多模态3D目标检测方法、系统、终端及介质
本发明涉及的是一种3d目标检测方法,具体涉及的是一种基于深度网络的多模态3d目标检测方法、系统、终端及介质。
背景技术:
目标检测是计算机视觉领域的重要方向,并且具有广泛的应用前景和市场价值。随着各种传感器技术和汽车技术的发展,3d目标检测在自动驾驶领域中的作用开始逐渐显现。自动驾驶中的3d目标检测任务最普遍使用的传感器包括相机和激光雷达,对应的数据类型分别为图像和lidar点云。由于图像和lidar点云这两种模态之间信息的互补性,以及逐渐降低的激光雷达价格,所以基于多模态的3d目标检测方法逐渐成为国内外研究的重点。
现有的基于多模态的3d目标检测方法主要分为3类:前融合、后融合、深度融合。1.前融合:在输入端进行的融合,通过将不同的模态进行预处理组合成一种新的表示方式;2.后融合:每个模态都被单独和独立地处理直到最后阶段进行结果层面的融合,这种融合方案允许最后的结果来自于单独的模块,因此具有很大的冗余性;3.深度融合:在神经网络中间层分层地融合不同的模态,允许来自不同模态的特征在中间层中交互信息。
然而,由于图像和lidar点云在数据格式以及分布上都存在着巨大的差异,国内外专家和学者提出了众多的算法模型融合两种不同的模态。对于深度融合而言,大多都集中在将lidar点云投影到2d平面上,然后再与图像信息进行融合。然而,在3d点云投影到2d平面的过程中,不可避免地会产生信息的损失。对于前融合或者后融合而言,融合只发生在输入或者输出端,没有充分利用不同模态数据之间的关联性和互补性。
经过检索发现:
公开号为:cn111860666a,公开日为2020年10月30日的中国发明专利申请《一种基于点云与图像自注意力机制融合的3d目标检测方法》,首先,提出一种基于三维点云的多层三维特征提取方法。然后,提出一种基于图像几何和语义特征投票机制的二维特征提取方法。其次,提出一种几何原则的方法,将二维特征转换到点云的3d检测管道中,并传递到点云结构。最后,提出一种多塔训练方案,优化二维和三维特征梯度融合协同性,并根据融合结果进一步精细化调整。本发明利用相机参数将二维特征提升到三维通道,并用多塔训练方法采用自注意力机制实现二维、三维特征有机梯度融合,克服了固有的基于三维点云稀疏数据检测方法,充分利用图像高分辨率和丰富纹理信息对三维目标检测进行补充优化,来实现精确的三维目标检测。该方法仍然存在如下技术问题:
1、该方法的输入为rgb-d图像,不适用于户外场景的稀疏点云情况。
2、该方法rgb图像候选框的提取与三维点云分支是解耦合的,同时三维点云的分类与rgb图像之间也是解耦的,因此无法充分利用图像与点云之间的互补信息。
公开号为cn110827202a,公开日为2020年02月21日的中国发明专利申请《目标检测方法、装置、计算机设备和存储介质》,获取点云数据以及对应的彩色图像;对所述点云数据以及对应的所述彩色图像进行融合得到融合数据;根据所述融合数据对所述点云数据进行补全得到补全后的点云数据;根据所述融合数据进行目标检测得到中间目标检测结果;从所述补全后的点云数据中,获取所述中间目标检测结果对应的区域的补全后的点云数据;根据所获取的补全后的点云数据,对所述中间目标检测结果进行结果修正得到最终目标检测结果。该方法仍然存在如下技术问题:
1、该方法的点云数据与rgb图像输入的特征融合仅停留在特征拼接的层面上,没有考虑两种模态属性之间的深度关联。
2、该方法的检测结果修正网络的监督信号来自根据融合数据对点云数据进行补全得到的补全后的点云数据,但是由于物体边缘的深度预测不准,补全后的点云会对修正网络引入部分噪声,从而削弱修正网络的性能。
目前没有发现同本发明类似技术的说明或报道,也尚未收集到国内外类似的资料。
技术实现要素:
本发明针对现有技术中存在的上述不足,提供了一种基于深度网络的多模态3d目标检测方法、系统、终端及介质,属于一种基于多模态的深度融合目标检测技术,以原始点云以及图像作为输入,实现多模态3d目标检测。
根据本发明的一个方面,提供了一种多模态3d目标检测方法,包括如下步骤:
分别提取原始图像i和对应的lidar点云l的特征;
将所述原始图像i和对应的lidar点云l的特征进行点和像素的特征融合,形成lidar点云特征,将所述原始图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议;
分别从所述3d区域提议和2d区域提议内提取特征并进行融合,生成最终的3d目标检测结果。
优选地,所述分别提取原始图像i和对应的lidar点云l的特征,包括:
获取原始图像i、对应的lidar点云l、图像特征提取器fei以及lidar点云特征提取器fel;
将所述原始图像i输入到所述图像特征提取器fei,得到原始图像i的特征fi;
将所述lidar点云l输入到所述lidar点云特征提取器fel,得到lidar点云l的特征fl。
优选地,所述将所述原始图像i和对应的lidar点云l的特征进行点和像素的特征融合,形成lidar点云特征,将所述原始图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议,包括:
根据提取得到的所述lidar点云l的特征fl,将所述lidar点云l分为前景点lf和背景点lb,对于所有前景点lf,以lf为中心设置3d锚框a3d;
将所述3d锚框a3d投影到图像平面上,得到对应的2d锚框a2d,形成lidar坐标系下的点与图像坐标系下的像素之间的投影关系;
根据所述投影关系,得到所述原始图像i的特征fi和所述lidar点云l的特征fl之间的对应关系,根据所述对应关系将所述原始图像i的特征fi和所述lidar点云l的特征fl进行点和像素的特征融合;
以融合得到的特征作为lidar点云特征f′l,对所述3d锚框a3d进行回归和分类任务,并计算回归误差
分别取得分最高的前t个2d锚框a′2d和3d锚框a′3d,分别作为2d区域提议pro2d和3d区域提议pro3d;
将所述3d锚框a′3d根据所述投影关系投影到图像平面生成2d锚框a″2d,并计算所述2d锚框a″2d与所述2d锚框a′2d的误差lpro;
构建损失函数
优选地,所述3d锚框a3d尺寸为:长3.9米、宽1.6米、高1.5米。
优选地,lidar坐标系下的点x与图像坐标系下的像素y之间的投影关系为:
其中,f.(i),c.(i),
优选地,α,β,γ分别取1,1,0.5。
优选地,所述分别从所述3d区域提议和2d区域提议内提取特征并进行融合,生成最终的3d目标检测结果,包括:
分别从所述2d区域提议pro2d和3d区域提议pro3d内提取特征
对3d区域提议pro3d进行回归和分类,并计算回归损失l′reg和分类损失l′cls;
构建损失函数lrefinement=l′cls+l′reg,通过最小化该损失函数更新网络参数,直至网络收敛。
根据本发明的另一个方面,提供了一种多模态3d目标检测系统,包括:
初始特征提取模块,该模块分别提取原始图像i和对应的lidar点云l的特征;
区域提议生成模块,该模块将所述原始图像i和对应的lidar点云l的特征进行点和像素的特征融合,形成lidar点云特征,将所述原始图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议;
目标检测模块,该模块分别从所述3d区域提议和2d区域提议内提取特征并进行融合,生成最终的3d目标检测结果。
根据本发明的第三个方面,提供了一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行上述任一项所述的方法。
根据本发明的第四个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述任一项所述的方法。
由于采用了上述技术方案,本发明与现有技术相比,具有如下至少一项的有益效果:
本发明提供的多模态3d目标检测方法、系统、终端及介质,针对现有技术中存在的融合方法没有充分利用图像和lidar点云这两种模态之间的关联性和互补性的问题,利用模态之间的几何约束关系和特征关联性完成目标检测。
本发明提供的多模态3d目标检测方法、系统、终端及介质,提出了一种二阶段的多模态3d目标检测技术,通过第一阶段的点-像素级别和第二阶段的区域提议级别的特征融合,完成了3d目标检测任务。
本发明提供的多模态3d目标检测方法、系统、终端及介质,设计了一种2d-3d锚框耦合机制,通过这个机制可以实现图像与点云之间的动态信息交互。
本发明提供的多模态3d目标检测方法、系统、终端及介质,设计的点-像素级别特征融合能够有效利用图像和lidar点云之间的几何约束,同时实现信息的共享,最终生成高质量的区域提议。
本发明提供的多模态3d目标检测方法、系统、终端及介质,设计的区域提议级别特征融合能够有效学习图像与lidar点云鲁棒的局部特征,实现鲁棒、高质量的检测。
本发明提供的多模态3d目标检测方法、系统、终端及介质,其中数据增强方法获得了比现有技术更高的性能提升。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明一实施例中提供的多模态3d目标检测方法的流程图。
图2为本发明一优选实施例中提供的多模态3d目标检测方法的流程图。
图3为本发明一实施例中提供的多模态3d目标检测系统的组成结构示意图。
具体实施方式
下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
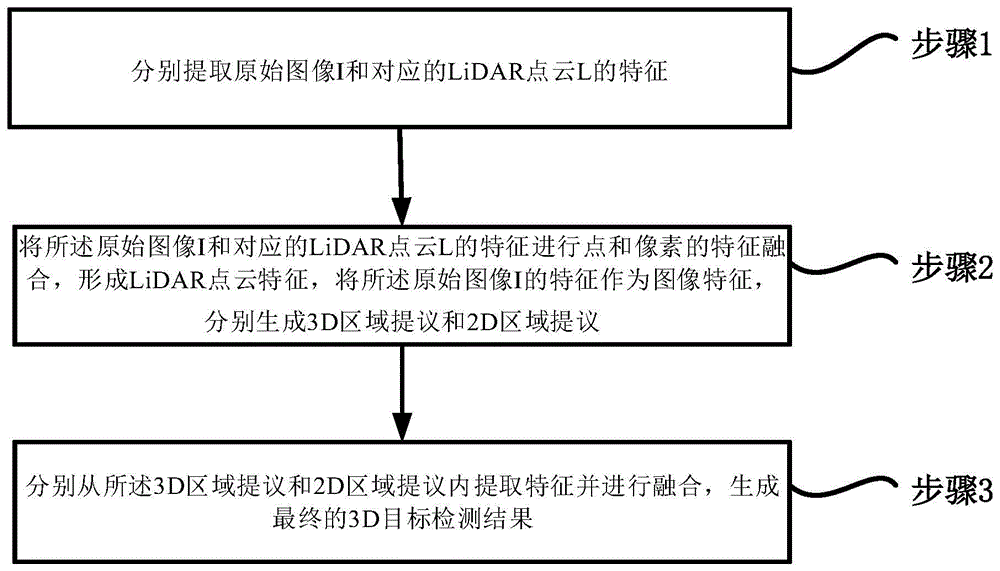
图1为本发明一实施例提供的多模态3d目标检测方法的流程图。
该实施例提供的多模态3d目标检测方法,首先以图像和原始点云作为输入,分别输入独立的特征提取器提取相应特征,然后进行第一阶段的点-像素级别特征融合,生成高质量3d区域提议。然后将3d区域提议对应的图像和lidar点云特征送入第二阶段进行融合,并生成最终的检测结果。
如图1所示,该实施例提供的多模态3d目标检测方法,可以包括如下步骤:
步骤1:分别提取原始图像i和对应的lidar点云l的特征;
步骤2:将步骤1中提取到的特征进行点和像素的特征融合,形成lidar点云特征,将步骤1中提取到的图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议;
步骤3:分别从步骤2中得到的3d区域提议和2d区域提议内提取特征并进行融合,生成最终的3d目标检测结果。
在该实施例的步骤1中,作为一优选实施例,分别提取原始图像i和对应的lidar点云l的特征,可以包括如下步骤:
步骤1.1:获取原始图像i、对应的lidar点云l、图像特征提取器fei以及lidar点云特征提取器fel;
步骤1.2:将原始图像i输入到图像特征提取器fei得到原始图像i的特征fi,同时,将lidar点云l输入到lidar点云特征提取器fel得到lidar点云l的特征fl。
在该实施例的步骤2中,作为一优选实施例,将步骤1中提取到的特征进行点和像素的特征融合,形成lidar点云特征,将步骤1中提取到的图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议,可以包括如下步骤:
步骤2.1:根据步骤1中提取得到的lidar点云l的特征fl,将lidar点云l分为前景点lf和背景点lb,对于所有前景点lf,以lf为中心设置3d锚框a3d;
步骤2.2:将步骤2.1中得到的3d锚框a3d投影到图像平面上,得到对应的2d锚框a2d,得到lidar坐标系下的点与图像坐标系下的像素之间的投影关系;
步骤2.3:根据步骤2.2中得到的投影关系,可以得到原始图像i的特征fi和lidar点云l的特征fl之间的对应关系,根据对应关系将原始图像i的特征fi和lidar点云l的特征fl进行点和像素的特征融合;
步骤2.4:,以步骤2.3中融合得到的特征作为lidar点云特征f′l,对步骤2.1中生成的3d锚框a3d进行回归和分类任务,并计算回归误差
步骤2.5:将步骤2.4中得到的3d锚框a′3d根据步骤2.2中的投影关系投影到图像平面生成2d锚框a″2d,并计算2d锚框a″2d与步骤2.4中2d锚框a′2d的误差lpro;
步骤2.6:构建损失函数
在该实施例的步骤2.1中,作为一具体应用实例,3d锚框a3d尺寸为:长3.9米、宽1.6米、高1.5米。
在该实施例的步骤2.2中,作为一优选实施例,lidar坐标系下的点x与图像坐标系下的像素y之间的投影关系为:
其中,f.(i),c.(i),
在该实施例的步骤2.6中,作为一具体应用实例,α,β,γ分别取1,1,0.5。
在该实施例的步骤3中,作为一优选实施例,提取步骤2中得到的区域提议对应的图像特征和lidar点云特征,并进行特征融合,生成最终的检测结果,可以包括如下步骤:
步骤3.1:分别从2d区域提议pro2d和3d区域提议pro3d内提取特征
步骤3.2:构建损失函数lrefinement=l′cls+l′reg,通过最小化该损失函数更新网络参数,直至网络收敛。
图2为本发明一优选实施例提供的多模态3d目标检测方法的流程图。
如图2所示,该优选实施例提供的多模态3d目标检测方法,可以包括如下步骤:
步骤1:将原始图像i和对应的lidar点云l分别输入到独立的特征提取器中提取特征。
步骤2:将步骤1中提取到的特征进行点-像素级别的特征融合,,形成lidar点云特征,将步骤1中提取到的图像i的特征作为图像特征,并生成高质量3d区域提议和2d区域提议。
步骤3:分别从步骤2中得到的3d区域提议和2d区域提议内提取特征并进行特征融合,生成最终的检测结果。
作为一优选实施例,步骤1包括如下步骤:
步骤1.1:获取输入原始图像i、对应的lidar点云l、图像特征提取器fei、lidar点云特征提取器fel。
步骤1.2:将图像i输入到图像特征提取器fei得到图像特征fi,同时将lidar点云l输入到lidar点云特征提取器fel得到lidar点云特征fl。
作为一优选实施例,步骤2包括如下步骤:
步骤2.1:根据步骤1.2中学习的lidar点云特征fl将点云分为前景点lf和背景点lb,对于所有前景点lf,以lf为中心设置3d锚框a3d,锚框尺寸为:长3.9米,宽1.6米,高1.5米。
步骤2.2:对于步骤2.1中的3d锚框a3d,我们将其投影到图像平面上,得到对应的2d锚框a2d。lidar坐标系下的点x与图像坐标系下的像素y的投影关系为:
其中f.(i),c.(i),
步骤2.3:根据步骤2.2中的投影关系,可以得到步骤1.2中图像特征fi和lidar点云特征fl的对应关系,根据对应关系将fi和fl进行点-像素级别的特征融合。
步骤2.4:以步骤2.3中融合后的特征作为新的lidar点云特征f′l,对步骤2.1中生成的3d锚框进行回归和分类任务并计算回归误差
步骤2.5:将步骤2.4中的3d锚框a′3d根据步骤2.2中的投影关系投影到图像平面生成2d锚框a″2d,并计算a″2d与步骤2.4中a′2d的误差lpro。
步骤2.6:构建损失函数
作为一优选实施例,步骤3包括如下步骤:
步骤3.1:以步骤1中的fi和步骤2中的f′l分别作为图像和lidar点云特征,以步骤2.4中的pro2d、pro3d分别作为2d、3d区域提议,提取区域内特征
步骤3.2:构建损失函数lrefinement=l′cls+l′reg,通过最小化该损失函数更新网络参数,直至网络收敛。
下面结合一具体应用实例,对本发明上述实施例所提供的技术方案进一步描述如下。
以pointrcnn检测器为例子,作为本具体应用实例的基准网络。采用本发明上述实施例提供的方法流程,包括:
第一步:将原始图像i和对应的lidar点云l分别输入到独立的特征提取器中提取特征。
1.1)获取输入原始图像i、对应的lidar点云l、图像特征提取器fei及各项网络参数θ1、lidar点云特征提取器fel及各项网络参数θ2。
其中fei是resnet-50网络,fel是pointnet++网络,θ1和θ2分别是对应的预训练的模型参数。
1.2)将图像i输入到图像特征提取器fei得到图像特征fi,同时将lidar点云l输入到lidar点云特征提取器fel得到lidar点云特征fl。
第二步:将第一步中提取到的特征进行点-像素级别的特征融合,并生成高质量3d区域提议。
2.1)根据pointnet++提取的点云特征fl对lidar分割结果打分,分数大于等于0.3的判定为前景点lf,低于0.3判定为背景点lb。对于所有前景点lf,我们以lf为中心设置3d锚框a3d,锚框尺寸为(长3.9米,宽1.6米,高1.5米)。
2.2)对于2.1中的3d锚框a3d,我们将其投影到图像平面上,得到对应的2d锚框a2d。lidar坐标系下的点x与图像坐标系下的像素y的投影关系为:
其中f.(i),c.(i),
2.3)根据2.2)中的投影关系,我们可以得到1.2中图像特征fi和lidar点云特征fl的对应关系,根据对应关系将fi和fl进行通道连接形成新的特征f′l=(fi|fl),然后将新特征f′l继续送入pointnet++网络中学习。
2.4)以2.3)中融合后的特征f′l作为新的lidar点云特征,对2.1中生成的3d锚框进行回归和分类任务并计算回归误差
2.5)将2.4)中的3d锚框a′3d根据2.2中的投影关系投影到图像平面生成2d锚框a″2d,并计算a″2d与2.4中a′2d的误差lpro。
2.6)构建损失函数
第三步:提取第二步生成的3d区域提议对应的图像和lidar点云特征并进行特征融合,生成最终的检测结果。
3.1)以第一步中的fi和第二步中的f′l分别作为图像和lidar点云特征,以2.4中的pro2d、pro3d分别作为2d、3d区域提议,提取区域内特征
3.2)构建损失函数lrefinement=l′cls+l′reg,通过最小化该损失函数更新网络参数,直至网络收敛。
实施效果:
依据上述步骤,在常用的3d目标检测数据集kitti上进行测试。该数据集被分成了训练集,验证集和测试集。该数据集以3d检测平均精度作为评价指标。表1是本发明在kitti数据集上与现有的3d目标检测方法的性能对比。如表1所示,可以看到本发明上述实施例提供的方法,在基准模型上的提升明显优于其他算法。
表1
本发明另一实施例提供了一种多模态3d目标检测系统,如图3所示,包括:
初始特征提取模块,该模块分别提取原始图像i和对应的lidar点云l的特征;
区域提议生成模块,该模块将所述原始图像i和对应的lidar点云l的特征进行点和像素的特征融合,形成lidar点云特征,将所述原始图像i的特征作为图像特征,分别生成3d区域提议和2d区域提议;
目标检测模块,该模块分别从所述3d区域提议和2d区域提议内提取特征并进行融合,生成最终的3d目标检测结果。
本发明第三个实施例提供了一种终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行本发明上述实施例中任一项所述的方法。
可选地,存储器,用于存储程序;存储器,可以包括易失性存储器(英文:volatilememory),例如随机存取存储器(英文:random-accessmemory,缩写:ram),如静态随机存取存储器(英文:staticrandom-accessmemory,缩写:sram),双倍数据率同步动态随机存取存储器(英文:doubledataratesynchronousdynamicrandomaccessmemory,缩写:ddrsdram)等;存储器也可以包括非易失性存储器(英文:non-volatilememory),例如快闪存储器(英文:flashmemory)。存储器用于存储计算机程序(如实现上述方法的应用程序、功能模块等)、计算机指令等,上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
上述的计算机程序、计算机指令等可以分区存储在一个或多个存储器中。并且上述的计算机程序、计算机指令、数据等可以被处理器调用。
处理器,用于执行存储器存储的计算机程序,以实现上述实施例涉及的方法中的各个步骤。具体可以参见前面方法实施例中的相关描述。
处理器和存储器可以是独立结构,也可以是集成在一起的集成结构。当处理器和存储器是独立结构时,存储器、处理器可以通过总线耦合连接。
本发明第四个实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行本发明上述实施例中任一项所述的方法。
本发明上述实施例提供的多模态3d目标检测方法、系统、终端及介质,针对现有技术中存在的融合方法没有充分利用图像和lidar点云这两种模态之间的关联性和互补性的问题,利用模态之间的几何约束关系和特征关联性完成目标检测;通过第一阶段的点-像素级别和第二阶段的区域提议级别的特征融合,完成了3d目标检测任务;通过2d-3d锚框耦合机制,可以实现图像与点云之间的动态信息交互;点-像素级别特征融合能够有效利用图像和lidar点云之间的几何约束,同时实现信息的共享,最终生成高质量的区域提议;区域提议级别特征融合能够有效学习图像与lidar点云鲁棒的局部特征,实现鲁棒、高质量的检测;数据增强方法获得了比现有技术更高的性能提升。
需要说明的是,本发明提供的方法中的步骤,可以利用系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照方法的技术方案实现系统的组成,即,方法中的实施例可理解为构建系统的优选例,在此不予赘述。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!