一种基于弱监督文本引导的动作定位模型的训练方法
本公开属于智能行为分析技术领域,尤其涉及一种基于弱监督文本引导的动作定位模型的训练方法、系统及动作定位方法。
背景技术:
文本引导的动作定位能够根据给定的文本,在视频中找到所描述的动作的起始和结束时间,在智能监控、视频描述、视频总结等领域有着广泛的应用。
传统的行为定位方法通常都是基于预定类别或者全监督的,利用预先定义进行精细化数据动作类别和边界标注,然后训练模型。这一过程需要预先定义好动作类型,并标注大量数据,严重限制了动作定位的应用性。
为了减轻对数据标注和预定动作类别的依赖,提升行为定位方法的拓展性和实用性,基于弱监督的文本引导的行为定位方法应运而生,在定位任务上也取得了较好的结果。
但是,在实现本公开实施例的过程中,发明人发现相关技术中至少存在如下问题:当前方法忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差。
技术实现要素:
有鉴于此,本公开提供了一种基于弱监督文本引导的动作定位模型的训练方法、系统及动作定位方法。
共公开的一个方面提供了一种基于弱监督文本引导的动作定位模型的训练方法,包括:
分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征;
根据所述第一初始视频特征和所述第一初始文本特征计算得到第一对应性矩阵;
利用第一处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到第一融合特征;
利用第二处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到局部对应性矩阵;
根据所述第一融合特征、所述局部对应性矩阵和所述第一初始文本特征训练初始动作定位模型,得到训练后的所述动作定位模型。
根据本公开的实施例,所述分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征包括:
将所述样本视频划分为n个视频片段,分别对每个所述视频片段进行特征提取,输出多个第一片段视频特征,其中,n≥1;
对每个所述第一片段视频特征进行处理,得到所述第一初始视频特征;以及
对所述样本文本进行处理,得到所述样本文本中的每个单词的词向量;
对每个所述词向量进行处理,得到所述第一初始文本特征。
根据本公开的实施例,所述利用第一处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到第一融合特征包括:
将所述第一对应性矩阵和所述第一初始文本特征进行加权聚合得到与所述样本视频候选区域自适应的第一聚合文本特征,其中,所述样本视频候选区域为一组起始时间和结束时间不同的视频片段;
将所述第一聚合文本特征与所述第一初始视频特征进行融合,得到第一初始融合特征;
对所述第一初始融合特征进行处理,以更新所述第一初始融合特征,得到最终的第一融合特征。
根据本公开的实施例,所述利用第二处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到局部对应性矩阵包括:
将所述第一对应性矩阵和所述第一初始视频特征进行加权聚合得到与样本文本对应的聚合视频特征;
根据所述聚合视频特征和所述第一初始文本特征计算得到第二对应性矩阵;
将所述初始第二对应性矩阵进行归一化处理得到最终的所述局部对应性矩阵。
根据本公开的实施例,所述根据所述第一融合特征、所述局部对应性矩阵和所述第一初始文本特征训练初始动作定位模型,得到训练后的所述动作定位模型包括:
将所述第一融合特征分别进行分类和排序处理,得到第一分类特征和第一排序特征;
根据所述第一分类特征和所述第一排序特征计算得到所述样本视频和所述样本文本的匹配损失;以及
对所述局部对应性矩阵和所述第一初始文本特征进行加权求和处理得到重构初始文本特征;
根据所述第一初始文本特征和所述重构初始文本特征计算得到所述样本视频和所述样本文本的局部对应性损失;
将所述匹配损失和所述局部对应性损失输入损失函数,得到损失结果;
根据所述损失结果训练所述初始动作定位模型,得到训练后的所述动作定位模型。
本公开的另一个方面提供了一种动作定位方法,其中,所述方法基于上述的训练方法训练得到的动作定位模型来实现,包括:
分别对目标视频和目标文本进行特征提取,输出第二初始视频特征和第二初始文本特征;
根据所述第二初始视频特征和所述第二初始文本特征计算得到第三对应性矩阵;
利用第一处理方式对所述第二初始视频特征、所述第二初始文本特征和所述第三对应性矩阵进行处理,得到第二融合特征;
对所述第二融合特征进行处理,得到所述目标视频和所述目标文本的匹配分数;
根据所述匹配分数得到最终的定位结果。
根据本公开的实施例,所述分别对目标视频和目标文本进行特征提取,输出第二初始视频特征和第二初始文本特征包括:
将所述目标视频划分为n个视频片段,分别对每个所述视频片段进行特征提取,输出多个第二片段视频特征,其中,n≥1;
对每个所述第二片段视频特征进行处理,得到所述第二初始视频特征;以及
对所述目标文本进行处理,得到所述目标文本中的每个单词的词向量;
对每个所述词向量进行处理,得到所述第二初始文本特征。
根据本公开的实施例,所述利用第一处理方式对所述第二初始视频特征、所述第二初始文本特征和所述第三对应性矩阵进行处理,得到第二融合特征包括:
将所述第三对应性矩阵和所述第二初始文本特征进行加权聚合得到与所述目标视频候选区域自适应的第二聚合文本特征,其中,所述目标视频候选区域为一组起始时间和结束时间不同的视频片段;
将所述第二聚合文本特征与所述第二初始视频特征进行融合,得到第二初始融合特征;
对所述第二初始融合特征进行处理,以更新所述第二初始融合特征,得到最终的第二融合特征。
根据本公开的实施例,所述对所述第二融合特征进行处理,得到所述目标视频和所述目标文本的匹配分数包括:
将所述第二融合特征分别进行分类和排序处理,分别得到第二分类特征和第二排序特征;
根据所述分第二类特征和所述第二排序特征计算得到所述目标视频和所述目标文本的匹配分数。
本公开的另一个方面提供了一种基于弱监督文本引导的动作定位模型的训练系统,包括:
提取模块,用于分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征;
计算模块,用于根据所述第一初始视频特征和所述第一初始文本特征计算得到第一对应性矩阵;
第一处理模块,用于利用第一处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到第一融合特征;
第二处理模块,用于利用第二处理方式对所述第一初始视频特征、所述第一初始文本特征和所述第一对应性矩阵进行处理,得到局部对应性矩阵;
训练模块,用于根据所述第一融合特征、所述局部对应性矩阵和所述第一初始文本特征训练初始动作定位模型,得到训练后的所述动作定位模型。
根据本公开实施例,通过对视频和文本之间的局部对应性进行建模,不需要精细的动作起始和结束时间标注,只需要视频级别的文本描述即可进行定位训练,所以至少部分的解决了现有技术中忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差的问题,进而达到了挖掘视频和文本之间的细粒度对应性,实现鲁棒的动作定位的技术效果。
附图说明
图1示意性示出了根据本公开实施例的基于弱监督文本引导的动作定位模型的训练方法的流程图。
图2示意性示出了根据本公开实施例的基于弱监督文本引导的动作定位方法的流程图。
图3示意性示出了本公开实施例的基于弱监督文本引导的动作定位模型的训练系统的模块结构图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
以下,将参照附图来描述本公开的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本公开的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本公开实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本公开的概念。
在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本公开。在此使用的术语“包括”、“包含”等表明了特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
发明人在实现本公开构思的过程中发现,现有的动作定位方法忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差。
图1示意性示出了根据本公开实施例的基于弱监督文本引导的动作定位模型的训练方法的流程图。
如图1所示,本公开实施例的基于弱监督文本引导的动作定位模型的训练方法包括操作s101~s105。
在操作s101中,分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征。
根据本公开实施例,分别对样本视频和样本文本进行特征提取,分别得到第一片段视频特征
在操作s102中,根据第一初始视频特征和第一初始文本特征计算得到第一对应性矩阵。
根据本公开实施例,基于第一初始视频特征和第一初始文本特征,得到第一对应性矩阵a;
其中,
在操作s103中,利用第一处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到第一融合特征。
在操作s104中,利用第二处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到局部对应性矩阵。
在操作s105中,根据第一融合特征、局部对应性矩阵和第一初始文本特征训练初始动作定位模型,得到训练后的动作定位模型。
根据本公开实施例,通过对视频和文本之间的局部对应性进行建模,不需要精细的动作起始和结束时间标注,只需要视频级别的文本描述即可进行定位训练,所以至少部分的解决了现有技术中忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差的问题,进而达到了挖掘视频和文本之间的细粒度对应性,实现鲁棒的动作定位的技术效果。
根据本公开实施例,分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征包括:
将样本视频划分为n个视频片段,分别对每个视频片段进行特征提取,输出多个第一片段视频特征,其中,n≥1。
根据本公开实施例,对视频片段进行特征提取的方式例如可以通过13d网络等进行特征提取。在本实施例中,将样本视频划分为n(n≥1)个视频片段,通过i3d网络提取每个视频片段的第一片段视频特征
对每个第一片段视频特征进行处理,得到第一初始视频特征。
根据本公开实施例,在对每个第一片段视频特征进行处理时,例如可以通过双向lstm网络等进行处理。在本实施例中,将每个视频片段的第一片段视频特征
然后根据得到的结果,生成第一初始视频特征:
对样本文本进行处理,得到样本文本中的每个单词的词向量。
根据本公开实施例,在对样本文本进行处理的方式例如可以通过glove的方法进行处理,得到每个单词的词向量
对每个词向量进行处理,得到第一初始文本特征。
根据本公开实施例,在对每个单词的词向量进行处理时,例如可以通过双向lstm网络等进行处理。在本实施例中,将每个单词的词向量
然后根据得到的结果,生成第一初始文本特征:
根据本公开实施例,利用第一处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到第一融合特征包括:
将第一对应性矩阵和第一初始文本特征进行加权聚合得到与样本视频候选区域自适应的第一聚合文本特征,其中,样本视频候选区域为一组起始时间和结束时间不同的视频片段。
根据本公开实施例,根据第一对应性矩阵和第一初始文本特征得到第一聚合文本特征
将第一聚合文本特征与第一初始视频特征进行融合,得到第一初始融合特征。
根据本公开实施例,将第一聚合文本特征和第一初始视频特征进行融合,得到第一初始融合特征f,其中,
对第一初始融合特征进行处理,以更新第一初始融合特征,得到最终的第一融合特征。
根据本公开实施例,对第一初始融合特征进行适应性处理,得到最终的第一融合特征。在本实施例中,例如可以通过二维卷积网络对第一初始融合特征进行候选区域关系建模,得到提升的第一融合特征。
根据本公开实施例,利用第二处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到局部对应性矩阵包括:
将第一对应性矩阵和第一初始视频特征进行加权聚合得到与样本文本对应的聚合视频特征;根据聚合视频特征和第一初始文本特征计算得到第二对应性矩阵;将初始第二对应性矩阵进行归一化处理得到最终的局部对应性矩阵。
根据本公开实施例,首先将第一对应性矩阵和第一初始视频特征进行加权聚合得到与样本文本对应的聚合视频特征,为了使每个文本对应的视频特征与自身具有高相似度,在将聚合视频特征和第一初始文本特征计算得到第二对应性矩阵
根据本公开实施例,根据第一融合特征、局部对应性矩阵和第一初始文本特征训练初始动作定位模型,得到训练后的动作定位模型包括:
将第一融合特征分别进行分类和排序处理,得到第一分类特征和第一排序特征;根据第一分类特征和第一排序特征计算得到样本视频和样本文本的匹配损失。
根据本公开实施例,对第一融合特征进行分类处理,得到表示每个片段的匹配分数的第一分类特征:
对第一融合特征进行排序处理,得到表示片段之间的相对匹配分数的第一排序特征:
根据第一分类特征和第一排序特征计算每个片段的最终匹配分数:
sm=scls×srank(八)
根据上述的最终匹配分数计算视频和文本的匹配分数:
根据上述匹配分数,计算样本视频和样本文本的匹配损失:
lcls=-∑log(s(v,qp)[0])+log(s(v,qn)[1])(十);
其中,qp为匹配文本,qn为不匹配文本。
对局部对应性矩阵和第一初始文本特征进行加权求和处理得到重构初始文本特征;根据第一初始文本特征和重构初始文本特征计算得到样本视频和样本文本的局部对应性损失。
根据本公开实施例,将第一初始文本特征的坐标图标记为mt,其中,
将匹配损失和局部对应性损失输入损失函数,得到损失结果。
根据本公开实施例,根据匹配损失和局部对应性损失得到损失结果:
l=lcls+20lcycle(十二)
根据损失结果训练初始动作定位模型,得到训练后的动作定位模型。
图2示意性示出了根据本公开实施例的基于弱监督文本引导的动作定位方法的流程图。
该基于弱监督文本引导的动作定位方法基于上述训练方法训练得到的动作定位模型来实现,如图2所示,该方法包括操作s201~s205。
在操作s201中,分别对目标视频和目标文本进行特征提取,输出第二初始视频特征和第二初始文本特征。
在操作s202中,根据第二初始视频特征和第二初始文本特征计算得到第三对应性矩阵。
在操作s203中,利用第一处理方式对第二初始视频特征、第二初始文本特征和第三对应性矩阵进行处理,得到第二融合特征。
在操作s204中,对第二融合特征进行处理,得到目标视频和目标文本的匹配分数。
在操作s205中,根据匹配分数得到最终的定位结果。
根据本公开实施例,通过对视频和文本之间的局部对应性进行建模,不需要精细的动作起始和结束时间标注,只需要视频级别的文本描述即可进行定位训练,所以至少部分的解决了现有技术中忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差的问题,进而达到了挖掘视频和文本之间的细粒度对应性,实现鲁棒的动作定位的技术效果。
根据本公开实施例,分别对目标视频和目标文本进行特征提取,输出第二初始视频特征和第二初始文本特征包括:
将目标视频划分为n个视频片段,分别对每个视频片段进行特征提取,输出多个第二片段视频特征,其中,n≥1;对每个第二片段视频特征进行处理,得到第二初始视频特征。
对目标文本进行处理,得到目标文本中的每个单词的词向量;对每个词向量进行处理,得到第二初始文本特征。
需要说明的是,本公开的实施例中定位方法中的特征提取部分与本公开的训练方法中的特征提取部分是相对应的,定位方法中的特征提取部分的描述具体参考训练方法中的特征提取部分,在此不再赘述。
根据本公开实施例,利用第一处理方式对第二初始视频特征、第二初始文本特征和第三对应性矩阵进行处理,得到第二融合特征包括:
将第三对应性矩阵和第二初始文本特征进行加权聚合得到与目标视频候选区域自适应的第二聚合文本特征,其中,目标视频候选区域为一组起始时间和结束时间不同的视频片段;将第二聚合文本特征与第二初始视频特征进行融合,得到第二初始融合特征;对第二初始融合特征进行处理,以更新第二初始融合特征,得到最终的第二融合特征。
需要说明的是,本公开的实施例中定位方法中的第二初始融合特征部分与本公开的训练方法中的第一初始融合特征部分是相对应的,定位方法中的第二初始融合特征部分的描述具体参考训练方法中的第一初始融合特征部分,在此不再赘述。
根据本公开实施例,对第二融合特征进行处理,得到目标视频和目标文本的匹配分数包括:
将第二融合特征分别进行分类和排序处理,分别得到第二分类特征和第二排序特征;根据分第二类特征和第二排序特征计算得到目标视频和目标文本的匹配分数。
需要说明的是,本公开的实施例中定位方法中的匹配分数部分与本公开的训练方法中的匹配分数部分是相对应的,定位方法中的匹配分数部分的描述具体参考训练方法中的匹配分数部分,在此不再赘述。
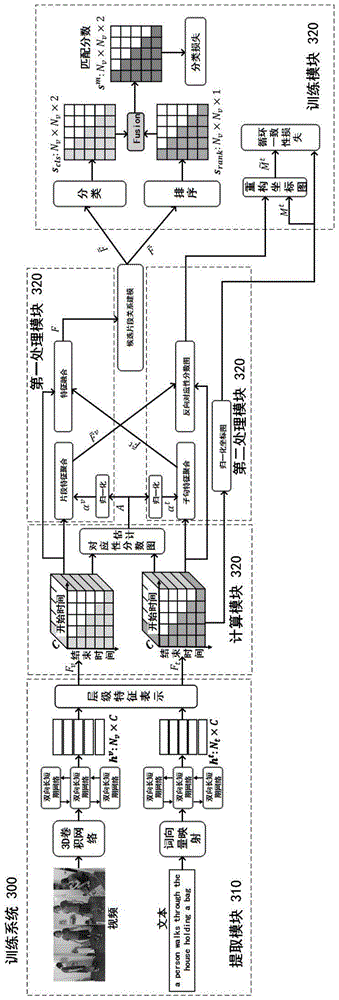
图3示意性示出了本公开实施例的基于弱监督文本引导的动作定位模型的训练系统的模块结构图。
如图3所示,该训练系统300包括提取模块310、计算模块320、第一处理模块330、第二处理模块340和训练模块350。
提取模块310,用于分别对样本视频和样本文本进行特征提取,输出第一初始视频特征和第一初始文本特征。
计算模块320,用于根据第一初始视频特征和第一初始文本特征计算得到第一对应性矩阵。
第一处理模块330,用于利用第一处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到第一融合特征。
第二处理模块340,用于利用第二处理方式对第一初始视频特征、第一初始文本特征和第一对应性矩阵进行处理,得到局部对应性矩阵。
训练模块350,用于根据第一融合特征、局部对应性矩阵和第一初始文本特征训练初始动作定位模型,得到训练后的动作定位模型。
根据本公开实施例,通过对视频和文本之间的局部对应性进行建模,不需要精细的动作起始和结束时间标注,只需要视频级别的文本描述即可进行定位训练,所以至少部分的解决了现有技术中忽略了视频和文本之间的细粒度对应性,导致模型容易出现定位偏差的问题,进而达到了挖掘视频和文本之间的细粒度对应性,实现鲁棒的动作定位的技术效果。
在本实施例中,提取模块310包括第一提取单元、第一处理单元、第二处理单元和第三处理单元。
第一提取单元,用于将样本视频划分为n个视频片段,分别对每个视频片段进行特征提取,输出多个第一片段视频特征,其中,n≥1。
第一处理单元,用于对每个第一片段视频特征进行处理,得到第一初始视频特征。
第二处理单元,用于对样本文本进行处理,得到样本文本中的每个单词的词向量。
第三处理单元,用于对每个词向量进行处理,得到第一初始文本特征。
在本实施例中,第一处理模块330包括第一聚合单元、融合单元和第四处理单元。
第一聚合单元,用于将第一对应性矩阵和第一初始文本特征进行加权聚合得到与样本视频候选区域自适应的第一聚合文本特征,其中,样本视频候选区域为一组起始时间和结束时间不同的视频片段。
融合单元,用于将第一聚合文本特征与第一初始视频特征进行融合,得到第一初始融合特征。
第四处理单元,用于对第一初始融合特征进行处理,以更新第一初始融合特征,得到最终的第一融合特征。
根据本公开实施例,第二处理模块340包括第二聚合单元、计算单元和第五处理单元。
第二聚合单元,用于将第一对应性矩阵和第一初始视频特征进行加权聚合得到与样本文本对应的聚合视频特征。
第一计算单元,用于根据聚合视频特征和第一初始文本特征计算得到第二对应性矩阵。
第五处理单元,用于将初始第二对应性矩阵进行归一化处理得到最终的局部对应性矩阵。
根据本公开实施例训练模块350包括分类与排序单元、第二计算单元、重构单元、第三计算单元、输入单元和训练单元。
分类与排序单元,用于将第一融合特征分别进行分类和排序处理,得到第一分类特征和第一排序特征。
第二计算单元,用于根据第一分类特征和第一排序特征计算得到样本视频和样本文本的匹配损失。
重构单元,用于对局部对应性矩阵和第一初始文本特征进行加权求和处理得到重构初始文本特征。
第三计算单元,用于根据第一初始文本特征和重构初始文本特征计算得到样本视频和样本文本的局部对应性损失。
输入单元,用于将匹配损失和局部对应性损失输入损失函数,得到损失结果。
训练单元,用于根据损失结果训练初始动作定位模型,得到训练后的动作定位模型。
需要说明的是,本公开的实施例中训练系统部分与本公开的实施例中训练方法部分是相对应的,训练系统部分的描述具体参考训练方法部分,在此不再赘述。
以上的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!