一种基于异质信息网络表示学习和词向量表示的学术论文同名排歧方法
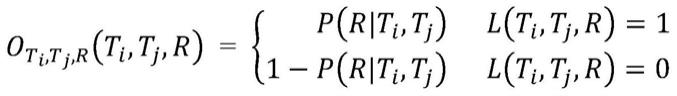
1.本发明主要涉及实体排歧,异质网络嵌入技术和深度学习领域,具体是一种基于异质信息网络表示学习和词向量表示的学术论文同名排歧技术。
背景技术:
2.在这个电子信息化时代,大规模学术数字图书馆在学术界的重要性日趋明显,包括国内的知网、百度学术、aminer,国外的dblp、citeseer、arxiv、google scholar等,这些数字图书馆系统吸引了海量的学者用户。在这些系统中收录了大量的学术期刊、论文以及学者信息,并且提供有助于文献研究和发现服务以及其他类型的功能。这样的数字图书馆系统可能会列出数以百万计的书目文献记录,它们允许集中搜索和查找相关出版物,现已成为学术界的重要信息来源。但因为此类数字图书馆数据量巨大,大量学术文章不能很好的匹配其作者,存在明显的同名歧义问题。目前已经有很多学者针对同名排歧问题提出了一系列的方法。大多数现有的排歧方法是基于特征的,利用论文自身的特征内容,如标题、摘要、关键词、出版期刊会议等信息来学习论文之间的相似性,进而通过语义表示学习将语义信息表示成词向量的形式,用于聚类,使得相似性度高的文章聚到一簇。近年来,一些网络表示学习方法在同名排歧问题上取得较好效果,如deepwalk,node2vec等,构造论文信息网络,之后对其进行聚类,从而达到同名排歧的目的。
技术实现要素:
3.为了解决大型数字图书馆中学术论文同名歧义的问题,本发明提供了一种基于网络表示学习和词向量表示对学术论文中同名歧义问题进行排歧的方法。该方法主要是利用论文的相关特征信息,包括论文的题目、论文的作者、论文所发表的期刊(会议)、论文作者所在机构、论文的摘要、关键词等。通过论文的文本信息,包括题目,摘要,关键词发表期刊(会议)等挖掘论文的语义信息,生成表示论文的语义向量;通过构建论文异质信息网络,学习生成论文间的关系向量;给论文的语义向量和关系向量赋不同的权值生成一个新的向量,该向量即表示一篇文章,通过计算两两向量(文章)之间的相似性生成相似性矩阵;对生成的论文相似性矩阵进行聚类,不同的作者的文章被分配到不同簇中,从而实现了学术论文中同名排歧。
4.本发明的具体步骤如下:
5.步骤一:对论文数据集中的数据进行去重处理。将论文的题目,发表期刊(会议),关键词,摘要以及作者的机构信息归为论文的语义信息;将论文的作者信息及作者的机构信息归为论文的关系信息。
6.步骤二:在步骤一的基础上,合并每篇文章的语义信息生成一段文本,对此段文本进行分词去停用词以及大小写转化生成最终用于训练的文本信息,通过fasttext训练生成词向量,从而获得每篇文章的语义表示向量。
7.步骤三:在步骤一的基础上,构建论文的异质信息网络,该网络包含一种类型的节点和两种类型的边。给定论文训练数据集d,通过hin2vec模型预测论文异质信息网络中两个节点t
i
和t
j
是否具有特定的关系r,同时学习网络中节点的向量表示,为了最大化目标函数o,同时简化计算,在训练时转化为最大化其对数函数为:
[0008][0009]
其中t
i
和t
j
代表论文异质信息网络中两个节点,即两篇文章,r代表两个节点是否存在特定关系。
[0010]
在训练时,训练数据集是通过以下四元组的形式给出:
[0011][0012]
其中p(r|t
i
,t
j
)表示网络中节点t
i
和t
j
存在关系r的概率,l(t
i
,t
j
,r)是一个二进制值,当其等于1是指在最大化目标函数。简化计算转化为对数函数如下:
[0013][0014]
步骤四:对每篇文章的关系向量和语义向量赋不同的权值生成最终表示每篇文章的向量:
[0015][0016]
其中α和β代表不同权重值,和代表步骤二和步骤三所生成的文章的语义向量和关系向量。
[0017]
最后通过上述得到的每篇文章的表示向量计算每两篇文章的相似性,生成相似性矩阵。
[0018]
步骤五:利用dbscan对步骤四生成的相似性矩阵进行聚类,聚类结果中的每一个簇代表论文集的真实作者。
[0019]
技术方案:
[0020]
一种基于异质信息网络表示学习和词向量表示的学术论文同名排歧方法,其步骤包括:
[0021]
1)提取待排歧论文数据集中的语义文本信息和关系信息。
[0022]
2)基于论文的语义文本信息通过fasttext生成论文的语义表示向量。具体步骤是把每篇论文的题目,摘要,关键词,发表期刊(会议)和作者机构信息合并成一条短文本信息,对生成的的短文本统一转化为小写。
[0023]
进而对上述短文本通过分词技术、去停用词技术生成训练语料库。进而通过fasttext对上述语料库训练生成词向量。
[0024]
3)基于论文的关系信息构建论文异质信息网络。然后基于构建的异质信息网络预测两篇文章是否存在特定的关系,学习生成每篇文章的关系向量。
[0025]
上述步骤3)中构建的异质信息网络中每个节点代表数据集中一篇文章,同时异质
网络中定义一定的关系,如果两篇文章之间有一定的关系,则在这两篇文章对应节点之间建立一条边,进而构建出论文集的异质信息网络。
[0026]
上述关系包括共同合作者,共同合作者机构两种关系。
[0027]
上述步骤3)在学习生成关系向量时,首先是采用随机游走模型策略和负采样生成训练数据,然后,采用hin2vec模型训练学习异质信息网络中每个节点的向量表示。
[0028]
上述步骤3)中极少数一部分文章无法与其他文章构建合作关系,这类文章无法为其生成关系向量,因此在后续处理时只使用其语义向量进行表示。
[0029]
上述步骤3)中通过hin2vec模型训练时,不用于原方式我们采用按照所定义的权重进行游走。在优化函数原模型采用的是sgd,我们采用的是adamw,因为我们发现adamw效率更高。
[0030]
4)对步骤2)生成的文本语义向量和步骤3)生成的关系向量赋不同的权值生成表示每篇文章的向量,然后计算两两文章之间的相似度生成论文集的相似性矩阵。
[0031]
5)对步骤4)生成的相似性矩阵矩阵进行聚类,聚类结果中每一个簇代表其真实作者的文章。
[0032]
有益效果
[0033]
本发明基于论文的文本语义信息和论文之间的关系信息,生成对应的语义向量和关系向量,进而生成相似度矩阵,进行聚类达到排歧的目的。利用hin2vec模型更好的捕捉了嵌入在网络结构的信息,能够更好的预测两篇文章之间的相似性,而fasttext模型能够更好的为低频但是相对重要的单词构造出效果更好的词向量。基于以上,本发明对于学术论文中同名排歧有较好的效果。
附图说明
[0034]
图1本发明整体流程图
[0035]
图2fasttext词粒度示意图
具体实施方式
[0036]
下面结合附图对本发明做更进一步的说明。
[0037]
本发明是基于语义表示向量和异质信息网络生成关系向量以解决学术论文中同名歧义的问题。语义向量的生成是基于论文集的文本信息,包括:论文题目,关键词,摘要,发表期刊(会议)以及作者机构;并通过fasttext模型生成文章的语义向量。关系向量是基于异质信息网络,通过hin2vec学习网络中节点之间的相似性,在构建异质信息网络时用到的论文的关系信息,包括论文的作者和作者机构。本发明的流程图如图1所示。
[0038]
步骤1是对论文集进行预处理,提取所需要的文本信息和关系信息。
[0039]
步骤2是对步骤1中的文本信息就行处理,并通过fasttext训练生成词向量,进而求得表示每篇文章的语义向量。在生成语义向量的过程中,我们首先对论文数据集进行去重处理,即删除论文集中的重复文章;接下来提取所需要的文本信息,包括论文的题目,论文的关键词,论文的摘要,论文所发表的期刊(会议)和论文作者的机构信息,并把上述信息拼接成一段短文本信息,但并不能保证每段文本都包含上述信息,如有的论文可能缺少摘要信息等,对于这种情况我们只保留论文中有的信息即可;紧接着我们对这段短文本进行
小写转化,分词,去停用词操作。保存完每篇文章的文本信息后,我们将其通过fasttext模型训练生成词向量模型,并将模型保存,用于后续每篇文章的语义向量的生成。
[0040]
我们使用python中的gensim.models中的fasttext训练生成词向量模型,具体参设置如下:
[0041]
具体参数数值size100sg0min_n3max_n6
[0042]
基于上表,可以看出我们采用cbow模型为每个词生成的词向量的维度是100维的词向量,不同于word2vec模型,我们采用的fasttext模型可以生成字符级别的词向量,如附图2所示,fasttext模型在训练时,对每个单词可以生成词粒度为3的字符词向量,在训练时我们选择的最短字符长度和最长字符长度分别为3和6。优于其他词向量生成模型的是当某个单词不存在于训练生成的词向量模型中时,可以通过fasttext生成的字符级的词向量生成此单词的词向量。
[0043]
在为每篇文章生成其语义向量阶段,首先提取论文的题目,论文的关键词,论文的摘要,论文所发表的期刊(会议)和论文作者的机构这类文本信息,并对其进行小写转化,分词,去停用词操作后得到表示此篇文章的文本信息,在通过上述训练好的词向量模型为此段文本信息的每个词都生成对应的词向量,通过求这些词向量的均值,进而得出表示这篇文章的语义表示向量。
[0044]
步骤3是通过步骤1中的关系信息构建论文的异质信息网络。首先将每个待排歧的作者名字下的所有文章提取出来,紧接着提取这些文章中除待排歧作者名字外的所有作者名字以及待排歧作者机构外所有其他作者的机构信息。
[0045]
构建时,在异质信息网络中我们设置一种类型的节点,两种类型的边。每个节点代表一篇文章。两个节点之间的边,一种类型是两篇文章如果有共同作者就建立一条co
‑
author类型的无向边,权重方面是两篇文章共同合作者的个数;另一种类型是如果两篇文章中作者机构信息出现共有词就建立一条co
‑
org类型的无向边,权重方面是两篇文章作者机构共有词个数。以此类推,我们便构建好论文的异质信息网络。
[0046]
上述构建过程前,我们首先将提取的合作者进行了小写化处理,同时对于合作者中包含的一些特殊符号,如
‘‑’
、空格等予以删除,只保留合作者姓名小写字符串。对于合作者机构信息,在构建前,我们也将其小写化,并去除了停用词。以上操作均是为了保证论文异质信息网络构建的有效性。
[0047]
在构建好论文的异质信息网络后,通过hin2vec模型预测论文异质信息网络中两个节点t
i
和t
j
是否具有特定的关系r,同时学习网络中节点的向量表示,为了最大化目标函数o,同时简化计算,在训练时转化为最大化其对数函数为:
[0048][0049]
其中d代表论文训练数据集,t
i
和t
j
代表论文异质信息网络中两个节点,即两篇文章,r代表两个节点是否存在特定关系。在训练时,训练数据的论文集是通过以下四元组的
形式给出:
[0050][0051]
其中p(r|t
i
,t
j
)表示网络中节点t
i
和t
j
存在关系r的概率,l(t
i
,t
j
,r)是一个二进制值,当其等于1是指在最大化目标函数。简化计算转化为对数函数如下:
[0052][0053]
通过最大化上述目标函数,预测网络中的两个节点是否存在确定关系,并为网络中每个节点生成向量表示,这个向量即使论文的关系向量。
[0054]
与原hin2vec模型不同的是,我们在进行函数优化的时候采用的是adamw算法,因为我们发现adamw算法比hin2vec模型中的sgd算法效率更高。
[0055]
同时在进行随机游走时hin2vec模型定义只要节点之间有连接边均可以进行游走,但是在应用时我们采用根据权重游走的方式,即在游走过程中,节点会偏向权重更大的边进行游走,这么设置的原因是我们发现采用根据权重游走的方式其排歧效果略好于不根据权重游走的方式。具体的参数设置如下:
[0056]
具体参数数值walk5walk_length20n_epoch5batch_size20
[0057]
对于每个节点,设置的游走次数为5次,每次游走的最长长度为20,生成用于训练的数据。在表示学习阶段,对模型训练5次,每次训练样本为20组,学习每个节点的向量表示,即上述提及的每篇文章的关系向量。
[0058]
步骤4是对基于步骤2为每篇论文生成的文本语义向量和基于步骤3为每篇文章生成的关系向量赋不同的权值生成表示每篇文章的向量:
[0059][0060]
其中α和β代表不同权重值,和代表步骤二和步骤三所生成的文章的语义向量和关系向量。语义向量的权值α我们设置为0.5;关系向量β的权值我们设置为0.5。
[0061]
由于步骤3中并不能保证每篇文章都能和其他文章构建关系,即这部分文章不能学习生成对应的关系向量,这部分文章我们只使用其文本语义向量表示。即语义向量的权值α我们设置为1;关系向量β的权值我们设置为0。
[0062]
在生成每篇文章的向量表示后,通过计算两两向量(文章)的余弦相似度,生成相似度矩阵。
[0063]
步骤5是基于步骤4生成的相似度矩阵进行聚类,实现学术论文中同名排歧。聚类时采用python中sklearn.cluster中dbscan聚类方法进行聚类。具体参数设置如下:
[0064]
具体参数数值
eps0.3min_samples4metricprecomputed
[0065]
聚类过程设置聚类半径为0.3,此距离之内的所有文章会被聚成一簇,每个簇最少文章数为4篇。到此我们已经实现了学术论文中同名排歧任务。
[0066]
我们通过本发明中的方法,按照上述操作步骤,对aminer公开论文数据集中同名问题进行了排歧,并且以精确率(pre.),召回率(rec.),f1值(f1)作为评分标准,具体效果如下表,可以看到,本发明对学术论文中的同名歧义问题有较好的效果。
[0067]
[0068]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1