基于数据重建和混合预测的网络流量预测方法及装置
本发明属于网络通信技术领域,具体涉及一种基于数据重建和混合预测的网络流量预测方法及装置。
背景技术:
人们近年来对即时通信、搜索引擎、社交娱乐、远程办公、在线交易和公共服务等网络业务的需求日益增加,导致网络业务规模爆炸性增长,技术进步与用户需求致使网络类型也更加多样化。但是由于网络资源有限,网络需求量的不断增加必然会造成网络拥塞和服务质量降低的情况出现。因此需要对网络的行为与状态进行掌握以增强网络管理的有效性和及时性。而网络流量是监测网络行为状态、研究网络行为的基础,因而有关网络流量预测的研究愈发受到国内外研究学者和工业界的广泛关注。然而,现代网络流量具有的自相似性、周期性、混沌性和多尺度等特征使得预测网络行为颇具挑战性。
为了能够充分利用流量数据间的时间相关性,实现对具有复杂特性的网络流量的预测,tokuyamay等人在论文theeffectofusingattributeinformationinnetworktrafficpredictionwithdeeplearning[c]//2018internationalconferenceoninformationandcommunicationtechnologyconvergence(ictc).ieee,2018:521-525中提出了一种rnn-vtd模型,它通过向rnn添加流量的一些属性信息来利用流量数据的周期性,将网络流量的流量值、时间戳和周几分别送入神经网络中进行训练和预测,有效地提高了预测的精度。但是,当数据集规模较大或数据波动较大时,单纯使用神经网络进行预测存在收敛速度较慢、容易陷入局部最优等问题。
目前,一些研究人员使用傅里叶分解或小波分解来平滑时间序列,用以解决上述问题。但这些方法依赖于先验谐波基函数或小波基函数,不适用于处理非平稳非线性数据。同时,由于网络流量具有较多突变数据,使得预测模型规模更加庞大,既增加预测复杂度,又降低预测精度。此外,现有的预测算法大都需要真实有效的数据集作为输入,但由于网络拓扑的复杂性、网络设备的资源限制和监视高速网络的高开销,在实际网络中收集所有真实流量数据是不切实际的,这也影响了预测模型的鲁棒性,从而影响系统的稳定性。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供了一种基于数据重建和混合预测的网络流量预测方法及装置。本发明要解决的技术问题通过以下技术方案实现:
一种基于数据重建和混合预测的网络流量预测方法,包括:
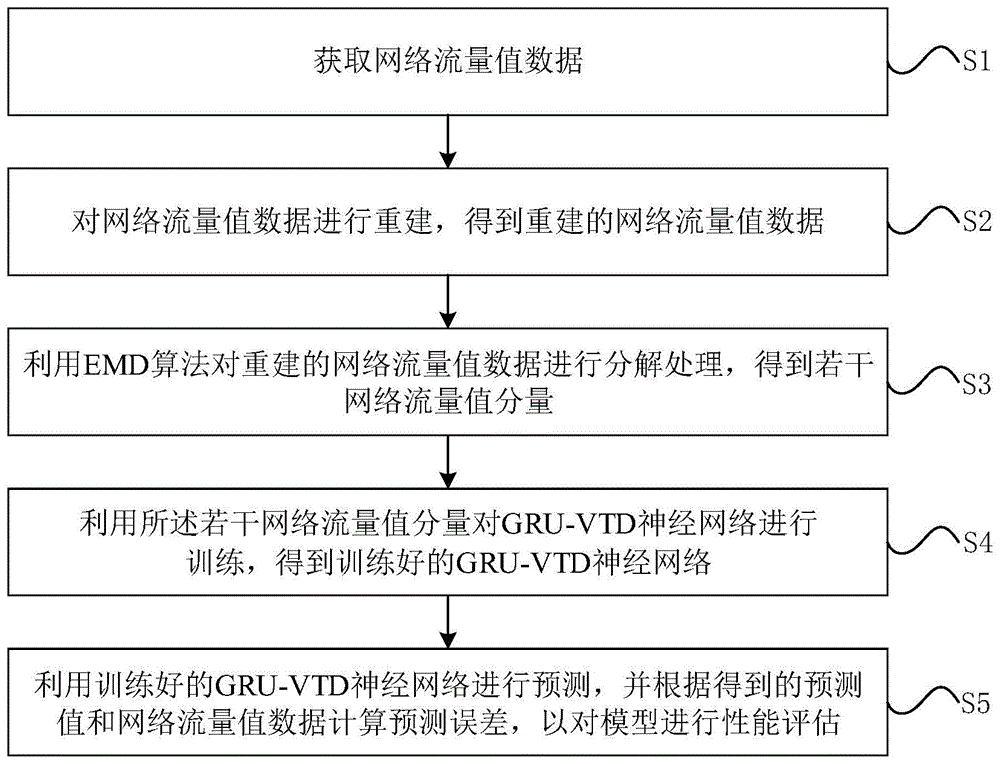
获取网络流量值数据;
对所述网络流量值数据进行重建,得到重建的网络流量值数据;
利用emd算法对所述重建的网络流量值数据进行分解处理,得到若干网络流量值分量;
利用所述若干网络流量值分量对gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络;
利用训练好的gru-vtd神经网络进行预测,并根据得到的预测值和网络流量值数据计算预测误差,以对模型进行性能评估。
在本发明的一个实施例中,对所述网络流量值数据进行重建,得到重建的网络流量值数据,包括:
对所述网络流量值数据进行初始化,得到多信息的网络流量值数据;
对所述多信息的网络流量值数据中的缺失点进行补足,得到补足完整的网络流量值数据;
对所述补足完整的网络流量值数据中的离群点进行剔除,得到重建的网络流量值数据。
在本发明的一个实施例中,对所述多信息的网络流量值数据中的缺失点进行补足,得到补足完整的网络流量值,包括:
根据可接受的流量最小值和相邻网络流量值之间的时间间隔对所述多信息的网络流量值数据进行筛查,当满足xt<σ或两个相邻数据的时间间隔大于采样间隔时,则判定该点为缺失点;其中,xt表示流量序列x(t)在时刻t的数据,σ表示可接受的流量最小值;
利用平均值法对所述缺失点进行补足,得到补足完整的网络流量值数据。
在本发明的一个实施例中,利用平均值法对所述缺失点进行补足,包括:
根据当前缺失点的前三个时刻的数据平均值对该缺失点进行补足,表示为:
其中,
在本发明的一个实施例中,对所述补足完整的网络流量值数据中的离群点进行剔除,得到重建的网络流量值数据,包括:
对所述补足完整的网络流量值数据进行归一化处理,得到归一化的网络流量值数据;
对所述归一化的网络流量值数据进行筛查,当不满足
利用差值替换法或趋势替换法对所述离群点进行剔除,得到重建后的网络流量值。
在本发明的一个实施例中,利用差值替换法或者趋势替换法对所述离群点进行剔除,包括:
利用插值替换法计算离群点的替换值,计算公式为:
或者利用趋势替换法计算离群点的替换值,计算公式为:
其中,
利用该离群点的替换值替换所述离群点的流量值。
在本发明的一个实施例中,利用emd算法对所述重建的网络流量值数据进行分解处理,得到若干网络流量值分量,包括:
利用emd算法对所述重建的网络流量值数据进行分解处理,得到具有不同频率的imf分量;
将每个所述imf分量按照一定比例分割为训练集和测试集。
在本发明的一个实施例中,利用所述若干网络流量值分量对gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络,包括:
构建多信息感知的gru-vtd神经网络;
将每个所述imf分量中训练集的网络流量值及其对应的时间戳和来源信息分别输入到所述gru-vtd神经网络的第一输入层、第二输入层以及第三输入层,得到的gru-vtd神经网络的输出层结果;
将所述gru-vtd神经网络的输出层结果与输入的网络流量值之间的mse作为损失函数调整神经网络节点间的连接权重,以对各个gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络。
在本发明的一个实施例中,利用训练好的gru-vtd神经网络进行预测,并根据得到的预测值和网络流量值数据计算预测误差,以对模型进行性能评估,包括:
将每个所述imf分量中测试集的网络流量值及其对应的时间戳和来源信息分别输入到对应的训练好的gru-vtd神经网络的第一输入层、第二输入层以及第三输入层,并将每个gru-vtd神经网络的输出结果进行累加,得到模型的预测值;
计算所述模型的预测值与所述网络流量值数据之间的预测误差,并根据该预测误差对网络模型进行评估。
本发明的另一个实施例提供了一种基于数据重建和混合预测的网络流量预测装置,包括:
数据获取模块,用于获取网络流量值数据;
重建模块,用于对所述网络流量值数据进行重建,得到重建的网络流量值数据;
分解模块,用于利用emd方法对所述重建的网络流量值数据进行分解处理,得到若干网络流量值分量;
训练模块,用于利用所述若干网络流量值分量对gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络;
预测模块,用于利用训练好的gru-vtd神经网络进行预测,并根据得到的预测值和网络流量值数据计算预测误差,以对模型进行性能评估。
本发明的有益效果:
1、本发明通过对网络流量值数据进行重建,并利用emd技术将网络流量序列分解为多个分量,从而将网络流量从多尺度进行分离,然后综合考虑网络流量的多种信息构建神经网络gru-vtd,并将emd分解得到的各个分量分别用于训练和预测与之对应的gru-vtd,最后将所有神经网络的输出送入到累加器中以获得最终的预测结果,克服了现有预测技术中预测精度低、易陷入局部最优、鲁棒性低的缺点,具有更高的预测精度和稳定性;
2、本发明通过归一化、缺失点补足和离群值剔除的方法对流量数据进行重建,可以有效避免异常数据对预测性能产生的负面影响,进一步提高预测精度;
3、本发明采用emd分解算法对数据流量值进行分解重构,将分解后的各个分量作为神经网络的输入数据,可有效利用网络流量的多尺度特性,并在一定程度上削弱了流量的混沌性对预测模型的影响,使不稳定的网络流量也可获得高预测精度,从而增加整体预测性能的稳定性;
4、本发明通过综合考虑网络流量的流量值、时间戳和来源信息,构建多信息感知的神经网络gru-vtd来利用流量数据的周期性,有效提高了预测的精度;同时,根据网络流量的自相似性,采用多信息感知的神经网络gru-vtd进行预测,克服传统预测模型预测精度低、收敛速度慢的缺点。
以下将结合附图及实施例对本发明做进一步详细说明。
附图说明
图1是本发明实施例提供的基于数据重建和混合预测的网络流量预测方法流程示意图;
图2是本发明实施例提供的基于数据重建和混合预测的网络流量预测方法框架示意图;
图3是本发明实施例提供的离群点剔除示意图;
图4是本发明实施例提供的emd分解流程示意图;
图5是本发明实施例提供的多信息感知的gru-vtd神经网络结构示意;
图6是本发明实施例提供的基于数据重建和混合预测的网络流量预测装置结构示意图;
图7为本发明仿真中结合不同的网络流量属性信息后神经网络预测误差的对比图;
图8为本发明仿真中结合了网络流量值、时间戳和星期几信息的预测模型gru-vtd与加入所提数据重建机制后的预测模型gru-vtd-rc的预测误差对比图;
图9为本发明仿真中gru-vtd、gru-vtd-rc以及结合了emd和gru-vtd-rc预测模型gru-vtd-rc-emd的预测误差对比图。
具体实施方式
下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
实施例一
请参见图1,图1是本发明实施例提供的基于数据重建和混合预测的网络流量预测方法流程示意图,具体包括以下步骤:
s1:获取网络流量值数据。
在本实施例中,设置流量序列x(t)在时刻t的流量值数据表示为xt。
s2:对网络流量值数据进行重建,得到重建的网络流量值数据。
请参见图2,图2是本发明实施例提供的基于数据重构的网络流量混合预测方法框架示意图,其中,步骤s2包括:
s21:对网络流量值数据进行初始化,得到多信息的网络流量值数据。
具体地,可根据网络流量值数据集和采样的起始时间计算与网络流量值对应的时间戳以及网络流量来源信息,得到多信息的网络流量数据。其中,来源信息可以根据网络流量的周期设定,例如,以星期为周期可设定为该网络流量值的来源信息为星期几。此外,还可以以天为周期进行设定。
s22:对多信息的网络流量值数据中的缺失点进行补足,得到补足完整的网络流量值数据。
首先,根据可接受的流量最小值和相邻网络流量值之间的时间间隔对网络流量值进行筛查;当满足xt<σ或两个相邻数据的时间间隔大于采样间隔时,则判定该点为缺失点;其中,xt表示流量序列x(t)在时刻t的数据,σ表示可接受的流量最小值。
然后,利用平均值法对缺失点进行补足,得到补足完整的网络流量值数据。
具体地,可根据当前缺失点的前三个时刻的数据平均值对该缺失点进行补足。例如,若xt对应的点被判定为缺失点,则补足公式表示为:
其中,
s23:对补足完整的网络流量值数据中的离群点进行剔除,得到重建的网络流量值数据。
首先,对补足完整的网络流量值数据进行归一化处理,得到归一化的网络流量值数据。例如,可通过最大最小归一化方法对补足后的网络流量值进行归一化处理,最大最小归一化的公式如下:
其中,x表示归一化值,x表示网络流量值,xmax和xmin分别表示网络流量数据集中的最大值和最小值。
然后,对归一化的网络流量值数据进行筛查,当不满足
进一步地,一天中xt的波动程度δt的计算公式为:
最后,利用差值替换法或者趋势替换法对离群点进行剔除,得到重建后的网络流量值。
请参见图3,图3是本发明实施例提供的离群点剔除示意图。具体地,若判断xt是离群值(即xt对应的点是离群点),则用一个替换值将其覆盖。
在本实施例中,可以利用差值替换法计算离群点的替换值,如图3中(a)所示,通过将最后一个时间间隔中的流量值差与xt前一时刻的流量值相加得到离群点的替换值,计算公式为:
其中,
然后利用该离群点的替换值替换所述离群点的流量值。
在本发明的另一个实施例中,还可以利用趋势替换法计算离群点的替换值,如图3中(b)所示,其中,离群值xt延续最近两个时间间隔内流量值的变化趋势,使离群点与前一时刻流量值间的差值继承上一时间间隔中的流量值之差,计算公式为:
其中,
然后利用该离群点的替换值替换所述离群点的流量值。
由于流量收集设备的故障或某些意外情况(例如紧急情况,社会事件和自然灾害等),采集的网络流量数据中存在一些缺失点和离群值,这些异常的流量值会导致较大的预测误差和较低的神经网络收敛速度,本发明提供的数据重建方法通过对流量数据中的缺失点和离群点进行筛选和剔除,可以有效避免异常数据对预测性能产生的负面影响,提高预测精度。
此外,本发明提供的差值替换法和趋势替换法可有效剔除流量中的离群点使流量数据更加稳定,从而为后续的emd分解和神经网络训练做准备。其中,差值替换法更为直观,趋势替换法可以更好地捕获流量动态变化的特征。
s3:利用emd算法对重建的网络流量值数据进行分解处理,得到若干网络流量值分量,包括:
s31:利用emd算法对重建的网络流量值数据进行分解处理,得到具有不同频率的imf分量。
emd(empiricalmodedecomposition,经验模态分解)主要是以信号的自身尺度特性为基础,无需预先设定任何基函数,而是通过筛选的方式将原始的时间序列自适应地分解为一系列的本征模态函数(intrinsicmodefunction,imf),这些imfs彼此相互独立,且可凸显原始数据的局部特征信息。该方法既具备传统小波变换方法的多尺度分析的优势,又可克服小波分析中需提前设定基函数的问题,在处理非平稳非线性数据时具有明显优势,因此常用于处理具有自相似性的网络流量数据。
具体地,请参见图4,图4是本发明实施例提供的emd分解流程示意图,具体流程如下:
31a)寻找重建后的网络流量值数据集x(t)中的上极值点和下极值点;
31b)用三次样条曲线分别拟合上极值点和下极值点的包络线eup(t)和elow(t),并找到包络线eup(t)和elow(t)的平均值m(t):
31c)通过在x(t)中减去m(t)来计算中间状态s(t):
s(t)=x(t)-m(t)
31d)判断s(t)是否符合imf的约束条件;
31e)如果不符合,就用s(t)替换x(t)并重复上述步骤,直到s(t)符合imf的约束条件,此时s(t)就是分解出的imfi(t);
31f)若分解出一个imf,就将该imf信号从x(t)中剔除出去。
31g)重复上述步骤,直到信号的最后剩余部分rn(t)只是单调序列或小于阈值。至此,x(t)被分解为一系列imf分量和一个余量rn(t):
其中,imf有两个约束条件:①在整个数据段内,极值点的个数和过零点的个数必须相等或相差最多不能超过一个。②在任意时刻,由局部极大值点形成的上包络线和由局部极小值点形成的下包络线的平均值为零,即上、下包络线相对于时间轴局部对称。
通过以上方式,流量数据被分为从高频到低频的各尺度分量,使各分量的数据突发性小于原始流量数据,为神经网络训练和预测做准备。
本发明采用emd分解算法,将数据流量值进行分解重构,将分解后的各个分量作为神经网络的输入数据,有效利用网络流量的多尺度特性,并在一定程度上削弱流量的混沌性对预测模型的影响,可以为不稳定的网络流量获得高精度的结果,使整体预测性能更加稳定。
s32:将每个imf分量按照一定比例分割为训练集和测试集。
具体的,本实施例可按照35:1的比例分割为训练集和测试集,前者用于训练神经网络模型,后者用于测试训练后的模型的预测性能。
s4:利用所述若干网络流量值分量对gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络。
s41:构建多信息感知的gru-vtd神经网络。请参见图5,图5是本发明实施例提供的多信息感知的gru-vtd神经网络结构示意,具体流程如下:
41a)首先构建一个包括一个输入层、若干隐含层和一个输出层的普通rnn,各层之间依次连接,用于传输数据;
41b)将普通rnn中隐含层神经元替换为具有门控机制的gru,得到一个普通的gru神经网络,其输入层为输入层1,也即第一输入层,若干隐含层为第一批隐含层;
41c)将网络流量值作为普通的gru神经网络的输入数据,得到gru-v神经网络;
41d)在gru-v神经网络的基础上,在第一批隐含层的最后一层与输出层之间加入与输入层1具有同等数量神经元的输入层2(即第二输入层)和与第一批隐含层具有同等规模的第二批隐含层,将输入层2和第一批隐含层的最后一层的输出作为第二批隐含层中第一层的输入数据,并将第二批隐含层中最后一层的输出数据传送给输出层,得到双信息感知的神经网络;
41e)将网络流量值对应的时间戳作为双信息感知的神经网络输入层2的输入数据,得到gru-vt神经网络;
41f)在gru-vt神经网络的基础上,在第二批隐含层的最后一层与输出层之间加入与输入层1具有同等数量神经元的输入层3(即第三输入层)和与第一批隐含层具有同等规模的第三批隐含层,将输入层3和第二批隐含层的最后一层的输出作为第三批隐含层中第一层的输入数据,并将第三批隐含层中最后一层的输出数据传送给输出层,得到多信息感知的神经网络;
41g)将网络流量值来自于星期几作为多信息感知的神经网络输入层3的输入数据,得到gru-vtd神经网络。
通过该神经网络模型可以有效利用神经网络的多种属性信息,充分把握网络流量的周期性,从而提高预测精度。
本发明通过综合考虑网络流量的流量值、时间戳和星期几信息,构建多信息感知的神经网络gru-vtd来利用流量数据的周期性,有效提高了预测的精度;同时,采用多信息感知的神经网络gru-vtd进行预测,还可以有效利用网络流量的自相似性,克服传统预测模型预测精度低、收敛速度慢的缺点。
s42:将每个imf分量中训练集的网络流量值及其对应的时间戳和来源信息分别输入到gru-vtd神经网络的第一输入层、第二输入层以及第三输入层,得到的gru-vtd神经网络的输出层结果。
具体地,将每个imf分量中训练集的网络流量值及其对应的时间戳和来源信息(也即星期几)分别输入到与各imf分量匹配的gru-vtd神经网络的第一输入层(输入层1)、第二输入层(输入层2)以及第三输入层(输入层3),得到每个gru-vtd神经网络的输出层结果。
s43:将gru-vtd神经网络的输出层结果与输入的网络流量值之间的mse作为损失函数调整神经网络节点间的连接权重,以对各个gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络。
s5:利用训练好的gru-vtd神经网络进行预测,并根据得到的预测值和网络流量值数据计算预测误差,以对模型进行性能评估。
s51:将每个所述imf分量中测试集的网络流量值及其对应的时间戳和来源信息分别输入到对应的训练好的gru-vtd神经网络的第一输入层、第二输入层以及第三输入层,并将每个gru-vtd神经网络的输出结果进行累加,得到模型的预测值。
具体地,将每个imf分量中测试集的网络流量值及其对应的时间戳和来源信息(也即星期几)分别输入到对应的训练好的gru-vtd神经网络的第一输入层(输入层1)、第二输入层(输入层2)以及第三输入层(输入层3),并将每个gru-vtd神经网络的输出结果进行累加,得到模型的预测值。
s52:计算所述模型的预测值与所述网络流量值数据之间的预测误差,并根据该预测误差对网络模型进行评估。
本发明针对采集到的原始流量数据中的失真数据,以及当前网络流量的自相似性、周期性、混沌性、多尺度等特征,通过归一化、缺失点补全和离群值剔除来重建流量数据;再通过emd技术将网络流量序列分解为多个分量,从而将网络流量的多尺度进行分离;然后综合考虑网络流量的流量值、时间戳和来源信息,构建多信息感知的神经网络gru-vtd,并将emd分解得到的各个分量分别用于训练与之对应的gru-vtd,最后将所有神经网络的输出送入到累加器中以获得最终的预测结果。克服了现有预测技术中预测精度低、易陷入局部最优、鲁棒性低的缺点,具有更高的预测精度和稳定性。
实施例二
在上述实施例一的基础上,本实施例提供了一种基于数据重建和混合预测的网络流量预测装置,请参见图6,图6是本发明实施例提供的基于数据重建和混合预测的网络流量预测装置结构示意图,其包括:
数据获取模块1,用于获取网络流量值数据;
重建模块2,用于对所述网络流量值数据进行重建,得到重建的网络流量值数据;
分解模块3,用于利用emd方法对所述重建的网络流量值数据进行分解处理,得到若干网络流量值分量;
训练模块4,用于利用若干网络流量值分量对gru-vtd神经网络进行训练,得到训练好的gru-vtd神经网络;
预测模块5,用于利用训练好的gru-vtd神经网络进行预测,并根据得到的预测值和网络流量值数据计算预测误差,以对模型进行性能评估。
本实施例提供的基于数据重建和混合预测的网络流量预测装置可实现上述实施例一提供的基于数据重建和混合预测的网络流量预测方法,具体过程在此不再赘述。
实施例三
下面通过仿真实验对本发明的有益效果进行进一步说明。
1.仿真条件:
在本次仿真实验中使用的流量数据集由wideinternet的测量与分析(mawi)工作组提供,提取2014年至2017年数据速率的平均值(以兆比特/秒(mbps)为单位),采样间隔为10分钟,将采样后的网络流量数据作为实验的数据集。我们使用2014年1月至2017年11月的数据进行训练,其余数据用于测试训练好的模型。
在本次仿真实验中,缺失点补足步骤中的可接受的流量最低值为300mbps,离群值消除的强度设置为6,emd中imf的保留数量设置为3。此外,将输入流量长度设置为一天(1440分钟),并将预测流量长度设置为半天(720分钟),因此将输入层中的神经元数设置为144,将输出层中的神经元数设置为72。隐藏层中的层数设置为1,隐藏层中的神经元数在gru中设置为100,在gru-vt和gru-vtd中设置为10。神经网络的损失函数为mse,学习率为0.1,训练的循环次数为30。具体如下表1所示:
表1仿真参数设置
2.仿真内容及结果分析:
本次仿真实验是利用本发明的方法和现有技术的方法,针对不同的改进机制,对各预测模型在对真实网络流量进行预测时的预测性能进行评估计算,仿真结果如图7-9所示。
在加入不同的网络流量属性信息时,gru神经网络具有不同的预测精度。图7给出了本发明仿真中结合不同的网络流量属性信息后神经网络预测误差的对比图,图7中gru-v表示基于gru的预测模型,该模型仅将流量值作为输入,gru-vt同时使用流量的值和时间戳,而gru-vtd基于gru-vt添加流量的星期几信息。如图7所示,gru-vt的mse平均值比gru-v的小71.07%,gru-vtd的mse平均值比gru-vt的小71.88%,这表明考虑了gru-vt的属性信息使预测模型能够捕获网络流量的周期性,从而提高了预测准确性。
图8为本发明仿真中结合了网络流量值、时间戳和星期几信息的预测模型gru-vtd与加入所提数据重建机制后的预测模型gru-vtd-rc的预测误差对比图,从图8可以看出,在26天的测试数据中,在gru-vtd模型基础上加入数据重建模块的gru-vtd-rc具有比gru-vtd更低的mse,且mse的平均值降低了45.76%。结果表明,数据重构过程可以有效消除数据集中的缺失点和离群值,有利于训练过程,从而提高了预测精度。但是,若某天的离群点较多,数据重建反而会增加预测误差。
图9为本发明仿真中gru-vtd、gru-vtd-rc以及结合了emd和gru-vtd-rc预测模型gru-vtd-rc-emd的预测误差对比图,如图7所示,通过添加emd模块,与gru-vtd-rc相比,gru-vtd-rc-emd具有更稳定的预测性能。gru-vtd-rc和gru-vtd-rc-emd的mse平均值分别为0.00268和0.00253。但是mse的标准偏差在gru-vtd-rc中为0.00171,在gru-vtd-rc-emd中为0.00081。换句话说,这两种预测方法的精度相似,但是gru-vtd-rc-emd的预测性能比gru-vtd-rc更稳定。因此emd可以平滑原始数据并减少因异常值频繁发生而造成的影响,从而使gru更容易捕获数据特征并稳定地获得较高的预测精度。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!