基于胶囊网络融合模型的新闻文本分类方法、系统及介质与流程
1.本发明属于深度学习领域,涉及一种基于胶囊网络的融合模型应用于新闻文本分类的方法。
背景技术:
2.新闻是“对新近发生的事实的报道”,使用简练的文字概括了丰富的信息并频繁更新,且通过公开媒体传播。大数据时代的发展,网络丰富了新闻的来源,加速了新闻的传播。截至2020年3月,我国网络新闻用户规模达7.31亿,较2018年底增长5598万,占网民整体的80.9%;手机网络新闻用户规模达7.26亿,较2018年底增长7356万,占手机网民的81.0%。面对新闻数据呈爆炸式增长且缺乏高效管理等问题,增加了读者快速获取有效信息的难度。从海量的新闻文本中获取所需的有效信息是一项在研究和应用方面都具有积极意义的工作,一种高效准确的分类算法可以为新闻文本进行自动分类提供有力的支撑,有助于新媒体传播平台对新闻的管理并且根据用户习惯为用户做个性化推荐。
3.基于深度学习的文本分类方法近年来研究趋热。2006年,hinton首次提出深度学习就引起了学术界和工业界的关注。其中,卷积神经网络(cnn)和循环神经网络(rnn,lstm,gru)等都可以运用在文本分类中。使用深度神经网络模型对海量文本进行分类的基础和关键是文本的特征表示,提取到较理想的浅层语义表示后能在更高层次上对深层语义特征进行抽取,省去了繁杂低效的人工特征工程,在自然语言处理的许多任务中取得了最佳表现。
4.目前,取自网络的新闻文本往往分为标题和正文两部分,其中标题内容通常是新闻全文的精要概括,信息量大,包含了文章的中心内容。但是在文本分类领域中,现有的基于深度学习的研究大多没有考虑标题和正文处理方式,单一的将二者汇合一起进行文本分类,降低了分类的准确率。另一个问题是单一的深度神经网络往往不能够获得最佳的效果,影响了新闻文本分类模型的效率。基于以上问题,本文基于深度学习的新闻文本分类的研究,将考虑标题和正文两部分,同时在分类效率上,将设计一种新型网络融合模型,充分利用模型优点以提高分类效率。
技术实现要素:
5.本发明旨在解决以上现有技术的问题。提出了一种提高分类准确率的基于胶囊网络融合模型的新闻文本分类方法、系统及存储介质。本发明的技术方案如下:
6.一种基于胶囊网络融合模型的新闻文本分类方法,其包括以下步骤:
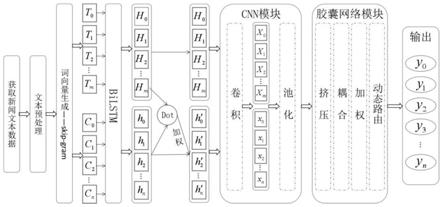
7.步骤一:对新闻文本采用分词与去停用词在内的预处理,并进行词向量生成;
8.步骤二:选择双向长短记忆神经网络bilstm模型对新闻文本进行特征表示;
9.步骤三:根据新闻文本标题与正文的重要程度,引入注意力机制,实现新闻词向量加权;
10.步骤四:通过双向长短记忆神经网络bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示;
11.步骤五:结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络(capsnet,也称之为向量胶囊网络模型)对获得的信息进行聚合,完成文本分类。
12.进一步的,所述步骤一对新闻文本采用分词与去停用词在内的预处理,并进行词向量生成,具体包括:
13.从搜狗实验室数据资源中获取的全网新闻数据,保留12种新闻标签,包括房产house、女性women、运动sports、娱乐yule、信息技术it、教育learning、商业business、军事mil、旅游travel、健康health、汽车auto、文化cul,首先将获取的新闻文本数据集进行预处理操作,包括分词与去停用词,采用的是基于python语言的jieba分词工具,通过增加一些专业词汇来扩充停用词表;词向量生成选择word2vec中的skip
‑
gram模型,skip
‑
gram模型是通过当前词来预测当前词前后单词,将预处理完成的新闻标题与正文文本输入到skip
‑
gram的模型结构中,以获取新闻文本标题与正文的词向量表示,分别表示为t0、t1、t2…
t
m
与c0、c1、c2…
c
n
,其中m表示新闻文本标题个数,n表示正文的词向量个数。
14.进一步的,所述步骤二选择双向长短记忆神经网络bilstm模型对新闻文本进行特征表示,具体包括:
15.采取双向长短记忆神经网络bilstm,bilstm由两个lstm组成的双向通道,包括输入门、遗忘门和输出门,选择bilstm模型对新闻文本进行特征表示,向量化的文本进入bilstm进行上下文语义特征提取,其结构算法如公式(20)、(21)、(22)、(23)、(24)、(25):
16.i
t
=σ(w
i
[h
t
‑1,x
t
]+b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0017]
f
t
=σ(w
f
[h
t
‑1,x
t
]+b
f
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0018]
g=tanh(w
c
[h
t
‑1,x
t
]+b
c
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0019]
c
t
=f
t
·
c
t
‑1+i
t
·
g
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0020]
o
t
=σ(w
o
[h
t
‑1,x
t
]+b
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0021]
h
t
=o
t
·
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(25)
[0022]
其中,x
t
表示此刻新闻标题与正文的输入信息,h
t
‑1表示前一时刻的输出,i
t
表示此刻输入门,f
t
表示此刻的遗忘门,g表示候选的输入,c
t
表示自循环神经元,用于保存序列信息,o
t
表示此刻的输出,h
t
是此刻的输出向量,w表示权重矩阵,b表示偏置向量。
[0023]
进一步的,所述步骤三:根据新闻文本标题与正文的重要程度,引入注意力机制,实现新闻词向量加权,具体为:新闻文本包含两个部分,分别是新闻标题和新闻正文,标题对新闻主题有着总结的作用,将新闻标题编码后与新闻正文的单词表示进行点积,获得每个新闻正文词语的重要程度即注意力权重,然后对新闻正文的单词表示进行加权,使得新闻中更重要的单词得到增强;
[0024]
新闻标题与正文的各个词的向量表示分别为t0、t1、t2…
t
m
与c0、c1、c2…
c
n
,作为输入传入bi
‑
lstm单元,得到对应隐藏层h0、h1、h2…
h
m
与h0、h1、h2…
h
n
,将标题词向量与正文词向量进行点积,对新闻正文词向量进行加权,计算出注意力概率分布值a0、a1、a2…
a
n
,其思想是获取新闻正文词向量的重要程度,最终获得包含文本信息的特征向量v,其运算过程如公式(26)、(27)、(28):
[0025]
[0026][0027][0028]
其中exp表示指数函数,f表示打分函数,其中m表示新闻文本标题个数,n表示正文的词向量个数。
[0029]
进一步的,所述步骤四:通过双向长短记忆神经网络bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示,具体为:
[0030]
cnn模块包含输入层、卷积层、池化层,输入层是新闻文本的向量化表示;卷积与池化层是卷积神经网络模型的核心层,目的是将原始的特征映射到更高层次维度的语义空间,通过bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示,设置3,4,5三种长度的卷积核,进行卷积与池化操作,将词向量加权模块后的输出作为cnn模块的输入,即新闻标题标题h0,h1,h2…
h
m
和加权后的新闻正文表示h
′0,h
′1,h
′2…
h
′
n
,经过cnn的卷积与池化操作,得到新闻标题与正文的特征向量x0,x1,x2…
x
m
与x0,x1,x2…
x
n
。
[0031]
进一步的,所述卷积与池化操作运算过程如下:
[0032]
(一)卷积操作
[0033]
新闻标题词向量表示卷积运算如公式(29):
[0034]
x
i
=f(w1⊙
h
i:i+l
‑1+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(29)
[0035]
其中,x
i
表示新闻标题卷积运算后的结果,w1表示滤波器,b表示偏置量,f表示激活函数,l表示滑动窗口大小,h
i:i+l
‑1表示为由第i到第i+l
‑
1个标题文本词组成的局部特征矩阵,
⊙
表示点乘运算;
[0036]
同理,新闻正文词向量表示卷积运算如公式(30):
[0037]
x
i
=f(w1⊙
h
′
i:i+l
‑1+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(30)
[0038]
(二)池化操作
[0039]
对卷积核产生的新闻标题与正文特征进行最大池化操作如公式(31)、(32):
[0040][0041][0042]
其中,x
i
为新闻标题词向量经卷积运算后的结果,i=0,1,...,n
‑
l+1,x
i
为新闻正文词向量加权后和卷积运算后的结果,表示新闻文本标题与正文经过最大池化运算后的结果。
[0043]
进一步的,所述步骤五结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络对获得的信息进行聚合,完成文本分类,具体为:
[0044]
胶囊网络与传统的神经网络不同,是通过向量来表示属性,即它的神经元是向量而不是标量,涉及到动态路由、输入胶囊、输出胶囊,本文采用的胶囊网络模块包括挤压、耦合、加权、动态路由在内的步骤,其中动态路由算法是胶囊网络模块的核心组件,通过动态路由不断的调整输入胶囊向量与输出胶囊向量的耦合系数,最终预测出输出胶囊向量;结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络对获得的信息进行聚合,完成文本分类,其算法过程如公式(33)、(34)、(35)、(36)、(37)、(38):
[0045][0046][0047][0048][0049][0050]
b
ij
=b
ij
+a
ij
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(38)
[0051]
其中,c
ij
表示耦合系数;i表示输入,j表输出;w
ij
表示变换矩阵,u
i
表示输入
[0052]
胶囊,表示输出胶囊向量,式(34)表示通过变换矩阵,实现输入胶囊与输出胶囊的转换;s
j
表示耦合过程的输出,v
j
表示s
j
通过压缩函数后的胶囊向量;a
ij
表示v
j
对应的预测向量进行点积预算;
[0053]
将cnn模块所提取得到的新闻文本标题与正文的特征作为子阶胶囊向量输入到胶囊网络模块进行文本分类,通过上述的算法,将新闻文本所有向量拼接获得高阶胶囊向量表示y0,y1,y2…
y
n
,最终完成新闻文本分类。
[0054]
一种基于所述方法的胶囊网络融合模型的新闻文本分类系统,其包括:
[0055]
预处理模块:对新闻文本采用分词与去停用词在内的预处理,并进行词向量生成;
[0056]
双向长短记忆神经网络bilstm:选择双向长短记忆神经网络bilstm模型对新闻文本进行特征表示;根据新闻文本标题与正文的重要程度,引入注意力机制,实现新闻词向量加权;通过双向长短记忆神经网络bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示;
[0057]
聚合模块:结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络(capsnet,也称之为向量胶囊网络模型)对获得的信息进行聚合,完成文本分类。
[0058]
一种介质,该介质内部存储计算机程序,所述计算机程序被处理器读取时,执行上述权利要求任一项的方法。
[0059]
本发明的优点及有益效果如下:
[0060]
1、本发明新闻文本往往分为标题和正文两部分,在模型的搭建中,草率的把标题与正文合并作为输入是不科学的,因此本文通过引入注意力机制,对词向量进行加权,即新闻标题编码后与新闻正文的单词表示进行点积,可以获得每个新闻单词的重要程度(也就是注意力权重),然后对新闻内容的单词表示进行加权,使得新闻中更重要的单词得到增强,从而提高分类准确率。
[0061]
2、bilstm关注上下文信息,cnn关注局部而非整体。bilstm对文本长序列有着很好的表示作用,但是新闻内容属于过长的文本内容,仅仅使bilstm会在序列化模型中损失一些信息,本文通过bilstm获得新闻词向量的表示之后,再通过cnn获得句子的局部表示,可
以有效弥补bilstm的一些缺点,并且最终通过胶囊网络对获得的信息进行聚合,获得输出胶囊,可以有效地提升分类效果。
附图说明
[0062]
图1是本发明提供优选实施例基于胶囊网络融合模型的新闻文本分类方法流程图。
具体实施方式
[0063]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
[0064]
本发明解决上述技术问题的技术方案是:
[0065]
如图1所示,在本实施例中,一种基于胶囊网络融合模型的新闻文本分类方法,具体包括以下步骤:
[0066]
步骤一:文本预处理与词向量生成;
[0067]
本次实验数据从搜狗实验室数据资源中获取的全网新闻数据,保留12种新闻标签,包括房产(house)、女性(women)、运动(sports)、娱乐(yule)、信息技术(it)、教育(learning)、商业(business)、军事(mil)、旅游(travel)、健康(health)、汽车(auto)、文化(cul)。首先将获取的新闻文本数据集进行预处理操作,包括分词与去停用词等。采用的是基于python语言的jieba分词工具。通过增加一些专业词汇来扩充停用词表。词向量生成选择word2vec中的skip
‑
gram模型,该模型在数据集较大的情况效果更好。包括输入层、投影层和输出层,通过当前词来预测当前词前后单词。将预处理完成的新闻标题与正文文本输入到skip
‑
gram的模型结构中,以获取新闻文本标题与正文的词向量表示,即t0、t1、t2…
t
m
与c0、c1、c2…
c
n
。
[0068]
步骤二:选择bilstm模型对新闻文本进行特征表示;
[0069]
采取双向长短记忆神经网络(bilstm),其模型结构由两个lstm组成的双向通道,包括输入门、遗忘门和输出门。该模型更关注于全局特征,具备记忆功能,在文本特征表示有着管饭的应用。因此本文利用bilstm对文本长序列有着很好的表示作用,选择bilstm模型对新闻文本进行特征表示。向量化的文本进入bilstm进行上下文语义特征提取,其结构算法如公式(39)、(40)、(41)、(42)、(43)、(44):
[0070]
i
t
=σ(w
i
[h
t
‑1,x
t
]+b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(39)
[0071]
f
t
=σ(w
f
[h
t
‑1,x
t
]+b
f
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(40)
[0072]
g=tanh(w
c
[h
t
‑1,x
t
]+b
c
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(41)
[0073]
c
t
=f
t
·
c
t
‑1+i
t
·
g
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(42)
[0074]
o
t
=σ(w
o
[h
t
‑1,x
t
]+b
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(43)
[0075]
h
t
=o
t
·
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(44)
[0076]
其中,x
t
表示此刻新闻标题与正文的输入信息,h
t
‑1表示前一时刻的输出,i
t
表示此刻输入门,f
t
表示此刻的遗忘门,g表示候选的输入。c
t
表示自循环神经元,用于保存序列信息。o
t
表示此刻的输出,h
t
是此刻的输出向量,w表示权重矩阵,b表示偏置向量。
[0077]
步骤三:考虑新闻文本标题与正文的重要程度,引入注意力机制,实现新闻词向量
加权;
[0078]
新闻文本通常包含两个部分,分别是新闻标题和新闻正文,标题对新闻主题有着总结的作用,因此本文将新闻标题编码后与新闻正文的单词表示进行点积,可以获得每个新闻正文词语的重要程度(也就是注意力权重),然后对新闻正文的单词表示进行加权,使得新闻中更重要的单词得到增强。
[0079]
新闻标题与正文的各个词的向量表示分别为t0、t1、t2…
t
m
与c0、c1、c2…
c
n
,作为输入传入bi
‑
lstm单元,得到对应隐藏层h0、h1、h2…
h
m
与h0、h1、h2…
h
n
,将标题词向量与正文词向量进行点积,对新闻正文词向量进行加权,计算出注意力概率分布值a0、a1、a2…
a
n
,其思想是获取新闻正文词向量的重要程度,最终获得包含文本信息的特征向量v,其运算过程如公式(45)、(46)、(47)。
[0080][0081][0082][0083]
其中exp表示指数函数,f表示打分函数,其中m表示新闻文本标题个数,n表示正文的词向量个数。
[0084]
步骤四:通过bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示,弥补bilstm的缺点;
[0085]
cnn模块包含输入层、卷积层、池化层。输入层是新闻文本的向量化表示;卷积与池化层是卷积深井网络模型的核心层,目的是将原始的特征映射到更高层次维度的语义空间。本文通过bilstm获得新闻文本的向量表示之后,再通过cnn获得句子的局部表示,可以有效弥补bilstm的缺点,实验设置3,4,5三种长度的卷积核,进行卷积与池化操作。将词向量加权模块后的输出作为cnn模块的输入,即新闻标题标题h0,h1,h2…
h
m
和加权后的新闻正文表示h
′0,h
′1,h
′2…
h
′
n
,经过cnn的卷积与池化操作,得到新闻标题与正文的特征向量x0,x1,x2…
x
m
与x0,x1,x2…
x
n
。其运算过程如下:
[0086]
(1)卷积操作
[0087]
新闻标题词向量表示卷积运算如公式(48):
[0088]
x
i
=f(w1⊙
h
i:i+l
‑1+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(48)
[0089]
其中,x
i
表示新闻标题卷积运算后的结果,w1表示滤波器,b表示偏置量,f表示激活函数,l表示滑动窗口大小,h
i:i+l
‑1可以表示为由第i到第i+l
‑
1个标题文本词组成的局部特征矩阵,
⊙
表示点乘运算。
[0090]
同理,新闻正文词向量表示卷积运算如公式(49):
[0091]
x
i
=f(w1⊙
h
′
i:i+l
‑1+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(49)
[0092]
(2)池化操作
[0093]
对卷积核产生的新闻标题与正文特征进行最大池化操作如公式(50)、(51):
[0094]
[0095][0096]
其中,x
i
(i=0,1,...,n
‑
l+1)为新闻标题词向量经卷积运算后的结果,x
i
(i=0,1,...,n
‑
l+1)为新闻正文词向量加权后和卷积运算后的结果。表示新闻文本标题与正文经过最大池化运算后的结果。
[0097]
步骤五:结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络对获得的信息进行聚合,完成文本分类。
[0098]
胶囊网络与传统的神经网络不同,是通过向量来表示属性,即它的神经元是向量而不是标量。涉及到动态路由、输入胶囊、输出胶囊等概念。本文采用的胶囊网络模块包括挤压、耦合、加权、动态路由等步骤,其中动态路由算法是胶囊网络模块的核心组件,通过动态路由不断的调整输入胶囊向量与输出胶囊向量的耦合系数,最终预测出输出胶囊向量。本文结合bilstm模型对文本长序列表示和cnn模型提取局部特征的优势,并利用胶囊网络具有局部与整体空间位置关系的学习能力,对获得的信息进行聚合,完成文本分类。其算法过程如公式(52)、(53)、(54)、(55)、(56)、(57)。
[0099][0100][0101][0102][0103][0104]
b
ij
=b
ij
+a
ij
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(57)
[0105]
其中,c
ij
表示耦合系数;i表示输入,j表输出;w
ij
表示变换矩阵,u
i
表示输入胶囊,表示输出胶囊向量,式(53)表示通过变换矩阵,实现输入胶囊与输出胶囊的转换;s
j
表示耦合过程的输出,v
j
表示s
j
通过压缩函数后的胶囊向量;a
ij
表示v
j
对应的预测向量进行点积预算。
[0106]
将cnn模块所提取得到的新闻文本标题与正文的特征作为子阶胶囊向量输入到胶囊网络模块进行文本分类。通过上述的算法,将新闻文本所有向量拼接获得高阶胶囊向量表示y0,y1,y2…
y
n
,最终完成新闻文本分类。
[0107]
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机。具体的,计算机例如可以为个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
[0108]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的
包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0109]
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1