基于异常样本检测和多维信息输出的脑卒中风险筛查方法
本发明属于脑卒中风险筛查技术领域,具体涉及一种基于异常样本检测和多维信息输出的脑卒中风险筛查方法。
背景技术:
脑卒中已成为威胁全球居民健康的重大疾病,是世界各国急需解决的重大公共卫生问题。脑卒中具有高发病率、高致死率以及高复发率等特点,严重地影响人类的生活质量和生命健康。据不完全统计,估算中国卒中患者的发病率在1300万左右,脑卒中死亡率大约占全球的30%,因此,如何对脑卒中高危人群的筛查,根据筛查结果对高危人群进行重点监护检测,是一种降低脑卒中的死亡率的方法;而提升脑卒中筛查技术的多样性、先进性、有效性对脑卒中的预防与控制有着至关重要的意义。目前,基于电子病历筛查脑卒中的方法中存在识别准确率不佳和脑卒中风险等级识别不够全面等问题,这是因为电子病历数据在采集的过程中存在医疗设备的系统误差、采集人员的偶然性误差、被采集人员的误报或漏报以及评估指标的主观性较强等问题,从而导致筛查数据集中存在大量的异常样本,异常样本的存在使得模型训练过程出现较大偏差及整体测试准确率较低。因此,如何剔除筛查数据集中存在的大量异常样本是目前提高用户脑卒中筛查效率和精确度中亟待解决的问题。
技术实现要素:
为解决以上现有技术存在的问题,本发明提出了一种基于异常样本检测和多维信息输出的脑卒中风险筛查方法,该方法包括:构建筛查对象的脑卒中风险因素数据集,将该数据集输入到训练好的脑卒中风险筛查预测评估模型中,得到风险因素重要性指标和脑卒中风险等级评估结果,并对异常评估结果的数据进行标记;所述脑卒中风险筛查预测评估模型包括风险因素重要性检测评估模型和脑卒中风险等级预测评估模型。
优选的,采用脑卒中风险筛查预测评估模型对数据集进行处理的过程包括:
s1:对脑卒中风险因素数据集中的数据进行归一化处理,得到归一化后的脑卒中风险因素数据集;
s2:采用卡方检验和f检验算法分别对归一化后的脑卒中风险因素数据集中各项风险因素进行重要性检验,得到两个重要性检验结果;
s3:采用特征复合得分指标对两个重要性检验结果进行优化,得到风险因素重要性检测评估结果;
s4:采用isolationforest算法对脑卒中风险数据集进行异常样本检测,去除识别到的异常样本,并对异常样本编号进行标记;
s5:将剔除异常样本后的数据集输入到脑卒中风险等级预测评估模型中进行预测评估,得到两个风险等级预测评估结果;所述脑卒中风险等级预测评估模型采用randomforest算法和线性svm算法分别计算剔除异常样本后的数据集;
s6:采用概率决策融合方法对两个风险等级预测评估结果进行优化,得到最终的脑卒中风险等级预测评估结果。
进一步的,脑卒中风险因素数据集包括筛查对象人群的人口统计学信息、生理检验指标信息、临床病史信息。
进一步的,对脑卒中风险数据集进行归一化处理的公式为:
进一步的,采用卡方检验和f检验算法分别对归一化后的脑卒中风险因素数据集中各项风险因素进行重要性检验的具体过程包括:
21、进行卡方检验的假设定义;设置零假定χi,0和备选假定χi,1;其中,零假定表示筛查对象风险数据集中第i项风险因素重要性高,备选假定表示筛查对象风险数据集中第i项风险因素重要性低;
22、根据卡方检验的假设定义计算各项风险因素的重要性评分;计算公式为:
其中,chi2i,score表示对数据集中第i条风险因素采用卡方检验计算出的重要性评分;a表示脑卒中患者中该项风险因素实际发生的频数,t表示预期发生的频数;
23、进行f检验的假设定义;设置f的零假定fi,0和备选假定fi,1,零假定表示筛查对象风险数据集中第i项风险因素重要性低;备选假定表示筛查对象风险数据集中第i项风险因素重要性高;
24、根据风险等级将筛查数据集中的样本进行划分;
25、根据f检验的假设定义和风险类别检测各项风险因素的重要性评分,检测方法为:
进一步的,风险等级分为5种等级,等级分别为第一等级为零风险,第二等级为低危,第三等级为高危,第四等级为缺血性脑卒中,第五等级为出血性脑卒中。
优选的,特征复合得分指标的计算公式为:
优选的,采用isolationforest算法对脑卒中风险数据进行异常样本检测和剔除的过程包括:
41:设置isolationforest异常样本检测模型的参数,所述参数包括采样点参数、二叉树个数以及二叉树深度;
42:将脑卒中风险数据集中的数据输入到isolationforest异常样本检测模型中检测异常样本,对识别出的异常样本数据进行标记;
43:将异常样本从脑卒中筛查对象的风险因素数据集中剔除,得到经过异常样本剔除的脑卒中筛查对象的风险因素数据集。
优选的,脑卒中风险等级预测评估模型预测两个风险等级预测评估结果的过程包括:
s51:对经过异常样本筛除后的脑卒中筛查对象数据集进行划分,得到训练集和测试集;
s52:配置randomforest分类预测模型的参数;所述配置的参数包括:特征指标总个数、决策树使用特征的最大数量、决策子树个数、决策树叶子数以及分类结果种类数;
s53:将训练集中的数据输入到randomforest分类预测模型训练,将测试集中的数据输入到训练好的randomforest分类预测模型中,得到第一脑卒中风险等级预测评估结果;
s54:构建线性svm分类预测模型,对线性svm分类预测模型的参数进行配置;配置的参数包括:核函数选择线性和核函数,输入数据中的属性数以及分类结果数;
s55:将训练集中的数据输入到线性svm分类预测模型进行训练,将测试集中的数据输入到训练好的线性svm分类预测模型中进行分类预测,得到第二脑卒中风险等级预测评估结果。
优选的,概率决策融合方法为:
本发明提出了一种基于异常样本检测和多维信息输出的脑卒中风险筛查方法,能够有效的辅助进行脑卒中风险筛查;采用单一检测方法评估脑卒中风险因素的重要性时,其检测结果存在波动性;本发明分别采用基于卡方(chi2)检验和f检验两种算法计算出重要性评估得分,然后采用特征复合得分指标对上述得到的两个评估评分进行优化处理,使得评估出的结果更加准确与稳定;本发明在进行风险等级分类预测评估前,先采用isolationforest算法对筛查数据中的异常样本进行检查和剔除,有效的减少了异常样本对于预测分类评估环节的影响,有效的提高了预测评估的准确度;本发明选取欧式距离较大且余弦相似度较低的两个算法模型:randomforest分类预测模型和线性svm分类预测来评估脑卒中风险评分,然后对上述两个评估出的结果采用概率融合决策方法进行优化处理,得到最终的脑卒中风险等级预测评估结果;通过上述方法能够增强对于不同地区和不同筛查对象下的普适性,进一步提高了预测结果的准确率。
附图说明
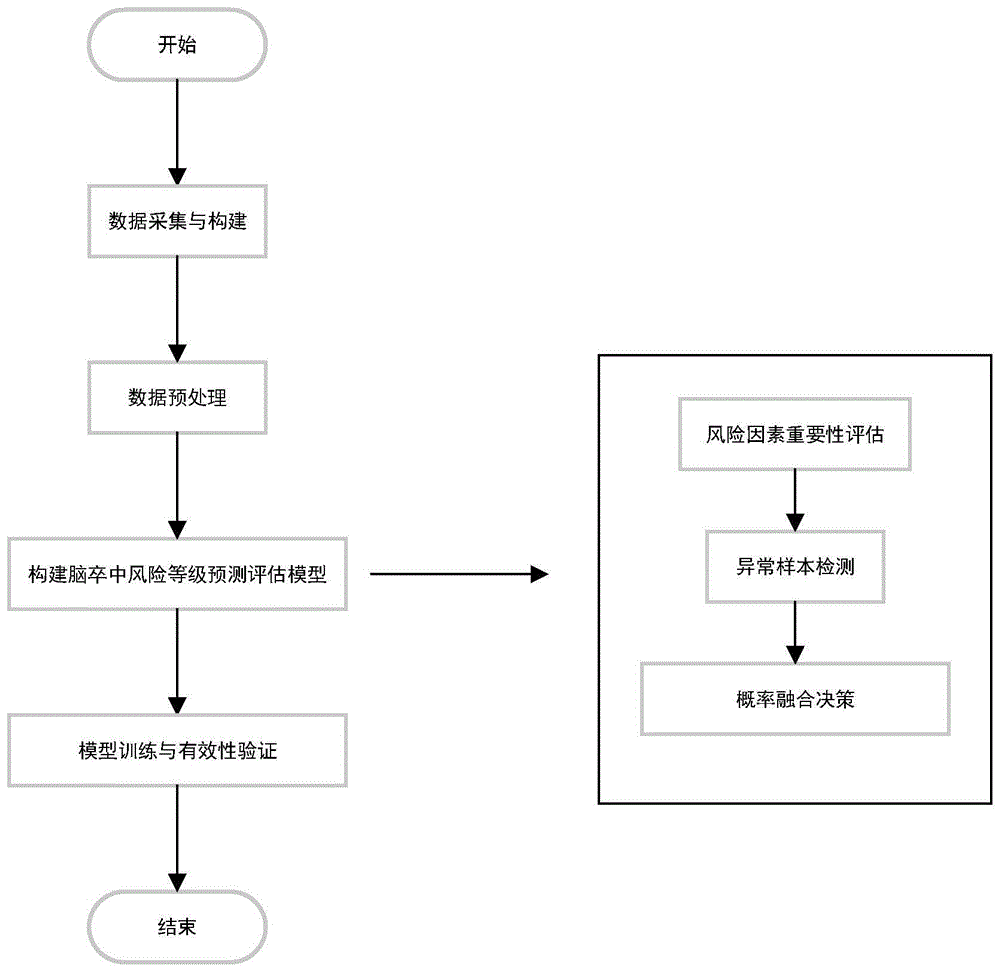
图1为本发明提出的优选的用于脑卒中风险等级预测评估的方法的流程图;
图2为本发明提出的复合特征指标方法评估出的风险因素重要性得分图;
图3为本发明提出的优选的异常样本检测流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于异常样本检测和多维信息输出的脑卒中风险筛查方法,如图1所示,该方法包括:构建筛查对象的脑卒中风险因素数据集,将该数据集输入到训练好的脑卒中风险筛查预测评估模型中,得到风险因素重要性指标和脑卒中风险等级评估结果,并对异常评估结果的数据进行标记;所述脑卒中风险筛查预测评估模型包括风险因素重要性检测评估模型和脑卒中风险等级预测评估模型。
优选的,脑卒中风险因素数据集包括筛查对象人群的人口统计学信息、生理检验指标信息、临床病史信息。
采用脑卒中风险筛查预测评估模型对数据集进行处理的过程包括:
s1:对脑卒中风险因素数据集中的数据进行归一化处理,得到归一化后的脑卒中风险因素数据集;
s2:采用卡方检验和f检验算法分别对归一化后的脑卒中风险因素数据集中各项风险因素进行重要性检验,得到两个重要性检验结果;
s3:为避免单一检测算法的局限性和波动性,构建特征复合得分指标计算方法,通过该方法对s3中计算出的两个检验结果进行优化处理,得出最终的风险因素重要性检测评估结果,
s5:采用isolationforest算法对脑卒中风险数据集进行异常样本检测,去除识别到的异常样本,并对异常样本编号进行标记;
s6:将剔除异常样本后的数据集输入到脑卒中风险等级预测评估模型中进行预测评估,在评估模型中,分别采用经典的randomforest分类预测模型和线性svm分类预测模型计算出两个风险预测评估得分,然后采用概率决策融合方法对上述得到的两个预测评估结果进行优化处理,得出最终的脑卒中风险等级预测评估结果。
数据采集与风险因素数据集的构建是通过从临床患者的电子病历中采集脑中卒筛查数据,然后从中选取20条信息项目构建脑中卒风险因素数据集。信息项目选取时,参考《中国脑卒中防治报告(2020)》以及临床医生的建议,选取的信息中包括筛查对象人群的人口统计学信息、生理检验指标信息、临床病史信息,具体如下表1所示。
表1脑卒中风险因素数据集中选取的信息项目说明
对采集到的数据进行归一化处理,即将数据映射到0~1范围内,确保数据不受量纲的影响。映射方式为:
其中,
构建脑卒中风险筛查预测评估模型包括:
步骤1:进行风险因素重要性评估。对风险数据集数据,分别使用卡方(chi2)检验、f检验两种检验算法计算出各个风险因数的重要性得分,然后采用复合特征指标计算方式得到最终的重要性评分。使用卡方(chi2)检验、f检验两种检验算法计算出各个风险因数的重要性得分的具体过程包括:
步骤11:进行卡方检验的假设定义。设置零假定为χi,0,表示筛查对象风险数据集中第i项风险因素重要性很高;设定备选假定为χi,1,表示筛查对象风险数据集中第i项风险因素重要性不高。
步骤12:使用卡方检验检测出这项风险因素的重要性评分,方法如下:
其中,chi2i,score表示对数据集中第i条风险因素采用卡方检验计算出的重要性评分,值越大表示重要性越高;a表示脑卒中患者中该项风险因素实际发生的频数,t表示预期发生的频数。此处,t值固定设置为脑卒中筛查对象数据集中样本的总个数。
步骤13:进行f检验的假设定义。设置零假定为fi,0,表示筛查对象风险数据集中第i项风险因素重要性不高;设定备选假定为fi,1,表示筛查对象风险数据集中第i项风险因素重要性很高。
步骤14:将筛查数据集中的样本按照风险不同划分为5组:组1(零风险),组2(低危),组3(高危),组4(缺血性脑卒中),组5(出血性脑卒中)。
步骤15:使用f检验检测出这项风险因素的重要性评分,方法如下:
其中,afi,score表示对数据集中第i条风险因素采用f检验计算出的重要性评分,值越大表示重要性越高;
得到的最终的重要性评分中,分值越高的风险因素表面该风险因素对于脑卒中发病风险的影响越大,反之则越小。
其中,scorei表示第i条风险因素的复合重要性评分,chi2i,score表示第i条风险因素采用卡方检验计算出的重要性评分,afi,score表示第i条风险因素采用f检验计算出的重要性评分。
图2是复合特征指标评估出的风险因素重要性得分,设置0.05为是否具有主要影响的判决门限,识别出12条风险因素存在主要影响;12条风险因素包括:年龄、是否缺血性脑卒中、是否出血性脑卒中、是否存在心率不齐、是否运动、是否有吸烟史、是否有家族脑卒中史、bmi、舒张压、收缩压、甘油三脂以及高密度胆固醇。
步骤2:采用isolationforest算法对脑卒中风险数据集进行异常样本检测,去除识别到的异常样本,并对异常样本编号进行标记。脑卒中患者筛查数据中由于医疗设备存在系统误差、采集人员的偶然误差、被采集人员的误报或漏报以及评估指标的主观性较强等因素,导致了在进行数据筛查时产生异常样本,异常样本严重影响最终的脑卒中风险预测评估的准确性。因此,采用isolationforest算法进行异常样本检测和筛除。其中,输入数据是经过步骤2预处理后的风险因素数据集,输出数据是剔除异常样本后的风险因素数据集。操作流程如图3所示:
步骤21:获取经过归一化处理后的风险因素数据集x。
步骤22:设置isolationforest异常样本检测模型的参数,设置的参数包括:将采样样本点设置为256,二叉树个数配置为100,二叉树深度配置为8,输入数据集设置为归一化处理后的风险因素数据集;将归一化处理后的风险因素数据集x输入到isolationforest异常样本检测模型进行异常样本检测,最终检测出异常样本集y。
步骤23:从风险因素数据集中剔除掉检测出的异常样本集y中包含的数据,形成新的风险因素数据集x。
步骤24:判断异常样本集y是否为空,是,则执行步骤2.5,否,则返回到步骤22执行。
步骤25:获得剔除掉异常样本后的风险因素数据集。
经过上述脑卒中异常样本检测后,异常样本被剔除,提升了后续风险预测评估的准确性,并且通过向医疗工作人员提供识别出的异常样本编号,便于后续有针对性的对这部分异常数据人群进行二次筛查,有效提高了筛查的效率。
步骤3:将剔除异常样本后的数据集输入到脑卒中风险等级预测评估模型中进行预测评估,得到两个风险等级预测评估结果;所述脑卒中风险等级预测评估模型采用randomforest算法和线性svm算法分别计算剔除异常样本后的数据集。
步骤31:对经过异常样本筛除后的脑卒中筛查对象数据集进行划分,得到训练集和测试集;其中,训练集中的样本数占总样本数的75%,测试集中的样本数占总样本数的25%。
步骤32:配置randomforest分类预测模型的参数;所述配置的参数包括:特征指标总个数、决策树使用特征的最大数量、决策子树个数、决策树叶子数以及分类结果种类数。
优选的,特征指标总个数为12,即为之前重要性预测步骤中识别出的对脑卒中风险性影响较高的风险因素,包括:年龄、是否缺血性脑卒中、是否出血性脑卒中、是否存在心率不齐、是否运动、是否有吸烟史、是否有家族脑卒中史、bmi、舒张压、收缩压、甘油三脂、高密度胆固醇;决策树使用特征的最大数量为(log212)向上取整=4个;决策子树个数为32;决策树叶子数为50,其余参数选取为默认。
步骤33:将训练集中的数据输入到randomforest分类预测模型训练,将测试集中的数据输入到训练好的randomforest分类预测模型中,得到第一脑卒中风险等级预测评估结果;
步骤34:构建线性svm分类预测模型,对线性svm分类预测模型的参数进行配置;配置的参数包括:核函数选择线性和核函数,输入数据中的属性数以及分类结果数;
优选的,输入数据中的属性数设置为12;输出结果分类个数为5;其余参数选取为默认。
步骤35:将训练集中的数据输入到线性svm分类预测模型进行训练,将测试集中的数据输入到训练好的线性svm分类预测模型中进行分类预测,得到第二脑卒中风险等级预测评估结果。
由于不同地区和国家的筛查数据存在较大差异性,会影响预测的普适准确性。因此,本发明优选的构建了欧式距离较大且余弦相似度较低的两种预测模型:randomforest和svmlinear分别计算出两组脑卒中风险等级预测评估结果。
步骤4:采用概率决策融合方法对两个风险等级预测评估结果进行优化,得到最终的脑卒中风险等级预测评估结果。
采用概率决策融合方法对两个风险等级预测评估结果进行融合优化,增强了对于不同地区、不同是筛查对象下的普适性,进一步提高了最终的预测准确率。具体的概率融合决策采用如下方式:
其中:hj(x)表示对第j个筛查对象的脑卒中风险等级最终预测结果,
在对模型进行训练和有效性验证过程中,利用29340份临床历史电子病历数据(脑卒中历史筛查数据)作为数据集进行测试,其中零风险3996份,低危2988份,高危18252份,缺血性脑卒中1404份,出血性脑卒中2700份,采用随机划分训练集和测试集的方式,其中训练集75%,测试集25%,进行随机训练和测试,平均预测准确率达到99.63%,准确率标准差0.003559。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!