一种基于多头注意力机制的连续兴趣点包推荐方法
本发明涉及兴趣点推荐技术领域,具体地说,涉及一种基于多头注意力机制的连续兴趣点包推荐方法。
背景技术:
随着移动社交平台的快速发展,人们每天会在各种平台分享自己的行程。这样的行为使我们获得了大量用户打卡数据。这些打卡数据有助于帮助我们建立一种兴趣点的推荐系统,提高用户在城市中的体验。
高效的推荐系统不仅可以带给服务商流量和利润,同时,还可以帮助用户计划后续一段时间的行程安排。传统的推荐兴趣点推荐算法往往没用考虑到最近访问的兴趣点相互的影响,这导致系统性能还有很大的提升空间。现有技术通过用户自身偏好对用户没有访问过的兴趣点进行推荐,但是一方面它使用的是传统协同过滤的思想对冷启动和数据稀疏性的处理能力不够好。另一方面它仅仅考虑了用户偏好对未访问兴趣点的影响而没有考虑到历史访问兴趣点对下一兴趣点访问的影响。还有一种技术通过语境、广告、受众三者的最佳匹配来找出个性化的推荐。虽然该技术考虑的因素很多,但是对于兴趣点推荐来说,它没有把握兴趣点与时间的关系。因为从大规模数据来看,用户访问兴趣点具有明显的周期性。且以上两种技术都是对用户接下来几天内甚至几个月内的兴趣点进行割裂式推荐。使得用户被推荐的兴趣点单一且不符合用户当下的需求,这在实际应用中实用性不强无法适应快速的社会发展。
因此,如何为用户提供连续兴趣点包推荐成为了本领域的技术人员需要解决的一个问题。
技术实现要素:
本发明的内容是提供一种基于多头注意力机制的连续兴趣点包推荐方法,其能够克服现有技术的某种或某些缺陷。
根据本发明的一种基于多头注意力机制的连续兴趣点包推荐方法,其包括以下步骤:
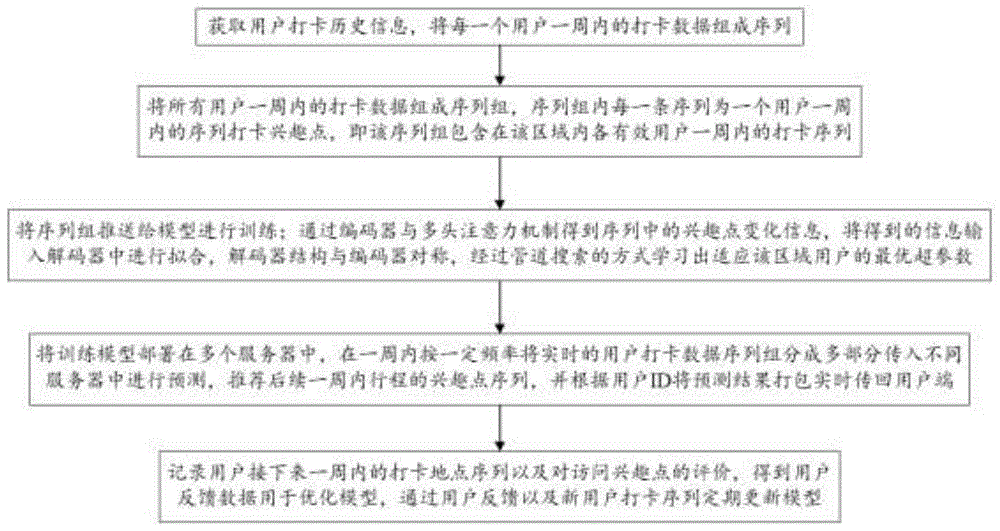
步骤一、获取用户打卡历史信息,将每一个用户一周内的打卡数据组成序列;
步骤二、将所有用户一周内的打卡数据组成序列组,序列组内每一条序列为一个用户一周内的序列打卡兴趣点,即该序列组包含在该区域内各有效用户一周内的打卡序列;
步骤三、将序列组推送给模型进行训练;通过编码器与多头注意力机制得到序列中的兴趣点变化信息,将得到的信息输入解码器中进行拟合,解码器结构与编码器对称,经过管道搜索的方式学习出适应该区域用户的最优超参数;
步骤四、将训练模型部署在多个服务器中,在一周内按一定频率将实时的用户打卡数据序列组分成多部分传入不同服务器中进行预测,为用户推荐后续一周内行程的兴趣点序列,并根据用户id将预测结果打包实时传回用户端;
步骤五、记录用户接下来一周内的打卡地点序列以及对访问兴趣点的评价,得到用户反馈数据用于优化模型,通过用户反馈以及新用户打卡序列定期更新模型。
作为优选,步骤一中,从移动应用运营商大数据平台中获取用户打卡历史信息,用户打卡历史信息包括用户id、打卡地点、打卡时间、打卡经纬度和用户评分。
作为优选,步骤二中,组成序列组后,对序列组进行清洗,剔除一周内打卡次数少的序列。
作为优选,步骤二中,清洗是将打卡次数少于5次的新用户剔除,剔除少于5次被打卡的兴趣点,剔除一周内打卡少于10次的序列。
作为优选,步骤三中,模型采用深度学习的方式,并在tensorflow框架上进行模型训练。
作为优选,步骤三中,将序列组分为训练集,测试集和验证集,将训练集推送给模型进行训练,通过以多头注意力为基础的编码器中进行编码,并于用户id嵌入向量进行拼接;将得到的向量输入至与编码器结构相似的解码器中解码得到一个包序列兴趣点;然后将得到的包序列兴趣点与目标兴趣点序列进行对比,降低损失;通过验证集来保证模型的有效性后,输入测试集进行测试,如果有过拟合现象则重新训练模型,没有则暂时部署该模型。
与现有技术相比,本发明具有以下优点:
(1)本发明采用多头注意力机制的连续兴趣点包推荐系统,能够根据一周内用户打卡序列对用户后续行为进行连续兴趣点包推荐,综合考虑了用户偏好,兴趣点的地理影响以及兴趣点在长序列中所起的影响力大小,将用户在一周内后续最有可能访问的兴趣点序列推荐给用户,对用户在一周内的后续所有兴趣点序列进行推荐。采用编码器与解码器的方式,编码与解码基础结构采用多头注意力机制和残差网络对用户序列特征进行建模,最后将学习到的模型部署在线上,及时用户后续一周内的兴趣点访问序列进行推荐,改变了过往对用户几天后甚至几个月后兴趣点偏好的预测,并且为用户推荐后续一周内访问兴趣点的最佳序列,是一个针对用户已访问历史序列和用户偏好,将后续一周内可能访问的兴趣点序列打包一次性推荐给用户。
(2)本发明将模型部署在服务器上,集中预测一个地区内所有打卡用户的下一阶段的兴趣点序列,以达到对用户行程安排的辅助的目的。本发明的模型也可部署在移动设备上,方便对用户行为特征更加个性化的拟合,部署在移动设备的模型,可对兴趣点打卡频繁的用户根据实际需求调整模型大小以及超参数,提高用户在日程行为安排上的体验感。
(3)本发明通过使用位置编码的方式并行的处理序列数据,并且在编码中采用的是结构简单且有效的多头注意力机制和残差网络的形式,该方法使我们的模型能够快速拟合,这种拟合速度的加快能够帮助我们处理更大规模的数据量和用户群,在模型部署及更新上迭代数据更快。本发明的目标是为用户后续一周内的行程安排做规划,用户历史序列的长度更加的长,其中具备的隐含信息量很大,所以使用该模型提高拟合速度,以具备优秀的部署能力。
(4)本发明采用对称的解码方式,并且在解码前与用户嵌入拼接,对特定用户一周内的后续行为进行拟合,该方式使我们实现对用户一周内行程安排的个性化包推荐,即为用户提供后续一系列的个性化行程安排建议,该模型既对来该区域的游客有意义,也对在该区域内长久居住的人群有意义。
(5)本发明通过收集用户对于模型推荐的兴趣点序列的打卡情况,以及对于各兴趣点的评价情况调整模型。通过微调操作,即使对模型进行迭代,以适应社会的快速发展以及用户偏好的迁移。
附图说明
图1为实施例1中一种基于多头注意力机制的连续兴趣点包推荐方法的流程图。
具体实施方式
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
实施例1
如图1所示,本实施例提供了一种基于多头注意力机制的连续兴趣点包推荐方法,其包括以下步骤。
步骤一、从移动应用运营商大数据平台中获取用户打卡历史信息,用户打卡历史信息包括用户id、打卡地点、打卡时间、打卡经纬度和用户评价,将每一个用户一周内的打卡数据组成序列。
步骤二、将所有用户一周内的打卡数据组成序列组,序列组内每一天序列为一个用户一周内的打卡序列兴趣点,即该序列组包含该地区有效用户一周内的打卡序列;然后对序列组进行清洗,剔除一周内打卡次数少的序列。清洗是将打卡次数少于5次的新用户数据剔除并且剔除少于5次打卡的兴趣点。
步骤三、将序列组分为训练集,测试集和验证集,将训练集推送给模型进行训练,通过编码解码、多头注意力机制与残差网络的结构对用户一周内的长打卡序列进行建模,该结构能够对用户一周内的打卡行为进行编码,将一周内用户行为语义进行压缩。并且能够学习到这段序列中的兴趣点在不同位置时的影响力大小,这对我们进行后续推荐有着实际的对比意义。最后我们将用户id嵌入向量与语义向量进行拼接,得到这一地区内的不同用户的偏好情况;模型采用深度学习的方式,并在tensorflow框架上进行模型训练。对于后续收集的用户数据直接将其分成训练集和测试集,将历史模型当作与训练模型,进行微调操作,对模型进行更新;之后根据用户反馈以及模型所产生影响力的合理性对模型进行调整。通过验证集来保证模型的有效性后,输入测试集进行测试,如果有过拟合现象则重新训练模型,没有则暂时部署该模型。
模型训练具体为:对每个用户一周内的打卡行为进行编码处理,编码的方式采用多头注意力机制与残差网络。具体的实施包括:对每个用户一周内兴趣点进行嵌入位置编码处理,再过编码层学习一个用户一周内的打卡行为的编码向量。
其中,上式i为兴趣点在全部兴趣点中的位置,pos为兴趣点在序列中所占的位置,dmodel为需要编码的长度,从此得到每个兴趣点在一段序列中的位置编码,代码如下:
此操作能够对一段序列进行位置编码,使得利用多头注意力机制并行的处理序列数据,此操作将大大减少运算量,以适用于用户量大,用户打卡序列长的情况下。接下来使用多头注意力机制与残差网络的形式对用户一周内的序列进行编码,以得到每一个用户的行为特征以及每个兴趣点在不同位置时的影响力大小。学习到的影响力向量为:
multihead(q,k,v)=concat(head1,...,headh)wo;
headi=attention(qwiq,kwik,vwiv);
其中,q为查询向量,k为键向量,v为值向量,我们采用的是自注意力机制,通常三者相等,headi代表多头注意机制的头数,concat中将每一个头所学习到的向量进行拼接,再通过权重参数wo得到多头注意力机制所编码向量,代码如下:
步骤四、将训练模型部署在多个服务器中,在一周内按一定频率将实时的用户打卡数据序列组分成多部分传入不同服务器中进行预测,推荐后续一周内行程的兴趣点序列,并根据用户id将预测结果打包实时传回用户端;即将训练好的模型部署在多个服务器中,在一周内按一定频率及时对用户后续行为进行打包式的推荐,为用户的行程规划提供便利,根据用户id为特定的用户进行个性化的推荐,及时将结果传回用户端。
步骤五、记录用户接下来一个阶段内打卡地点以及对兴趣点的评分,得到用户反馈数据用于优化模型,通过用户反馈及新用户打卡序列定期更新模型。
本实施例重点阐述部署在服务器上,但不局限于服务器中还包括各品牌移动端,当在用户端部署专有的模型后,本实施例可以更及时地对用户进行推荐并收集数据。在收集到用户一周内的打卡序列后,可以及时将该序列输入到本产品模型中进行预测,并定期根据用户反馈更新模型。
本实施例中,更新的模型重新部署在服务器,然后观测更新后一段时间内用户的反馈情况,若是用户反馈模型效果明显下降,则重复步骤三,找到合适的推荐模型。
本实施例灵活使用位置编码以及多头注意力机制的形式计算兴趣点在中长期内的影响力大小,该影响力越大代表用户打卡此兴趣点后对后续一周内的行为有很大影响。比如:用户在某风景名胜地登过山,则该用户在后续一周内都可能不会再去有剧烈运动的地方,例如游泳池,体育馆等。通过该模型我们可以获得一个地区内的兴趣点对用户中长期行为的影响程度,再结合用户对打卡兴趣点的评价,我们整理出这样的排名用于优化我们的推荐列表,使得我们的推荐系统更加适应被部署地区的生产活动。
日常的生活告诉我们,我们大多数用户通常以一个星期为周期进行活动,我们这样的实验方法有助于我们更好的学习到用户在中长期内的行为特征,该特征能够帮助我们分析一个城市居民活动的大数据情况,帮助我们对舆情的检测。
线下实验所使用数据为instagram,这是最流行的基于手机的社交网络之一。instagram数据不仅包括用户的兴趣点签到信息,还包括用户写的文字内容。该数据集删除了少于5个嵌入的兴趣点和少于10个评论的用户。在预处理后,我们的数据集有2216631个签入,13187个兴趣点,78233个用户,并且从其中提取了337073条日打卡序列,用作训练模型。
线上数据通过采集大数据平台的活跃用户数据而得,通过流式处理定期采集的数据,就可以具备对用户群体内各个用户一周内及时推荐合适兴趣点的功能并且能够及时更新推荐系统。
本实施例设计出一种为用户后续一周内活动兴趣点的包推荐方法且具备及时更新的能力,通过多头注意力机制处理并行的处理数据的方式,大大减少模型的训练时间,并且占用很少的存储空间对用户进行后续兴趣点的包推荐,从而实现根据用户历史数据为用户推荐接下来一周内的兴趣点访问行程推荐。本实施例的具体优势是在面对庞大用户量以及用户打卡数据序列非常多的情况下,我们没有使用循环神经网络来串行处理数据,相反我们对用户一周内的序列进行位置编码处理,将其通过一系列操作并行的输入至模型中处理序列信息,该操作使我们在保留了推荐系统的能力下,大大减少了计算时间和预测时间。这在实际应用中能够帮助我们更及时的对用户在一周内这样的中远周期的行为预测。具有很强的实际应用能力,且无需在过多服务器中部署本模型也依旧能够做到及时为大量用户的行程安排提供便利。本实施例的主要特征是对用户一周内的后续行为进行推荐,该方式能够适应游客以及长久居住的居民,它既能为游客设计出一套最优的参观路线,也能为长久居住的居民近期行程安排提供个性化的建议。
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!