一种应用公开数据构建的金融预警系统及预警方法
本发明属于数据处理技术领域,具体涉及一种应用公开数据构建的金融预警系统,本发明还涉及一种应用公开数据构建的金融预警方法。
背景技术:
金融风险预警系统,是金融监理机关为了更好的对金融经营机构实施有效监控,既是对其可能发生的金融风险进行预警、预报所建立的早期预警系统。其在性质上系属一种兼具风险管理及经营评鉴的双重功能,尤其是对上市公司之财务及业务具有预防及警戒作用。其意义系指依据有关之监理法规与公司财务业务之经营原则,选定若干变数而订定之一套预警函数、指标(indicator)、临界值或基准值(decimalvalue),或判别模型等,在金融预警实务作业上,对于财务危机公司的预测,监理者大都以传统的财务指标对金融经营机构的经营状况进行监测。
然而,目前的预警系统仅依据与金融直接相关的量价数据对金融风险进行预警的方式,忽视了互联网中海量文本数据的影响,其存在预警准确性低的问题。
技术实现要素:
本发明的目的是提供一种应用公开数据构建的金融预警系统,能够对金融风险进行预警。
本发明的第二个目的是提供一种应用公开数据构建的金融预警方法,能够提供有效的金融风险预警方式。
本发明所采用的技术方案是,一种应用公开数据构建的金融预警系统,寻找警源模块,用于监测互联网信息以获取输入数据;
辨识警讯与分析警兆模块,用于将输入数据变为警讯的过程的文档数据特征提取,以明确与预警企业相关的事件信息;
预报警度模块,用于预测企业的警度信息。
本发明的特征还在于,
互联网信息包括企业官网、财报、交易、新闻、杂质、媒体、网络及舆情公开数据。
警度等级包括有警、无警两个级别。
本发明所采用的第二种技术方案是,一种应用公开数据构建的金融预警方法,具体按照以下步骤实施:
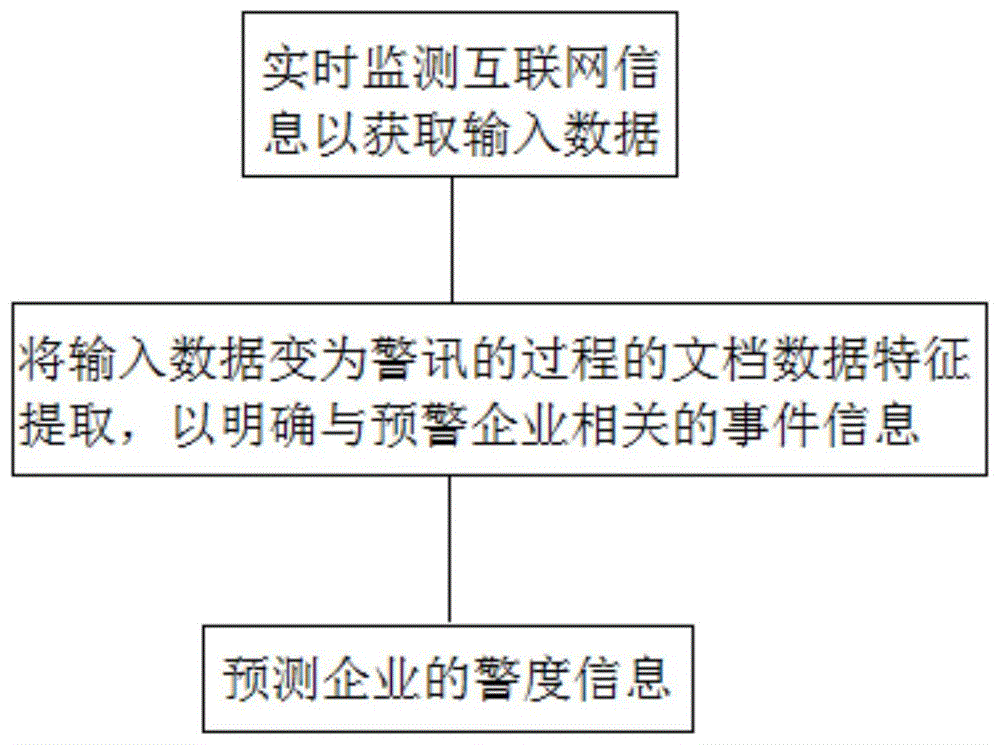
步骤1,实时监测互联网信息以获取输入数据;
步骤2,利用bert模型将输入数据变为警讯的过程的文档数据特征提取,以明确与预警企业相关的事件信息;
步骤3,利用lstm预测企业的警度信息,划分出不同的警度等级。
本发明的特征还在于,
步骤1中,互联网信息包括企业官网、财报、交易、新闻、杂质、媒体、网络及舆情公开数据。
步骤2的具体过程为:
步骤2.1,进行词嵌入,词嵌入表达式为:
x=epos(onehot(s)+eseg)(1)
式(1)中,onehot表示词嵌入,eseg表示句子嵌入,epos表示位置嵌入;
步骤2.2,定义单注意力机制:
式(2)中,wq、wk、wv是可训练的参数;softmax表示softmax归一化函数,将值映像到0-1的范围内;d表示向量的维度;
步骤2.3,将多个单注意力机制进行组合,组成多头注意力机制层,多头注意力机制层表达式为:
multihead(x)=concat(att1,...,atth)wo(3)
式(3)中,concate表示链接操作,h表示注意力机制头的数目,wo表示可训练的参数;
步骤2.4,将多头注意力机制层的输出向量与词嵌入相加,构成残差网络,再经过批次归一化得到注意力机制层的最终输出:
matt=bn(multihead(x)+x)(4)
式(4)中,bn就表示批次归一化;
步骤2.5,步骤2.4得到的最终输出经过带有残差网络与批次归一化的全连接层,得到文文件特征b:
b=bert(x)=bn(dense(matt)+matt)(5);
对于字数为n的文档s,文文件特征b={b1,…,bn+1},
步骤3的具体过程为:
步骤3.1,假设上一lstm的隐藏层输出ht-1和第t个文档向量bt,则lstm可以表达式为:
ft=σ(wf·y+bf)(7)
it=σ(wi·y+bi)(8)
ot=σ(wo·y+bo)(9)
ct=ft⊙ct-1+it⊙tanh(wc·y+bc)(10)
ht=ot⊙tanh(ct)(11)
式中,wi,wf,wo,wc,bi,bf,bo,bc是可训练的参数,σ是sigmod启动函数,⊙表示hadamard乘积,ct表示第t个文档的输出;
步骤3.2,通过步骤3.1得到的向量ht预测企业的警度等级:
lt=softmax(dense(ht))(12)。
当lt≥0.5表示有警,即异常;当lt<0.5表示无警,即正常。
本发明的有益效果是:
(1)本发明一种应用公开数据构建的金融预警系统,避免依据与金融直接相关的量价数据对金融风险进行预警的方式造成了准确性低的问题;
(2)本发明一种应用公开数据构建的金融预警方法,通过对互联网中的海量文本数据进行特征提取,产生预测企业的警度信息,提高了金融风险预测的准确性。
附图说明
图1为本发明一种应用公开数据构建的金融预警方法的流程图;
图2为本发明一种应用公开数据构建的金融预警方法中步骤2的流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种应用公开数据构建的金融预警系统,包括:寻找警源模块,用于监测互联网信息以获取输入数据,互联网信息包括业官网、财报、交易、新闻、杂质、媒体、网络及舆情等公开数据;
辨识警讯与分析警兆模块,用于将输入数据变为警讯的过程的文档数据特征提取,以明确与预警企业相关的事件信息;
预报警度模块,用于预测企业的警度信息,警度等级分为有警和无警两个级别。
本发明提供一种应用公开数据构建的金融预警方法,通过应用公开数据构建的金融预警系统实现,如图1所示,具体按照以下步骤实施:
步骤1,实时监测互联网信息以获取输入数据,其中互联网信息包括企业官网、财报、交易、新闻、杂质、媒体、网络及舆情等公开数据;
步骤2,利用金融新闻数据预训练的bert模型将输入数据变为警讯的过程的文档数据特征提取,以明确与预警企业相关的事件信息;
bert是2018年由google提出的语言模型,通过在大笔资料上的预训练,提高在特定任务上的结果,bert网络主要由三个部分组成,词嵌入层,注意力机制层与全连接层。词嵌入层将字转化为编码,这些编码通过由注意力机制层与全连接层组成的多层网络模块,就是最后获得的输出。词嵌入层包括三种词嵌入,字嵌入,句子嵌入,和位置嵌入。其中字嵌入就是对字进行编码,句子嵌入是用编码表示不同的句子,位置嵌入是使用学习的位置嵌入;
步骤2.1,假设n个文文件的文文件集合s={s1,s2,…,sn},文文件集合按时间排序,进行词嵌入,词嵌入表达式为:
x=epos(onehot(s)+eseg)(1)
式(1)中,onehot表示词嵌入,eseg表示句子嵌入,epos表示位置嵌入;
步骤2.2,定义单注意力机制:
式(2)中,wq、wk、wv是可训练的参数;softmax表示softmax归一化函数,将值映像到0-1的范围内;d表示向量的维度;
步骤2.3,将多个单注意力机制进行组合,组成多头注意力机制层,多头注意力机制层表达式为:
multihead(x)=concat(att1(x),...,atth(x))wo(3)
式(3)中,concate表示链接操作,h表示注意力机制头的数目,wo表示可训练的参数;
步骤2.4,将多头注意力机制层的输出向量与词嵌入相加,构成残差网络,再经过批次归一化得到注意力机制层的最终输出:
matt=bn(multihead(x)+x)(4)
式(4)中,bn就表示批次归一化;
步骤2.5,步骤2.4得到的最终输出经过带有残差网络与批次归一化的全连接层,得到文文件特征b:
b=bert(x)=bn(dense(matt)+matt)(5);
对于字数为n的文档s,文文件特征b={b1,…,bn+1},
步骤3,利用lstm预测企业的警度信息,划分出不同的警度等级;
长短期记忆(longshort-termmemory,lstm)是一种用于进程列数据的神经网络。相比一般网络,他能够进程列变化的数据。比如某个文档的意思会因为上一个文档的内容不同而有不同的含义,lstm就能够很好的解决这类问题;
步骤3.1,由于每一个lstm单元都存在两个输入,假设上一lstm的隐藏层输出ht-1和第t个文档向量bt,则lstm可以表达式为:
ft=σ(wf·y+bf)(7)
it=σ(wi·y+bi)(8)
ot=σ(wo·y+bo)(9)
ct=ft⊙ct-1+it⊙tanh(wc·y+bc)(10)
ht=ot⊙tanh(ct)(11)
式中,wi,wf,wo,wc,bi,bf,bo,bc是可训练的参数,σ是sigmod启动函数,⊙表示hadamard乘积,ct表示第t个文档的输出;
步骤3.2,通过步骤3.1得到的向量ht预测企业的警度等级:
lt=softmax(dense(ht))(12)
当lt≥0.5表示有警,即异常;
当lt<0.5表示无警,即正常。
- 还没有人留言评论。精彩留言会获得点赞!