一种针对社区问答平台的答者推荐方法
本发明属于推荐技术领域,具体属于一种针对社区问答平台的回答者推荐方法。
背景技术:
传统的推荐方法有协同过滤、基于内容的推荐、基于关联规则的推荐,这些方法都有各自的优缺点,比如协调过滤的优点是:能够有效的使用其他相似用户的反馈信息,较少用户的反馈量,加快个性化学习的速度;能够过滤难以进行机器自动内容分析的信息;缺点是:数据稀疏性问题和可扩展性问题。基于内容的推荐的优点是:没有冷启动、新项目和数据稀疏问题;能为具有特殊兴趣爱好的用户进行推荐;缺点是:所推荐的内容必须能抽象出有意义的特征,并且具有良好的结构性。
技术实现要素:
本发明旨在解决以上出现的技术问题,提出一种针对社区问答平台的回答者推荐方法。
一般社区问答平台中回答某一话题帖子比较多的用户也有回答相似帖子的倾向,所以首先可以根据问题帖子的相似程度,对问题帖子进行划分。问题帖子除了显示标记的标签信息可以用来分类,其标题中的文本信息也可以用来进行相似度的计算。根据问题帖子中包含的标签和标题,计算jaccard相似度。
jaccard相似度:
jaccard(a,b)=|a∩b|÷|aub|
其中a是原有问题中的标题集合,b是新问题中的标题集合。
接下来,对于问题帖子的文本内容,运用一个结合文本词汇频率(termfrequency)和逆文本频率(inversedocumentfrequency)的混合模型,使用文本体上的余弦相似度测量方法计算帖子文本内容的余弦相似度。tf-idf是一个数值统计,旨在反映一个词在一个集合或语料库中对文档的重要程度,并作为给定用户查询的文档相关性打分和排名的核心工具。帖子数据中的内容文本都是对问题或回答的文字描述,文字内容越相近说明这两个帖子越相似。
tf-idf:
tf-idf(t,d,d)=tf(t,d)×idf(t,d)
其中n:语料库中的文档总数,n=|d||{d∈d,t∈d}|,术语t出现的文档数。d表示文档,d表示文档中的一项,t表示一个文档中的一条术语。
余弦相似度:
其中ai和bi分别是向量a和b的分量。
进一步的,根据jaccard相似度和tf-idf余弦相似度对提问帖子进行划分后,根据问题所在的分类,在这个分类中查找对应的回答,再找到这些回答对应的用户,这些用户都是潜在的相似新问题的回答者。在这里推荐比较可能回答相似问题的用户时,考虑了系统对用户过去历史行为评价的一些属性特征,比如用户声誉值、用户主页浏览数、用户评分、用户徽章数、用户发帖数量等,并对这些用户属性特征使用不同的权重。使用逻辑回归的方法来确定这些权重参数值,对这些属性值与权重进行累加和,得出的数值中最高的几个作为最终的推荐结果。
权重累加和计算公式:
每个权重值都在0~1之间,参数值都归一化在0~10之间。最后根据综合计算指标的得分,选择得分最高的几个回答作为推荐的结果。
本发明在传统的基于内容的推荐的基础上,结合了用户属性权重,使得推荐结果更具有针对性,提高了推荐的相关度和准确度,从而使用户可以在问答平台上更高效的找到所提出问题的潜在的回答者,更快的得到问题的回答,解决问题长时间没人回答的困境,促进问答平台的发展。
附图说明
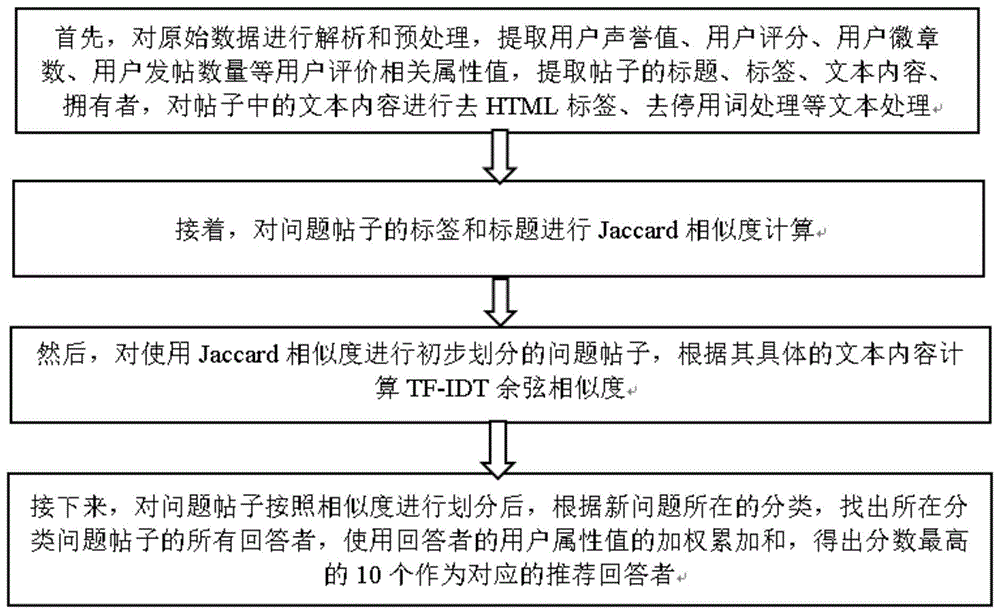
图1是本发明所使用的一种针对社区问答平台的混合推荐方法的总体流程图。
具体实施方式
以下结合附图对本发明的技术方案进行详细说明。
如图1所示为一种针对社区问答平台的回答者推荐方法,其包括以下步骤:
首先,把从问答社区平台中下载的原始数据进行解析和预处理,提取平台中所有用户的用户声誉值、用户主页浏览数、用户评分、用户徽章数、用户发帖数、用户注册日期、用户最后登入日期,用户最后活动日期这些用户相关的属性值,并专门存入用户数据的数据表。把平台中所有帖子分为回答和提问两类,将帖子中的标题、标签、文本内容、拥有者进行提取,对帖子中的文本内容进行去html标签、去停用词处理,并把处理后的数据专门存入帖子数据的数据表。
接着,对于所要进行推荐的问题获取它的标题和标签,与数据库中其他的问题帖子的标题和标签进行jaccard相似度的计算。
jaccard相似度:
jaccard(a,b)=|a∩b|÷|aub|
其中a是原有问题集中的标题集合,b是新问题中的标题集合。
接下来,对上述jaccard得出的相似度进行排序,选出相似度高的进行下一步的操作。对初步筛选后问题帖子的文本内容,运用一个结合文本词汇频率(termfrequency)和逆文本频率(inversedocumentfrequency)的混合模型,使用文本体上的余弦相似度测量方法计算帖子文本内容的余弦相似度。tf-idf是一个数值统计,旨在反映一个词在一个集合或语料库中对文档的重要程度,并作为给定用户查询的文档相关性打分和排名的核心工具。帖子数据中的内容文本都是对问题或回答的文字描述,文字内容越相近说明这两个帖子越相似。
tf-idf:
tf-idf(t,d,d)=tf(t,d)×idf(t,d)
其中n:语料库中的文档总数,n=|d||{d∈d,t∈d}|,术语t出现的文档数。d表示文档,d表示文档中的一项,t表示一个文档中的一条术语。
余弦相似度:
其中ai和bi分别是向量a和b的分量。
紧接着,在通过计算jaccard相似度和tf-idf余弦相似度对问题帖子集进行划分后,根据需要推荐的问题所在的分类,在这个分类包含的问题帖子中查找对应的回答帖子,再找到这些回答帖子对应的用户,这些用户都是潜在的相似新问题的回答者。在这里推荐比较可能回答相似问题的用户时,考虑了系统对用户过去历史行为评价的一些属性特征,比如用户声誉值、用户主页浏览数、用户评分、用户徽章数、用户发帖数量,并计算用户在这段时间内的用户活跃度,并对这些用户属性特征使用不同的权重。根据这些属性值与权重加权和的计算,得出最终所要推荐给问题提问者的几个潜在回答用户。
在推荐潜在的回答者时,对于用户属性值进行归一化处理,把每个属性的数值都确定在0~10之间,权重值都确定在0~1之间,并使用逻辑回归的方法确定权重参数。以这些属性值和权重参数的加权和进行排序,把排在前面的用户作为潜在回答者推荐给提出问题的提问者。
权重累加和计算公式:
最后,根据最终计算得到的回答过与所需推荐问题相似的其他问题的每个回答者的用户评分指标的得分,选取其中得分最高的几个用户,作为对要进行回答者推荐的问题的推荐回答用户返回给问题提问者,从而完成了对社区问答平台针对某一问题推荐潜在回答者的目标。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡在本发明的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!