一种基于知识图谱的个性化试题推荐方法
1.本发明属于智慧教育推荐方法技术领域,涉及一种基于知识图谱的个性化试题推荐方法。
背景技术:
2.随着互联网大数据的不断发展,在线教育和智慧教育得到了迅速的发展,推荐系统也如雨后春笋般发展起来。在线教育打破时间和空间的限制,有效提高了学生的学习效率。这些推荐系统为学生提供了海量的练习试题来帮助学生对知识的检验和巩固。在数据爆炸的时代,面对浩如烟海的试题资源,学生在有限的时间内练习完所有相关的试题是不可能的。如何让学生在有限时间内练习适合个体认知水平和发展的试题是一个重要的研究课题。
3.推荐系统这一思想是在1994年被resnick等人引入的,推荐算法是推荐系统的核心,目前的推荐算法主要被分为基于内容的推荐算法、基于协同过滤的推荐算法和混合推荐算法。协同过滤算法是这三类推荐算法中最简单易懂且应用最广泛的推荐算法,尤其在电子商务领域的应用效果特别显著。近些年,有学者将学生对象看作电子商务中的用户,试题看作商品,学生在测试试题后的得分看作用户对商品的评分,使用协同过滤推荐算法进行学生的得分预测。还有学者使用基于近邻和模型的协同过滤来预测学生在试题上的得分。虽然协同过滤算法普适性高,但是其旨在通过学生答题的共性来预测学生的得分,忽略了学生的个性特征,同时协同过滤算法会遇到矩阵数据稀疏、冷启动等问题。
4.在认知心理学中,认知诊断模型从知识层面对学生的认知状态进行了很好的建模,因此基于认知诊断的计算机自适应测试为个性化试题推荐提供了新的思路。系统根据受试者当前题目作答情况自适应地动态调整下一道试题,实施的反馈受试者的认知信息。朱天宇等提出了一种基于学生知识点掌握程度的协同过滤试题推荐方法,利用答题情况和知识点的关联对学生实际知识水平进行建模,并将掌握水平用于概率矩阵以分解预测作答状况,从而进行相应的试题推荐,一定程度上提高了解释性和可靠性。齐斌等人提出基于协同过滤和认知诊断的试题推荐方法,设计了基于多级属性评分的认知诊断模型,并利用该模型对被试者的答题情况进行建模;然后,将被试者的知识属性掌握模式用于概率矩阵分解,预测被试者的潜在答题情况。上述提出两种方案分别从个性和共性考虑完善推荐模型,但是却没有考虑到推荐试题对应知识点间的关系。
技术实现要素:
5.本发明的目的是提供一种基于知识图谱的个性化试题推荐方法,解决了现有技术中存在的无法考虑到推荐试题对应知识点间的关系的问题。
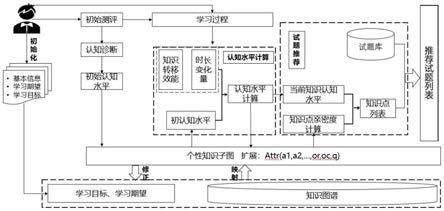
6.本发明所采用的技术方案是,一种基于知识图谱的个性化试题推荐方法,具体按照如下步骤实施:
7.步骤1,构建对应领域的知识图谱
8.根据推荐对象选择对应的知识领域的电子课本构建知识点的本体结构,然后人工抽取本体结构中的实体、关系和属性,实现知识图谱初步构建,然后自顶向下人工构建对应领域的知识图谱;
9.步骤2,爬取网络中对应领域的试题作为试题库,并对试题库中的试题通过人工分析试题所考察的知识点,将试题对应到知识图谱中,从而将考查知识点与试题对应起来;
10.步骤3,根据学习者的学习目标和知识图谱,映射出每一个学习者的个性化知识子图;
11.步骤4,获取学习者知识点的当前认知水平;
12.步骤5,计算知识点的亲密度;
13.步骤6,基于学习者对目标知识点的认知水平与知识点的亲密度实现个性化试题推荐。
14.本发明的特征还在于,
15.步骤1具体为:
16.步骤1.1,根据推荐对象选择对应的知识领域,将对应知识领域电子课本按照三层进行分类,章为第一层,节为第二层,元知识为第三层,其中,章中包含的字段有章id、章名、章的描述以及章节下所包含节的id;节中包含的字段有节id、节名、节的描述及所属的章id;元知识不可再分,包含的字段有元知识id、元知识名、先序知识点id、后续知识点id、其他关系知识点id及所属节id,完成对应知识领域本体结构的构建;
17.步骤1.2,然后人工抽取本体结构中的实体、关系和属性,实体即就是章、节、元知识,关系是指通过边将两个实体连接起来,属性是指实体对象所具有的特点,实现知识图谱初步构建;
18.步骤1.3,使用八爪鱼爬虫工具爬取百度百科数据,将获取的部分语料句子数据进行人工bio标注,对标注的数据使用bilistm+crf算法经过训练后,对其余部分数据进行实体抽取,并对一条语料中含有的多个实体进行不重复两两组队,抽取后结果存入mysql数据库中,对抽取结果两个实体完全一样的数据进行去重;
19.步骤1.4,进行关系抽取,将步骤1.3得到的去重后的数据的一部分数据通过人工判断实体间关系,生成<实体,实体,关系,语料句子>这种格式的数据,将其作为训练数据使用双重注意的bi
‑
gru训练关系模型进行训练,然后用训练完成的模型对其余部分数据生成<实体,实体,语料句子>格式的数据进行关系抽取,最后将抽取出来的三元组与人工手工初步建立的知识图谱进行融合,实现领域知识图谱的构建。
20.步骤2中的试题标注即就是通过人工分析试题所考察知识点,将试题对应到知识图谱中对应知识点的实体id,从而将考查知识点与试题对应起来,然后进行整理,保存到mysql数据库中,其中试题的具体保存信息主要包括试题id、题干、答案、解析、对应的知识点id以及试题难度。
21.学习目标定义为:学习者想要学习的知识范围,使用gl(k,e)表示,其中,k表示知识范围即知识的广度,e则表示学习者想要将知识掌握的程度即知识的深度。
22.步骤3具体为:
23.首先将学习目标gl(k,e)中的k定位到已经构建好的层级知识图谱中:
24.若定位不到步骤1构建好的知识图谱中,则重新确定学习目标;
25.如果k知识点为一层知识点,则把通过父子关系查询该知识点的所有第二层子知识点,然后再通过所有第二层知识点分别查询它们的第三层子知识点,通过第三层子知识点查询各自的属性及其知识点间的关系,构成个性化知识子图;
26.如果k知识点为第二层的知识点,则通过父子关系查询该知识点的所有第三层的子知识点,并且对与查询到的知识点查询各自的属性及知识点间的关系,构成个性化知识子图;
27.如果k知识点本身就是第三层的元知识,则以该知识点为中心,查询与该知识点相关的所有元知识,并查询这些元知识间的关系构成个性化知识子图。
28.步骤4中学习者知识点的当前认知水平p(l
c
)的计算方法如下:
29.p(l
c
)=p(l
o
)+(1
‑
p(l
o
))*p(t)*f(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
30.其中,p(l0)表示知识点的初始认知水平;f(t)表示学习者学习过程中的时间效率,表示学习者掌握知识点的过程中所消耗时间;p(t)表示学习者的知识转移效能;
31.其中,
[0032][0033]
式中,t
e
表示学习者学习知识点的期望学习时长;t表示学习者实际学习知识点的时长。
[0034]
学习者对知识点的初始认知水平p(l0)为:
[0035][0036]
其中,z
u
表示学生u对所有试题的答题情况,p(α
i
|z
u
)在已知试题答题情况下的某种模式下知识点掌握情况概率,l表示可能出现的模式的数量,i表示某种指定模式,v表示试题的数量,和表示dina模型中获取的所有试题失误率和猜对率两个参数,α
i
指dina原始模型获取到某个学生的离散认知水平,l表示似然函数,α
uk
表示学生u对知识点k的掌握程度;z
uv
表示学生u对试题v的答题情况。
[0037]
步骤5具体为:
[0038]
在步骤3确定学习者个性化知识子图后,学习者个性化知识子图中知识点的亲密度采用直接关系与间接关系相结合的方式计算,其中,直接关系是指两个实体之间含有边,间接关系是第三个实体同时与两个实体之间有边,就说这两个实体间存在间接关系;
[0039]
计算知识点的亲密度,即就是计算知识点实体之间的亲密度,具体按照如下公式计算:
[0040][0041]
其中,λ为直接关系权重,λ2为间接关系权重,0<λ<1,直接关系的权重大于间接关系的权重,w(k
i
,k
j
)指两个实体的直接关系,r为两个实体的间接关系,r=(r1,r2,...,r
l
),w为关系权重,w=(w1,w2,
…
w
l
),l表示关系数量,w
τ
为w的转置,k
i
和k
j
表示两个不同的实体向
量,k
i
=(e
1i
,e
2i
,...,e
ni
)τ,k
j
=(e
1j
,e
2j
,
…
,e
nj
)
τ
,其中,n为实体向量的维度,r
l
=0or1,0则表示实体在间接关系中不存在关系,1则表示实体在间接关系中存在关系。
[0042]
步骤6具体为:
[0043]
步骤6.1,根据公式(3)计算个性化知识子图中每个知识点对应的当前认知水平,并存入列表klist<(k1,p(l
c1
)),(k2,p(l
c2
)),...,(k
n
,p(l
cn
))>中,其中,(k
n
,p(l
cn
))表示k
n
表示某个知识点,p(l
cn
)表示该知识点k
n
当前认知水平;
[0044]
步骤6.2,根据公式(7)个性化知识子图中所有知识点的亲密度,然后由高到低选取前υ个亲密度的知识点;
[0045]
步骤6.3,遍历获取的υ个知识点,找到目标知识点,获取学习者对其的认知水平p(l
cg
),若0<p(l
cg
)<α,则从个性化知识子图中获取与该目标知识点为前驱后继关系的另一知识点,则从个性化知识子图中获取该目标知识点的前驱知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者;
[0046]
若α<=p(l
cg
)<β,则根据获取到的亲密度较高的前υ个知识点的id和认知水平推荐对应难度的试题给学习者,其中0<α<β<1;则根据获取到的亲密度较高的前υ个知识点的认知水平推荐对应难度的试题给学习者,其中0<α<β<1;
[0047]
若β<=p(l
cg
)<1,则从个性化知识子图中获取该目标知识点的后继知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者。根据另一知识点的认知水平对应难度的试题给学习者。
[0048]
本发明的有益效果是:
[0049]
(1)考虑到了学习者间的个性特征。本发明在计算学习者对知识点的初始认知水平时,利用dina对初始测试结果进行分析,获取学习者的初始认知水平。
[0050]
(2)认知水平的动态变化性。对于已有的试题推荐算法,基本都是对于静态某个时间点上试题的推荐,但对于学习者来说,学习是一个过程,不同时刻的知识认知水平可能会发生变化,所以对应于所需要推荐的试题也应该随之改变。本发明则根据学习者的知识转移效能和时间变化中的学习,更新学习者的认知水平后,再进行试题的推荐。
[0051]
(3)考虑知识体系结构为学习者推荐更合理的试题。以往研究者在研究试题推荐问题时,大多忽略了知识点间的结构关系,对于学习者来说,知识的掌握不成体系,离散程度高,不益于学习者的后续学习。在本发明中,首先根据知识体系结构,构建了相关课程的知识图谱,同时在试题推荐过程中,依据知识点间依存关系,为学习者推荐更合适自己的试题,更方便了学习者明确自己知识点的掌握情况。
[0052]
(4)具有良好的扩展性能。在本发明提出的推荐方法中,每个模块都是分别做了设计,都是独立的,所以如果后期需要扩展或者变动,只需要对需要变动的部分进行修改,其他模块不需要进行变动,具有良好的扩展性能。
附图说明
[0053]
图1是本发明一种基于知识图谱的个性化试题推荐方法的流程图;
[0054]
图2是本发明一种基于知识图谱的个性化试题推荐方法实施例中实体抽取结果图;
[0055]
图3是本发明一种基于知识图谱的个性化试题推荐方法实施例中关系抽取结果
图;
[0056]
图4是本发明一种基于知识图谱的个性化试题推荐方法实施例中课程知识图谱构建过程图;
[0057]
图5是本发明一种基于知识图谱的个性化试题推荐方法生成个性化知识子图算法流程图;
[0058]
图6是本发明一种基于知识图谱的个性化试题推荐方法实施例中实体间关系示例图。
具体实施方式
[0059]
下面结合附图和具体实施方式对本发明进行详细说明。
[0060]
本发明一种基于知识图谱的个性化试题推荐方法,具体按照如下步骤实施:
[0061]
步骤1,构建对应领域的知识图谱
[0062]
根据推荐对象选择对应的知识领域的电子课本构建知识点的本体结构,然后人工抽取本体结构中的实体、关系和属性,实现知识图谱初步构建,然后自顶向下人工构建对应领域的知识图谱;
[0063]
具体为:
[0064]
步骤1.1,根据推荐对象选择对应的知识领域,将对应知识领域电子课本按照三层进行分类,章为第一层,节为第二层,元知识为第三层,其中,章中包含的字段有章id、章名、章的描述以及章节下所包含节的id;节中包含的字段有节id、节名、节的描述及所属的章id;元知识不可再分,包含的字段有元知识id、元知识名、先序知识点id、后续知识点id、其他关系知识点id及所属节id,完成对应知识领域本体结构的构建;
[0065]
步骤1.2,然后人工抽取本体结构中的实体、关系和属性,实体即就是章、节、元知识,关系是指通过边将两个实体连接起来,属性是指实体对象所具有的特点,实现知识图谱初步构建;
[0066]
步骤1.3,使用八爪鱼爬虫工具爬取百度百科数据,将获取的部分语料句子数据进行人工bio标注,对标注的数据使用bilistm+crf算法经过训练后,对其余部分数据进行实体抽取,并对一条语料中含有的多个实体进行不重复两两组队,抽取后结果存入mysql数据库中,对抽取结果两个实体完全一样的数据进行去重;
[0067]
步骤1.4,进行关系抽取,将步骤1.3得到的去重后的数据的一部分数据通过人工判断实体间关系,生成<实体,实体,关系,语料句子>这种格式的数据,将其作为训练数据使用双重注意的bi
‑
gru训练关系模型进行训练,然后用训练完成的模型对其余部分数据生成<实体,实体,语料句子>格式的数据进行关系抽取,最后将抽取出来的三元组与人工手工初步建立的知识图谱进行融合,实现领域知识图谱的构建。
[0068]
步骤2,爬取网络中对应领域的试题作为试题库,并对试题库中的试题通过人工分析试题所考察的知识点,将试题对应到知识图谱中,从而将考查知识点与试题对应起来;其中,试题标注即就是通过人工分析试题所考察知识点,将试题对应到知识图谱中对应知识点的实体id,从而将考查知识点与试题对应起来,然后进行整理,保存到mysql数据库中,其中试题的具体保存信息主要包括试题id、题干、答案、解析、对应的知识点id以及试题难度;
[0069]
步骤3,根据学习者的学习目标和知识图谱,映射出每一个学习者的个性化知识子
图;学习目标定义为:学习者想要学习的知识范围,使用gl(k,e)表示,其中,k表示知识范围即知识的广度,e则表示学习者想要将知识掌握的程度即知识的深度,具体为:
[0070]
首先将学习目标gl(k,e)中的k定位到已经构建好的层级知识图谱中:
[0071]
若定位不到步骤1构建好的知识图谱中,则重新确定学习目标;
[0072]
如果k知识点为一层知识点,则把通过父子关系查询该知识点的所有第二层子知识点,然后再通过所有第二层知识点分别查询它们的第三层子知识点,通过第三层子知识点查询各自的属性及其知识点间的关系,构成个性化知识子图;
[0073]
如果k知识点为第二层的知识点,则通过父子关系查询该知识点的所有第三层的子知识点,并且对与查询到的知识点查询各自的属性及知识点间的关系,构成个性化知识子图;
[0074]
如果k知识点本身就是第三层的元知识,则以该知识点为中心,查询与该知识点相关的所有元知识,并查询这些元知识间的关系构成个性化知识子图。
[0075]
步骤4,获取学习者知识点的当前认知水平;学习者知识点的当前认知水平p(l
c
)的计算方法如下:
[0076]
p(l
c
)=p(l
o
)+(1
‑
p(l
o
))*p(t)*f(t)
ꢀꢀꢀꢀꢀꢀꢀ
(3)
[0077]
其中,p(l0)表示知识点的初始认知水平;f(t)表示学习者学习过程中的时间效率,表示学习者掌握知识点的过程中所消耗时间;p(t)表示学习者的知识转移效能;
[0078]
其中,
[0079][0080]
式中,t
e
表示学习者学习知识点的期望学习时长;t表示学习者实际学习知识点的时长;
[0081]
步骤5,计算知识点的亲密度;在步骤3确定学习者个性化知识子图后,学习者个性化知识子图中知识点的亲密度采用直接关系与间接关系相结合的方式计算,其中,直接关系是指两个实体之间含有边,间接关系是第三个实体同时与两个实体之间有边,就说这两个实体间存在间接关系;
[0082]
计算知识点的亲密度,即就是计算知识点实体之间的亲密度,具体按照如下公式计算:
[0083][0084]
其中,λ为直接关系权重,λ2为间接关系权重,0<λ<1,直接关系的权重大于间接关系的权重,w(k
i
,k
j
)指两个实体的直接关系,r为两个实体的间接关系,r=(r1,r2,...,r
l
),w为关系权重,w=(w1,w2,
…
w
l
),l表示关系数量,w
τ
为w的转置,k
i
和k
j
表示两个不同的实体向量,k
i
=(e
1i
,e
2i
,...,e
ni
),k
j
=(e
1j
,e
2j
,
…
,e
nj
)
τ
,其中,n为实体向量的维度,r
l
=0or1,0则表示实体在间接关系中不存在关系,1则表示实体在间接关系中存在关系。
[0085]
步骤6,基于学习者对目标知识点的认知水平与知识点的亲密度实现个性化试题推荐,具体为:
[0086]
步骤6.1,根据公式(3)计算个性化知识子图中每个知识点对应的当前认知水平,
并存入列表klist<(k1,p(l
c1
)),(k2,p(l
c2
)),...,(k
n
,p(l
cn
))>中,其中,(k
n
,p(l
cn
))表示k
n
表示某个知识点,p(l
cn
)表示该知识点k
n
当前认知水平;
[0087]
步骤6.2,根据公式(7)个性化知识子图中所有知识点的亲密度,然后由高到低选取前υ个亲密度的知识点;
[0088]
步骤6.3,遍历获取的υ个知识点,找到目标知识点,获取学习者对其的认知水平p(l
cg
),若0<p(l
cg
)<α,则从个性化知识子图中获取与该目标知识点为前驱后继关系的另一知识点,则从个性化知识子图中获取该目标知识点的前驱知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者;
[0089]
若α<=p(l
cg
)<β,则根据获取到的亲密度较高的前υ个知识点的id和认知水平推荐对应难度的试题给学习者,其中0<α<β<1;则根据获取到的亲密度较高的前υ个知识点的认知水平推荐对应难度的试题给学习者,其中0<α<β<1;试题难度是0
‑
1之间的数值,认知水平是0
‑
1之间的数值,根据认知水平推荐对应知识点下对应难度的试题;
[0090]
若β<=p(l
cg
)<1,则从个性化知识子图中获取该目标知识点的后继知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者。根据另一知识点的认知水平对应难度的试题给学习者。
[0091]
实施例
[0092]
一种基于知识图谱的个性化试题推荐方法,其流程如图1所示,具体按照如下步骤实施:
[0093]
步骤1,构建对应领域的知识图谱
[0094]
根据推荐对象选择对应的知识领域的电子课本构建知识点的本体结构,然后人工抽取本体结构中的实体、关系和属性,实现知识图谱初步构建,然后自顶向下人工构建对应领域的知识图谱;
[0095]
具体为:
[0096]
步骤1.1,根据推荐对象选择对应的知识领域,将对应知识领域电子课本按照三层进行分类,章为第一层,节为第二层,元知识为第三层,其中,章中包含的字段有章id、章名、章的描述以及章节下所包含节的id;节中包含的字段有节id、节名、节的描述及所属的章id;元知识不可再分,包含的字段有元知识id、元知识名、先序知识点id、后续知识点id、其他关系知识点id及所属节id,完成对应知识领域本体结构的构建;
[0097]
步骤1.2,然后人工抽取本体结构中的实体、关系和属性,实体即就是章、节、元知识,关系是指通过边将两个实体连接起来,属性是指实体对象所具有的特点,实现知识图谱初步构建;
[0098]
步骤1.3,使用八爪鱼爬虫工具爬取百度百科数据,将获取的部分语料句子数据进行人工bio标注,对标注的数据使用bilistm+crf算法经过训练后,对其余部分数据进行实体抽取,并对一条语料中含有的多个实体进行不重复两两组队,抽取后结果存入mysql数据库中,对抽取结果两个实体完全一样的数据进行去重;
[0099]
步骤1.4,进行关系抽取,将步骤1.3得到的去重后的数据的一部分数据通过人工判断实体间关系,生成<实体,实体,关系,语料句子>这种格式的数据,将其作为训练数据使用双重注意的bi
‑
gru训练关系模型进行训练,然后用训练完成的模型对其余部分数据生成<实体,实体,语料句子>格式的数据进行关系抽取,最后将抽取出来的三元组与人工手工初
步建立的知识图谱进行融合,实现领域知识图谱的构建。
[0100]
本发明中选择了初中数学课程,首先根据课程标准将初中数学知识分为三大类:数与代数、图形与集合和统计与概率。在三大类结构下根据人教版电子课本章
‑
节
‑
知识点构建本体概念层次模型,其中章、节、元知识分别为一个类。章中包含的字段有章id(id是唯一的,所表示的实体是唯一的)、章名、章的描述以及章节下所包含节的id;节中包含的字段有节id、节名、节的描述及所属的章id;元知识不可再分,包含的字段有元知识id、元知识名、先序知识点id、后续知识点id、其他关系知识点id及所属节id,从而构建初中数学本体概念层次模型,然后根据构建的本体概念层次模型通过人工抽取初中人教版电子课本中的实体、关系和属性。根据初中数学课程本身的特性,本发明将实体包括章、节、知识点三级,章为一级,节为二级,知识点为三级;关系包括了包含、依赖、对义和同位四种类型,共7种关系:包含、被包含、依赖、被依赖、同义、反义和同位,如图6所示,例如:<正数,同义,负数>三元组表示正数和负数的关系是同义关系,属性包含17种:定义、加减乘除法则、交换律、结合律、分配律、意义、性质、基本事实、运算律、性质定理、判定定理、定理、推论、基本性质、判定方法、公式、运算法则,例如:<有理数,提出时间,公元前0580年>提出时间为有理数的属性,公元前0580年则为该属性值;从而自顶向下人工构建了“章
‑
节
‑
元知识”三级网状初中数学知识图谱。在人工构建了较高质量的图谱后,使用八爪鱼爬虫工具爬取百度百科数据,将获取的部分数据进行人工bio标注,定义实体,使用“b”表示实体中的第一个字符,“i”表示其他字符,非实体标记为“o”。对标注的数据使用bilistm+crf算法经过训练后,对其余部分数据进行实体抽取,并对一条语料中含有的多个实体进行不重复两两组队,抽取后结果存入mysql数据库中,如图2所示。对抽取结果两个实体完全一样的数据进行去重,将去重后的数据作为关系抽取的输入数据。在关系抽取中,一部分输入数据通过初中数学老师或专家对人工判断实体间关系,关系种类上述7种,将其作为训练数据使用双重注意的bi
‑
gru训练关系模型,然后用训练完成的模型对其余输入数据进行关系抽,抽取结果如图3所示,最后将抽取出来的三元组与人工手工构建的图谱进行融合,实现领域知识图谱的构建。因为从百度百科获取数据本身粒度较小,所以融合仅在知识点部分进行融合,构建过程如附图说明中图4所示。
[0101]
步骤2,爬取网络中对应领域的试题作为试题库,并对试题库中的试题通过人工分析试题所考察的知识点,将试题对应到知识图谱中,从而将考查知识点与试题对应起来;其中,试题标注即就是通过人工分析试题所考察知识点,将试题对应到知识图谱中对应知识点的实体id,从而将考查知识点与试题对应起来,然后进行整理,保存到mysql数据库中,其中试题的具体保存信息主要包括试题id、题干、答案、解析、对应的知识点id以及试题难度;
[0102]
步骤3,根据学习者的学习目标和知识图谱,映射出每一个学习者的个性化知识子图;学习目标定义为:学习者想要学习的知识范围,使用gl(k,e)表示,其中,k表示知识范围即知识的广度,对应到个性化知识子图中的某个实体,e则表示学习者想要将知识掌握的程度即知识的深度,具体为:
[0103]
首先将学习目标gl(k,e)中的k定位到已经构建好的层级知识图谱中:
[0104]
若定位不到步骤1构建好的知识图谱中,则重新确定学习目标;
[0105]
如果k知识点为一层知识点,则把通过父子关系查询该知识点的所有第二层子知识点,然后再通过所有第二层知识点分别查询它们的第三层子知识点,通过第三层子知识
点查询各自的属性及其知识点间的关系,构成个性化知识子图;
[0106]
如果k知识点为第二层的知识点,则通过父子关系查询该知识点的所有第三层的子知识点,并且对与查询到的知识点查询各自的属性及知识点间的关系,构成个性化知识子图;
[0107]
如果k知识点本身就是第三层的元知识,则以该知识点为中心,查询与该知识点相关的所有元知识,并查询这些元知识间的关系构成个性化知识子图。对于个性化的知识子图的结构,除了知识图谱本身的“实体
‑
关系
‑
实体,实体
‑
关系
‑
属性”外,对于知识点属性进行了扩展attr(a1,a2,...,or,cr,q),其中a
i
表示一般属性,or表示初始认知水平,cr表示当前认知水平,q表示期望掌握水平。如图所示为生成个性化知识子图的算法流程图如附图说明图5所示。
[0108]
步骤4,获取学习者知识点的当前认知水平;学习者知识点的当前认知水平p(l
c
)的计算方法如下:
[0109]
p(l
c
)=p(l
o
)+(1
‑
p(l
o
))*p(t)*f(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0110]
其中,p(l0)表示知识点的初始认知水平;f(t)表示学习者学习过程中的时间效率,表示学习者掌握知识点的过程中所消耗时间;p(t)表示学习者的知识转移效能;
[0111]
其中,
[0112][0113]
式中,t
e
表示学习者学习知识点的期望学习时长;t表示学习者实际学习知识点的时长;
[0114]
为学习者提供一份初始测评试题来分析学习者的初始认知水平。根据学习者的个性化知识子图,随机选取权重(某知识点在知识体系结构中的重要程度)较大的k知识点简单偏中等试题为学习者生成一组测评试卷,学习者的测评数据使用认知诊断中dina模型计算学习者的初始认知水平。
[0115]
经过dina模型可以直接获取到离散的认知水平,记作:α
u
,使用0和1表示未掌握和掌握两种情况,在此,为了获得从0~1之间的连续认知水平,本发明种考虑所有可能的后验概率来获得,则学习者对知识点初始认知水平p(l0)为:
[0116][0117]
其中,z
u
表示学生u对所有试题的答题情况,p(α
i
|z
u
)在已知试题答题情况下的某种模式下知识点掌握情况概率,l表示可能出现的模式的数量,i表示某种指定模式,v表示试题的数量,和表示dina模型中获取的所有试题失误率和猜对率两个参数,α
i
指dina原始模型获取到某个学生的离散认知水平,l表示似然函数,α
uk
表示学生u对知识点k的掌握程度;z
uv
表示学生u对试题v的答题情况。
[0118]
步骤5,计算知识点的亲密度;在步骤3确定学习者个性化知识子图后,学习者个性化知识子图中知识点的亲密度采用直接关系与间接关系相结合的方式计算,其中,直接关系是指两个实体之间含有边,间接关系是第三个实体同时与两个实体之间有边,就说这两
个实体间存在间接关系;
[0119]
计算知识点的亲密度,即就是计算知识点实体之间的亲密度,具体按照如下公式计算:
[0120][0121]
其中,λ为直接关系权重,λ2为间接关系权重,0<λ<1,直接关系的权重大于间接关系的权重,w(k
i
,k
j
)指两个实体的直接关系,r为两个实体的间接关系,r=(r1,r2,...,r
l
),w为关系权重,w=(w1,w2,
…
w
l
),l表示关系数量,w
τ
为w的转置,k
i
和k
j
表示两个不同的实体向量,k
i
=(e
1i
,e
2i
,...,e
ni
)τ,k
j
=(e
1j
,e
2j
,
…
,e
nj
)
τ
,其中,n为实体向量的维度,r
l
=0or1,0则表示实体在间接关系中不存在关系,1则表示实体在间接关系中存在关系。
[0122]
步骤6,基于学习者对目标知识点的认知水平与知识点的亲密度实现个性化试题推荐,对于课程知识点,其具有很严格逻辑性和结构性,不同知识点间可能存在着先后顺序。所以在试题推荐中知识点间的关系是一个重要的考虑因素。在步骤3中获得了学习者个性化知识子图后,除了明确的前驱后继关系,对于同义反义近义等一些关系很难直接判断知识点间的亲密度,同时如果在一个实体与另外两个实体间具有相同的直接关系,那么还需要借助间接关系来区分它们之间的其密度,因此在本发明中采取直接关系与间接关系相结合的方式计算知识点的间的亲密度,以确保获得更加准确的实体间亲密度,具体为:
[0123]
步骤6.1,根据公式(3)计算个性化知识子图中每个知识点对应的当前认知水平,并存入列表klis
t
<(k1,p(l
c1
)),(k2,p(l
c2
)),...,(k
n
,p(l
cn
))>中,其中,(k
n
,p(l
cn
))中k
n
表示某个知识点,p(l
cn
)表示该知识点k
n
当前认知水平;
[0124]
步骤6.2,根据公式(7)个性化知识子图中所有知识点的亲密度,然后由高到低选取前υ个亲密度的知识点;
[0125]
步骤6.3,遍历获取的υ个知识点,找到目标知识点,获取学习者对其的认知水平p(l
cg
),若0<p(l
cg
)<α,则从个性化知识子图中获取与该目标知识点为前驱后继关系的另一知识点,则从个性化知识子图中获取该目标知识点的前驱知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者;
[0126]
若α<=p(l
cg
)<β,则根据获取到的亲密度较高的前υ个知识点的id和认知水平推荐对应难度的试题给学习者,其中0<α<β<1;则根据获取到的亲密度较高的前υ个知识点的认知水平推荐对应难度的试题给学习者,其中0<α<β<1;例如,认知水平是0.5,推荐对应知识点下难度为0.5的试题;
[0127]
若β<=p(l
cg
)<1,则从个性化知识子图中获取该目标知识点的后继知识点,根据学习者另一知识点id和其认知水平推荐对应难度的试题给学习者。根据另一知识点的认知水平对应难度的试题给学习者。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1