视角和标签双重缺失下的深度不完整多视角多标签分类方法
1.本发明涉及模式识别技术领域,尤其涉及一种视角和标签双重缺失下的深度不完整多视角多标签分类方法。
背景技术:
2.近年来,多视角学习在机器学习和计算机视觉领域都受到了许多关注,在诸如推荐系统、生物特征分析、视频图像标注、疾病诊断等应用场景都有许多成功的应用案例。多视角学习主要通过联合挖掘多个传感器或从多个不同源域采集到的多视角数据信息来得到更好的性能。在多视角多标签分类研究领域,基于潜在语义感知的多视角多标签分类方法(latent semantic aware multi
‑
view multi
‑
label classification)、流形正则多视角多标签分类方法(manifold regularized multi
‑
view multi
‑
label classification)和多视角标签嵌入方法是其中比较具有代表性的方法,这些传统方法的模型普遍假定用于模型训练的多视角数据含有完整的视角和标签信息。然而,在实际应用中,所采集到的多视角数据通常不完整,存在部分标签信息和视角信息缺失的现象。例如,在基于视频图像、文本和音频的多媒体视频数据标注任务中,存在部分视频文件中缺失文本字幕信息或声音的现象;此外,由于视频标注的模糊性和复杂性,很难人为对所有视频都贴上准确的标签信息,导致出现部分视角信息缺失和标签信息缺失的不完整多视角多媒体视频数据。
3.显然,基于视角和标签完备性假设的传统多视角多标签分类模型无法直接处理含有视角缺失或标签信息缺失的数据。近年来,针对视角缺失或标签信息缺失下的多视角学习问题,学者们也进行了一些研究,但是当前研究成果大多仅能处理其中一种信息缺失下的多视角学习问题。例如,多视角嵌入学习(multi
‑
view embedding learning)方法被提出来解决不完整标签信息情形下的学习问题,但是该方法并不能处理视角信息不完整的数据;不完整多视角学习(multi
‑
view learning with incomplete views)针对视角缺失下的多视角学习问题提供了解决方案,但是该方法不能处理不完整标签信息下的多视角数据分类任务。
4.根据调研,目前国内外能够同时处理不完整视角和不完整标签信息下多视角数据的方法还不多见。为了解决不完整视角和不完整标签信息下多视角数据分类难题,不完整多视角弱标签学习(incomplete multi
‑
view weak
‑
label learning,imvwll)设计了一种基于加权矩阵分解的模型,其中一个矩阵分解模型用于得到多个视角间的共享表征,而另一个矩阵分解模型则用于标签预测。该工作是罕见的能够同时解决两种不完整信息下的多视角分类方法,但是该方法存在诸多缺陷,如:1)该方法所得到的模型不能处理新数据;2)该模型扩展性差,不能直接处理含有图像、文本、音频等混合形式的多视角数据;3)该方法特征抽取能力弱、性能差。
技术实现要素:
5.为了解决多视角学习中的视角和标签信息双重缺失难题,并满足实际应用场景中
实时处理新数据和高性能的需求,本发明提供了一种视角和标签双重缺失下的深度不完整多视角多标签分类方法。
6.本发明提供了一种视角和标签双重缺失下的深度不完整多视角多标签分类方法,包括网络模型训练步骤和测试样本标签预测步骤,
7.所述网络模型训练步骤包括:
8.步骤1,数据输入及填充步骤:输入不完整多视角多标签训练数据,将数据和标签矩阵中的缺失值用0值填充;
9.步骤2,数据划分步骤:将填充后的数据和标签矩阵随机划分为个不重复的子集,将第i个子集定义为{y
j
}
j∈ψ(i)
、{w
j
}
j∈ψ(i)
和{g
j
}
j∈ψ(i)
,其中ψ(i)表示第i个子集的数据索引;
10.步骤3,特征编码步骤:将第i个子集数据({y
j
}
j∈ψ(i)
、{w
j
}
j∈ψ(i)
和{g
j
}
j∈ψ(i)
)输入到深度多视角特征提取网络,得到各个视角的鉴别表征,记为
11.步骤4,加权表征融合步骤:将步骤3得到的各视角的鉴别表征输入到加权表征融合模块,通过式得到输入多视角数据的融合表征
12.步骤5:包括多标签分类步骤和多视角深度解码步骤,在所述多标签分类步骤中,将步骤4得到的融合表征输入多标签分类模块,通过式得到输入子集的标签预测概率值{f
j
}
j∈ψ(i)
,其中p和b表示多标签分类模块中线性层的权重参数和偏置参数,sigmoid(
·
)表示多标签分类模块的sigmoid激活函数;在所述多视角深度解码步骤中,将步骤4得到的输入子集的融合表征输入到深度多视角解码网络,得到输入子集对应的重构数据
13.步骤6,网络损失计算步骤:根据多标签分类模块和多视角深度解码模块的输出结果,通过式(4),得到该输入子集对应的网络损失l
ψ(i)
,式(4)的模型损失函数表示为:l=l1+αl2,α为可调节的惩罚项参数,l1为加权多标签分类损失函数,l2为基于视角缺失索引信息的多视角加权重构损失函数;
14.步骤7:根据步骤6得到的网络损失值l
ψ(i)
,利用梯度下降优化算法,优化一次所有网络模型的参数,若i<m,则令i=i+1,并跳转到步骤3继续往下执行;若i=m,则执行步骤8;
15.步骤8,收敛性判断步骤:当迭代步数t>3且时,停止网络模型的训练并输出网络模型参数,否则t=t+1并跳转到步骤2继续执行,其中和分别表示第t步和第t
‑
1步的重构损失;
16.所述测试样本标签预测步骤包括:
17.步骤a,数据输入及填充步骤:输入不完整多视角多标签测试数据,将数据中的缺失视角用0值填充;
18.步骤b,深度特征编码步骤:将填充后的数据输入深度多视角特征编码网络,得到其各个视角的鉴别表征
19.步骤c,加权表征融合步骤:将步骤b的鉴别表征和索引矩阵w∈r
n
×
l
输入加权表征融合模块,根据式得到该测试数据的融合表征
20.步骤d,多标签分类步骤:将融合表征输入多标签分类模块,根据式得到该输入不完整多视角数据的标签预测结果
21.步骤e,识别结果输出步骤:根据多标签分类标签定义规则得到输入数据最终的0
‑
1二值标签矩阵其中f
i
和y
i
分别表示矩阵f和y的第i行向量。
22.作为本发明的进一步改进,在所述步骤6中,第i个输入数据子集对应的损失值为其中n
i
表示子集ψ(i)的样本总数。
23.作为本发明的进一步改进,在所述步骤8中,可根据式求得各迭代步的重构损失。
24.作为本发明的进一步改进,所述深度多视角特征提取网络由多个视角所对应的多层深度特征编码网络组成。
25.作为本发明的进一步改进,所述多层深度特征编码网络的结构可根据输入数据类型灵活设计,包括向量型深度特征编码网络或图像型深度特征提取网络;针对向量型输入数据,所述向量型深度特征编码网络由四个线性层和三个线性整流激活函数组成,若输入向量型视角的特征维度为m
v
,则向量型数据的深度特征编码网络的各线性层维度自适应选取为0.8m
v
、0.8m
v
、1500和d,其中d为期望的数据表征的特征维度;针对图像型输入数据,所述图像型深度特征提取网络由三个卷积层、三个relu激活函数和一个向量转换指令组成,其中三个卷积层的核范数分别设置为5
×
5、3
×
3和3
×
3;对于文本型数据,则将lstm网络模型和线性层进行组合来作为文本型视角的自适应特征编码深度网络。
26.作为本发明的进一步改进,在所述加权表征融合模块中,
27.28.其中为第i个样本各视角的融合特征,w为数据给定的视角缺失索引矩阵,若第i个样本的第v个视角未缺失,则w
i,v
=1,否则w
i,v
=0;视为第i个训练样本第v个视角的编码特征,w
i,v
=0表示第i个样本的第v个视角缺失,且在原始数据中其缺失的视角的每个元素值都用非正常值表示;w
i,v
=1表示其第i个样本的第v个视角未缺失。
29.作为本发明的进一步改进,所述多标签分类模块设计了如下加权多标签分类损失函数:
[0030][0031]
其中g为标签信息索引矩阵,若不确定第i个样本是否含有第j类标签,则g
i,j
=0,否则g
i,j
=1;y为数据集给定的不完整标签信息矩阵,若y
i,j
=1则表明第i个样本含有第j类标签;若y
i,j
=0,则表示第i个样本不含第j类标签;若不确定第i个样本是否含有第j类标签,在原始数据中则定义y
i,j
=nan,nan为非正常值。n和c分别表示输入数据的样本个数和类别数。矩阵f是步骤5和步骤d所述的输入数据经过多标签分类模块的标签预测概率值,f
i,j
表示矩阵f的第i行第j列的元素。
[0032]
作为本发明的进一步改进,所述深度多视角解码网络由l个独立的含有多个网络层的解码网络组成,将各个视角的解码网络设计为该视角深度多视角特征提取网络相反的结构。
[0033]
作为本发明的进一步改进,所述多视角加权重构损失函数:
[0034][0035]
上式中,表示第v个视角对应的深度解码网络所重构的第i个样本的第v个视角的数据,w
i,v
=0表示第i个样本的第v个视角缺失,且原始数据中缺失视角的每个元素值都用非正常值表示;w
i,v
=1表示其第i个样本的第v个视角未缺失。其中l表示输入数据的视角个数。m
v
为输入数据第v个视角的特征维度,n为输入数据样本个数。
[0036]
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的深度不完整多视角多标签分类方法的步骤。
[0037]
本发明的有益效果是:本发明不仅适用于任何不完整/完整多视角多标签分类情形;而且同样适用于半监督分类和全监督分类情形。本发明具有很高的实时性,能够实时在线处理完整/不完整多视角多标签数据的分类任务。
附图说明
[0038]
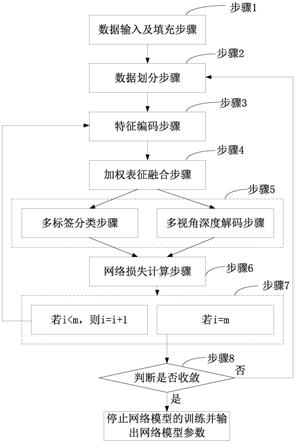
图1是深度双重不完整多视角多标签分类网络的原理图;
[0039]
图2是向量型视角的深度特征编码网络示意图;
[0040]
图3是图像型视角的深度特征编码网络示意图;
[0041]
图4是加权表征融合模块示意图;
[0042]
图5是向量型视角的深度解码网络示意图;
[0043]
图6是图像型视角的深度解码网络示意图;
[0044]
图7(a)是网络模型训练流程图;
[0045]
图7(b)是测试样本标签预测流程图。
具体实施方式
[0046]
为了解决多视角多标签分类领域中存在的视角信息不完整和标签信息不完整等两个挑战性问题,本发明设计了一种更鲁棒、更灵活和更高性能的深度双重不完整多视角多标签分类模型,该模型的结构图如图1所示。本发明所设计的模型主要由四个模块组成:深度多视角特征提取网络、加权表征融合模块、多标签分类模块和深度多视角解码网络。深度多视角特征提取网络能够从复杂的原始多视角数据中挖掘其高阶鉴别特征;加权表征融合模块一方面可融合多视角互补信息,另一方面能够解决视角缺失所造成的不利影响;多标签分类模块可消除缺失标签的不利影响,让模型更充分地利用未缺失标签的监督信息;深度多视角解码网络则用于重构数据,并通过最小化数据重构误差,让模型更充分地利用数据自身的信息。
[0047]
深度多视角特征提取网络:传统多视角多标签分类模型中常用的矩阵分解模型特征抽取能力弱、灵活性不足,不同于传统方法,本发明针对不同的视角设计了深度多视角特征提取网络,该网络能够自适应地提取数据中的高阶鉴别特征。具体地,该网络由多个视角所对应的多层深度特征编码网络组成,每个视角的深度特征编码网络可根据输入数据的类型灵活扩展。以向量型和图像型数据为例,本发明设计了如图2和图3所示的深度特征编码网络。如图2所示,针对向量型视角,本发明的向量型深度特征编码网络主要由四个线性层和三个线性整流(relu)激活函数组成,若输入向量型视角的特征维度为m
v
,则本发明中图2所示的向量型数据的深度特征编码网络的各线性层维度自适应选取为0.8m
v
、0.8m
v
、1500和d,其中d为期望的数据表征的特征维度;针对图像型输入视角,如图3所示,本发明的图像型深度特征提取网络主要由三个卷积层、三个relu激活函数和一个向量转换指令组成,其中三个卷积层的核范数分别设置为5
×
5、3
×
3和3
×
3。对于文本型数据,则将lstm网络模型和线性层进行组合来作为文本型视角的自适应特征编码深度网络。
[0048]
加权表征融合模块:将各个视角深度特征编码网络的输出定义为其中n为训练样本数,l为数据的总视角数,可视为第i个训练样本第v个视角的编码特征,本发明设计了如下基于视角缺失索引信息的加权融合模块来融合多个视角的互补信息并消除缺失视角对模型训练的不利影响:
[0049][0050]
其中为第i个样本各视角的融合特征。w为数据给定的视角缺失索引矩阵,若第i个样本的第v个视角未缺失,则w
i,v
=1;否则w
i,v
=0。
[0051]
加权表征融合模块的具体示意图如图4所示。
[0052]
多标签分类模块:加权分类模块主要由一个线性层和一个sigmoid激活函数组成,
将加权表征融合模块的输出输入到线性层,在经过sigmoid激活函数即可得到该输入样本的标签预测结果。本发明中,线性层的维度为数据的标签总数c,其中为了解决缺失标签信息对模型训练的不利影响,本发明设计了如下加权多标签分类损失函数:
[0053][0054]
其中g为标签信息索引矩阵,若不确定第i个样本是否含有第j类标签,则g
i,j
=0;否则g
i,j
=1。y为数据集给定的不完整标签信息矩阵,若y
i,j
=1则表明第i个样本含有第j类标签;若y
i,j
=0,则表示第i个样本不含第j类标签;需要注意的是,若不确定第i个样本是否含有第j类标签,在原始数据中则定义y
i,j
=nan(非正常值)。n和c分别表示输入数据的样本个数和类别数。矩阵f是步骤5和步骤d所述的输入数据经过多标签分类模块的标签预测概率值,f
i,j
表示矩阵f的第i行第j列的元素。
[0055]
深度多视角解码网络:本发明的深度多视角解码网络主要由l个独立的含有多个网络层的解码网络组成,期望能够在视角和标签信息缺失情形下捕获数据自身更多的信息,以得到更好的特征抽取和分类模型。具体地,为了对输入数据的各个视角进行重构,本发明将各个视角的解码网络设计为该视角深度特征提取网络相反的结构,例如,对于向量型数据,本发明的深度解码网络结构如图5所示,主要由5个线性层和4个relu激活函数组成,其中对于第v个向量型输入视角而言,线性层的维度分别设置为d、1500、0.8m
v
、0.8m
v
和m
v
,其中m
v
为输入数据的第v个视角的特征维度;对于图像型视角数据,其深度解码网络主要由“矩阵转换”模块、三个反卷积层和三个relu激活函数组成,其中“矩阵转换”的目的是将视角融合后的向量型表征转换为与其特征编码网络输出维度一致的矩阵型数据,三个反卷积层的卷积核和数量与其特征编码网络一致,分别为3
×
3、3
×
3和5
×
5。为了消除缺失视角的不利影响,本发明设计了如下基于视角缺失索引信息的多视角加权重构损失函数:
[0056][0057]
上式中,表示第v个视角对应的深度解码网络所重构的第i个样本的第v个视角的数据。视角缺失索引矩阵w的定义如前面加权表征融合模块所述。m
v
为输入数据第v个视角的特征维度,n为输入数据样本数。
[0058]
本发明完整的目标损失函数:如前所述,本发明的深度模型主要包含4个模块,其中涉及分类损失和数据重构损失,因此本发明总的模型损失函数表示为:
[0059]
l=l1+αl2ꢀꢀ
(10)
[0060]
上式中,α为可调节的惩罚项参数。通过联合优化目标损失函数l,即可得到本发明最优的不完整多视角多标签深度分类模型。
[0061]
本发明包括网络模型训练步骤和测试样本标签预测步骤,下面进行具体的说明:
[0062]
为了便于后续阐述,首先给出原始输入数据的符号定义:原始多视角数据用表示,其中含有l个视角和n个样本,n
×
l维的二值矩阵w∈r
n
×
l
记录了视角是否缺失的信息,w
i,v
=0表示第i个样本的第v个视角缺失,且缺失的视角元素的每个元素值
都用“nan(非正常值)”表示;反之w
i,v
=1表示其第i个样本的第v个视角未缺失。对于该数据,其原始标签信息用n
×
c维的二值矩阵y∈r
n
×
c
来表示,同时其标签是否缺失的索引矩阵用n
×
c维的二值矩阵g∈r
n
×
c
表示,当g
i,j
=0时,表示不确定第i个样本是否含有第j类标签,即该标签信息缺失;反之g
i,j
=1,表示数据已明确给定第i个样本的第j类标签信息。对于给定的标签矩阵,若y
i,j
=1,则认为第i个样本含有第j类标签,y
i,j
=0则视为第i个样本不含第j类标签;若第i个样本的第j类标签信息缺失,则原始数据中y
i,j
=nan。w
i
、y
i
和g
i
分别表示矩阵w、y和g的第i行向量数据。
[0063]
如图7(a)所示,网络模型训练步骤包括:
[0064]
步骤1,数据输入及填充步骤:输入不完整多视角多标签训练数据,将数据和标签矩阵中的缺失值用0值填充。并定义模型训练初始迭代步数t=1。
[0065]
步骤2,数据划分步骤:将填充后的数据和标签矩阵随机划分为个不重复的子集,其中表示向上取整。便于后续阐述,将第i个子集定义为{y
j
}
j∈ψ(i)
、{w
j
}
j∈ψ(i)
和{g
j
}
j∈ψ(i)
,其中ψ(i)表示第i个子集的数据索引。
[0066]
步骤3,特征编码步骤:令i=0,将上述第i个子集数据({y
j
}
j∈ψ(i)
、{w
j
}
j∈ψ(i)
和{g
j
}
j∈ψ(i)
)输入到前面所述的深度多视角特征提取网络,得到各个视角的鉴别表征,记为
[0067]
步骤4,加权表征融合步骤:将上一步得到的各视角的表征输入到加权表征融合模块,通过式得到输入多视角数据的融合表征
[0068]
步骤5:包括多标签分类步骤和多视角深度解码步骤,在所述多标签分类步骤中,将步骤4得到的融合表征输入多标签分类模块,通过式得到输入子集的标签预测概率值{f
j
}
j∈ψ(i)
,其中p和b表示多标签分类模块中线性层的权重参数和偏置参数,sigmoid(
·
)表示多标签分类模块的sigmoid激活函数。
[0069]
在所述多视角深度解码步骤中,将步骤4得到的输入子集的融合表征输入到本发明中的深度多视角解码网络,得到输入子集对应的重构数据
[0070]
步骤6,网络损失计算步骤:根据多标签分类模块和多视角深度解码模块的输出结果,通过式(4),得到该输入子集对应的网络损失l
ψ(i)
,具体为其中n
i
表示子集ψ(i)的样本总数。
[0071]
步骤7:根据步骤6得到的网络损失值l
ψ(i)
,利用梯度下降优化算法,优化一次所有网络模型的参数,若i<m,则令i=i+1,并跳转到步骤3继续往下执行;若i=m,则执行步骤8。
[0072]
步骤8,收敛性判断步骤:当迭代步数t>3且时,停止网络模型的训练并输出网络模型参数;否则t=t+1并跳转到步骤2继续执行。其中和分别表示第t步和第t
‑
1步的重构损失,可根据式求得各迭代步的重构损失。
[0073]
所述测试样本标签预测步骤包括:
[0074]
便于后面阐述,定义与训练数据具有相同数据类型的不完整多视角测试数据表示为w∈r
n
×
l
表示其视角是否缺失的索引矩阵。具体的测试过程表述如下:
[0075]
步骤a,数据输入及填充步骤:输入不完整多视角多标签测试数据,将数据中的缺失视角用0值填充。
[0076]
步骤b,深度特征编码步骤:将填充后的数据输入深度多视角特征编码网络,得到其各个视角的鉴别表征该步骤中的多视角深度特征编码网络参数为本发明网络模型训练步骤中所述训练好的模型参数。
[0077]
步骤c,加权表征融合步骤:将步骤b的鉴别表征和索引矩阵w∈r
n
×
l
输入加权表征融合模块,根据式得到该测试数据的融合表征
[0078]
步骤d,多标签分类步骤:将融合表征输入多标签分类模块,根据式得到该输入不完整多视角数据的标签预测结果在该步骤中,网络参数p和b均为网络模型训练步骤中经过训练后的模型参数。
[0079]
步骤e,识别结果输出步骤:根据多标签分类标签定义规则得到输入数据最终的0
‑
1二值标签矩阵其中f
i
和y
i
分别表示矩阵f和y的第i行向量。
[0080]
视角缺失和标签缺失是多视角多标签分类场景的两个挑战性问题。过去几年,学者们对这两个挑战性问题进行了大量研究,但是这些方法普遍只适用于其中一种信息缺失下的多视角学习问题。在本发明中,我们提出了一种新颖的深度双重不完整多视角多标签分类方法,该方法能够同时解决视角缺失和标签缺失下的多视角多标签分类问题。该方法主要由四大结构组成:深度多视角特征提取网络、加权表征融合模块、多标签分类模块和深度多视角解码网络。通过分别将视角缺失信息和标签缺失信息引入加权表征融合模块和多标签分类模块,该方法能够有效地利用未缺失视角和标签信息来训练模型,进而消除视角缺失和标签缺失对模型训练的不利影响。在五个公开数据集上的实验验证了本方法能够大幅度地提升部分视角和标签双重缺失下的不完整多视角多标签分类性能。
[0081]
本发明是一种利用深度学习技术、数字图象处理技术、模式识别理论等实现多视
角数据自适应分类的方法,该方法能够应用在诸如人脸识别、车辆识别等安防场景,也能灵活应用在疾病诊断、图像检索、推荐系统分析、金融分析和多媒体分析等领域。
[0082]
在应用方面,这里不介绍训练数据的获取,默认已搜集到应用场景大量的训练数据。以基于人脸、舌苔、呼出的气味、脉搏信号等多模态信息疾病诊断为例:假设已经采集到大量用户的人脸、舌苔、气味、脉搏等部分信息数据和其对应的诸如糖尿病、脂肪肝、甲亢、胃癌等多种疾病诊断标签数据,这些多模态数据可以是完整,也可是不完整的数据,将采集到的数据输入到本发明图7(a)所示的训练方案中,训练该类疾病诊断的分类模型;当模型训练好后,即可将训练好的分类模型部署在个人电脑或嵌入到下位机中按照图7(b)所示的测试步骤对采集到的用户数据进行实时分类,并报告疾病诊断结果。
[0083]
图像中一般含有多种目标信息,如一张图像含有猫、狗、草等多种类型目标,同时可能含有文本解释信息。在图像检索场景可通过搜集带有标记信息的文本和图像等两种模态信息的训练数据,然后以此作为图7(a)的训练数据来训练用于图像检索的多模态多标签分类模型;模型训练好后,即可根据此模型来进行图像的检索。图像检索可通过输入文本信息检索、也可以通过输入相似图片检索。
[0084]
同理,在多视角人脸识别、车辆识别、推荐系统分析、金融分析和音视频多媒体分析领域,只需要提前采集到的相关场景的一定规模的数据并人工贴上一定数量的标签信息,即可利用图7(a)来训练相关场景的多视角多标签分类模型,然后利用图7(b),根据实时采集的数据和训练好的模型得到实时的分类结果。
[0085]
本发明的有益效果如下:
[0086]
1)本发明是第一个能够同时解决不完整视角和不完整标签信息问题的多视角多标签深度分类网络。本深度网络不仅适用于任何不完整/完整多视角多标签分类情形;而且同样适用于半监督分类和全监督分类情形。
[0087]
2)本发明具有很高的实时性,能够实时在线处理完整/不完整多视角多标签数据的分类任务。
[0088]
3)在5个不完整多视角多标签数据集上的实验表明了本发明获得了最优性能。
[0089]
表格1在视角缺失率为50%、标签缺失率为50%、训练样本率为70%时的五个数据集上所得到的平均精度(average precision,ap)。其中imvwll是目前国内外唯一适用于不完整多视角多标签分类任务的方法。
[0090]
数据集imvwll本发明corel 5k0.3130.363voc20070.4550.508esp game0.2360.264iapr tc
‑
120.2340.299mir flickr0.4970.597
[0091]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1