回s2-1重新选取信号特征,再利用s4估计信源数目c1,及返回s1-2对信号再进行去噪,再通过s5得到信源数目c2,重复操作直至c1=c2,输出信源数目。
上述方法能够应用于盲源分离中的声音信源估计。
本发明的优点和技术效果:
本发明针对混合信号,尤其是声信号,利用传统的fft变换方法,并结合机器学习算法来估计信源数目,bp算法能够获得更准确的信源数目,提高接收信号的准确性,并行判断方法增加了算法的鲁棒性,使得其抗噪声性能更好,保证了后续的盲源分离过程的有效性。
本发明通过优化方法来提高算法的准确率,最终得到准确的信源数目,实现了盲源分离中的信源有效估计,提高了信源估计的鲁棒性。
附图说明
图1是本发明的具体流程图;
图2是实施例1中高信噪比下根据信号幅值观测信源数目图;
图3是实施例1中低信噪比或者去噪效果差时根据信号幅值观测信源数目图;
图4是实施例1中的bp神经网络拓扑结构图;
图5是实施例1中的基于bp神经网络的声特征信号分类算法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下将结合附图和实施例,对本发明作进一步详细说明。
实施例1:
在信号的盲源分离过程中,由于信源数目未知,容易造成分离结果不准确的问题,为了提高盲源分离结果的有效性,首先对信源的数目进行估计,为了能够准确估计信源数。目前信源估计是通过去噪后直接观察的方法,如图2所示,可以通过肉眼简单观测出有3个源信号。然而在信噪比较低或者是对接收信号去噪效果比较差的情况下,仅凭肉眼观测不能看出信源数目,如图3所示。即,利用fft变换将信号变换到频域,观察频域的幅度来判断信源数目。由于在低信噪比的情况下,这种方法存在观测结果不准确,且受主观因素影响等问题。如何利用客观科学方法估计信源数目,得到准确的信源数目信息,是本实施例要解决的技术问题。
本实施例提出了一种基于机器学习和fft变换的盲源分离信源数目并行估计方法,具体模型如图1所示。
本实施例提出了一种基于机器学习和fft变换的盲源分离信源数目并行估计方法,以声信号为例,本实施例包括以下步骤:
s1:接收待估计的声信号,同时提取m个信号相关特征和对信号进行去噪,具体步骤如下:
s1-1:提取信号的特征:
相关信号特征有,信号香农熵和指数熵、相位谱香农熵和指数熵、频谱香农熵和指数熵、信号均差香农熵和指数熵、小波能量香农熵和指数熵、功率谱香农熵和指数熵、奇异谱香农熵和指数熵、信号绝对值的方差与均值之比、零中心归一化瞬时幅度的谱密度的最大值、零中心归一化瞬时幅度绝对值的标准偏差、信号绝对值的方差等,其具体的数学表示为:
香农熵:
指数熵:
其中p(xi)表示随机变量xi出现的概率。
s1-2:利用softsure阈值规则对接收信号进行去噪。
s2:在已经提取的信号特征中随机选取t个特征(其中1≤t≤m),并利用线性判别分析法(lda)对该t个信号特征进行降维,降维后的样本有更好的分类性能,具体步骤如下:
s2-1:选取信号特征:
在m个特征中随机选取t(其中1≤t≤m)个特征作为输入bp神经网络的特征分量;
s2-2:利用线性判别分析法(lda)对信号特征进行降维:
利用线性判别分析法(lda)对信号进行降维,降维后的样本有更好的分类性能。
具体步骤为:
输入:数据集d={(x1,y1),(x2,y2),...,(xm,ym)},其中任意样本xi为n维向量,yi={c1,c2,...,ck},k表示共有k类样本;降维到的维度d。
输出:降维后的样本集d'
1)计算类内散度矩阵sω;
2)计算类间散度矩阵sb;
3)计算矩阵sω-1sb;
4)计算sω-1sb的最大的d个特征值和对应的d个特征向量(ω1,ω2,...,ωd),得到投影矩阵w;
5)对样本集中的每一个样本特征xi,转化为新的样本zi=wtxi;
6)得到输出样本集d'={(z1,y1),(z2,y2),...,(zm,ym)}。
s3:提取已有环境数据、仿真数据和实际环境数据的特征来训练bp神经网络和判断阈值,具体步骤如下:
s3-1:提取已有环境数据、仿真数据和实际环境数据的特征来训练bp神经网络。bp神经网络的拓扑结构如图4所示,其中,x1,x2,...,xn是bp网络的输入值,y1,y2,...,yn是bp神经网络的预测值,ωij和ωjk为bp神经网络的权值。bp神经网络预测前首先要训练网络,通过训练使网络具有联想记忆和预测能力。bp神经网络的训练过程的步骤为:
步1、网络初始化。根据系统输入输出序列(x,y)确定网络输入层节点数p、隐含层节点数l,输出层节点数q,初始化输入层、隐含层和输出层神经元之间的连接权值ωij和ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数;
步2、隐含层输出计算。根据输入变量x,输入层和隐含层连接权值ωij以及隐含层阈值a,计算隐含层输出h:
式中,l为隐含层节点数,f为隐含层激励函数,该函数有多种表达形式;选用sigmoid函数:
步3、输出层计算。根据隐含层输出h,连接权重ωjk和阈值b,计算bp神经网络预测输出o。
步4、误差计算,根据网络预测输出o和期望输出y,计算网络预测误差e:
ek=yk-okk=1,2,...,q;
步5、权值更新,根据网络预测误差e更新网络连接权值ωij和ωjk:
ωjk=ωjk+ηhjekj=1,2,...,l;k=1,2,...,q
式中,η为学习率。;
步6、阈值更新,根据网络预测误差e更新节点阈值a,b:
bk=bk+ekk=1,...,q
步7、判断算法迭代是否结束,若没有结束,返回步骤2。
具体的训练及分类过程如图5所示。
s3-2:提取已有环境数据、仿真数据和实际环境数据的特征来确定判断阈值;
s4:对降维的信号特征进行归一化和变维后输入bp神经网络,训练后的神经网络根据特征进行分类,最后输出类别为估计的信源数目c1;
s5:对去噪的信号进行快速傅里叶变换(fft),利用判断阈值来估计信源得到信源数目c2,具体步骤如下:
s5-1:首先对信号进行fft变换;
s5-2:根据已有环境数据、仿真数据和实际环境数据的特征确定的判断阈值,对fft变换后的信号的幅值进行判断,如果幅值超过了阈值,则认为它是一个信源,幅值未超过阈值,则认为它是噪声;
s6:通过比较c1和c2是否相等,最终得到输出的信源数目或者重新估计c1、c2,具体步骤如下:
s6-1:判断c1和c2是否相等,
s6-2:若c1=c2,则输出的信源数目c=c1(或c=c2);若c1≠c2,则对信号重新去噪后进行fft变换判断幅值重新估计信源数c2、并重新选取特征输入bp神经网络进行信号分类估计信源数c1,直至c1≠c2。
基于机器学习的信源数目估计方法流程图如图1所示,伪代码如下;
本发明提出的bp神经网络和fft变换方法并行的盲源分离信源数目估计方法能够对信源数目进行有效的估计,提高了方法的鲁棒性,增强了准确度,为盲源分离的有效进行创造了先验条件。
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!