一种文本处理方法、装置、计算机设备以及可读存储介质与流程
1.本技术涉及计算机技术领域,尤其涉及一种文本处理方法、装置、计算机设备以及可读存储介质。
背景技术:
2.随着全球化进程的推进以及互联网信息业务的飞速发展,越来越多的产品拥有面向不同国家的业务,与此同时,产品服务方也面临着处理大量不同语言的文本数据,例如海外用户的咨询邮件,而在这些文本数据中,绝大多数是多种语言混合的文本数据,在此情景下,需要对文本数据的主要语种进行识别,以便根据识别出来的语种提供更有针对性的服务。
3.目前,对文本的语言识别通常是根据某个语种的特殊字符对文本进行判别,即当文本中出现的特殊字符属于某个语种,则将该语种作为文本所属的语种;或者收集某个语种的高频词集,当文本中出现的词语属于某个语种的高频词,则将该语种确定为文本所属的语种。上述方案的语种判别条件对语种成分的识别比较可靠,但是在识别多语种的文本的主要语种时可靠度不高,会影响识别结果的准确度。
技术实现要素:
4.本技术实施例提供了一种文本处理方法、装置、计算机设备以及可读存储介质,可以准确确定出待处理文本的主要语种。
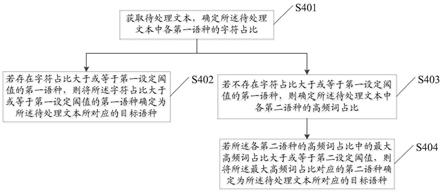
5.本技术实施例一方面提供了一种文本处理方法,包括:
6.获取待处理文本,确定所述待处理文本中各第一语种的字符占比;
7.若存在字符占比大于或等于第一设定阈值的第一语种,则将所述字符占比大于或等于第一设定阈值的第一语种确定为所述待处理文本所对应的目标语种;
8.若不存在字符占比大于或等于第一设定阈值的第一语种,则确定所述待处理文本中各第二语种的高频词占比;
9.若所述各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将所述最大高频词占比对应的第二语种确定为所述待处理文本所对应的目标语种。
10.本技术实施例一方面提供了一种文本处理装置,包括:
11.获取模块,用于获取待处理文本,确定所述待处理文本中各第一语种的字符占比;
12.确定模块,用于若存在字符占比大于或等于第一设定阈值的第一语种,则将所述字符占比大于或等于第一设定阈值的第一语种确定为所述待处理文本所对应的目标语种;
13.所述确定模块,还用于若不存在字符占比大于或等于第一设定阈值的第一语种,则确定所述待处理文本中各第二语种的高频词占比;
14.所述确定模块,还用于若所述各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将所述最大高频词占比对应的第二语种确定为所述待处理文本所对应的目标语种。
15.本技术实施例一方面提供了一种计算机设备,包括:处理器和存储器;
16.存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行本技术实施例中的文本处理方法。
17.本技术实施例一方面提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序包括程序指令,程序指令当被处理器执行时,执行本技术实施例中的文本处理方法。
18.相应的,本技术实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行本技术实施例中一方面提供的文本处理方法。
19.在本技术实施例中,通过将各第一语种的字符占比和第一设定阈值进行比较,将大于第一设定阈值的字符占比对应的第一语种确定为待处理文本所对应的主要语种(即目标语种,为待处理文本中占比较大的语言),这样针对混合不同语种的待处理文本,可以增强语种识别的准确性,若上述利用字符的方式不能识别出待处理文本的语种,则需要将对待处理文本的字符识别提升到对待处理文本的单词识别,通过将待处理文本中各第二语种的高频词占比和第二设定阈值进行比较,可以将大于第二设定阈值的最大高频词占比对应的第二语种确定为待处理文本所对应的主要语种。这样不仅解决了真实应用场景中多语种混杂的情况,还提升了整个语种识别模型对待处理文本的主要语种判别的可信度和准确性。
附图说明
20.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
21.图1是本技术实施例提供的一种文本处理系统的架构示意图;
22.图2是本技术实施例提供的一种邮件处理的流程示意图;
23.图3是本技术实施例提供的一种文本语种识别的流程示意图;
24.图4是本技术实施例提供的一种文本处理方法的流程示意图;
25.图5是本技术实施例提供的一种文本处理方法的流程示意图;
26.图6是本技术实施例提供的一种文本处理装置的结构示意图;
27.图7是本技术实施例提供的一种计算机设备的结构示意图。
具体实施方式
28.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
29.本技术实施例的核心思想是针对不同语言的特性,通过字符编码确定待处理文本
的字符的占比或者通过对待处理文本分词得到的分词信息确定待处理文本的词的占比,根据占比和相应阈值的比较结果确定待处理文本所属的主要语种,这样对不同语言的特性差异化检测方法,提升了待处理文本的主要语种识别效率,同时引入置信度(即阈值)在相应语种的占比达到阈值的情况下才判定为该语种,增加了识别结果的准确度。其中,待处理文本所属的主要语种通常只有一种,可以是按照待处理文本中字符或者高频词计算得到的最大字符占比或最大高频词占比的语言,也称为目标语种,因此,主要语种等同于目标语种,在下述内容中两者出现任一者均可替换。本技术实施例提供的文本处理方法基于人工智能领域下属的自然语言处理(nature language processing,nlp)技术。
30.人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
31.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
32.其中,自然语言处理(nature language processing,nlp)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。例如本技术实施例中利用字符编码得到待处理文本的字符占比或对待处理文本分词得到高频词占比。
33.请参阅图1,图1是本技术实施例提供的一种文本处理系统的架构示意图。如图1所示,该文本处理系统的架构可以包括文本处理设备100以及终端设备101,终端设备101可以包括多个,每个终端设备101可以与上述文本处理设备100进行网络连接,网络连接可以包括有线连接或无线连接,以便于每个终端设备可以通过该网络连接与文本处理100进行数据交互,以及文本处理设备100可以接收到来自于每个终端设备101的业务数据,下面对文本处理设备100和终端设备101的具体功能进行详细介绍。
34.文本处理设备100可以是单个服务器、服务器集群、云服务器中的一种或多种,在此对其不做限制,文本处理设备100主要功能是对待处理文本进行语种识别,此处待处理文本可以是从文本数据库中获取的预先存储的文本数据,也可以是终端设备101直接上传给文本处理设备100的实时文本数据。语种识别的过程中,首先文本处理设备100先对待处理文本中每个字符进行处理,生成字符编码,然后根据字符编码统计各第一语种的字符数和文本字符总数,并结合文本数据库中预先存储的字符集对应的字符编码区间,对待处理文本各第一语种的字符占比进行检测,然后根据字符占比和第一设定阈值来确定待处理文本所属的主要语种,若根据字符占比无法确定待处理文本所属的主要语种,文本处理设备100则会对待处理文本进行分词处理,得到分词信息并结合文本数据库中预先存储的目标高频
词表,对待处理文本中各第二语种的高频词占比进行检测,根据高频词占比和第一设定阈值来确定待处理文本所属的主要语种,若根据高频词占比也无法确定待处理文本所属的主要语种,会将默认语种确定为待处理文本的主要语种。文本处理设备100在将待处理文本所对应的语种识别出来之后,可以将识别结果存储到文本数据库或者直接发送给终端设备,以便终端设备101进行后续处理,例如待处理文本是邮件文本,则根据该邮件的识别结果将其分发给对应的服务部门的终端设备101中由专员进行回复。此外,文本处理设备100也可以作为文本数据库存储全量业务数据,该业务数据可以是文本数据或识别数据,例如未识别的待处理文本或者已识别的待处理文本。
35.终端设备101可以是智能手机、摄像机、台式计算机、平板电脑、mp4播放器和膝上型便携计算机中的一种或多种,终端设备101可以安装和运行用于管理文本数据的目标应用程序,在该目标应用程序中,终端设备101可以监测到未识别待处理文本数量、文本处理设备100已识别的待处理文本数量、派发的已识别的待处理文本数量,查看相应数据报表等。此外,终端设备101也可以上传待处理文本给文本处理设备100,或者从文本数据库或文本处理设备100中下载识别成功的待处理文本进行后续处理。
36.针对上述文本处理系统的架构图的具体应用场景,请参见图2,图2是本技术实施例提供的一种邮件处理的流程示意图,针对邮件的语种识别能力主要应用在一种客服服务平台上,具体涉及对海外用户的邮件进行回复的服务场景。整个流程包括步骤如下:
37.步骤1,邮件收取。具体可以通过服务端从专门存放邮件数据的数据库中获取用户发送过来的邮件,例如某款产品的官方邮箱中的邮件所在的数据库。通常情况下,邮件文本涉及对产品的咨询和使用帮助,以某一种语言为主进行文字描述,因此该邮件文本可能包括一种或多种语言,例如韩语为主同时夹杂少量英文缩写的邮件。
38.步骤2,语种识别。对于收取到的邮件所属的语种,需要送入语种识别模型中进行智能化检测,语种识别模型中利用相应的检测方法对该邮件进行处理,最终给出一种语言作为该邮件所对应的目标语种,以达到语种识别的目的。如上述示例英语和韩语中,经过语种识别确定韩语是邮件所属的目标语种。
39.步骤3,邮件分派。将得到识别结果的目标邮件分派给对应的语种服务技能组。具体是根据邮件的识别结果自动分配,而不再需要将邮件集合到公共服务组,然后由公共服务组人工分发,这样可以提高每个语种服务技能组对接相应邮件的效率,简化处理流程。
40.步骤4,人工处理。当邮件分派到对应的语种服务技能组时,仍旧是需要人工处理,具体是由语种服务技能组安排专员进行处理,例如上述韩语的邮件,分派给韩语服务技能组,韩语服务技能组安排专员答复该邮件。
41.至此,完成了邮件回复的整个流程。在整个邮件派发流程中,通过机器自动识别邮件语种,自动派发到不同技能组的方式,无需人工干预,减少了流程复杂度,节省了人力。
42.图2提供的邮件处理流程中的语言识别这一步骤在具体的技术实现中,可参见图3,图3是本技术实施例提供的一种文本语种识别的流程示意图。由于海外版邮件的回复往往建立在多语种之上,高效的语种检测是实现多语种邮件回复的前提条件,因此本方案设计了一个能够识别多种语言的检测服务,并能很容易扩充到其他语种,目前实现的有中文(ch)、英文(en)、阿拉伯语(ar)、俄语(ru)、土耳其语(tr)、西班牙语(es)以及意大利语(it),具体的语种识别流程参见图3,其核心内容为字符集检测和停用词检测,根据不同语
种的特性选择不同的方式进行检测。首先对文本进行预处理,过滤掉文本中的标点符号、超链接、数字等,再通过字符集检测文本是否含特殊字符,如果不含则进行停用词占比检测,若再次检测失败则返回默认语种英文,对应流程图中的内容则具体可以解释为:
43.步骤1,输入文本。输入文本包括的语种不限,可以包括目前语种识别能够处理的语种,如中文(ch)、英文(en)、阿拉伯语(ar)、俄语(ru)、土耳其语(tr)、西班牙语(es)以及意大利语(it)。
44.步骤2,快速预处理。主要是去除文本内除特殊字符外的符号,例如标点符号、超链接、数字等,去除后得到的文本包括所需的文本字符,这样可以节省后续处理的时间,加快处理速度。
45.步骤3,字符集检测。用于检测有特殊字符的语种,包括中文(ch)、阿拉伯语(ar)、俄语(ru)。当字符集检测成功,执行步骤5的召回,将符合标准的语种返回给步骤5;当字符集检测失败,执行步骤4停用词比例检测。
46.步骤4,停用词比例检测。当字符集检测失败,执行此步骤,主要用于检测土耳其语(tr)、西班牙语(es)以及意大利语(it)。当停用词比例检测成功,同样执行步骤5的召回,将停用词检测得到的结果进行召回处理;当停用词比例检测失败,同样执行召回处理,此时召回的是默认语种英文(en),然后将召回的语种作为输入文本所属的主要语种,结束文本识别。
47.步骤5,召回。在字符集检测或停用词比例检测成功的情况下,将通过字符集检测得到的语种进行召回处理或者将停用词比例检测得到的语种进行召回处理,然后将召回的语种作为输入文本所属的目标语种,结束文本识别。在停用词比例检测失败的情况下,召回默认语种英文,作为输入文本所属的目标语种。通常情况下,召回成功只会返回一种语种,且从字符或词的角度理解,多种语言的占比之和为1,通过对各语种的占比进行计算并设置特定阈值可以确定输入文本的主要语种。
48.上述文本语种识别的方案根据不同语种的特性差异,利用字符集检测和停用词比例检测有针对性地检测文本的主要语种,提升了模型判别的准确性和可靠度,通过文本语种识别的整体方案高效鉴别输入文本的主要语种,这样有利于针对待处理文本准确的分配相应语种的处理人员,特别是在智能化识别邮件语种方面进一步加快了相应语种的客服人员针对性答复,提升邮件处理效率。实验证明,该方案中的针对邮件的语种识别准确率在90%以上,上线后简化了多语种邮件回复流程,降低了系统复杂度,节省了人力。
49.可以理解的是,本技术实施例提供的文本语种识别方法可以由计算机设备执行,计算机设备包括但不限于终端设备101和文本处理设备100。其中,计算机设备可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn、以及大数据和人工智能平台等基础云计算服务的云服务器。
50.进一步地,为便于理解,请参见图4,图4是本技术实施例提供的一种文本处理方法的流程示意图。该实施例中的执行主体可以是一个计算机设备或者是多个计算机设备构成的集群,该计算机设备可以是终端设备,也可以是服务器,此处,以本实施例中的执行主体为服务器为例进行说明。其中,该文本处理方法至少可以包括以下步骤s401
‑
s404:
51.s401,获取待处理文本,确定所述待处理文本中各第一语种的字符占比。
52.在一种可能的实施例中,待处理文本包括一个或多个字符,这些字符可以是罗马数字、拉丁文字母、标点符号、几何符号、多种语言的文字字符等中的一种或多种,根据这些字符可以构成一段表达特定语义的内容,例如拉丁字母和标点符号等组成的超链接,或英文字符组成的多个单词构成的一句话,或者其他语言文字构成的一段内容,当然,也可以是随机的字符构成无任何语义的内容,对待处理文本的内容和所涉及的语种,本技术在此不做限制。具备文本处理功能的服务器可以从文本数据库中获取待处理文本,该文本数据库可归属于服务端,获取到待处理文本后,还需要对待处理文本进行预处理,过滤掉文本中的标点符号、超链接、数字等,再利用预处理之后的待处理文本包括的字符确定出各第一语种的字符占比。
53.在一种可能的实施例中,确定待处理文本中各第一语种的字符占比的实现方式可以包括以下步骤:获取待处理文本中每个字符对应的字符编码。这里的字符编码可以是针对待处理文本每个字符生成的unicode编码(即全球文字统一编码),由于unicode编码把世界上的各种文字的每一个字符指定唯一编码,可以实现跨语种、跨平台的应用,由此利用unicode编码可以确定待处理文本中的字符所属的编码范围以及该字符所属的语言,所以采用unicode编码可以很好地识别文本的语种,当然字符编码还可以是其他可以唯一表示各种语言的文字的编码,在此不做限制。上述提及待处理文本包括的字符可以是多语种的字符,而每个语种的字符编码、字符编码区间不同,因此根据各第一语种的字符编码区间、待处理文本中每个字符的字符编码以及待处理文本的字符总数,可以确定待处理文本中各第一语种的字符占比。对应的,这里的各第一语种的字符编码区间对应为有特殊字符的unicode编码范围,每一种语言的字符编码区间都对应有不同字符编码对应的字符所构成的字符集,字符占比是指第一语种的特殊字符占比,特殊字符是只在这个语种(或语言)中出现的字符,而在其他语种(或语言)中没有出现,而有特殊字符的语种也统一称为第一语种。示例的,例如拉丁字符,不仅在英语中有,包括意大利语、法语等中均有使用,因此拉丁字符不是特殊字符,英语、意大利语和法语等也不是第一语种。即使每个拉丁字符有unicode编码,但对于不同语言中由拉丁字符构成的单词也可能重复,没有唯一的表示,相反,例如中文、阿拉伯语、俄语、韩语和日语,这些语言各自拥有独特的字符,有独特的unicode编码范围,如表1所示,为不同语言的unicode编码范围。
54.表1不同语言的unicode编码范围
[0055][0056]
由上表可知,每个编码范围对应一个字符集,例如4e00
‑
9fcc是常用汉字中的部分字符集合,3400
‑
4db5是中文扩展a的字符集,包括6582个字,又如日语中的3040
‑
309f是日文平假名的字符集,30a0
‑
30ff是日文片假名的字符集,由于表1中的语言均有对应unicode
编码范围的独特字符(即特殊字符),因此均可以作为第一语种。若对第一语种进行扩展,具体的扩展标准则可以是将拥有特殊字符的语种均可以作为第一语种,如泰语、蒙古语等语言中的文字,在其他语言中没有重复出现过的可以视为特殊字符,而泰语、蒙古语等具备特殊字符的语言和表1中的语言可以一同作为第一语种。
[0057]
综上所述,由于不同语言会有相同字符,而相同字符的编码是一样的,因此找出不同语言的编码范围即可确定特殊字符,然后根据待处理文本的字符编码可以判定其是否落入如表1所示的带有特殊字符的第一语种的字符编码范围,如果在这个范围之内,即可将该字符认定为属于对应语种的特殊字符,其他字符也依照同样的原理进行特殊字符的判断,之后将待处理文本中的特殊字符的字数和文本总字数的比值作为特殊字符占比。针对不同的第一语种,特殊字符占比需要分别进行统计,因此字符占比数值可能相同或不同,和表1中的第一语种相对应,最终得到的待处理文本中各第一语种的字符占比就包括中文、阿拉伯语、俄语、韩语和日语,各自的字符占比可分别记为{x1,x2,x3,x4,x5},每个第一语种的字符占比通常表示为百分数,如10%这样的形式,若待处理文本中不包括某一个第一语种,例如中文,则对应的字符占比记为0。
[0058]
举例来说,例如待处理文本为“尽快帮我解封我的pubg id”,字符涉及的语言包括中文和英文,而特殊字符只有中文,由此,特殊字符数量为8,英文字符数量为6,文本总字符数为14,计算得到中文的字符占比为8/14(约为57.14%),其他第一语种(包括阿拉伯语、俄语、韩语和日语)的字符占比均为0,而英文由于不是特殊字符,因此不纳入第一语种的字符占比计算中。
[0059]
s402,若存在字符占比大于或等于第一设定阈值的第一语种,则将所述字符占比大于或等于第一设定阈值的第一语种确定为所述待处理文本所对应的目标语种。
[0060]
在一种可能的实施例中,理想情况下,只要判断输入文本的字符unicode编码范围包含特定语种的编码范围就可以认定该文本就是这个语种,然而,在实际应用场景的文本中常常会混合不同的语种,采用上述方式无法确定出文本的主要语种,如上述示例的中英文混杂文本:help me unblock my pubg id as soon as possible,谢谢。其中包括中文和英文,按照unicode编码认定该文本的语种是中文,但实际上英文才是主要语种,将英文正确识别出来才能提供相应语种的处理。因此为了增强判别的准确性,本方案中引入了特殊字符占比(即字符占比)和置信度(即第一设定阈值),将待处理文本中包含的特殊字符的字数与文本总字数的比值作为特殊字符占比,仅当该比值达到特定阈值(即第一设定阈值),才可以被判定为对应语种,需要说明的是,各第一语种共用一个第一设定阈值。
[0061]
通过将各第一语种的字符占比和第一设定阈值进行比较,可以确定出大于等于第一设定阈值的字符占比对应的第一语种,将其作为待处理文本对应的目标语种,即待处理文本的主要语种。作为一种可选的实现方式,也可以先从各第一语种的字符占比中确定出最大字符占比,将最大字符占比和第一设定阈值进行比较,若最大字符占比都大于或等于第一设定阈值,那么在第一语种中一定存在待处理文本的主要语种,就可以将最大字符占比对应的第一语种作为待处理文本所对应的主要语种,而不用再进行后续的处理步骤。通常情况下,第一设定阈值的数值设定大于50%,这样可以针对相同的语种,保证待处理文本中的字符半数以上都是该语种的特殊字符,将其作为待处理文本的主要语种也更加可信。
[0062]
s403,若不存在字符占比大于或等于第一设定阈值的第一语种,则确定所述待处
理文本中各第二语种的高频词占比。
[0063]
在一种可能的实施例中,如果待处理文本中各第一语种的最大字符占比都小于第一设定阈值,那么则说明各第一语种中不存在字符占比大于或等于第一设定阈值的第一语种,也就无法识别出待处理文本所属的主要语种,这可能是因为待处理文本中包括较多的拉丁字母,因此,需要将识别方法从利用字符上升到利用单词,通过对输入的待处理文本建立多种语言下的高频词分布来判定最佳对应语种,而此种识别方式首先需要确定各第二语种的高频词占比,其中,高频词是指在第二语种中使用频率较高的词语或者单字符。待处理文本中包括的高频词的确定是需要结合预先收集整理的停用词表(stop words),在本方案中,收集并整理了土耳其语、西班牙语和意大利语的停用词表,其中,土耳其语、西班牙语和意大利语可称为第二语种。停用词这一概念常用在检索系统中,称为停用词是因为文本处理过程中遇到这些词汇立即停止处理,将其扔掉,以减少索引量,增加检索效率,进而提高检索效果,在本技术实施例中也有同样的原理,根据停用词(此方案中采用高频词作为停用词)可以更快速有效地确定待处理文本所包括的语种,然后根据高频词占比从待处理文本所包括的语种中确定出主要语种(即目标语种)。通过将输入的待处理文本分词之后,计算各第二语种的停用词在待处理文本内所占的比例,具体可以将第二语种的高频词的词数和文本总词数的比值作为对应的高频词占比,且每个第二语种都对应有一个高频词占比,通常以百分比的形式出现。
[0064]
s404,若所述各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将所述最大高频词占比对应的第二语种确定为所述待处理文本所对应的目标语种。
[0065]
在一种可能的实施例中,和字符占比类似,此步骤同样引入了高频词占比和置信度(此处指第二设定阈值),将高频词占比达到第二设定阈值对应的第二语种判定为待处理文本所属的主要语种(即目标语种)。具体的,可以先从各第二语种的高频词占比中确定最大高频词占比,然后将最大高频词占比和第二设定阈值进行比较,如果最大高频词占比大于等于第二设定阈值,则判定待处理文本所属的目标语种为最大高频词占比对应的第二语种,也就是说如果某种语言的高频词占比既是最高值,同时也达到了设定阈值,那么待处理文本判定为该语种。相反,如果最大高频词占比都小于第二设定阈值,这说明各第二语种的高频词占比中没有大于或等于第二设定阈值的高频词占比,也就无法从第二语种中确定出待处理文本所对应的主要语种,在此情况下,可以将默认语种作为待处理文本所对应的主要语种,这里的默认语种可以为英语。
[0066]
可选的,也可以各第二语种的高频词占比和第二设定阈值分别进行比较,确定出大于等于第二设定阈值的最大高频词,如果出现两个及以上的大于等于第二设定阈值的高频词占比,就从这两个及以上的大于等于第二设定阈值的高频词占比中选择最大高频词占比,将最大高频词占比对应的第二语种确定为待处理文本所对应的目标语种。
[0067]
需要说明的是,第二设定阈值和第一设定阈值在数值上设定不同,但类似的是,第二设定阈值也是多种语言共用,即各第二语种的高频词占比均以第二设定阈值为判别标准进行比较。
[0068]
综上所述,本技术实施例至少具有以下优点:
[0069]
通过unicode编码构成的字符集或者高频词构成的高频词表,对包括多种语言的
待处理文本进行检测,确定出待处理文本的主要语种。具体的,为了保证多语种待处理文本的主要语种识别的准确度,从字符方面,引入特殊字符占比和第一设定阈值作为主要语种识别的参考标准,利用字符集检测待处理文本的特殊字符占比,以确定待处理文本的主要语种;当字符集检测无法判断出待处理文本对应的主要语种,则需要从词语方面考量,通过引入各第二语种的高频词占比和第二设定阈值,利用高频词表检测待处理文本的高频词占比,以确定所属的主要语种。在上述两种方式的处理过程中,优先采用字符集检测,而高频词表检测作为辅助,且两种方式引入占比和阈值,保证了对待处理文本在多种语言情况下,得到的识别结果更有说服力,提升了待处理文本的主要语种识别的准确度和可信度。
[0070]
请参见图5,图5是本技术实施例提供的一种文本处理方法的流程示意图。该实施例中的执行主体可以是一个计算机设备或者是多个计算机设备构成的集群,该计算机设备可以是终端设备,也可以是服务器,此处,以本实施例中的执行主体为服务器为例进行说明。其中,该文本处理方法至少可以包括以下步骤s501
‑
s505:
[0071]
s501,获取待处理文本,确定所述待处理文本中各第一语种的字符占比。
[0072]
s502,若存在字符占比大于或等于第一设定阈值的第一语种,则将所述字符占比大于或等于第一设定阈值的第一语种确定为所述待处理文本所对应的目标语种。
[0073]
上述步骤的具体实现方式可参见上述图4对应实施例中的s401
‑
s402,这里不再进行赘述。
[0074]
s503,若不存在字符占比大于或等于第一设定阈值的第一语种,则确定各第二语种的目标高频词表,以及获取所述待处理文本的分词信息。
[0075]
在一种可能的实施例中,若各第一语种的字符占比均小于第一设定阈值,利用字符集对待处理文本检测方法无法有效判别主要语种,此时可以利用待处理文本的词语进行语种检测,在这个过程中,关键在于预先建立各第二语种准确的目标高频词表,这里的目标高频词表即上述实施例提及的停用词表(stopwords)。对于各第二语种的目标高频词表的确定过程,可以包括以下内容:针对任一第二语种,获取第二语种中由一个或多个高频词构成的候选高频词表。这里的候选高频词表是根据统计的第二语种中词语的出现次数和设定的阈值来确定的,例如将出现次数大于阈值的词语作为高频词。需要说明的是,各第二语种的候选高频词表都是独立统计的,对于各第二语种之间重复的高频词也是存在于候选高频词表中的,示例的,如西班牙语和意大利语就共用了许多高频词,在西班牙语和意大利语的候选高频词表中均存在候选高频词a。由此可知,各第二语种的候选高频词表之间可能存在交集,而过多地交集会影响高频词分布,在一段文本中所计算的停用词分布会具有很大的误导性,进而导致语种识别准确率比较低,为了解决这一问题,本技术实施例中对候选高频词表进行了预处理,具体是将候选高频词表中的共用候选高频词进行剔除,进而得到第二语种的目标高频词表。这里的共用高频词是指出现在各第二语种的候选高频词表中的次数大于等于设定次数的候选高频词,简单理解即多个第二语种共用的停用词。示例的,假设第二语种有4种,对应的候选高频词表分别为{t1,t2,t3,t4,},每个候选高频词出现的设定次数为2次,其中,候选高频词语a在这四张候选高频词表中的出现次数为3次,大于设定次数,由此可以将其进行剔除。对于共用高频词的筛选标准可以采用如下表达式(1):
[0076]
s≥ceil(n/2)
ꢀꢀꢀꢀꢀꢀꢀ
(1)
[0077]
其中,s表示候选高频词在候选停用词表中的出现次数,ceil表示向上取整,n表示
语种个数。按照此筛选标准,具体则是将出现在半数及以上的候选高频词表中的候选高频词进行删除。
[0078]
除此之外,还可以剔除候选高频词表中的单字符候选高频词,其中,单字符候选高频词可以是单个拉丁字母a
‑
z(或a
‑
z)。对候选高频词表中的单字符候选高频词和共用候选高频词这两种类型的高频词都进行剔除,具体操作可以通过遍历每个第二语种对应的候选高频词表,剔除候选高频词表中的单字符候选高频词,然后将需要使用候选高频词表检测的语种(第二语种中的部分语种或者所有第二语种)的所有候选高频词放在一个集合中,对集合中的词进行统计计数并排序,将筛选出次数大于等于设定次数的所有词记录在共用高频词表filtered_stopwords中,然后遍历每个候选高频词表,将出现在filtered_stopwords中的候选高频词进行剔除,最后将剔除后的候选高频词表作为第二语种的目标高频词表,如表2展示的停用词表(即各第二语种的目标高频词表):
[0079]
表2停用词表
[0080][0081]
上述停用词表的土耳其语、西班牙语、意大利语统称为第二语种,对应的停用词(即高频词)是部分内容的展示,其中,第二语种可以根据能否建立对应的高频词表进行扩展。
[0082]
另外,还可以针对业务特性在目标高频词表中加入一些常出现的业务高频词,将不同语种的业务高频词加入目标高频词表。具体的,可以先确定待处理文本所指示的业务类型,如游戏类、美妆类、娱乐类等,具体可以按照待处理文本的语义信息来确定或者其他方式,在此不作限定,然后获取和业务类型相关的高频词,例如海外游戏业务,可以从待处理文本中收集到游戏相关的词语,如封号、解封、登录、卡顿等,将这些高频词对应的第二语种加入目标高频词表,例如将“封号”对应的土耳其语、西班牙语和意大利语分别各自对应的目标高频词表中,以便遇到同样业务类型的待处理文本时可以快速确定出待处理文本所包括的语种,提高待处理文本的主要语种识别的效率。当然,也可以预先收集所有业务类型相关的术语作为业务高频词,将其加入对应的目标高频词表中,按照业务类型对目标高频词表的业务高频词进行分区管理,然后根据待处理文本所指示的业务类型,从对应业务类型分区的业务高频词中确定相应语种的高频词。进一步地,还可以增加部分语种独特性的高频词提升各第二语种的区分度,也可以快速确定待处理文本的高频词对应的第二语种。
[0083]
上述方案对候选高频词表进行了预处理,包括删除所有单个拉丁字母表示的停用词、删除部分多个语种共用的停用词以及增加部分更具有语种独特性的高频词,在整个过程中,需要针对不同的操作设定不同的阈值进行判断,最终得到目标高频词表,其所体现的高频词分布更加具有指导意义,并且适当的引入更有针对性业务相关的停用词,增加了业务关联性,提高了目标候选高频表的区别度,从而实现对待处理文本的主要语种的高效识别。
[0084]
在确定各第二语种的目标候选高频词表的同时,还需要获取待处理文本的分词信息,具体的获取方式可以是按照词间隔符对待处理文本进行分词处理或者利用分词模型对待处理文本进行分词处理,得到一个或多个词语,并将其作为分词信息。其中,词间隔符可以为空格,由于单词和单词之间有天然的空格作为分词的标准来使用,使用空格划分拉丁字母构成的单词不仅准确,而且快速方便,然而对于没有空格作为分词基础的语种,如中文、日文等,使用词间隔符的分词会有一定的误差,进而导致准确度欠佳,因此需要考虑采用一种通用的深度分词方法,例如利用通用的分词模型对待处理文本进行处理,既可以按照空格快速拆分单词,还可以将紧密相连的文字按照语义拆分,由此提高多语种文本分词的正确率,从而提升基于各第二语种的目标高频词表识别待处理文本所属的主要语种的准确度,其中,通用的分词模型可以是利用各种语言进行训练之后的深度神经网络,或者其他网络模型,在此不做限制。
[0085]
s504,根据所述各第二语种的目标高频词表和所述待处理文本的分词信息,确定所述待处理文本中各第二语种的高频词占比。
[0086]
在一种可能的实施例中,由于待处理文本的分词信息包括一个或多个文本词语,根据这个一个或多个文本词语可以确定待处理文本包括的高频词和文本词语总数。对于高频词的确定,需要结合各第二语种的目标高频停用词表,针对每一个第二语种,将分词信息中的文本词语和目标高频词表中的高频词进行匹配,把和目标高频词表中相同的文本词语确定为高频词,进而确定出各第二语种的高频词以及高频词数量,此时可以将高频词数量和文本词语总数的比值作为第二语种的高频词占比。
[0087]
示例的,如“ay
ú
dame a desbloquear mi id de pubg lo antes posible”中涉及英文缩写和西班牙语,可以按照空格进行分词,得到的文本总词数为10,而高频词包括ay
ú
dame、desbloquear、mi、lo、de这5个,由于英文在其他语种中也比较常见,因此没有对应的高频词表,也就没有对应的高频词,那么各第二语种的高频词占比中西班牙语的高频占比为50%,而土耳其语和意大利语的高频词占比均为0。
[0088]
s505,若所述各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将所述最大高频词占比对应的第二语种确定为所述待处理文本所对应的目标语种。
[0089]
此步骤的具体实现方式可参见上述图4对应实施例中的s404,这里不再进行赘述。
[0090]
综上所述,本技术实施例至少具有以下优点:
[0091]
在利用高频词占比和第二设定阈值确定待处理文本所属的目标语种的过程中,各第二语种的目标高频词表和待处理文本的分词信息都是文本语种识别的关键之处,需要获取足够精准的高频词分布以及文本分词,以使得高频词占比和文本分词准确,进而保证最终的识别结果更准确。其中,针对不同第二语种之间的高频词可能交叉共用,会影响高频词分布的作用,采取的具体措施是删除多个语种共用的高频词。此外还可以通过剔除单字符高频词、增加语种独特性的高频词、引入针对业务类型的高频词等多种方式,辅助提升高频词分布的准确度,也增加了各第二语种的目标高频词表的区分度,这样在利用目标高频词匹配待处理文本的分词信息时可以快速准确地确定高频词占比,从而在各第二语种中确定出待处理文本所对应的主要语种。另外,针对待处理文本的分词信息的处理,采用通用的分词模型处理多语种的待处理文本,可以极大地减少分词的误差,高效准确识别待处理文本
所属的主要语种。
[0092]
请参见图6,是本技术实施例提供的一种文本处理装置的结构示意图,该文本处理装置可以是运行于图1所示的文本处理设备100中的一个计算机程序(包括程序代码),例如文本处理装置为一个应用软件;该装置可以用于执行本技术实施例提供的方法中的相应步骤。该文本处理装置60包括:获取模块601、确定模块602,其中:
[0093]
获取模块601,用于获取待处理文本,确定待处理文本中各第一语种的字符占比;
[0094]
确定模块602,用于若存在字符占比大于或等于第一设定阈值的第一语种,则将字符占比大于或等于第一设定阈值的第一语种确定为待处理文本所对应的目标语种;
[0095]
确定模块602,还用于若不存在字符占比大于或等于第一设定阈值的第一语种,则确定待处理文本中各第二语种的高频词占比;
[0096]
确定模块602,还用于若各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将最大高频词占比对应的第二语种确定为待处理文本所对应的目标语种。
[0097]
在一实施例中,确定模块602具体用于:获取待处理文本中每个字符对应的字符编码;根据各第一语种的字符编码区间、待处理文本中每个字符对应的字符编码以及待处理文本的字符总数,确定待处理文本中各第一语种的字符占比。
[0098]
在一实施例中,确定模块602具体用于:确定各第二语种的目标高频词表,以及获取待处理文本的分词信息;根据各第二语种的目标高频词表和待处理文本的分词信息,确定待处理文本中各第二语种的高频词占比。
[0099]
在一实施例中,确定模块602具体用于:针对任一第二语种,获取第二语种的候选高频词表,候选高频词表包括一个或多个候选高频词;将候选高频词表中的单字符候选高频词和共用候选高频词中的一种或者多种进行剔除,得到第二语种的目标高频词表,共用候选高频词是指出现在各第二语种的候选高频词表中的次数大于等于设定次数的候选高频词。
[0100]
在一实施例中,文本处理装置60还包括添加模块603,其中:
[0101]
确定模块602,用于确定待处理文本所指示的业务类型;
[0102]
获取模块601,用于获取与业务类型相关的高频词;
[0103]
添加模块603,用于将与业务类型相关的高频词加入目标高频词表。
[0104]
在一实施例中,获取模块601具体用于:按照词间隔符对待处理文本进行分词处理,将得到的一个或多个词语作为待处理文本的分词信息;或者利用分词模型对待处理文本进行分词处理,将得到的一个或多个词语作为待处理文本的分词信息。
[0105]
在一实施例中,确定模块602还用于:若各第二语种的高频词占比中的最大高频词占比小于第二设定阈值,则将默认语种确定为待处理文本所对应的目标语种。
[0106]
可以理解的是,本技术实施例所描述的文本处理装置的各功能模块的功能可根据上述文本处理方法实施例中的相关方法具体实现,其具体实现过程可以参照上述方法实施例的相关描述,在此不再赘述。另外,对采用相同文本处理方法的有益效果描述,也在此不再赘述。
[0107]
请参见图7,是本技术实施例提供的一种计算机设备的结构示意图,该计算机设备70可以包括处理器701、存储器702、网络接口703和至少一个通信总线704。其中,处理器701
用于调度计算机程序,可以包括中央处理器、控制器、微处理器;存储器702用于存储计算机程序,可以包括高速随机存取存储器,非易失性存储器,例如磁盘存储器件、闪存器件;网络接口703提供数据通信功能,通信总线704负责连接各个通信元件。该计算机设备70对应于前文的文本处理设备100。
[0108]
其中,处理器701可以用于调用存储器中的计算机程序,以执行如下操作:
[0109]
获取待处理文本,确定待处理文本中各第一语种的字符占比;
[0110]
若存在字符占比大于或等于第一设定阈值的第一语种,则将字符占比大于或等于第一设定阈值的第一语种确定为待处理文本所对应的目标语种;
[0111]
若不存在字符占比大于或等于第一设定阈值的第一语种,则确定待处理文本中各第二语种的高频词占比;
[0112]
若各第二语种的高频词占比中的最大高频词占比大于或等于第二设定阈值,则将最大高频词占比对应的第二语种确定为待处理文本所对应的目标语种。
[0113]
在一实施例中,处理器701具体用于:获取待处理文本中每个字符对应的字符编码;根据各第一语种的字符编码区间、待处理文本中每个字符对应的字符编码以及待处理文本的字符总数,确定待处理文本中各第一语种的字符占比。
[0114]
在一实施例中,处理器701具体用于:确定各第二语种的目标高频词表,以及获取待处理文本的分词信息;根据各第二语种的目标高频词表和待处理文本的分词信息,确定待处理文本中各第二语种的高频词占比。
[0115]
在一实施例中,处理器701具体用于:针对任一第二语种,获取第二语种的候选高频词表,候选高频词表包括一个或多个候选高频词;将候选高频词表中的单字符候选高频词和共用候选高频词中的一种或者多种进行剔除,得到第二语种的目标高频词表,共用候选高频词是指出现在各第二语种的候选高频词表中的次数大于等于设定次数的候选高频词。
[0116]
在一实施例中,处理器701还用于:确定待处理文本所指示的业务类型;获取与业务类型相关的高频词;将与业务类型相关的高频词加入目标高频词表。
[0117]
在一实施例中,处理器701具体用于:按照词间隔符对待处理文本进行分词处理,将得到的一个或多个词语作为待处理文本的分词信息;或者利用分词模型对待处理文本进行分词处理,将得到的一个或多个词语作为待处理文本的分词信息。
[0118]
在一实施例中,处理器701还用于:若各第二语种的高频词占比中的最大高频词占比小于第二设定阈值,则将默认语种确定为待处理文本所对应的目标语种。
[0119]
具体实现中,本技术实施例中所描述的处理器701、存储器702及网络接口703可执行本技术实施例提供的一种文本处理方法中所描述的计算机设备的实现方式,也可执行本技术实施例提供的一种文本处理装置中所描述的实现方式以及有益效果,在此不再赘述。
[0120]
本技术实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行如本技术实施例所述的文本处理方法。其具体实现方式可参考前文描述,此处不再赘述。
[0121]
本技术实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取计算机指令,处理器执行计算机指令,使得计算机设备执
行如本技术实施例的文本处理方法。其具体实现方式可参考前文描述,此处不再赘述。
[0122]
需要说明的是,对于前述的各个方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某一些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本技术所必须的。
[0123]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read
‑
only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0124]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1