一种可重叠的社群发现方法
本发明涉及图数据分析
技术领域:
,尤其是涉及一种可重叠的社群发现方法。
背景技术:
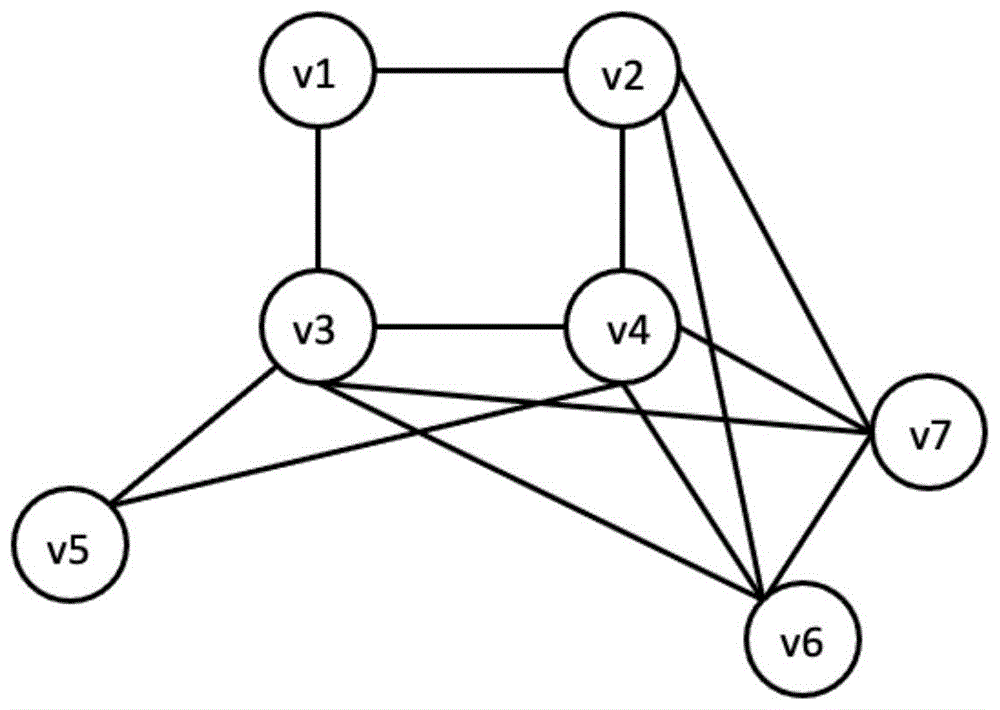
:在真实世界中,图被广泛用于表示实体以及实体之间的关系。而真实世界中的图通常由稠密子图构成,即图中一小部分顶点具有紧密的联系。从图中挖掘稠密子图是一个非常基础的问题,在图数据库和数据挖掘领域已经得到的广泛的研究,并且针对社群也有若干种不同的定义。派系过滤在社交网络中寻找紧密联系的群体中有重要应用。在社交网络中,寻找紧密联系的社群有着非常重要的意义,可以用于智能推荐,广告推送以及金融系统中的风风险控制。派系是一种基于团的结构,但是它对子图联系程度的要求比团更低,这有助于在图中发现更大的社区。现有技术多为单机单线程的方法,这些方法虽然效率高,但是可扩展性低。在实际使用中,提升计算机的单核心性能成本高,且提升不明显。由于互联网工业的发展,现实世界中的图数据无法使用单机进行处理。而现有的分布式算法基于mapreduce(一种用于大规模数据集的并行运算的编程模型)。然而,mapreduce的性质决定它更适和批处理计算,而不适应图算法中出现的大量迭代计算,故效率较低。技术实现要素:本发明的目的是提供一种可重叠的社群发现方法,增加了系统对大图的处理能力,横向扩展更加容易且成本更低。为实现上述目的,本发明提供了一种可重叠的社群发现方法,步骤如下:s1、分布式计算图g中的所有极大团,统计极大团的数量信息并将极大团的数量信息发送到所有计算节点中,按照极大团编号顺序决定极大团的顺序;s2、对所有的极大团按照数组排序的规则进行排序,按照排序结果,对所有的极大团进行编码,给每个极大团分配全局唯一编码,按照该编码顺序确定极大团;s3、计算极大团中的子团,每个极大团的子团跟对应的极大团具有相同的编号,将计算出的极大团的子团按照子团的最小顶点将子团发送到不同的计算节点中;s4、在每个计算节点内,构建反向索引;s5、对每个极大团,利用反向索引,计算与每个极大团与其同一个计算节点内有k-1个共享顶点的极大团,利用共查集将这些极大团的id保存在同一个集合中;s6、合并不同集群中的并查集,求出相应的派系。优选的,在步骤s1中,将每个极大团的最小顶点id作为极大团的类别,统计所有极大团的类别和数量,将所有极大团从0开始连续编号,按照极大团中最小顶点的大小将所有的极大团连续、平均分配到所有计算节点中。优选的,在步骤s3中,计算极大团中的子团步骤为,对所有极大团q,q的大小为|q|,对k=1到|q|-k,将q[k:|q-1|]分配给q[k]所在的节点,若q[k-1]和q[k]属于同一个计算节点,则可以跳过该分配,每个极大团的子团跟对应的极大团具有相同的编号,在分发时,连同其对应极大团的编号。优选的,步骤s4具体为,顶点到包含该顶点且存在于该计算节点的极大团或部分极大团的id。优选的,在步骤s5中,若其中有极大团已经属于其他集合,则将本集合与其他集合合并,数据结构可以由并查集维护。因此,本发明采用上述的一种可重叠的社群发现方法,具有以下有益效果:(1)、算法的分布式特性避免了串行算法中单核心性能瓶颈,使得算法可以更加容易的进行横向扩展,在实际生产中,增加了系统对大图的处理能力。(2)与纵向扩展相比,横向扩展更加容易且成本更低,符合实际生产的要求。下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。附图说明图1为本发明原图结构示意图;图2为本发明节点中团的分布结构示意图。具体实施方式实施例一种可重叠的社群发现方法,步骤如下:s1、图1为本发明原图结构示意图,如图1所示,计算出图g中的所有极大团,对图中的每个极大团按照顶点编号大小排序,将每个极大团的最小顶点id作为极大团的类别,分布式统计所有极大团的编号,按照极大团编号顺序决定极大团的顺序,并将所有信息发送到计算节点中。求得的极大团如下表:编号极大团中的顶点子团01,2,3,4(2,3,4),(3,4)13,4,5╲22,3,4,6,7(3,4,6,7),(4,6,7),(6,7)统计所有极大团的类别和数量,将所有极大团从0开始连续编号,按照极大团中最小顶点的大小将所有的极大团连续、平均分配到所有计算节点中。s2、对所有的极大团按照数组排序的规则进行排序,按照排序结果,对所有的极大团进行编码,给每个极大团分配全局唯一编码,按照该编码顺序确定极大团。s3、计算极大团中的子团,对所有极大团q,q的大小为|q|,对k=1到|q|-k,将q[k:|q-1|]分配给q[k]所在的节点,若q[k-1]和q[k]属于同一个计算节点,则可以跳过该分配,每个极大团的子团跟对应的极大团具有相同的编号。每个极大团的子团跟对应的极大团具有相同的编号,将计算出的极大团的子团按照子团的最小顶点将子团发送到不同的计算节点中。在分发时,连同其对应极大团的编号。s4、在每个计算节点内,构建反向索引,顶点到包含该顶点且存在于该计算节点的极大团或部分极大团的id。s5、对每个极大团,利用反向索引,计算与每个极大团与其同一个计算节点内有k-1个共享顶点的极大团,利用共查集将这些极大团的id保存在同一个集合中;若其中有极大团已经属于其他集合,则将本集合与其他集合合并,数据结构可以由并查集维护。s6、合并不同集群中的并查集,求出相应的派系。算法输出的结果为一系列的社群,每个社群为联系紧密的顶点的集合。这些顶点代表的个体通常具有某些相似的性质,这些相似的性质可用于智能推送,广告推荐以及金融行业中的风险控制。本发明实现了一种可重叠的社群发现方法,该方法可以在多台计算上同时运行,克服了单台计算机的算力瓶颈。同时增加计算机的数量比增加单台计算机的计算性能更加符合经济效益。本发明可以用于社交网络等图数据中的数据挖掘。在一个特定的社群中,成员有很大概率分享某些特性,故可以用于智能推荐以及广告的精准推送,增加用户的点击率以及广告的盈利。社群中的成员练习较为紧密,可以用于金融系统中的风险控制,降低金融服务中的风险。因此,本发明采用上述的一种可重叠的社群发现方法,增加了系统对大图的处理能力,横向扩展更加容易且成本更低。最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1