一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法
本发明涉及计算机视觉图像处理领域,特别涉及一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法。
背景技术:
目标检测和人体行为识别技术是现今计算机视觉领域的热点。人体行为识别的目标是从一个未知的视频或者是图像序列中自动分析其中正在进行的行为。本方法运用到了许多新兴的技术。可以对违规行为起到一个预测的作用。可以及时遏止违规事件的发生,也可以对违规事件起到即使报警的作用。为了更好的预测人体违规行为的发生,人体行为识别技术是必然需要时用到的技术。但是,受光照条件各异,视角多样性,背景复杂,类内变化大,人群聚集等诸多不可控因素的影响,人体行为识别是一项十分具有挑战性的任务。为了解决以上诸多问题,研究人员也是提出了各式各样的处理方法。rnn网络虽然可以处理时间序列数据,但是无法解决梯度消失的问题,因此无法处理时间序列较长的数据。
lstm是rnn改进以后的循环神经网络。它是在rnn结构的基础上,加上了一个神经元和三个门结构,来控制时间序列上的记忆信息。这三个门分别是,遗忘门,输入门和输出门。每次信息都需要经过这三个门,经过一定的处理以后,细胞会选择性记忆,控制遗忘程度。通过这种方式,可以很好的弥补rnn遗留下来的缺点,可以有效地被应用于中长期序列数据。
隐马尔可夫模型(hiddenmaikovmodel,简称hmm)是结构最简单的动态贝叶斯网,这是一种著名的有向图模型,主要用于时序数据建模,在语音识别、自然语言处理等领域有广泛应用。利用此模型解决具有马尔可夫性的时间序列数据,可以大大减少演算求解过程。本发明将隐马尔可夫模型应用于修正违规行为的预测结果。
技术实现要素:
本发明的目的是为了更好的对人体违规行为做出预测,本发明提供了一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法,在使用lstm循环神经网络的同时,结合隐马尔可夫模型来修正,提高了预测的准确性。
本发明解决的技术方案如下:
一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法,包括以下步骤:
1)数据采集:获取不同违规行为的视频数据并进行切片,将连续的视频数据转换为连续的图像,标记每一组连续图像所属的违规行为;
2)对图像进行预处理;
3)对预处理后的图像进行目标检测,得到目标检测框;
4)将带有目标检测框的图像作为cpn网络的输入,提取目标检测框中的人体骨架,标记关节点,得到带有目标检测框和关节点标记信息的图像;将每组中带有目标检测框和关节点标记信息的图像均转换为像素矩阵;
5)将步骤4)得到的每一组像素矩阵作为一个样本,构成样本训练集;利用样本训练集对lstm模型进行训练,得到该样本属于每一项违规行为的概率,构成概率矩阵;
6)利用隐马尔可夫模型对概率矩阵进行修正,取修正后的概率矩阵中最大概率值对应的违规行为作为最终的预测结果,根据预测结果和真实结果对隐马尔可夫模型进行训练;
7)获取待预测的视频数据,通过步骤1)至4),将待预测的视频数据转换为待处理的像素矩阵,利用训练好的lstm模型得到初始概率矩阵,再经训练好的隐马尔可夫模型对初始概率矩阵进行修正,取修正后的概率矩阵中最大概率值对应的违规行为作为最终的预测结果。
进一步的,步骤2)所述的预处理方法为滤波方法,以图片上的像素点为中心取正方形区域,将区域中每个像素点的灰度值进行排序,取排序的中间值作为中心像素灰度的新值,以滑窗的方式遍历图像。
进一步的,步骤3)中的目标检测过程包括:
将一组内的连续图像依次进行尺寸调整并提取特征,获得特征图;
将特征图进行一次卷积,集中特征信息,之后分为两个支路:第一支路中,先经过rpn_data层,区分出人和背景,输出标记为人的候选框;第二支路中,计算候选框的偏移量并输出;
对候选框进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框;将剩余的候选框和特征图输入roipooling层,将候选框映射到特征图上,再经过全连接层后输出。
进一步的,输入lstm模型中的数据为按时间序列排序的像素矩阵a=(a1,a2,a3,a4,…,an),其中ai表示该组中的第i个图像对应的像素矩阵。
进一步的,所述的隐马尔可夫模型的建立过程为:
6.1)确定隐含状态集为s={s1,s2,...,sn},观测状态集为o={o1,o2,...,on},n为违规行为的类型数量;
6.2)确定状态转移概率矩阵a=[aij]n*n,且当前时刻的状态只与上一时刻的状态有关,即:
aij=p(yt+1=sj|yt=si)
其中,yt表示t时刻的状态,yt=si表示t时刻的状态为si,yt+1=sj表示t+1时刻的状态为sj;p(yt+1=sj|yt=si)表示当t时刻的状态为si时,那么t+1时刻的状态为sj的概率值;aij为观测概率矩阵a中第i行第j列的元素,即在t-1时刻时,模型的状态为si,在t时刻时,模型的状态转移到sj;
6.3)确定观测概率矩阵b=[bij]n*n:
bij=p(xt=oj|yt=si)
其中,oj表示第j个观测值,xt表示t时刻的观测值,xt=oj表示t时刻的观测值为oj;p(xt=oj|yt=si)表示当t时刻的状态为si时,那么t时刻的观测值为oj的概率值;bij为观测概率矩阵b中第i行第j列的元素,即在状态si的条件下出现观测值oj的概率值;
6.5)将lstm模型输出的概率矩阵作为初始状态概率分布π(π1,π2,…,πn):
πi=p(y=si)
其中,πi表示属于状态si的概率。
进一步的,在步骤4)和步骤5)之间还包括将像素矩阵进行特征提取和降维的步骤,具体为:将步骤4)得到的像素矩阵输入卷积层进行特征提取,再进入池化层进行降维;降维后的像素矩阵作为lstm模型的输入。
本发明有益效果:
本发明提供了一种基于隐马尔可夫模型和循环神经网络人体行为违规的预测方法,根据不同的场景设置不同的违规行为,在特定场景中采取数据集后训练网络模型对其进行预测,再结合隐马尔可夫模型对其进行误差修正,能够正确判断并及时制止违规行为的发生,达到了及时报警,警示的作用。
附图说明
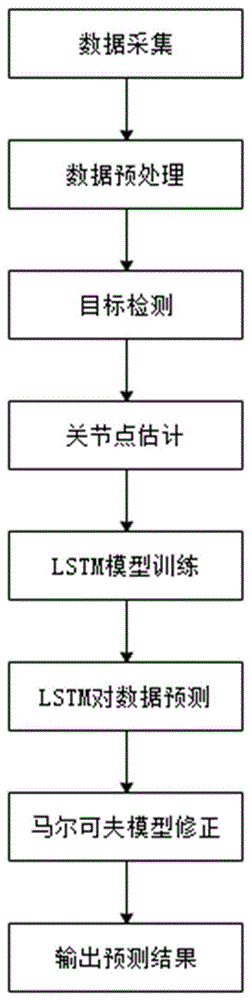
图1是预测方法的基本流程图;
图2是cpn对人体关节点估计的简要流程;
图3是lstm模型各类参数的设置与调节;
图4是lstm模型训练的流程图;
图5是隐马尔可夫模型的图结构;
具体实施方式
下面结合附图以及具体实施对本发明一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法做进一步详细说明。
如图1所示,本发明的一种基于隐马尔可夫模型和循环神经网络的人体违规行为预测方法,包括以下步骤:
s1:数据采集:获取不同违规行为的视频数据并进行切片,将连续的视频数据转换为连续的图像,标记每一组连续图像所属的违规行为。本实施例中,根据监控系统对时间序列数据进行采集,在模型训练过程中,部分数据来自inriaxmax多视角视频库,并按特定需求筛选出特征明显的。
为了更好的进行后续操作,在对得到的数据进行切片操作时,隔一定的时间对视频数据进行图像截取,将视频数据变为连续的图像。
s2:为了提高训练的效率以及训练完成后模型的精度,要对截取好的图像数据进行预处理。
采用中值滤波,是一种非线性方法。中值滤波在过滤脉冲噪声方面有比较好的效果,它选择适当的点来代替污染点的值。首先确定一个以某个像素为中心的领域,这里取正方形领域,然后将领域中个像素的灰度值排序,取其中间值作为中心像素灰度的新值。以滑窗的方式移动这个正方形区域,完成所有遍历后,得到更清晰的,损失较小的图片。
s3:对预处理后的图像进行目标检测,得到目标检测框:
采用基于faster-rcnn网络进行目标检测,主要包含四个层结构。第一层是convlayers,用卷积池化的方法来提取特征图。第二层是一个rpn(regionproposalnetwork),用来获取精确的候选框。第三层是roipooling,用于提取候选框特征图,送入全连接层判定目标。第四层是分类层,利用候选框特征图计算候选框的类别,同时获得候选框的精确位置。
实施中,将一组内的连续图像依次进行尺寸调整并提取特征,获得特征图;
将特征图进行一次卷积,集中特征信息,之后分为两个支路:第一支路中,先经过rpn_data层,区分出人和背景,输出标记为人的候选框;第二支路中,计算候选框的偏移量并输出;
对候选框进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框;将剩余的候选框和特征图输入roipooling层,将候选框映射到特征图上,再经过全连接层后输出。
本实施例以图5为例进行说明:
s3.1:先将图片经过convlayers层用于特征提取。此层包含了13个conv(卷积)层,每个conv层的kernel_size=3,pad=1,stride=1,根据图片大小公式:
可知,经过卷积的图片并不会改变原图大小;接着链接13个relu层,经过一层relu图像数目会增加一倍,4个pooling(池化)层,且kernel_size=2,stride=2,因此,图片大小会变为原来的1/2。图片依次经过卷积,激活,卷积,激活,池化,后得到特征图,大小为(m/16)*(n/16)*512。
s3.2:featuremap进入rpn后,先经过一次3*3的卷积,同样特征图大小依然是m*n,数量512,这样做的目的应该是进一步集中特征信息,接着为两个全卷积,即kernel_size=1*1,pad=0,stride=1。
s3.3:卷积后分为两条支路。上面一条分路为首先经过rpn_data层,逐像素对其9个anchorbox进行二分类,分出是人还是背景。
anchor是分别对卷积后每一张图片的每一个小框进行不同长宽比所截取的图片。在生成anchor时,先定义一个大小为16*16的box,之所以取16*16是因为特征图上的一个点可以对应到原图上一个16*16大小的区域。以16*16大小的box为基础,划分出三个边长分别为8,16和32的正方形缩放图,对每个正方形截取三个长宽比分别为0.5,1,2的anchor,所以一共生成了m*n*9个anchorbox。
进一步,在此层还会对剩下的anchorbox进行过滤和标记,规则如下:
①过滤掉超过原图大小的anchorbox;
②如果anchorbox与groundtruth的iou值最大,标记为正样本,label=1;
③如果anchorbox与groundtruth的iou>0.7,标记为正样本,label=1;
④如果anchorbox与groundtruth的iou<0.3,标记为负样本,label=0;
计算iou的公式如下:
iou=(a∩b)/(a∪b)
其中,正样本表示有目标存在,负样本表示无目标存在,剩下的既不是正样本也不是负样本,不用参加训练,label=-1。
除了对anchorbox进行标记外,另外就是计算anchorbox与groundtruth之间的偏移量。令:groundtruth:标定的框(真实框)中心点位置坐标x*、y*和宽高w*、h*,anchorbox:中心点位置坐标x_a、y_a和宽高w_a、h_a。
则:
δx=(x*-x_a)/w_a
δy=(y*-y_a)/h_a
δw=log(w*/w_a)
δh=log(h*/h_a)
通过groundtruthbox与预测的anchorbox之间的差异来进行学习,从而使得rpn网络中的权重能够学习到预测box的能力。
s3.4:在以下几层中,其中rpn_loss_cls是使用交叉熵(binarycrossentropy)函数来计算分类损失;rpn_loss_bbox是使用smoothl1loss函数来计算回归损失;rpn_cls_prob时使用softmax函数计算概率值。在rpn_data中已经为预测框anchorbox进行了标记,作为rpn上面一条支路网络的输入;并且计算出anchorbox与gt_boxes之间的偏移量,作为rpn下面一条支路网络的输入。再利用rpn网络进行训练。而使用两层rpn_cls_score_reshape是因为softmax中他的输入输出的形状是规定的,需要换化为一定的形状,分类完之后再将其输出结果也变为需要的形状。最后再将分类出来是目标的数据放入候选框(proposal)当中。
s3.5:rpn_bbox_pred中记录着训练好的四个回归位置偏移值△x,△y,△w,△h,然后利用预测的四个位置偏移量修正anchors的位置信息得到的较精确的预测框。进一步对这些预测框进行越界剔除和使用nms非最大值抑制,剔除掉重叠的框。先设定nms的iou阈值为0.7,即仅保留覆盖率不超过0.7的局部最大分数的anchorboxes。最后留下大约m个anchor,然后再按照rpn_cls_prob的值从大到小取前n个anchorboxes;最终进入到下一层roipooling时regionproposal大约只有n个。
s3.6:将rpn产生的regionproposal和之前产生的特征图输入到roipooling层当中遍历每个regionproposal,将其坐标值缩小16倍,这样就可以将在原图基础上产生的regionproposal映射到m*n的特征图上,从而将在featuremap上确定一个区域,也即是该regionproposal对应的特征图,并作为下一层的全连接输入。
s3.7:通过fullconnect层与softmax计算每个regionproposal具体属于哪个类别,输出cls_prob概率向量;同时再次利用boundingboxregression获得每个regionproposal的位置偏移量bbox_pred,用于回归获得更加精确的目标检测框。
结束目标检测后,将带目标检测框的图片作为cpn网络的输入,进行关节点估计。
s4:将带有目标检测框的图像作为cpn网络的输入,提取目标检测框中的人体骨架,标记关节点,得到带有目标检测框和关节点标记信息的图像;将每组中带有目标检测框和关节点标记信息的图像均转换为像素矩阵。
如图2所示,在golbalnet阶段,它负责图像中的所有关节点的检测,对比较容易检测的眼睛,胳膊等部位的关节点预测效果较好。另一方面可以提供充足的语境信息,这对于推断遮挡和不可见的关节点来说是很重要的。根据图可知,当前图片人体的耳朵,左右手肘等关节点可以简单测预测,在本阶段,主要负责检测这些易观察的关节点。并且对不易观察的关节点,对其周围像素信息进行处理预测。
在refinenet阶段,它负责对golbalnet预测的结果进行修正。golbalnet对身体部位的那些遮挡、看不见或者有复杂背景的关节点预测误差较大,refinenet则专门修正这些点。
整合以上两步骤,放入原图中,得到已经进行关节点估计的图片。
s5:将步骤s4得到的每一组像素矩阵作为一个样本,构成样本训练集;利用样本训练集对lstm模型进行训练,得到该样本属于每一项违规行为的概率,构成概率矩阵;
为了较好的避免梯度消失的问题,这里选取lstm作为网络模型。采用反向传播算法对lstm网络模型进行训练,得到训练集中人体状态与时间之间的特征联系,获取lstm网络的几个权重和偏置;
结合图3和图4,lstm模型训练的具体流程为:
先确定lstm模型的函数以及参数,具体的激活函数为sigmoid和tanh两个函数。为了防止过拟合,应确定一个dropout的值,这里为0.2,损失函数使用的是预测值与真实值的方差。1000个数据集,将batchsize设置为200,则epoch为5。
训练时,先将数据输入卷积层,进行特征提取,在进入池化层进行降维。这里要看具体实例,可以有多个卷积层和池化层,滑窗的大小也根据实例有所不同。经过一个dropout以后,进入lstm网络。经过几个神经元的处理后再次经过一个dropout,在进行回归,结果为各个行为可能发生的一个概率矩阵。在迭代次数未满的前提下,再计算lossfunction更新权重与偏置。重复以上过程,直到迭代次数满。
s6:利用隐马尔可夫模型对概率矩阵进行修正,取修正后的概率矩阵中最大概率值对应的违规行为作为最终的预测结果,根据预测结果和真实结果对隐马尔可夫模型进行训练。
具体为:确定隐含状态集为s={s1,s2,...,sn},观测状态集为o={o1,o2,...,on},n为违规行为的类型数量;
确定状态转移概率矩阵a=[aij]n*n,且当前时刻的状态只与上一时刻的状态有关,即:
aij=p(yt+1=sj|yt=si)
其中,yt表示t时刻的状态,yt=si表示t时刻的状态为si,yt+1=sj表示t+1时刻的状态为sj;p(yt+1=sj|yt=si)表示当t时刻的状态为si时,那么t+1时刻的状态为sj的概率值;aij为观测概率矩阵a中第i行第j列的元素,即在t-1时刻时,模型的状态为si,在t时刻时,模型的状态转移到sj;
确定观测概率矩阵b=[bij]n*n:
bij=p(xt=oj|yt=si)
其中,oj表示第j个观测值,xt表示t时刻的观测值,xt=oj表示t时刻的观测值为oj;p(xt=oj|yt=si)表示当t时刻的状态为si时,那么t时刻的观测值为oj的概率值;bij为观测概率矩阵b中第i行第j列的元素,即在状态si的条件下出现观测值oj的概率值;
将lstm模型输出的概率矩阵作为初始状态概率分布π(π1,π2,…,πn):
πi=p(y=si)
其中,πi表示属于状态si的概率。
在实际应用中,获取待预测的视频数据,通过s1至s4,将待预测的视频数据转换为待处理的像素矩阵,利用训练好的lstm模型得到初始概率矩阵,再经训练好的隐马尔可夫模型对初始概率矩阵进行修正,取修正后的概率矩阵中最大概率值对应的违规行为作为最终的预测结果。
- 还没有人留言评论。精彩留言会获得点赞!