基于ReRAM神经网络加速器的可调硬件感知的剪枝和映射框架的制作方法
本发明涉及计算机科学人工智能领域,尤其涉及一种针对基于reram神经网络加速器的可调硬件感知的剪枝和映射框架。
背景技术:
深度神经网络在计算机视觉、自然语言处理、机器人学等领域发展中起着重要的推动作用,随着移动物联网平台的发展,iot设备端的神经网络应用迅猛发展。由于神经网络的计算密集性和大量的数据移动性,神经网络的应用会产生高能量消耗和高延迟,然而,iot平台上计算资源有限、能量支持有限,因此iot设备需要更高效的神经网络映射方案来降低能耗和延迟。电阻式随机访问存储器(reram)由于其极低的能量泄漏、高密度存储和存内计算的特性,基于reram的神经网络加速器为iot设备的局限性提供了解决思路。另一方面,由于目前大量的稀疏神经网络模型越来越大,造成了大量不必要的资源浪费和延迟增加,在模型映射到reram神经网络加速器之前进行剪枝,可以极大地降低模型的大小,从而降低硬件能量消耗和应用的延迟。但是当reram神经网络加速器的硬件规格和种类不同时,而且面对用户对于延迟、能耗等不同层次的需求时,传统的深度学习剪枝方案无法感知硬件和用户需求的变化而做出产生同一种剪枝方案,从而造成reram神经网络加速器硬件上模型映射的性能低效性,制约了reram神经网络加速器的性能优势发展。
技术实现要素:
为了根据移动设备用户的需求而更加高效地探索在reram神经网络加速器上映射卷积神经网络,本发明提出了一种可调的智能硬件感知剪枝和映射框架,利用强化学习代理从reram神经网络加速器硬件上得到的反馈(如延迟、能耗、能效等)来代替无法在硬件加速器性能上表现的信号(如模型大小、浮点操作次数等),使用深度确定性策略梯度(ddpg)来进行剪枝策略的搜索和决策,以实现基于reram神经网络加速器的更友好的剪枝策略的确定,降低剪枝后映射的神经网络模型在硬件加速器上的延迟、能耗,从而使得可穿戴移动物联网设备在有限资源限制下实现深度学习应用,并且根据硬件和用户对延迟、能耗的需求不同,找到与之最适配的剪枝和映射框架。
本发明采用的技术方案是:
一种基于reram神经网络加速器的可调硬件感知的剪枝和映射框架,包括ddpg代理器和reram神经网络加速器;所述ddpg代理器由行为决策模块actor和评判模块critic组成,其中,所述行为决策模块actor用于对神经网络模型做出剪枝决策;
所述reram神经网络加速器用于映射行为决策模块actor产生的剪枝决策下形成的模型,并将剪枝决策下的模型映射的性能参数作为信号反馈给评判模块critic;所述性能参数包括reram神经网络加速器的能耗、延迟和模型准确率;
所述评判模块critic用于根据反馈的性能参数更新奖励函数值,评估行为决策模块actor的表现,并指导行为决策模块actor下一阶段的剪枝决策使奖励函数值收敛;
所述奖励函数值根据用户的需求来选择通过reward1(能耗)和/或reward2(延迟)更新,已达到硬件中的实际性能表现:
reward1=-error×log(energy)
reward2=-error×log(latency)
其中,error=1-accuracy,accuracy为模型准确率,energy为reram神经网络加速器的能耗性能,latency为reram神经网络加速器的延迟性能。
进一步地,行为决策模块actor用于对神经网络模型做出剪枝决策具体为:
行为决策模块actor根据输入的用于表征第k层神经网络的状态参数sk,输出稀疏率,并根据每层的稀疏率使用压缩算法对神经网络模型进行逐层压缩。即:使用指定的压缩算法(例如通道修剪),压缩当前层。然后,代理移动到下一层k+1,并接收状态sk+1直至完成最后一层。
进一步地,状态参数sk采用8个特征进行表征:
(k,type,inchannels,outchannels,stride,kernelsize,flops[k],ak-1)
其中k是层索引,type是层的种类,inchannels表示输入通道数,outchannels表示输出通道数,stride表示卷积的步长,kernelsize表示卷积核长,因此卷积核尺寸为inchannels×outchannels×kernelsize×stride;flops[k]是第k层的浮点操作次数,并在传递给行为决策模块actor之前,在[0,1]内缩放;ak-1是前一层作出的剪枝动作,可以采用压缩率表示。
由于传统的深度学习剪枝优化方案中利用浮点操作次数或者模型的大小作为剪枝的信号来指导强化学习代理的剪枝决策,但是当reram神经网络加速器的硬件规格和种类不同时,并且面对用户对于延迟、能耗等不同层次的需求时,传统的深度学习剪枝方案无法感知硬件和用户需求的变化而做出产生同一种剪枝方案,从而造成reram神经网络加速器硬件上模型映射的性能低效性。本发明提出了一种可调的智能硬件感知剪枝方案和映射框架,与原始方案选择直接将神经网络映射到reram神经网络加速器上不同,该框架利用强化学习中深度确定性策略梯度(ddpg)来进行剪枝策略的搜索和决策,并根据用户的需求来选择硬件中的实际性能表现(如延迟、能耗等)反馈给强化学习中的代理。当根据用户需求进行硬件感知的剪枝后然后将模型映射到reram神经网络加速器上,能够极大地减少神经网络模型应用在加速器上的延迟和能耗,使其映射的性能提高。
附图说明
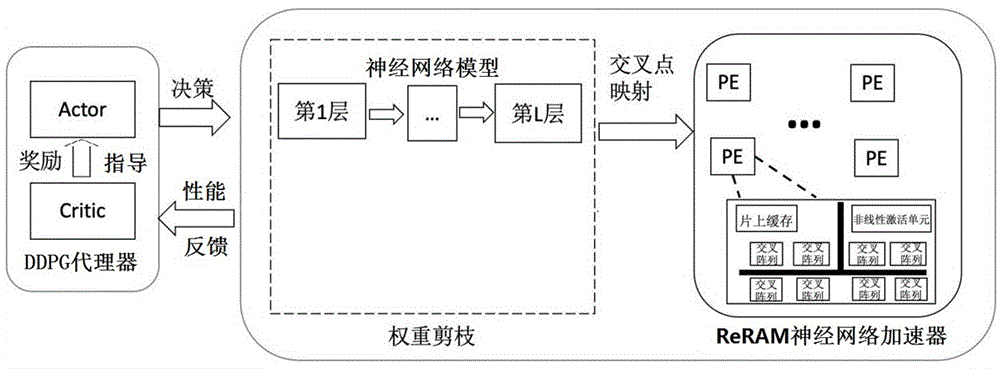
图1为本发明的硬件感知的剪枝和映射框架整体结构图;
图2为实验流程图;
图3为vgg-16采用延迟感知方案下,在配置2、配置3、配置4三种模拟器neurosim硬件配置下搜索到的剪枝策略对比柱状图。
具体实施方式
图1是本发明的硬件感知剪枝和映射框架整体结构图,如图所示,包括ddpg代理器和reram神经网络加速器;其中,reram神经网络加速器包括多个处理单元(processingelement,pe),每个处理单元由多个reram单元构成的交叉阵列、片上缓存、非线性激活处理单元、模电转换器以及其他外围电路组成(图中仅画出交叉阵列、片上缓存和非线性激活处理单元)。所述ddpg代理器由行为决策模块actor和评判模块critic组成;整个剪枝和映射框架包含两个层次。在第一层次中,ddpg代理器的行为决策模块actor根据硬件反馈对神经网络模型做出从第一层到最后一层的剪枝决策,并将剪枝决策下形成的模型在第二层次中通过reram神经网络加速器上进行映射,将此剪枝决策方案下的模型映射的性能参数作为信号反馈给第一层次ddpg代理器中的评判模块critic。评判模块critic负责评估行为决策模块actor的表现,更新在该硬件种类和用户需求下的奖励函数值,并指导行为决策模块actor下一阶段的剪枝决策。经过一定的周期数后,奖励函数值收敛,系统找出最优的剪枝决策方案,并按照该硬件感知剪枝策略进行剪枝后的ckpt模型导出,然后对其进行模型微调以保证精度。
其中,作为优选方案,ddpg代理器的行为决策模块actor根据性能参数反馈对神经网络模型做出从第一层到最后一层的剪枝决策具体为:
行为决策模块actor从环境接收神经网络模型第k层的状态参数sk,输出稀疏率,并根据每层的稀疏率使用指定的压缩算法,以ak压缩当前层,然后,代理移动到下一层k+1,并接收状态sk+1。
对于每个层k的状态参数sk,采用8个特征来表征:
(k,type,inchannels,outchannels,stride,kernelsize,flops[k],ak-1)(1)
其中k是层索引,type是层的种类(包括卷积层和全连接层,分别用0和1表示),inchannels表示输入通道数,outchannels表示输出通道数,stride表示卷积的步长,kernelsize表示卷积核长,因此卷积核尺寸为inchannels×outchannels×kernelsize×stride;flops[k]是第k层的浮点操作次数,并在传递给行为决策模块actor之前,在[0,1]内缩放;ak-1是前一层作出的剪枝动作。
为了实现更细粒度的剪枝决策,行为决策模块actor的剪枝动作采用压缩率表示,akϵ(0,1],即:使用通道修剪算法,四舍五入到最接近的能够最终获得整数通道数的分数作为ak,并以ak压缩当前层。
在完成最后一层剪枝决策之后,将采用验证集在reram神经网络加速器上对准确率和硬件的性能参数(延迟或者能耗)进行评估,计算奖励函数的值,并将其返回给评判模块critic。
其中,此处计算的准确率与微调后精度近似,因此为了快速探索,可以在不进行微调的情况下评估奖励函数中的准确率。
所述奖励函数值通过reward1和/或reward2更新:
reward1=-error×log(energy)
reward2=-error×log(latency)
其中,error=1-accuracy,accuracy为模型准确率,energy为reram神经网络加速器的能耗性能,latency为reram神经网络加速器的延迟性能。
当某些iot设备中对于能量的支持十分有限并且用户对于延迟的需求没有十分紧急(即用户在剪枝映射中更加重视“能耗”性能)时,可以在奖励函数中考虑剪枝后的准确性和reram神经网络加速器硬件上映射的“能耗”性能。而在某些iot设备中对于能量的支持稍微充足并且用户对于延迟的需求较大(即用户在剪枝映射中更加重视“延迟”性能)时,可以在奖励函数中考虑剪枝后的准确性和reram神经网络加速器硬件上映射的“延迟”性能。因此,本发明方法可以根据不同的硬件和用户需要,更高效、目的精准地设计剪枝方案和映射框架。
此外,还可以调整reram神经网络加速器的配置,实现硬件感知,获得最佳配置和用户需求下的剪枝方案和映射框架。
下面结合具体的实施例对本发明作进一步说明,具体实验如下:
实验配置:
(1)操作系统:ubuntu18.04.3lts;
(2)cpu:型号为8核intel(r)xeon(r)gold6126cpu@2.60ghz,配有32gbdram;
(3)gpu:teslav10032gb显存;
(4)存储设备:512gb,skhynixsc311satassd;westerndigitalwdcwd40ezrz-75ghdd;
神经网络模型配置:
(1)神经网络模型:cifar10,plain20,vgg-16,其结构如表1。
表1.神经网络模型及其结构表示
(2)数据集:cifar10,包含60000张彩色图像,大小为32*32,分为10个类,每类6000张图,其中50000张图片用于训练,10000张图片用于测试;
(3)batch大小:1024张图片/批次(cifar10,plain20),512张图片/批次(vgg-16);
(4)训练轮数:70轮(epoch);
(5)finetune的轮数:50epoch;
reram神经网络加速器配置:
采用reram神经网络加速器的模拟器neurosim进行实验,配置如表2所示。
表2.模拟器neurosim配置
实验流程
图2为整个剪枝实验流程图。包括以下步骤:
步骤一:当用户编写完神经网络模型代码,输入本发明的剪枝和映射框架,对其进行预训练并保存获得ckpt文件;
步骤二:利用强化学习加入硬件感知搜索出最优的剪枝策略;
步骤三:根据步骤二强化学习中得到的最优剪枝策略进行修剪,并将剪枝后的参数保存ckpt文件;
步骤四:为保证剪枝后的准确率,对ckpt模型进行参数微调;
步骤五:在模拟器neurosim上模拟得到剪枝后的准确率,完成最终的剪枝策略映射。
最终测试结果:
在原始的直接神经网络映射方案(利用浮点操作次数或者模型的大小作为剪枝的信号来指导强化学习代理的剪枝决策)中,cifar10(配置2)、plian20(配置1)、vgg-16(配置2)在相应的硬件配置下,硬件模拟器的延迟分别为957150.6ns/image,4830571.6ns/image,1026976.8ns/image,模拟器的能耗分别是23488814pj、15816979.0pj、8058001.0pj。采用本发明的硬件感知——延迟感知方案,三个模型延迟性能分别提升了57.358%、6.771%、38.017%,并且top5准确率分别提升0.210%,0.190%,0.290%。采用能耗感知方案,三个模型分别将能耗性能提升了76.833%、5.615%、38.425%,并且top5准确率分别提升0.270%、0.230%、0.420%。采用本发明的硬件感知剪枝方案和映射框架,在提升用户关注的性能的同时,也保证了准确性。
表3为vgg-16采用延迟感知方案下,在配置2、配置3、配置4三种模拟器neurosim硬件配置下搜索到的剪枝策略。其中剪枝策略中的列表表示每组filter通道的保留率。
表3vgg-16采用延迟感知方案下三种模拟器neurosim硬件配置下搜索到的剪枝策略
图3为vgg-16采用延迟感知方案下,在配置2、配置3、配置4三种模拟器neurosim硬件配置下搜索到的剪枝策略对比柱状图。横坐标代表filter的组数,纵坐标表示剪枝策略下的通道保留率。柱状图表明在不同硬件配置下,每组filter的通道保留率分布具有不同的趋势。这也后验了面对不同硬件配置的情形下,硬件感知策略的必要性。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法把所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!