用于深度学习加速的池化单元的制作方法
本公开总体上涉及在电子系统中实现的卷积神经网络。
背景技术:
深度学习算法在涉及识别、标识和/或分类任务的许多应用中促进了非常高的性能,然而,这种进步可能以处理能力方面的显著需求为代价。因此,由于缺乏低成本和节能的解决方案,它们的采用可能会受到阻碍。因此,当在嵌入式设备上部署深度学习应用时,严格的性能规范可以与功耗和能耗方面的严格限制共存。
技术实现要素:
一个实施例是一种卷积神经网络的池化单元。池化单元包括裁剪器,裁剪器被配置为接收特征张量并通过裁剪特征张量来生成包括多个数据值的经裁剪的特征张量。池化单元包括:行缓冲器(linebuffer),被配置为从裁剪器接收数据值;列计算器,被配置为对来自行缓冲器的数据列执行列池化操作;以及行计算器(rowcalculator),被配置为对来自列计算器的数据行执行行池化操作。
一个实施例是一种方法,该方法包括在卷积神经网络的池化单元中接收特征张量,以及通过利用池化单元的裁剪器裁剪特征张量来生成包括多个数据值的经裁剪的特征张量。该方法包括将经裁剪的特征张量的数据值传递给池化单元的单端口行缓冲器。该方法包括通过对来自行缓冲器的数据值执行列池化计算和行池化计算来生成经池化的特征数据
一个实施例是一种方法。该方法包括:在卷积神经网络的池化单元中接收特征张量,在池化单元的配置寄存器中存储池化窗口尺寸数据,以及根据池化窗口尺寸数据,利用池化单元从特征张量生成多个池化窗口。该方法包括通过对来自池化窗口的数据值执行列池化计算和行池化计算来生成经池化的特征数据。
附图说明
图1是根据一个实施例的电子设备的框图。
图2是根据一个实施例的卷积神经网络内的处理流程的框图。
图3是根据一个实施例的特征张量的表示。
图4是根据一个实施例的池化单元的框图。
图5a是根据一个实施例的由裁剪器执行的裁剪操作的示意图。
图5b是根据一个实施例的裁剪器的裁剪操作的示意图。
图6a是根据一个实施例的池化单元的行缓冲器的示意图。
图6b示出了根据一个实施例的池化单元的行缓冲器的操作。
图7a示出了根据一个实施例的池化单元的填充控制的操作。
图7b是根据一个实施例的池化单元的列计算器的示意图。
图8示出了根据一个实施例的池化单元的批量缓冲器的操作。
图9示出了根据一个实施例的池化单元的批量缓冲器和行计算器的操作。
图10示出了根据一个实施例的由池化单元执行的池化操作。
图11是根据一个实施例的用于操作卷积神经网络的方法的流程图。
图12是根据一个实施例的用于操作卷积神经网络的方法的流程图。
具体实施方式
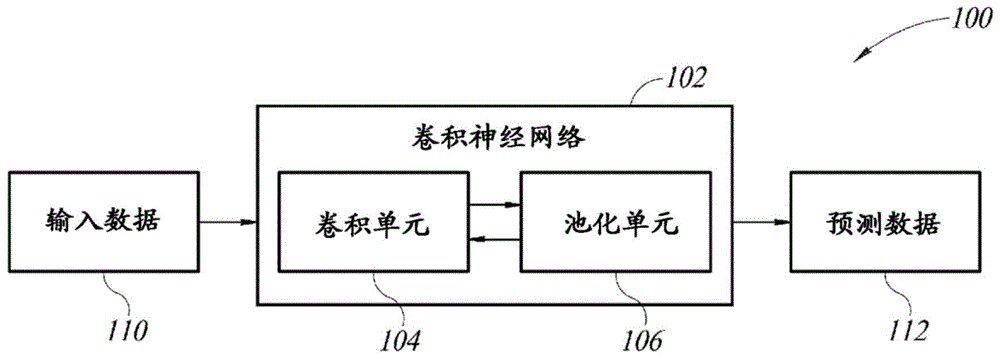
图1是根据一个实施例的电子设备100的框图。电子设备100包括卷积神经网络(cnn)102。cnn102接收输入数据110,并基于输入数据110生成预测数据112。cnn102通过对输入数据110执行一个或多个卷积操作来生成预测数据112。
在一个实施例中,输入数据110由电子设备100的图像传感器(未示出)或另一类型的传感器提供。因此,输入数据110可以包括与由图像传感器捕获的一个或多个图像对应的图像数据。对图像数据进行格式化以使其能够被cnn102接收。cnn102分析输入数据110并生成预测数据112。预测数据112指示与图像数据的一个或多个方面相关的预测或分类。预测数据112可以对应于识别图像的形状、对象、面或其它方面。尽管本文中的一些实施例描述了从传感器或传感器系统接收输入数据110,但是在不背离本公开的范围的情况下,可以从其他类型的系统或设备接收输入数据110。例如,输入数据110可以包括如下的数据结构,该数据结构被存储在存储器中并且包含由外部cpu收集和存储的统计数据。在不背离本公开的范围的情况下,可以使用其他类型的输入数据110。
在一个实施例中,通过机器学习过程来训练cnn102,以识别提供给cnn102的训练图像的方面。机器学习过程包括将具有已知特征的多个训练图像传递给cnn。机器学习过程训练cnn102以生成准确地预测或分类训练图像的特征的预测数据。训练过程可以包括深度学习过程。
cnn102包括多个卷积单元104和池化单元106。卷积单元104实现cnn102的卷积层。因此,每个卷积单元是执行与卷积层对应的卷积操作的硬件块。池化单元106实现卷积层之间的池化功能。卷积单元104和池化单元106协作从输入数据110生成预测数据112。
在一个实施例中,每个卷积单元104包括卷积加速器。每个卷积单元104对被提供给卷积单元104的特征数据执行卷积操作。从输入数据110生成特征数据。卷积层处的卷积操作将特征数据与在用于cnn102的机器学习过程期间生成的核数据卷积。卷积操作产生的特征数据根据核数据而变化。新的特征数据从一个卷积单元104被提供给下一个卷积单元104。
在卷积层之间对特征数据执行池化操作。当特征数据从一个卷积层被传递到下一个卷积层时,对特征数据执行池化操作以准备用于下一个卷积层的卷积操作的特征数据。池化单元106执行卷积层之间的池化操作。池化单元106用于加速卷积神经网络操作。池化单元106可以执行最大池化操作、最小池化操作、平均池化操作或其他类型的池化操作。
卷积层的输出是张量或一系列传感器。张量类似于矩阵,因为它们包括在各种数据字段中具有数据值的多个行和列。池化操作获取特征张量的一部分(诸如池化窗口),并生成与池化操作相比维度减小的池化子张量。通过对来自特征张量的多个数据字段执行特定类型的数学运算(诸如从这些数据字段中取最大值、最小值或平均值)来生成池化子张量中的每个数据字段。在特征张量的每个部分上执行池化操作。各种池化张量被传递到下一个卷积层作为该卷积层的特征张量。因此,池化有助于减少用于下一卷积操作的数据,并安排用于下一卷积操作的数据。
为了简单起见,图1的cnn102仅示出了池化单元106中的卷积单元104。然而,在实践中,cnn102可以包括许多其它硬件块,这些其它硬件块可以包括批量归一化块、缩放块、偏置块、归一化块、激活块、以及执行各种操作的其它类型的硬件块作为cnn102的一部分。
图2是根据一个实施例的cnn102内的处理流程的简化框图。
cnn102包括输入层120、多个卷积层105、以及一个或多个连接层
121。输入数据110被提供给输入层120并且通过各种卷积层104和全连接层121。最后的全连接层的输出是预测数据112。
每个卷积层105对输入数据110或者对由cnn102的前一层从输入数据110生成的数据执行一系列卷积操作。特别地,核数据与每个卷积层105相关联。每个卷积层105在该卷积层105的核数据与被提供给卷积层105的特征数据之间执行卷积操作。特征数据来源于输入数据110。
在一个实施例中,第一卷积层105从输入层120接收特征数据。第一卷积层105的特征数据是输入数据110。第一卷积层105通过在输入数据110的特征张量与张量数据的核张量(kerneltensors)之间执行卷积操作,来从输入数据110生成特征数据。然后,第一卷积层将特征数据传递给第二卷积层105。如本文所使用的,每个卷积层105接收特征数据并将特征数据与核数据卷积,该卷积操作的输出在本文中也被称为特征数据。因此,每个卷积层105接收特征数据并基于卷积操作生成调节后的特征数据。该调节后的特征数据随后被传递到下一卷积层105,该卷积层105通过对特征数据执行卷积操作来进一步调节特征数据。
对每个卷积层之间的特征数据执行池化操作107。如上所述,池化操作通过对特征数据执行算术运算来降低特征数据的维数。池化操作还为下一卷积层105的卷积操作准备和组织特征数据。池化单元106执行池化操作107。
该卷积和池化过程重复,直到最后的卷积层107对所接收的特征数据执行卷积操作为止。对来自最后的卷积层105的特征数据执行池化操作107。然后,将特征数据提供给全连接层122。然后,全连接层122从特征数据生成预测数据112。在一个实施例中,池化操作生成经池化的特征数据。
在实践中,cnn102包括图2中所示的过程以外的其它过程。特别地,cnn102可以包括批量归一化操作、缩放操作、偏置操作、归一化操作、激活操作和其他类型的操作。此外,在不背离本公开的范围的情况下,可以将池化操作的输出提供给除卷积层以外的进程、层、模块或组件。
图3是根据一个实施例的特征张量128的表示。特征张量128包括多个块。这些块中的每个块代表一个数据值。张量128包括高度、宽度和深度。尽管图3的特征张量128示出了5x5x5张量,但在实践中,特征张量128可以包括其他高度、宽度和深度维度。
在一个实施例中,在池化操作期间,将特征张量128划分为批量(batch)。特征张量120按深度修补。对来自特征张量的批量执行池化操作。对来自每个批量的子张量执行池化操作。因此,每个批量被划分为多个子张量。
图4是根据一个实施例的池化单元106的框图。池化单元106作为构成cnn102的硬件块的一部分。池化单元106包括流过滤器142、裁剪器144、行缓冲器146、填充控制148、列计算器150、批量缓冲器152、行计算器154、复用器156、平均乘法器级158、跨步管理器(stridemanager)160、复用器162、以及非池化单元163。输入流链路141向池化单元106提供数据。池化单元106将数据输出到输出流链路165。配置寄存器164存储池化单元106的配置数据。池化单元106在cnn102的卷积层之间执行池化操作。
池化单元106的输入是被划分为称为批量的子张量的3d特征张量128。3d特征张量128经由输入流链路141流入池化单元106。可以在设计时配置流链路141的宽度,从而配置流链路141中携带的数据的最大宽度。
在一个实施例中,池化单元106在输入处包括流过滤器142。流过滤器接收特征张量数据128。流过滤器142确保只有经验证的流被输入到池化单元106。在一个实施例中,流过滤器142可以用先进先出(fifo)缓冲器来扩充,以缓冲来自流链路141的输入数据。
在一个实施例中,特征张量128从流链路141被读入池化单元106,首先是深度,然后是宽度从左到右,并且最后是高度从上到下。因此,在一个实施例中,以经典光栅之字形扫描顺序在宽度和高度上读取数据。
在一个实施例中,裁剪器144被配置为裁剪输入特征张量128。在某些情况下,可能仅对特征张量128的某些部分执行池化操作。裁剪器144可以被配置为裁剪特征张量128,以仅提取特征张量128中的如下部分,将对该部分执行池化操作。
图5a是根据一个实施例的由裁剪器144执行的裁剪操作的示意图。特征张量128被输入到裁剪器144。裁剪器144从输入特征张量128生成经裁剪的特征张量168。
用户可以经由配置寄存器164选择经裁剪的张量168的维度。特别地,可以将数据写入配置寄存器164,该配置寄存器164指示裁剪器144应当如何裁剪输入特征张量128。因此,配置寄存器包括用于裁剪器144的专用配置数据。配置寄存器可以被设置有用于裁剪特征张量128的高度索引、宽度索引和深度索引。
图5b是根据一个实施例的裁剪器144的裁剪操作的示意图。特征张量128由索引1a至9c表示,每个索引表示特征张量128内的数据位置。图5b还示出了在特征张量128上执行裁剪操作将产生的结果。
图5b还包括特征张量128和经裁剪的张量168的展平表示。展平表示将三维特征张量128和经裁剪的张量168表示为二维张量。
图6a是根据一个实施例的图4的池化单元106的行缓冲器146的示意图。行缓冲器146从裁剪器144接收输入流。来自裁剪器144的输入流对应于经裁剪的特征张量168。备选地,如果裁剪器144未被配置为裁剪特征张量128,则来自裁剪器144的输入流可以是特征张量128。图6a中所示的输入流对应于图5b的经裁剪的张量168的索引。
从池化单元106的内部存储器组织行缓冲器146。行缓冲器146缓冲存储器中的输入的水平行。行缓冲器146可以根据请求从存储行提取和输出竖直列。此外,行缓冲器146允许在存储进来的新的行时重用先前缓冲的行。
在一个实施例中,行缓冲器146接收输入流并输出列170中的特征数据。每列170包括来自行缓冲器146的每行中的特定位置的数据值。例如,第一列包括来自行缓冲器146的每行中的第一位置的数据值。第二列包括来自行缓冲器146的每行中的第二位置的数据值。第三列对应于来自行缓冲器146的每行中的第三位置的数据值,以此类推。
在一个实施例中,行的数目和行的宽度定义了用于行缓冲器146的存储器的尺寸。例如,具有五个行的行缓冲器可以缓冲高度高达5的输出竖直列。
图6b示出了根据一个实施例的池化单元106的行缓冲器146的操作。特别地,图6b示出了当所有现有的行都已满时,在行缓冲器146中填充新行的顺序。在图6b的示例中,在行缓冲器146处接收新的数据行。行缓冲器的处于其当前状态的顶行将被替换为新的数据行。因此,新缓冲器状态包括行缓冲器146的顶行中的新数据行。
在一个实施例中,行缓冲器146是单端口行缓冲器。这意味着行缓冲器146包括单个输入端口和单个输出端口。结果是单端口行缓冲器146具有非常低的功耗和并且占用集成电路的面积小。这在池化单元106的功耗、面积消耗和一般效率方面是非常有益的。
图7a示出了根据一个实施例的池化单元106的填充控制148的操作。填充控制器148从行缓冲器146接收特征数据列170。填充控制器148可以通过用户提供的输入填充来填充特征数据列170。
在一些情况下,可能需要填充来将输入数据窗口的尺寸调节为所需的池化窗口,因为在输入上进行了跨步(stride)。这可能意味着需要附加数据列170和/或每个数据列需要一个或多个附加行。在这种情况下,用户可以配置配置寄存器164中的配置数据,以使得填充控制148填充特征数据列170。
在图7a的示例中,输入特征数据列170的高度为2。填充控制140被配置为添加额外的零行和额外的零列。因此,填充控制148生成经填充的特征数据列172。经填充的特征数据列172包括额外的零列和每列中的零的额外行。在不背离本公开的范围的情况下,可以选择其他填充配置。填充控制140还可以被配置为不执行任何填充。在这种情况下,填充控制148的输出与填充控制148的输入相同。
图7b是根据一个实施例的池化单元106的列计算器150的示意图。列计算器150从填充控制148接收经填充的特征数据列172。列计算器150生成输出数据174,对于每一列,输出数据174包括相应的数据值。
来自列计算器150的输出数据174基于为列计算器150选择的操作类型。配置寄存器164中的配置数据可以定义要由列计算器150执行的操作的类型。列计算器可以执行的操作类型的一些示例包括最大操作、最小操作和平均操作。
图7b示出了两种类型的输出数据174。顶部输出数据对应于由列计算器150执行的最大操作。在最大操作中,列计算器确定每个输入列172的最大值。列计算器150针对每个输入172输出与该列中的数据值的最大值相对应的数据值。在图7b的示例中,第一输入列172的最大值是6,第二输入列172的最大值是4,第三输入列172的最大值是2。因此,最大操作的输出数据174是6、4和2。
底部输出数据174对应于列计算器150的求和计算。对于求和计算,列计算器150为每个输入列172生成输入列172中的数据值之和。第一输入列172中的数据值之和为11。第二输入列172中的数据值之和为7。第三输入列172中的数据值之和是3。因此,求和运算的输出数据174包括数据值11、7和3。
图8示出了根据一个实施例的池化单元106的批量缓冲器152的操作。批量缓冲器152从列计算器150接收数据值174。批量缓冲器152在行和列中存储数据值174。批量缓冲器152经由列解复用器176接收数据值174。批量缓冲器由多个行和列构成。最大行数对应于单元被设计支持的最大批量尺寸。例如,如果最大批量尺寸为8,则行数为8,因此单元支持批量尺寸范围从1到8的张量。在这个具体示例中,张量批量尺寸是3,因此3行被占用,即使实际的行数可能会更大。类似地,单元可以设计为具有与预期支持的最大池化窗口宽度维度相对应的多个列。在此图中,列数为3,因此该单元可以支持1、2或3的池化窗口宽度。
列解复用器176根据与进来的列相关联的批量索引,接收数据值174并将其放入所期望的批量缓冲器列中。在该示例中,数据值op(1a,1b,1c)对应于批量索引0(批量尺寸=3,因此索引范围为0、1、2),因此被放置在第一批量缓冲器行中。类似地,下一个数据值op(2a,2b,2c)对应于批量索引1,因此被放置在第二批量缓冲器行中,以此类推,而数据值op(4a,4b,4c)对应于批量索引0,因此被放置在批量缓冲器行0中,但是列索引1,因为它是沿特征张量的宽度维度的第二列的结果。因此,在图8的示例中,op(1a,1b,1c)对应于通过对数据列172执行列计算器的所选择的操作而生成的数据值174,其包括对应于来自特征张量128或经裁剪的特征张量168的索引1a、1b和1c。列解复用器176以所选择的方式在批量缓冲器152的行和列中输出174中的各种数据值。
图9示出了根据一个实施例的池化单元106的批量缓冲器152和行计算器154的操作。批量缓冲器152将数据值174的行输出到行复用器178。行计算器154从行复用器178接收数据行。
在一个实施例中,行计算器154对来自批量缓冲器152的每一行执行操作。行计算器154针对每一行输出与对该行执行的操作相对应的数据值。将由行计算器154执行的操作的类型存储在配置寄存器164中。这些操作可以包括最大操作、最小操作或求和操作。
图10示出了根据一个实施例的由池化单元106执行的池化操作。配置寄存器164确定用于每个池化操作的池化窗口的尺寸。池化窗口对应于经裁剪的特征张量168的被选择的部分。池化窗口的尺寸部分地确定池化单元106的输入和池化单元106的输出之间的尺寸减小幅度。
在图10的示例中,池化窗口是3x3。如果经裁剪的特征张量168的高度和宽度为9x9,所选择的池化窗口为3x3,跨步为3(下面将更详细地描述),则对于经裁剪的特征张量168的单个深度切片的每个不重叠的3x3窗口,池化操作将生成单个数据值。这对应于来自经裁剪的特征张量168的每个9x9切片的九个数据值。
在图10的示例中,从经裁剪的张量168中选择3x3子张量。将3x3子张量传递给列计算器150。列计算器150被配置为针对每一列提供该列中的数据值之和。因此,列计算器的输出是数据值12、15、18。行计算器154也被配置为执行求和操作。因此,行计算器154生成数据值45,该数据值45是12、15和18之和。
在一个示例中,所选择的池化操作是平均而不是求和。在这种情况下,列计算器150和行计算器150各自生成总和,如图10中所示。然后,总和45被提供给平均乘法器级158。平均乘法器级158对来自行计算器150的总和执行平均操作。平均乘法器级的输出是值5。5是3x3池化窗口中的值的平均。对所有池化窗口执行此操作,直到为每个池化窗口生成平均值为止。已经由池化单元106生成了经减小的特征张量,其包括为池化窗口中的每个池化窗口生成的值中的每个值。
在一个实施例中,平均乘法器级158包括乘法器180和调节器单元182。平均乘法器级158的效果是将由行计算器154提供的值除以池化窗口中的数据值的数目。在图10的示例中,平均乘法器级158的效果是将行计算器154的输出除以9。然而,除法运算在计算能力领域的方面是非常昂贵的。因此,乘法器将分数1/9转换为其固定点q15形式的3641。然后,乘法器将3641乘以45,得到值163845。该数字被提供给调节器单元。调节器单元182将值降档(downshift)、舍入和饱和(saturate)(如果是这样配置的话)降到值5,这是池化窗口中的值的平均。通过这种方式,平均乘法器级158可以计算池化窗口的平均。
乘法器级158包括可配置的降档或支持基于池化单元配置寄存器164中指定的值来对值的降档进行截断、舍入和饱和。可以支持各种舍入模式,诸如舍入到最近值、离零舍入(roundawayfromzero)、舍入到最接近的偶数等。如果需要的话,可以通过经由配置寄存器164启用饱和来饱和输出。如果未启用饱和,则输出将被简单地截断以输出数据。返回到图4,跨步管理器160负责对输入进行选通,并且仅允许基于池化中指定的水平跨步和竖直跨步来传递那些样本值。一个实施例可以使用2个计数器,分别计数到水平跨步的值和竖直跨步的值。计数器在每个到达的输入被触发,而输出是选通的,除非计数器都是0,因此只允许输出那些遵循跨步要求的值。
在一个实施例中,池化单元106还支持全局池化。特别地,池化单元106包括全局池化单元166。全局池化单元提供了专用数据路径,以对任意尺寸的张量执行全局池化。全局池化不同于窗口池化在于,池化窗口包含输入特征张量的整个宽度和高度。全局池化将行缓冲器146、填充控制148、列计算器150、行计算器154和可被时钟选通的批量缓冲器152旁路,从而节省运行时功率(runtimepower)。全局池化单元166也是批量感知(batchaware)的。
池化单元106还支持非池化。特别地,非池化块163实现非池化操作。非池化操作通过尤其是在语义分割中的应用扩充了卷积神经网络拓扑中的最大和最小池化。在最大非池化中,非池化块163针对每个池化窗口记录池化窗口中的从中汲取最大值的位置。特征张量128或经裁剪的特征张量168可以通过非池化操作部分地被重新生成。特别地,将最大值从特征张量128或经裁剪的特征张量168放回这些最大值的相应的数据字段中。其他数据字段可以用零填充。除了将最小值放回它们的数据字段中并且用零填充其他数据字段之外,非池化块163可以对最小池化做相同的事情。
图11是根据一个实施例的用于操作卷积神经网络的方法1100的流程图。在1102处,方法1100包括在卷积神经网络的池化单元中接收特征张量。在1104处,方法1100包括通过使用池化单元的裁剪器裁剪特征张量,来生成包括多个数据值的经裁剪的特征张量。在1106处,方法1100包括将经裁剪的特征张量的数据值传递给池化单元的单端口行缓冲器。在1108处,方法1100包括通过对来自行缓冲器的数据值执行列池化计算和行池化计算来生成经池化的特征数据。在1110处,方法1100包括将经池化的特征数据输出到卷积神经网络的卷积层。
尽管方法1100描述了将经池化的特征数据输出到卷积层,但是在不背离本公开的范围的情况下,经池化的特征数据可以被输出到除卷积层以外的层、过程、组件或模块。在不背离本公开的范围的情况下,可以对方法1200进行其他变型。
图12是根据一个实施例的用于操作卷积神经网络的方法1200的流程图。在1202处,方法1200包括在卷积神经网络的池化单元中接收特征张量。在1204处,方法1200包括在池化单元的配置寄存器中存储池化窗口尺寸数据。在1206处,方法1200包括利用池化单元根据池化窗口尺寸数据从特征张量生成多个池化窗口。在1208处,方法1200包括通过对来自池化窗口的数据值执行列池化计算和行池化计算来生成经池化的特征数据。在1210处,方法1200包括将经池化的特征数据输出到卷积神经网络的卷积层。
尽管方法1200描述了将经池化的特征数据输出到卷积层,但是在不背离本公开的范围的情况下,经池化的特征数据可以被输出到除卷积层以外的层、过程、组件或模块。在不背离本公开的范围的情况下,可以对方法1200进行其他变型。
与实现卷积神经网络的电子设备相关的进一步细节可以在于2019年2月20日提交的美国专利申请公开2019/0266479、于2019年2月20日提交的美国专利申请公开2019/0266485、以及于2019年2月20日提交的美国专利申请公开2019/0266784中找到,这些专利申请公开中的每个专利申请公开都通过引用整体并入本文。
可以组合上述各种实施例以提供进一步的实施例。根据上述详细描述,可以对实施例进行这些和其他改变。通常,在所附权利要求中,所使用的术语不应该被解释为将权利要求限制于说明书和权利要求中所公开的具体实施例,而应当被解释为包括所有可能的实施例以及这些权利要求享有的等同物的全部范围。因此,权利要求不受本公开的限制。
- 还没有人留言评论。精彩留言会获得点赞!