基于微调BERT模型的电力零售套餐向量表示方法与流程
本发明属于结构化数据处理
技术领域:
,具体涉及一种基于微调bert模型的电力零售套餐标准化向量表示方法。
背景技术:
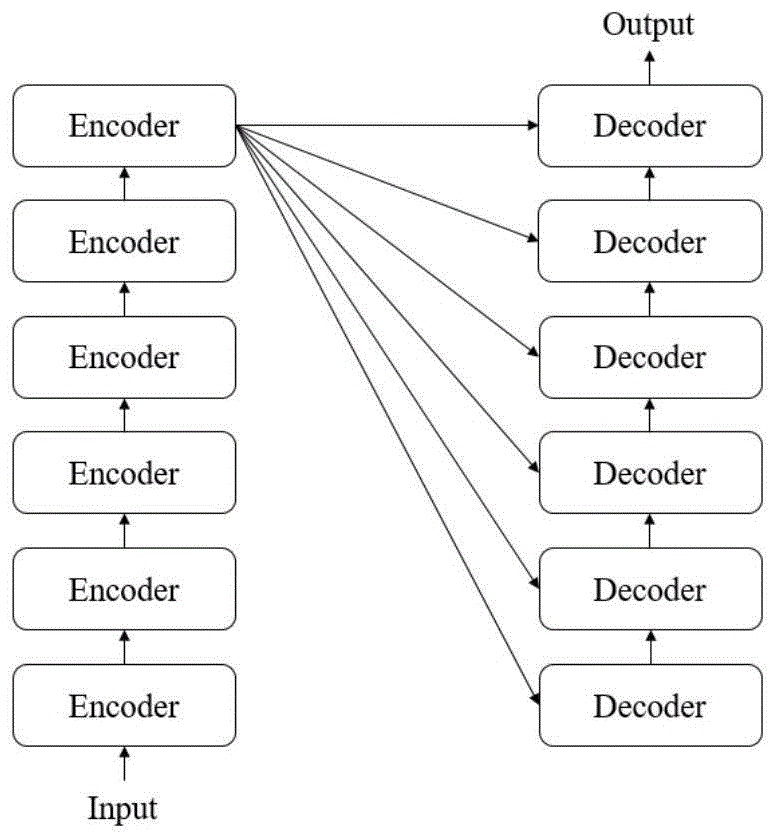
:随着我国电力市场化改革不断落实和推进,电力零售市场作为电力批发市场的一种补充,逐渐进入了人们的视野,它有效完善了电力市场的交易方式,提升了交易灵活性。电力套餐作为电力零售市场的最主要商品,其商品属性如价格、履约金、服务费和偏差处理规则等备受电力用户的关注,也很大程度上决定了用户体验。有效的对电力套餐进行表征的方法直接为后续对电力套餐进行准确的聚类、用户推荐等操作提供了可靠支撑,大大提升了电力零售平台上数据处理的效率和精度。近年来在深度学习领域发展迅速的表示学习技术旨在利用低维连续的稠密向量来对建模样本的特征进行表示,它要求向量能够一定程度反映建模样本的语义特性。基于词语的分布式表示作为表示学习最为基础的单元,近年来发展迅速。词语的分布式表示技术最先以于2013年被提出的静态词向量模型word2vec为代表,之后通过elmo、gpt及bert等动态词向量模型不断改进和优化,大大增强了对文本语义的理解能力,同时也很好地促进了各类自然语言处理任务的发展。然而对于类似电力套餐这类结构化数据,目前还没有较好的对其进行有效表征的方法。基于此,本发明提出了一种针对电力套餐这种结构化数据的标准化向量表示方法。技术实现要素:本发明的目的是为了解决现有技术的不足,基于在当前国内电力市场化改革背景下,在电力零售市场中缺乏一种高效准确的对电力零售套餐进行有效表征的方法,提出了一种基于预训练bert模型的电力零售套餐标准化向量表示方法。为实现上述目的,本发明采用的技术方案如下:基于微调bert模型的电力零售套餐向量表示方法,包括如下步骤:步骤(1),采集电力零售市场中的信息;步骤(2),对步骤(1)采集到的信息进行过滤,以去除标点、特殊符号、网页标签和乱码字符,然后将这些文本调整为预训练bert模型进行微调所需的单字形式;例如被过滤后的文本“电力市场化改革要求售电公司进入市场”被拆分为“电”、“力”、“市”、“场”、“化”、“改”、“革”、“要”、“求”、“售”、“电”、“公”、“司”、“进”、“入”、“市”和“场”这些序排列的单字;步骤(3),将步骤(2)调整后得到的文本形式输入到bert模型中进行训练;步骤(4),采集电力零售市场中电力套餐;步骤(5),提取电力套餐中的特征,将使用结构化数据描述的特征转换为使用非结构化进行描述的文本,使得该文本包含该电力套餐的属性参数信息;步骤(6),通过步骤(3)训练得到的模型对步骤(5)得到的使用非结构化进行描述的文本进行向量化;步骤(7),对向量化结果通过基于余弦相似度的计算来进行评估,若达到预设目的,则采用步骤(3)训练得到的模型对电力零售套餐进行标准化向量计算;反之,则返回到步骤(1),在上一次采集新闻和报告数量的基础上再新采集电力零售市场中的信息,将新采集的连同上一次采集的电力零售市场中的信息作为微调数据集,依次进行步骤(2)和步骤(3),对bert模型进行再次调整,直至向量化结果评估达到预设目的。进一步,优选的是,步骤(1)中,所述的信息包括电力零售市场的新闻、报道及政策。进一步,优选的是,采集电力零售市场中的新闻、报道及政策500篇。进一步,优选的是,步骤(4)中,采集电力零售市场中100份电力套餐。进一步,优选的是,步骤(5)中,电力套餐中的特征包括价格p、履约金pg、服务费sc、正偏差处理规则pr、负偏差处理规则mr和电量控制说明ci。进一步,优选的是,步骤(7)的具体方法为:随机选取一个电力零售套餐p1,而后分别选取与p1套餐属性内容相似和属性内容截然不同的两个电力套餐p2和p3,并分别提取电力套餐中的特征,且将使用结构化数据描述的特征转换为使用非结构化进行描述的文本tp1、tp2和tp3;然后使用步骤(3)训练得到的模型分别为其生成对应文本向量vec1、vec2和vec3;最后通过余弦相似度公式(4)、(5)分别计算vec1和vec2、vec3之间的相似度similarity1和similarity2并进行比较;similarity1和similarity2之间的差值|similarity1-similarity2|通过如下的方式进行评估:(1)若0<|similarity1-similarity2|<0.1,说明步骤(3)训练得到的模型几乎没有学习到电力零售市场的领域知识,即没有达到预设目的;这种情况下需要考虑是否是用于微调bert的数据集数量不充足或是数据集质量不佳所致。对于数据集数量,可以重复进行步骤(1)至步骤(3),每次在步骤(1)中增加数据集文本数量来对bert模型进行训练;对于数据集质量,可以在步骤(1)中通过人工对数据集中部分文本内容进行筛查,去除内容与电力零售市场相关度低的文本,提升数据集内容和电力零售市场的整体相关性。(2)若0.1≤|similarity1-similarity2|<0.5,说明步骤(3)训练得到的模型一定程度上学习到电力零售市场的领域知识,但仍有提升的空间,即没有达到预设目的;可参照(1)中增加训练数据集数量,同时提升数据集质量,而后再对bert模型进行训练。(3)若0.5≤|similarity1-similarity2|<1,说明步骤(3)训练得到的模型较好地学习到电力零售市场的领域知识,即达到预设目的,直接采用步骤(3)训练得到的模型对电力零售套餐进行标准化向量计算。本发明涉及对电力零售市场中电力套餐的特征进行抽取,并基于特征对套餐进行向量化的方法。该方法首先将使用结构化数据描述的电力套餐转换为使用非结构化进行描述的文本,使得该文本包含套餐的属性参数信息;然后通过预训练bert模型微调后的结果对描述文本进行向量化;最终对向量化结果通过基于余弦相似度的计算来进行评估,之后便可以对电力套餐基于其向量表示进行聚类和用户推荐等操作。具体内容如下:(1)实现将电力套餐从结构化数据到非结构化数据的转换。电力套餐作为一种商品,其各属性和参数都具有明显的语义,可以将其各属性的值进行合理的拼接和处理转换为文本;(2)利用适量电力零售市场领域文本对预训练bert模型进行微调。bert是一个基于互联网庞大语料库训练而得到的词向量模型,利用一定量的电力零售市场领域文本对其进行微调,能够让其具备与电力零售市场知识对应的上下文感知能力,从而更好提供领域向量表征服务;(3)利用微调后的bert模型对电力套餐对应文本进行向量化。微调后的bert模型具备了一定的领域知识,能够有效生成具有领域语义的电力套餐特征向量;(4)对生成的电力套餐特征向量通过相似度指标进行评估。选取若干对属性值相似和属性值不同的套餐,分别计算其对应特征向量的相似度,对比二者的差异。本发明与现有技术相比,其有益效果为:本发明以电力零售市场中的电力零售套餐作为建模对象,首先将以结构化数据进行表示的电力零售套餐转换为非结构化数据文本,而后借助电力零售市场的特定领域语料库对预训练bert模型进行微调来使其具有和电力零售市场知识相关的上下文语义推断能力,并利用微调后的bert模型对电力零售套餐的文本进行向量化,最终通过余弦相似度来评估生成向量的有效性和准确性。对电力零售套餐进行向量化表示不仅为后续电力套餐的聚类及用户套餐推荐等应用提供可靠支撑,同时也大大提升电力零售平台的数据处理效率。附图说明图1为transformer模型结构图;图2为transformer编码器和解码器结构;图3为bert模型结构图;图4为微调bert模型生成的向量。具体实施方式下面结合实施例对本发明作进一步的详细描述。本领域技术人员将会理解,下列实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用材料或设备未注明生产厂商者,均为可以通过购买获得的常规产品。一、问题定义特征抽取和表示是对建模样本根据任务类别将其相关特征进行提取并表示成向量的过程。无论是在传统的机器学习还是深度学习中,特征抽取和表示都是最为基础和关键的前置性步骤。在深度学习中,特征抽取和表示通常是由神经网络自动学习而完成的,因此又被称为表示学习技术。本发明针对电力零售市场中电力套餐的属性具有明显语义的特点,选择在庞大语料库上训练而成的bert模型为电力套餐提供有效的向量表征,之后通过相似度指标对向量化结果进行评估。二、传统技术方法缺陷特征提取和表示的方法经历了人工抽取和表示学习两个阶段。人工抽取即根据机器学习任务类型,人为对建模对象特征进行设计、抽取、处理和表示。这种方式可解释性强,但十分耗时耗力,面对复杂任务时可能造成特征稀疏和灾难维度问题。表示学习通过神经网络自动学习得到建模对象的特征向量表示。以最为常见的词向量为代表,表示学习技术通常先在大规模语料库上进行训练,而后对语料库中的每个词语生成一个向量表示,同时使得词语对应的向量表示能够体现该词语在语料库中的上下文语义特征。虽然以词向量为核心的表示学习技术近年来不断刷新着自然语言处理众多任务的性能指标,但对于结构化数据,现有表示学习技术却难以对其进行有效的向量化。另一方面,随着我国电力市场化改革加速推进,电力零售市场作为一种电力新兴市场,有效地对电力批发市场进行了补充,大大完善了电力市场的运作机制。电力零售套餐是零售市场中最主要的商品,它直接关系到电力用户的用电体验及生产经营状况,因此,如何有效地对电力套餐进行向量化表示,从而对其进行聚类、推荐等操作无论是对于交易平台还是售用电双方都大有裨益。然而,电力零售套餐作为一种结构化数据,现有的表示学习技术无法直接有效地对其进行向量化。三、基于预训练bert模型的电力零售套餐的向量化方法本发明通过分析电力零售套餐各属性参数中的语义,将表示电力零售套餐的结构化数据转换为非结构化文本,而后利用预训练bert模型对转换后的文本进行向量化。下面对各步骤进行介绍。1、电力零售套餐的文本化处理每个电力零售套餐都包含价格p、履约金pg、服务费sc、正负偏差处理规则pr、mr和电量控制说明ci六种属性,其中服务费、正负偏差处理规则和电量控制说明均是使用文字进行描述,具备很强的语义特性,因此可以考虑将这些属性的对应描述进行拼接,再适当加上对价格以及履约金的描述,便能够将使用结构化数据表示的电力零售套餐转换为使用文本描述的非结构化数据tp。转换过程如公式(1)所示,其中process表示对拼接后的文本进行衔接词补充和冗余词过滤操作。其中,衔接词补充操作是在套餐的属性和相应描述之间加上如“为”、“是”的动词,使得文本描述更加连贯,例如对于表1中的“价格”属性和其对应的描述“0.121元/kwh”,可在其间加入“为”来得到文本“价格为0.121元/kwh”。冗余词过滤操作则是对一些重复或复杂的表达方式进行简化,例如对于表1中的“负偏差处理规则”属性,若是采用在属性和描述之间加入衔接词进行文本化,则表达便产生了冗余,因为“负偏差”和“月用电量低于交易电量”表达的是相同的语义,此处通过冗余词过滤操作便可将文本处理为“无负偏差处理规则”或“无负偏差考核”。tp=process([p,pg,sc,pr,mr,ci])(1)例如对于某电力零售套餐,其属性如表1所示。表1将上述结构化描述转为非结构化文本表示为:该电力零售套餐价格为0.121元/kwh,履约金为0.03元/kwh,服务费标准为0.001元/kwh且单笔不低于0元,正偏差处理规则为月用电量超过交易电量的部分按0.15元/kwh,无负偏差考核,购买电量超过历史同期±5%需要售电公司进行审核。2、基于领域文本的预训练bert模型微调预训练bert模型是基于互联网大规模语料库训练而得到的动态词向量模型,相比于之前的elmo和gpt这类动态词向量模型,它在结构上使用了双向的注意力模型transformer。transformer模型结构如图1所示,它是基于seq2seq架构进行设计的,在编码器部分和解码器部分均分别采用多个编码器和解码器堆叠而成,每个编码器和解码器结构如图2所示。对于编码器,输入先后经过自注意力层和前馈神经网络进行处理,这两层使得模型不仅只关注到当前词语,还能获取到上下文的语义;解码器则在自注意力层和前馈神经网络层之间还加了一层注意力层,来帮助当前节点获取需要重点关注的内容。bert模型采用了双向transformer结构如图3所示,其中t表示transformer,输入e表示某个词的wordpiece、位置和分割嵌入的和,输出t则是模型经过训练后得到的最终向量表示。相比于先前的词向量模型,bert表征能够基于所有层的左右两侧语义来表征特定词语。另外,在训练策略上bert一方面使用mask机制随机挖空文本中的若干词语,而后预测这些被挖空的词语;同时也使用下一句子预测,来很好地使预训练模型具有上下文句子之间的推断能力,符合人类对文本认知理解的规律。然而,目前的预训练bert模型都是在通用语料库上进行训练得到的,不具备针对特定领域的上下文感知和语义推断能力,而电力零售市场恰恰是一个特定领域,蕴含了丰富的领域知识。因此需要通过微调的方式对预训练通用bert模型进行特殊化处理,使其具备针对电力零售市场领域的上下文感知能力。此处选取若干关于电力零售市场的新闻和报告,将这些新闻和报告进行过滤和分字操作后得到微调文本c。其中过滤是将文本中的标点、助词、介词、网页标签和特殊符号这类不蕴含过多实际语义的符号去掉,而分字主要是将新闻和报告中的句子分割成单字序列作为微调bert模型的输入。假设图3中所有transformer编码器和解码器的参数为p,微调过程finetine则是利用文本c对预训练bert模型lmp针对电力零售市场的领域知识对p进行调整得到p’,微调过后的bert模型lmp’便具有一定的针对电力零售市场的上下文语义感知能力。如公式(2)所示。lmp′=finetine(lmp,c)(2)3、基于微调bert模型的电力零售套餐向量化bert模型既能对文本中的每个词语都进行向量化,也能对一段文本整体生成一个向量,此处使用bert的文本级向量化功能对电力套餐的文本化描述进行处理。微调后的bert模型为lmp’,电力套餐的文本化描述为tp,生成的对应向量为vec,则微调过程如公式(3)所示。vec=lmp′(tp)(3)以上述电力套餐“该电力零售套餐价格为0.121元/kwh,履约金为0.03元/kwh,服务费标准为0.001元/kwh且单笔不低于0元,正偏差处理规则为月用电量超过交易电量的部分按0.15元/kwh,无负偏差考核,购买电量超过历史同期±5%需要进行审核”为例,其经过微调bert模型生成的向量如图4所示,所生成向量维数为bert模型固定的512维,向量中每一维值的绝对值在0到1之间,向量中值的正负分布无特定规律,且特定维度的值不与文本中特定语义相对应,只有整个向量才具有表征文本整体语义的能力。四、生成向量的评估指标在bert模型微调完成后,需要对其生成电力套餐向量的效果进行评估,此处采用余弦相似度作为评估指标。首先随机选取一个电力零售套餐p1,而后分别选取与p1套餐属性内容相似和属性内容截然不同的两个电力套餐p2和p3,并对其进行文本化分别得到tp1、tp2和tp3;然后使用微调后的bert模型分别为其生成对应文本向量vec1、vec2和vec3;最后通过余弦相似度公式(4)、(5)分别计算vec1和vec2、vec3之间的相似度similarity1和similarity2并进行比较。similarity1和similarity2之间的差值|similarity1-similarity2|通过如下的指标进行衡量:(1)若0<|similarity1-similarity2|<0.1,说明微调bert几乎没有学习到电力零售市场的领域知识;(2)若0.1≤|similarity1-similarity2|<0.5,说明微调bert一定程度上学习到电力零售市场的领域知识;(3)若0.5≤|similarity1-similarity2|<1,说明微调bert较好地学习到电力零售市场的领域知识。由上可知,当|similarity1-similarity2|较大时说明说明微调后的bert模型一定程度上学习到了电力零售市场的领域知识,能够根据不同电力零售套餐内容为其分配表征不同语义的向量。上述评估过程可重复多次进行验证,以保证生成向量的可靠性和有效性。应用实例1、微调数据集准备与bert微调从互联网上随机爬取关于电力零售市场相关新闻、报道及政策等文本500篇,并将这些文本进行过滤,去除标点、特殊符号和网页标签内容,然后将这些文本的格式调整为预训练bert模型进行微调所需的单字格式。最终将文本按bert微调所需的单字格式输入到模型中进行训练,待训练结束后保存微调完成后的bert模型参数。bert模型每个模块参数数量如表2所示。表2模型模块参数数量嵌入层23837184transformer模块85054464全连接层590592总计109482240此处选取elmo[petersme,neumannm,iyyerm,etal.deepcontextualizedwordrepresentations[j].arxivpreprintarxiv:1802.05365,2018.]和gpt[radford,alec,etal."improvinglanguageunderstandingbygenerativepre-training."(2018).]作为对比模型,使用相同的微调数据集分别对其预训练模型进行训练,训练完成后保存微调后的elmo和gpt模型参数。2、基于微调bert模型的电力零售套餐向量化从电力零售平台上随机爬取100份电力套餐的相关信息,并将其以结构化表示的数据转换为以非结构化文本表示的数据。而后将这些电力套餐的文本表示分别输入到经过微调的elmo、gpt和bert模型中得到对应的电力套餐向量化表示,保存下电力套餐和其对应的三种模型输出的向量表示。3、向量结果评估针对上述100份电力零售套餐,对于每一份套餐,挑选出一份与其内容相似的套餐和一份内容不同的套餐,并分别通过微调后的elmo、gpt和bert输出这两个电力套餐的向量化表示,而后通过公式(4)和(5)分别计算该套餐向量和同一模型生成的两个套餐向量的余弦相似度,最后计算该套餐与相似套餐和不同套餐向量之间余弦相似度的差值。不断重复上述过程,直至对100份套餐都计算得到三种模型生成向量的余弦相似度的差值,并计算这100份套餐在三种模型下的平均余弦相似度差值,作为对三种模型微调效果的评估,统计结果如表3所示。表3向量化模型平均余弦相似度差值elmo0.4523gpt0.5125bert0.6034由表3可知,三个模型都不同程度地学习到了电力零售市场的领域知识,其中elmo模型学习效果最差,而bert模型学习效果最好,进一步验证了bert在模型结构和学习能力较其他两个模型更具有优势,因此可将其作为对电力零售套餐向量化的最佳模型。4、电力零售套餐聚类和用户推荐在实现电力零售套餐的向量化之后,可以基于此使用不同聚类算法例如k-means和clara等对电力套餐进行聚类,距离函数通常可以选取欧氏距离、曼哈顿距离、切比雪夫距离等,聚类完成后根据聚类结果对电力套餐的类别通过人工加以总结和归纳,以此作为针对不同电力用户推荐相应电力零售套餐的依据。例如聚类完成后的套餐通过人工归纳,将一些正负偏差处理规则较为宽松的归纳为“松散偏差规则套餐”类,将一些履约金和服务费价格相对较低的归纳为“高信用套餐”类,针对一些难以预估未来交割月用电量而又希望不被考核套餐的用户,系统可为其推荐“松散偏差规则套餐”,而对于一些信用评价等级较高的用户,系统则可为其推荐“高信用套餐”。以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1