一种工业园区工厂用电负荷的超短期预测方法与流程
本发明属于配电网负荷预测技术领域,具体涉及一种基于灰色斜率关联度分析及optics聚类联合算法的工业园区工厂用电负荷的超短期预测方法。
背景技术:
目前用电负荷预测主要包含两种方法,一种是基于数据驱动的用电负荷预测方法,其首先对用电历史数据进行聚类分析,然后借助于各种先进的机器学习算法实现待预测日的用电负荷预测。另一种方法是基于模型驱动的用电负荷预测方法,其一般是根据设备用电固有规律构建用电负荷机理模型,然后基于待预测日的预测参数直接求解用电负荷。
对于用电负荷的超短期预测而言,目前主要采用的是基于数据驱动的方法。现有方法用于工业园区工厂用电负荷的超短期预测时,预测精度往往达不到要求。经分析发现,虽然工业园区工厂用电负荷存在较强的规律性,但受工业产能及电动机实时启停影响,用电负荷波动性大。传统的聚类方法主要集中在用电峰谷差等参数方面进行分析,不能适应工厂用电负荷这一特性。在预测算法上,多采用人工智能的方法,通过大量历史数据的训练来优化神经网络,达到预测目的。由于工厂用电负荷受影响因素众多,这一预测方法的有效性大打折扣。
技术实现要素:
本发明的目的是针对现有技术存在的上述问题,提供一种能够有效提高负荷预测精度的工业园区工厂用电负荷的超短期预测方法。
为实现以上目的,本发明的技术方案如下:
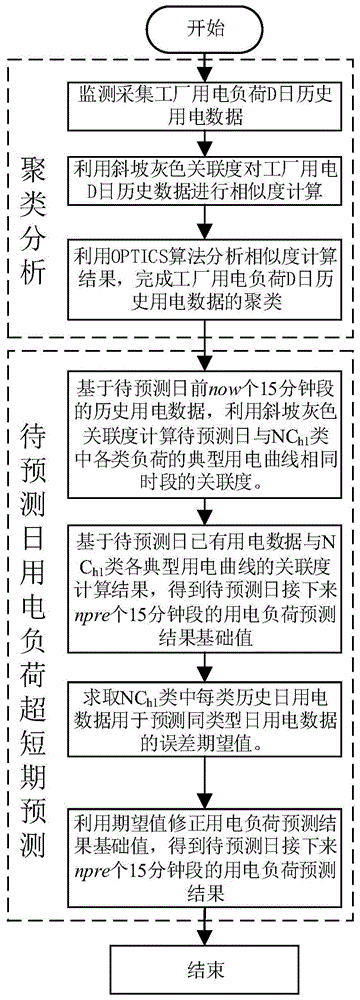
一种工业园区工厂用电负荷的超短期预测方法,依次包括以下步骤:
步骤a、先获取工业园区工厂用电负荷h1的d日历史用电数据,然后对这些历史用电数据进行聚类分析,得到nch1类负荷用电数据;
步骤b、基于待预测日前now个时段的已有用电数据,先计算其与步骤a得到的各类负荷的典型用电曲线相同时段的总关联度,然后根据总关联度计算结果确定待预测日接下来npre个时段的用电负荷预测基础值;
步骤c、采用各类负荷的历史日用电数据预测同类型日用电数据的误差期望值对步骤b得到的用电负荷预测基础值进行修正,得到待预测日接下来npre个时段的用电负荷预测结果。
所述步骤b采用灰色斜率关联度分析计算待预测日的已有数据与步骤a得到的各类负荷的典型用电曲线相同时段的总关联度:
sp=[ph1,tp,1,ph1,tp,2,ph1,tp,3,……,ph1,tp,96]
上式中,ρh1,pre,p为待预测日的已有数据与第p类负荷的典型用电曲线相同时段的总关联度,
所述步骤b采用以下公式计算得到待预测日接下来npre个时段的用电负荷预测基础值:
上式中,ph1,pre,t为待预测日第t个时段的用电负荷预测基础值,ph1,tp,t为第p类负荷的典型用电曲线在第t个时段的用电功率,ρh1,pre,kk为待预测日的已有数据与第kk类负荷的典型用电曲线相同时段的总关联度。
步骤c中,所述误差期望值为基于各类负荷用电数据中与待预测日最接近的xd天数据、计算得到的其与该类负荷的典型用电曲线在第now时段之后至now+npre个时段差值的期望值:
上式中,ep,t为第p类负荷的用电数据与其典型用电曲线在第t个时段差值的期望值。
步骤c中,所述待预测日接下来npre个时段的用电负荷预测结果由以下公式计算得到:
上式中,
步骤a中,所述对这些历史用电数据进行聚类依次包括以下步骤:
a1、利用灰色斜率关联度分析对历史用电数据进行相似度计算,得到第i日与第j日各时段用电数据的相似度;
a2、利用optics聚类算法分析步骤a1得到的相似度结果,得到nch1类负荷用电数据。
步骤a1中,所述第i日与第j日的各时段用电数据的相似度ρh1,i,j采用下列公式计算得到:
上式中,m为每日的总时段数,
所述步骤a2依次包括以下步骤:
步骤a2-1、设定最小领域点数minpts=0.1×d,对于第i日的历史用电数据,若满足j∈d,ρh1,i,j≥ρset的天数大于等于minpts,则将第i日设为核心对象,遍历所有d日历史用电数据,形成含有n个元素的核心对象集ω,其中,ρset为设定的相似度值;
步骤a2-2、按顺序挑选对象集ω的第k个元素o,将o加入结果队列m,k=1,2,…,n;
步骤a2-3、先计算元素o的核心距离cd(o),即将其它元素与o的相似度按从小到大排序排列得到的第minpts个相似度值,然后计算满足j∈d,ρh1,o,j≥0.8的元素j与元素o的可达距离rd(j,o):
上式中,inf表示未定义,ρh1,j,o为元素j与元素o的相似度;
步骤a2-4、将可达距离最小的元素q加入结果队列m中,如果q∈ω,则跳转至步骤a2-3;如果
步骤a2-5、循环重复步骤a2-2至步骤a2-4,直至完成对象集ω中所有元素的分析,得到结果队列m;
步骤a2-6、从结果队列m中取出某点,如果该点的可达距离不大于ρset,则该点属于当前聚类,否则进入步骤a2-7;
步骤a2-7、如果该点的核心距离大于ρset,则该点为噪声,可以忽略;否则该点属于新聚类,跳转至步骤a2-6;
步骤a2-8、循环执行步骤a2-6至步骤a2-7,完成结果队列m的遍历,最终将历史用电数据分为nch1类。
与现有技术相比,本发明的有益效果为:
1、本发明一种工业园区工厂用电负荷的超短期预测方法先获取工业园区工厂用电负荷h1的d日历史用电数据,并对这些历史用电数据进行聚类分析,得到nch1类负荷用电数据,再基于待预测日前now个时段的已有用电数据,计算其与得到的各类负荷的典型用电曲线相同时段的总关联度,然后根据总关联度计算结果确定待预测日接下来npre个时段的用电负荷预测基础值,最后采用各类负荷的历史日用电数据预测同类型日用电数据的误差期望值对得到的用电负荷预测基础值进行修正,即可得到待预测日接下来npre个时段的用电负荷预测结果,该设计通过对待预测日与各类历史用电负荷之间的关联度进行分析,并利用与待预测日最接近的历史日用电负荷特征对待预测日的负荷预测结果进行修正,有效避免了产能扩张等复杂因素给工厂用电负荷预测带来的难题,提高了工厂用电负荷超短期预测的精度。因此,本发明有效提高了工厂用电负荷超短期预测的精度。
2、本发明一种工业园区工厂用电负荷的超短期预测方法中对历史用电数据的聚类具体采用了:先利用灰色斜率关联度分析对历史用电数据进行相似度计算,得到第i日与第j日各时段用电数据的相似度,然后利用optics聚类算法分析得到的相似度结果,得到nch1类负荷用电数据,本设计采用色斜率关联度分析根据全天24小时用电曲线的波动进行关联度计算,可以充分利用曲线波动规律来提取工厂的用电特征,optics聚类算法基于关联度分析结果的分布密度完成聚类,改进了传统密度聚类算法对核心点距离输入参数过于敏感的缺点,两者联合可有效刻画高波动性工厂用电负荷的曲线特征,避免了传统方法仅利用峰谷差等个别参数带来的聚类效果不理想的问题,从而获得更佳的聚类效果。因此,本发明提升了对历史用电数据的聚类效果。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合具体实施方式以及附图对本发明作进一步详细的说明。
参见图1,一种工业园区工厂用电负荷的超短期预测方法,依次包括以下步骤:
步骤a、先获取工业园区工厂用电负荷h1的d日历史用电数据,然后对这些历史用电数据进行聚类分析,得到nch1类负荷用电数据;
步骤b、基于待预测日前now个时段的已有用电数据,先计算其与步骤a得到的各类负荷的典型用电曲线相同时段的总关联度,然后根据总关联度计算结果确定待预测日接下来npre个时段的用电负荷预测基础值;
步骤c、采用各类负荷的历史日用电数据预测同类型日用电数据的误差期望值对步骤b得到的用电负荷预测基础值进行修正,得到待预测日接下来npre个时段的用电负荷预测结果。
所述步骤b采用灰色斜率关联度分析计算待预测日的已有数据与步骤a得到的各类负荷的典型用电曲线相同时段的总关联度:
sp=[ph1,tp,1,ph1,tp,2,ph1,tp,3,……,ph1,tp,96]
上式中,ρh1,pre,p为待预测日的已有数据与第p类负荷的典型用电曲线相同时段的总关联度,
所述步骤b采用以下公式计算得到待预测日接下来npre个时段的用电负荷预测基础值:
上式中,ph1,pre,t为待预测日第t个时段的用电负荷预测基础值,ph1,tp,t为第p类负荷的典型用电曲线在第t个时段的用电功率,ρh1,pre,kk为待预测日的已有数据与第kk类负荷的典型用电曲线相同时段的总关联度。
步骤c中,所述误差期望值为基于各类负荷用电数据中与待预测日最接近的xd天数据、计算得到的其与该类负荷的典型用电曲线在第now时段之后至now+npre个时段差值的期望值:
上式中,ep,t为第p类负荷的用电数据与其典型用电曲线在第t个时段差值的期望值。
步骤c中,所述待预测日接下来npre个时段的用电负荷预测结果由以下公式计算得到:
上式中,
步骤a中,所述对这些历史用电数据进行聚类依次包括以下步骤:
a1、利用灰色斜率关联度分析对历史用电数据进行相似度计算,得到第i日与第j日各时段用电数据的相似度;
a2、利用optics聚类算法分析步骤a1得到的相似度结果,得到nch1类负荷用电数据。
步骤a1中,所述第i日与第j日的各时段用电数据的相似度ρh1,i,j采用下列公式计算得到:
上式中,m为每日的总时段数,
所述步骤a2依次包括以下步骤:
步骤a2-1、设定最小领域点数minpts=0.1×d,对于第i日的历史用电数据,若满足j∈d,ρh1,i,j≥ρset的天数大于等于minpts,则将第i日设为核心对象,遍历所有d日历史用电数据,形成含有n个元素的核心对象集ω,其中,ρset为设定的相似度值;
步骤a2-2、按顺序挑选对象集ω的第k个元素o,将o加入结果队列m,k=1,2,…,n;
步骤a2-3、先计算元素o的核心距离cd(o),即将其它元素与o的相似度按从小到大排序排列得到的第minpts个相似度值,然后计算满足j∈d,ρh1,o,j≥0.8的元素j与元素o的可达距离rd(j,o):
上式中,inf表示未定义,ρh1,j,o为元素j与元素o的相似度;
步骤a2-4、将可达距离最小的元素q加入结果队列m中,如果q∈ω,则跳转至步骤a2-3;如果
步骤a2-5、循环重复步骤a2-2至步骤a2-4,直至完成对象集ω中所有元素的分析,得到结果队列m;
步骤a2-6、从结果队列m中取出某点,如果该点的可达距离不大于ρset,则该点属于当前聚类,否则进入步骤a2-7;
步骤a2-7、如果该点的核心距离大于ρset,则该点为噪声,可以忽略;否则该点属于新聚类,跳转至步骤a2-6;
步骤a2-8、循环执行步骤a2-6至步骤a2-7,完成结果队列m的遍历,最终将历史用电数据分为nch1类。
本发明的原理说明如下:
工业园区工厂用电负荷具有波动性大、受影响因素众多等特点,传统基于数据驱动的工厂用电负荷超短期预测精度达不到现场要求。为此,本发明提出一种基于灰色斜率关联度分析及optics聚类算法的工业园区工厂用电负荷的超短期预测方法,该方法首先利用利用灰色斜率关联度对工厂用电负荷的历史用电数据进行相似度分析,然后利用optics算法对相似度结果进行分析,实现对工厂用电负荷历史用电数据的聚类;随后基于待预测日已有的用电数据、利用灰色斜率关联度计算待预测日与所有聚类中各类负荷的典型用电曲线相同时段的关联度,最终利用加权求和及期望值修正的方法,实现了待预测日接下来数个时间段的用电负荷超短期的预测。
实施例1:
参见图1,一种工业园区工厂用电负荷的超短期预测方法,依次按照以下步骤进行:
1、通过智能电表等用电监测设备获取工业园区工厂用电负荷h1的d日历史用电数据,d取90,用电监测设备每15分钟采集一次用电量,每天形成96个时段的用电数据;
2、利用灰色斜率关联度分析对历史用电数据进行相似度计算,得到第i日与第j日各时段用电数据的相似度ρh1,i,j:
上式中,m为每日的总时段数,
3、利用optics聚类算法分析步骤2得到的相似度结果,实现对工厂用电负荷d日历史用电数据的聚类,得到nch1类负荷用电数据,具体为:
3-1、设定最小领域点数minpts=0.1×d,对于第i日的历史用电数据,若满足j∈d,ρh1,i,j≥ρset的天数大于等于minpts,则将第i日设为核心对象,遍历所有d日历史用电数据,形成含有n个元素的核心对象集ω,其中,ρset为设定的相似度值,不失一般性,ρset取0.8;
3-2、按顺序挑选对象集ω的第k个元素o,将o加入结果队列m,k=1,2,…,n;
3-3、先计算元素o的核心距离cd(o),即在任意元素o的邻域内,按与元素o的相似度结果从小到大排序,元素o与其第minpts近邻点的相似度定义为核心距离,然后计算满足j∈d,ρh1,o,j≥0.8的元素j与元素o的可达距离rd(j,o):
上式中,inf表示未定义,ρh1,j,o为元素j与元素o的相似度;
3-4、将可达距离最小的元素q加入结果队列m中,如果q∈ω,则跳转至步骤3-3;如果
3-5、循环重复步骤3-2至步骤3-4,直至完成对象集ω中所有元素的分析,得到结果队列m;
3-6、从结果队列m中取出某点,如果该点的可达距离不大于ρset,则该点属于当前聚类,否则进入步骤3-7;
3-7、如果该点的核心距离大于ρset,则该点为噪声,可以忽略;否则该点属于新聚类,跳转至步骤3-6;
3-8、循环执行步骤3-6至步骤3-7,完成结果队列m的遍历,最终将历史用电数据分为nch1类,得到nch1类负荷用电数据;
4、基于待预测日前now个时段的已有用电数据,先采用灰色斜率关联度分析计算待预测日的已有数据与得到的各类负荷的典型用电曲线相同时段的总关联度:
sp=[ph1,tp,1,ph1,tp,2,ph1,tp,3,……,ph1,tp,96]
上式中,ρh1,pre,p为待预测日的已有数据与第p类负荷的典型用电曲线相同时段的总关联度,
5、根据关联度计算结果、采用以下公式确定待预测日接下来npre个时段的用电负荷预测基础值:
上式中,ph1,pre,t为待预测日第t个时段的用电负荷预测基础值,ph1,tp,t为第p类负荷的典型用电曲线在第t个时段的用电功率,ρh1,pre,kk为待预测日的已有数据与第kk类负荷的典型用电曲线相同时段的总关联度;
6、基于各类负荷用电数据中与待预测日最接近的xd天数据、计算得到的其与该类负荷的典型用电曲线在第now时段之后至now+npre个时段差值的期望值:
上式中,ep,t为第p类负荷的用电数据与其典型用电曲线在第t个时段差值的期望值,xd取3;
7、采用上述期望值对步骤5得到的用电负荷预测基础值进行修正,确定待预测日接下来npre个时段的用电负荷预测结果:
上式中,
- 还没有人留言评论。精彩留言会获得点赞!