一种高准确率的跨模态行人重识别方法
1.本发明应用深度学习和知识引入实现高准确率的跨模态跨摄像头行人匹配的方法,属于计算机视觉领域。
背景技术:
2.随着社会的发展,道路监控系统越来越普及。由于监控摄像机的性能问题,以及监控环境条件的变化,人员识别中的人脸识别技术在跨摄像头行人追踪中并不能够发挥作用,因此行人重识别课题的重要性日益凸显[1]。行人重识别,目的在于在跨摄像头环境下检索筛选相同的人员目标,进而确定相应人员目标的活动轨迹[1]。同时,由于夜间摄像头所拍摄的图像大多是红外图像,与白天所拍摄的rgb图像有所区别,用传统的re
‑
id方法难以克服两种模态之间的模态差异,因此提出跨模态re
‑
id解决上述问题[3]。
[0003]
随着监控设备的大量普及以及大数据时代的到来,行人检索匹配在公共安全领域越来越具有重大意义。然而由于道路监控安装的局限性以及监控设备的性能问题,传统的人脸识别技术在道路监控下并不能够发挥作用[1]。因此,能够适应道路监控任务环境,并且完成跨摄像头特定人员识别追踪的行人重识别技术研究的必要性和重要性越来越受到重视。
[0004]
目前对于行人重识别的研究主要集中在三个方面,单模态re
‑
id,无监督re
‑
id,以及跨模态re
‑
id,此外还有去遮挡re
‑
id,密集人群以及跨分辨率等多个小方向。单模态re
‑
id的研究课题提出的最早,因此发展的最为完善,为后续的其他相关研究方向打下了基础。无监督re
‑
id是基于实际应用中标签难以获取的前提提出的研究方向,可以说是re
‑
id实际应用中必须进行的处理。跨模态re
‑
id是基于追踪检测的实际需求提出的,大多数的违法犯罪活动在夜间进行,因此夜间与白天的行人图像之间的匹配成为一个越来越重要的课题。
[0005]
单模态re
‑
id已经在现有的re
‑
id数据集上达到了非常高的匹配准确率,提出了许多较为鲁棒的baseline。单模态re
‑
id是rgb图像在有人工标签的情况下进行的监督训练,其主要目的在于挖掘行人样本中较为有区分力的细节形成样本特征,以此提升匹配准确率。这些方法中,self
‑
attention和基于part
‑
level特征的方法的效果尤为突出。self
‑
attention在行人重识别中的做法是将行人图像进行分块,并利用图像块之间的关系以及每块图像在最终匹配时的权重,重塑每块的内容,使得重塑后的图像块所能提供的区分能力更强。基于part
‑
level特征的方法的做法更为直接一些,比较典型的pcb模型,就是将图像直接进行横向切分,利用切分之后的每一个小图像块代表原来的整个行人样本,这样的做法强迫模型更多的关注图像的细节区域。这里的切分是基于先验知识的切分,pcb切分了六块,对应着人体的部位,有些方法切分为三块,对应头、上身、与下身。
[0006]
跨模态re
‑
id需要克服的问题相对于单模态re
‑
id来说要多很多。除去需要提取表征能力强的样本特征之外,还需要克服模态差异。目前多数论文[3[10]的做法是利用two
‑
stream网络结构对两个模态进行分别的处理,之后再用共享层提取模态共享特征,在此基础上提取可靠的表征。另有一些方法致力于研究模态独有特征的作用,一种典型的做法是
利用同标签的另一模态样本对本模态缺失特征进行填充,以此达到样本之间的特征平衡。利用gan也能达到类似的效果,这些方法保留原有样本的内容,替换为另一模态的风格特征,扩充数据集,达到模态之间样本的平衡[2]。
[0007]
参考文献:
[0008]
[1]ye,mang.(2020).deep learning for person re
‑
identification:a survey and outlook.
[0009]
[2]choi,seokeon&lee,sumin&kim,youngeun&kim,taekyung&kim,changick.(2020).hi
‑
cmd:hierarchical cross
‑
modality disentanglement for visible
‑
infrared person re
‑
identification.10254
‑
10263.10.1109/cvpr42600.2020.01027.
[0010]
[3]ye,mang&shen,jianbing&crandall,david&shao,ling&luo,jiebo.(2020).dynamic dual
‑
attentive aggregation learning for visible
‑
infrared person re
‑
identification.
[0011]
[4]wang,guan
‑
an&zhang,tianzhu&yang,yang&cheng,jian&chang,jianlong&liang,xu&hou,zeng
‑
guang.(2020).cross
‑
modality paired
‑
images generation for rgb
‑
infrared person re
‑
identification.proceedings of the aaai conference on artificial intelligence.34.12144
‑
12151.10.1609/aaai.v34i07.6894.
[0012]
[5]y.lu et al.,"cross
‑
modality person re
‑
identification with shared
‑
specific feature transfer,"2020ieee/cvf conference on computer vision and pattern recognition(cvpr),seattle,wa,usa,2020,pp.13376
‑
13386,doi:10.1109/cvpr42600.2020.01339.
[0013]
[6]jia,mengxi&zhai,yunpeng&lu,shijian&ma,siwei&zhang,jian.(2020).a similarity inference metric for rgb
‑
infrared cross
‑
modality person re
‑
identification.
[0014]
[7]fan,xing&luo,hao&zhang,chi&jiang,wei.(2020).cross
‑
spectrum dual
‑
subspace pairing for rgb
‑
infrared cross
‑
modality person re
‑
identification.
[0015]
[8]zhang,ziyue&jiang,shuai&huang,congzhentao&li,yang&xu,richard.(2020).rgb
‑
ir cross
‑
modality person reid based on teacher
‑
student gan model.
[0016]
[9]wang,guanan&zhang,tianzhu&cheng,jian&liu,si&yang,yang&hou,zengguang.(2019).rgb
‑
infrared cross
‑
modality person re
‑
identification via joint pixel and feature alignment.
[0017]
[10]zhu,yuanxin&yang,zhao&wang,li&zhao,sai&hu,xiao&tao,dapeng.(2019).hetero
‑
center loss for cross
‑
modality person re
‑
identification.neurocomputing.386.10.1016/j.neucom.2019.12.100.
[0018]
[11]wang,zhixiang&wang,zheng&zheng,yinqiang&chuang,yung
‑
yu&satoh,shin'ich.(2019).learning to reduce dual
‑
level discrepancy for infrared
‑
visible person re
‑
identification.618
‑
626.10.1109/cvpr.2019.00071.
[0019]
[12]hao,yi&wang,nannan&gao,xinbo&li,jie&wang,xiaoyu.(2019).dual
‑
alignment feature embedding for cross
‑
modality person re
‑
identification.57
‑
65.10.1145/3343031.3351006.
[0020]
[13]ye,mang&lan,xiangyuan&leng,qingming.(2019).modality
‑
aware collaborative learning for visible thermal person re
‑
identification.347
‑
355.10.1145/3343031.3351043.
[0021]
[14]liu,haijun&cheng,jian.(2019).enhancing the discriminative feature learning for visible
‑
thermal cross
‑
modality person re
‑
identification.
[0022]
[15]basaran,emrah&muhittin&kamasak,mustafa.(2020).an efficient framework for visible
‑
infrared cross modality person re
‑
identification.signal processing:image communication.87.115933.10.1016/j.image.2020.115933.
[0023]
[16]pingyang,dai&ji,rongrong&wang,haibin&wu,qiong&huang,yuyu.(2018).cross
‑
modality person re
‑
identification with generative adversarial training.677
‑
683.10.24963/ijcai.2018/94.
[0024]
[17]wang,guanan&zhang,tianzhu&cheng,jian&liu,si&yang,yang&hou,zengguang.(2019).rgb
‑
infrared cross
‑
modality person re
‑
identification via joint pixel and feature alignment.
[0025]
[18]sun,y.,zheng,l.,yang,y.,tian,q.,&wang,s.(2018).beyond part models:person retrieval with refined part pooling.arxiv,abs/1711.09349.
[0026]
[19]wang,guanshuo&yuan,yufeng&chen,xiong&li,jiwei&zhou,xi.(2018).learning discriminative features with multiple granularities for person re
‑
identification.
[0027]
[20]ge,y.,chen,d.,&li,h.(2020).mutual mean
‑
teaching:pseudo label refinery for unsupervised domain adaptation on person re
‑
identification.arxiv,abs/2001.01526.
技术实现要素:
[0028]
为了解决以上现有技术中存在的不足,需要采取更为有效的方法处理两个不同模态,rgb模态和ir模态之间的差异,形成更加合理的特征空间,便于后续的检测和匹配。为了实现相应的目的,不仅需要处理单模态下不同身份样本之间的相似性关系,更要处理跨模态下同身份样本的相似性关系,达到最终通过一模态query检测另一模态相同样本的目的。
[0029]
本发明提出一种多尺度结合的双流网络结构,既能同时处理两个模态的异质样本信息,提取样本中的模态共有特征,又能通过全局尺度和局部尺度的特征融合形成更加具有表征能力的特征,设计合理,满足建模需求,具有良好的效果。
[0030]
为实现上述目的,本发明采用的技术方案为:
[0031]
一种高准确率的跨模态行人重识别方法,包括如下步骤:
[0032]
步骤1,从数据集中获取真实的监控环境下的行人视频信息,对整段的行人视频信息进行预处理得到行人图像样本,将视频中的关键行人图像进行截取并标记相应的行人身份信息;
[0033]
步骤2,搭建多尺度结合的双流跨模态深度网络,初始化网络参数,使用步骤1中得到的行人图像样本,行人身份信息作为监督信息,对所述双流跨模态深度网络进行有监督的训练,训练结束后,根据最终的训练效果,对双流跨模态深度网络中的超参数进行微调,
并固定网络参数;
[0034]
步骤3,将感兴趣行人目标query作为所述双流跨模态深度网络的输入,双流跨模态深度网络将给出与query目标相似程度较高的行人目标列表,相似性从高到低,操作者根据行人目标列表,找到其中的同身份行人目标,进行行人追踪。
[0035]
所述步骤一中,预处理后的行人图像样本包括包含行人身体样貌特征的图像本身、图像样本对应的行人身份信息、以及行人图像样本原本的视频序列信息。
[0036]
所述步骤1中,数据集为sysu
‑
mm01真实数据集。
[0037]
所述步骤2中,双流跨模态深度网络使用pytorch模型库中的在imagenet上进行过预训练的resnet
‑
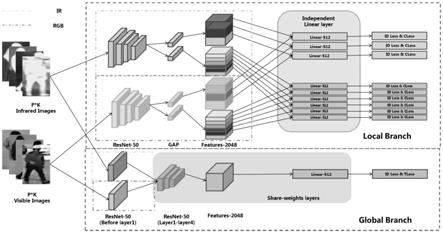
50作为骨架网络;双流跨模态深度网络分为local分支和global分支,每个分支都包含双流结构,用以处理两个模态的样本特征。
[0038]
所述步骤2中,global分支中将resnet
‑
50中的layer0部分作为双流的结构,后面的layer1至layer4作为共享参数的网络结构;双流部分不共享参数,分别提取两个模态的特征,保留部分模态特征信息,共享参数网络部分提取两种不同模态样本的模态共享特征,并继续利用共享特征进行后续的优化操作;后续的优化操作包括:利用线性层将所提取的特征进行降维,减少模型参数量,降低计算负担,得到最终的特征之后,利用难负样本三元组损失和交叉熵损失对特征空间进行优化,交叉熵损失用于优化模态内的样本关系,三元组损失用于优化模态间的样本关系;
[0039]
local分支包括两个子分支,分别对样本进行了三块及六块的切分;local分支的双流结构为将resnet
‑
50的所有层均不进行参数共享,保留更多的模态特征,在backbone后利用global average pooling层将样本特征进行水平分割,切分为三块的对应人体的头部、上半身及下半身,六块的则对应更为精细的人体部位;两个模态样本的特征经过切割之后进行连接,并进入共享参数的线性层进行降维,之后所切分的每一个特征块单独进行目标函数的优化;其中,采用交叉熵函数优化模态内的特征空间;引入基于簇中心的目标函数,利用同身份样本的簇中心实现同身份样本距离更近,异特征样本距离更远的优化目标;
[0040]
在最终的匹配检测阶段,所有的local分支的特征以及global分支的特征会被连接以形成一个更具有表征区分能力的描述子。
[0041]
本发明的有益效果是:
[0042]
(1)本发明从大规模真实的跨模态行人样本数据集中发掘有效的匹配方式,不同于现有的跨模态行人重识别方法,本方法是多尺度结合的特征表征方法,不仅有传统方法中粗粒度的表征特征,同时融合了相应的细粒度的样本局部特征,提升了方法的表征区分能力。
[0043]
(2)本发明引入了基于簇中心的目标函数,能够更加有效的处理模态之间的特征空间,同时这种新的目标函数适应局部特征的优化方式,不会引入相应的负面作用,极大的提高了方法的准确率。能够有效处理模态间的差异,该目标函数使用欧氏距离作为度量标准,利用身份相同的样本特征的平均值作为簇中心,以差值作为计算目标,拉近跨模态同身份的样本之间的距离,并利用超参数作为margin,利用差值扩大跨模态异身份的样本之间的距离,以形成良好的特征空间。
[0044]
(3)本发明引入了异构的双流网络结构,用共享层较多的网络结构处理全局信息,用共享层较少的网络结构处理局部信息,各自满足相应分支的目标函数的要求,进一步提
升了跨模态的处理能力。
[0045]
(4)本发明实现了全局粗粒度特征与局部细粒度特征的结合。global分支中所提取的全局特征能提供较为全面的样本信息,同时local分支能够在切分特征的基础上提供较为精细的局部特征,弥补全局特征中所缺少的细节信息,提升模型的区分能力。
附图说明
[0046]
图1为双流跨模态深度网络的结构示意图。
具体实施方式
[0047]
下面对本发明做更进一步的说明。
[0048]
本发明的一种高准确率的跨模态行人重识别方法,包括如下步骤:
[0049]
步骤1,数据准备及形式化定义:行人重识别的原始数据通常为监控视频,需要人工或者算法将其中的关键行人信息裁剪出来。此方式是基于图像的跨模态行人重识别算法,因此需要使用图像识别及裁剪算法作为前置方法,将视频片段中的行人图像裁剪,并标记相应的行人身份信息,用以区分不同的行人目标。本发明中,使用了sysu
‑
mm01真实数据集,并且数据集没有进行深度的人工标注,存在一定的噪声标签,符合实际的应用场景。对整段的行人视频信息进行预处理得到行人图像样本,将视频中的关键行人图像进行截取并标记相应的行人身份信息;预处理后的行人图像样本包括包含行人身体样貌特征的图像本身、图像样本对应的行人身份信息、以及行人图像样本原本的视频序列信息。
[0050]
步骤2,搭建多尺度结合的跨模态双流行人重识别网络:按照如图1所示的模型示意图,搭建相应的网络结构。使用步骤1中得到的行人图像样本,行人身份信息作为监督信息,对所述双流跨模态深度网络进行有监督的训练,训练结束后,根据最终的训练效果,对双流跨模态深度网络中的超参数进行微调,直至达到相对较好的效果,并固定网络参数。
[0051]
使用pytorch模型库中的在imagenet上进行过预训练的resnet
‑
50作为模型的骨架网络。模型分为local分支和global分支,每个分支都包含双流结构,用以处理两个模态的样本特征。双流网络本质上是并行的同结构不共享参数的网络,使用双流网络结构处理跨模态任务,可以保留部分模态独有特征方便后续进行优化操作。
[0052]
global分支中将resnet
‑
50中的layer0部分作为双流的结构,后面的layer1至layer4作为共享参数的网络结构。双流部分不共享参数,分别提取两个模态的特征,保留部分模态特征信息,共享参数网络部分旨在提取两种不同模态样本的模态共享特征,并继续利用共享特征进行后续的优化操作。后续利用线性层将所提取的特征进行降维,减少模型参数量,降低计算负担,得到最终的特征之后,利用难负样本三元组损失和交叉熵损失对特征空间进行优化,交叉熵损失旨在优化模态内的样本关系,三元组损失旨在优化模态间的样本关系。难负样本三元组损失表示为:
[0053][0054]
其中,p为每个mini
‑
batch中随机选择出的p个行人身份标签,k为每个行人标签所选择的行人样本数目,因此每个mini
‑
batch共有p*k个样本。f表示模型对样本进行提取特
征的操作,d为衡量标准,采用欧式距离判定两个样本的距离。
[0055]
交叉熵损失表示为:
[0056][0057]
其中,f表示经过网络提取的样本特征,w为相应的同维度的权重向量。
[0058]
local分支包括两个子分支,分别对样本进行了三块及六块的切分。local分支的双流结构不同于global分支,其结构为将resnet
‑
50的所有层均不进行参数共享,保留更多的模态特征,方便进行后续优化。在backbone后利用global average pooling层将样本特征进行水平分割,切分为三块的对应人体的头部、上半身及下半身,六块的则对应更为精细的人体部位。两个模态样本的特征经过切割之后进行连接,并进入共享参数的线性模块进行降维,之后所切分的每一个特征块单独进行目标函数的优化。线性模块包括三个操作,线性层降维,relu函数重新激活以及normalize进行正则化。同样的,交叉熵函数主要优化模态内的特征空间。引入基于簇中心的目标函数,旨在利用同身份样本的簇中心实现同身份样本距离更近,异特征样本距离更远的优化目标。基于簇中心的目标函数表示为:
[0059][0060]
其中,||表示求算欧氏距离,加和平均计算求解同身份样本簇中心并拉近,异身份样本簇中心在超参数μ的作用下逐渐远离。
[0061]
在最终的匹配检测阶段,所有的local分支的特征以及global分支的特征会被连接以形成一个更具有表征区分能力的描述子。
[0062]
本发明中,使用标记好的行人样本数据对模型进行训练,训练周期为80个,学习率设为0.01,并随着训练周期逐渐下降,每20个下降为本身的0.1。在整个训练周期结束之后,将模型训练过后的参数进行保存,方便后面的检测处理。
[0063]
步骤3,将需要进行检测的行人目标图像进行整理,选择特征较多的图像作为query图像传入训练后的模型,将所有的监控录像生成的行人样本图像作为检测集进行检测匹配,模型将输出匹配度高的行人样本,相似程度由高到低排列,操作者根据行人目标列表,找到其中的同身份行人目标,进行行人追踪。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1