一种基于文本聚类的恶意投诉识别方法及系统与流程
1.本发明涉及人工智能与软件系统技术领域,尤其是一种基于文本聚类的恶意投诉识别方法及系统。
背景技术:
2.近年来,针对银行、支付公司、消金公司、互金公司、保险公司等机构(简称金融机构)的恶意投诉代理,已经形成一个“黑色产业”。接单、签约、“维权”、分成,团火作业、分工明确。金融机构不堪其扰,一方面恶意投诉越来越多,另一方面银行内部确实有监管考核压力。恶意投诉的最终目的,就是恶意逃废债。近年来,金融领域的逃废债行为,使得金融行业不良贷款率不断攀升,造成部分中小金融机构以及金融从业机构的风险不断积聚。
3.当前金融行业关于恶意投诉的识别方法比较少。通过深入研究恶意投诉用户的行为模式,发现恶意投诉用户一般都采用黑产中介提供的投诉模板,集中在网络渠道或者监管线下渠道进行投诉。网络投诉渠道如:黑猫投诉、聚投诉等。
4.基于此,本文提出了一种基于文本聚类的恶意投诉识别方法及系统,综合应用爬虫技术、自然语言处理技术以及聚类算法技术,通过网络投诉渠道爬虫投诉信息内容,基于本文内容构建lda主题模型进行自然语言处理,并采用密度聚类方法dbscan对所有投诉信息进行分类,最终识别恶意投诉。
技术实现要素:
5.针对上述现有技术中存在的不足,本发明的目的在于提供一种基于文本聚类的恶意投诉识别方法及系统,解决目前无法快速识别恶意投诉的问题。
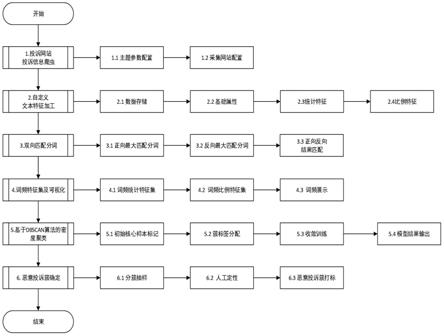
6.为解决上述问题,本发明公开了一种基于文本聚类的恶意投诉识别方法,包括以下步骤:
7.步骤1:通过界面配置指定投诉网站以及主题参数,后台通过爬虫技术采集满足一定条件的投诉内容;
8.步骤2:将爬虫的投诉信息存储在关系数据库中,并进行用户自定义的文本特征加工;假设采集了n篇投诉内容;主键字段名为id,定义为自增主键,取值为1,2,......,n;投诉信息集合记作c={c1,c2,......,c
n
},其中c
i
表示第i篇投诉的内容,i=1,2,......,n;假设文本加工的特征集为x1,自定义文本特征有m个特征,记作
9.步骤3:本文中假定投诉描述主要为中文,本文采取中文分词的方法对每篇投诉内容进行分词;中文分词将每篇投诉描述切分成一个一个单独的词;通过双向匹配分词法对投诉描述内容进行分词处理;双向最大匹配法是一种基于词典的分词方法,基于词典的分词方法是按照一定策略将待切分的汉字串与一个词典库中的词条进行匹配,若在词典中找到某个字符串,则匹配成功;对于采集的n篇投诉舆情,假设将第i篇投诉分割成k
i
个词语组成的向量,记作成的向量,记作对于投诉信息集c,切词之后形成的投诉信息分
割集记作割集记作割集记作其中i=1,2,......,n;
10.步骤4:对步骤3的分词结果进行词频统计,即统计全量投诉信息中每个词出现的次数,并形成词云图;统计每篇投诉信息每个词出现的次数,以及在该篇投诉信息内容中的占比,并形成词频统计特征集和词频比例特征集
11.步骤5:合并上述加工的文本特征集x1、词频统计特征集和词频比例特征集合计m+2nt个特征变量,记作聚类特征集计m+2nt个特征变量,记作聚类特征集计m+2nt个特征变量,记作聚类特征集
12.将作为dbscan算法的入参,对每篇投诉内容进行分类,假设模型输出结果的分类变量为y,对于第i篇投诉内容的聚类结果为y
i
,y={y1,y2,......,y
n
},i=1,2,......,n;
13.步骤6:对于dbscan算法的聚类结果进行分层抽样,基于抽样结果进行人工“是否恶意投诉”的打标判断,最终通过每族中恶意投诉的比例来确认恶意投诉簇的标签,修正恶意投诉模型的聚类结果。
14.作为优选:步骤1具体包括如下步骤:
15.步骤1.1主题参数配置:主题参数模块主要设置爬虫的条件内容,包括监控主题、主题编码、采集频率、关键词配置4个参数;监控主题为本次爬虫需要指定的主题内容;主题编码为监控主题的唯一主键,由数字、字符及下划线组成;采集频率指定爬虫的采集条件,需要设置信息采集的间隔时长;关键词配置指定爬虫内容的过滤条件,满足该条件的内容才进行采集;
16.步骤1.2采集网站配置:采集网站模块通过界面的方式设置需要爬虫的网站,需要指定网站名称和网站地址;同时可添加多个采集信息源。
17.作为优选:步骤2具体包括如下步骤:
18.步骤2.1数据存储:将爬虫来的投诉信息存储在关系数据库mysql中,创建投诉信息数据表,以投诉编号为主键;
19.步骤2.2基础属性:基础属性指的是投诉信息关联的基础属性字段;
20.步骤2.3统计特征:统计特征指的是统计投诉信息内容中满足某些条件的文本数量;
21.步骤2.4比例特征:比例特征指的是统计投诉信息内容中满足某些条件的文本数量占比。
22.作为优选:步骤3具体包括如下步骤:
23.步骤3.1正向最大匹配分词:所谓正向,就是从字符串左边正向扫描,取出子串与词典进行匹配;正向最大匹配算法主要分为三个步骤:第一,对于第i篇(i=1,2,......,n)投诉描述,从左向右取该篇投诉中max个字符作为匹配字段,max为词典库中最长词条个数;第二,将这个切分的匹配字段在词典库中查找并进行匹配;若匹配成功,则将这个匹配字段作为一个词切分出来;若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配;第三,重复以上过程,直到切分出所有词为止;
24.步骤3.2反向最大匹配分词:该算法是正向最大匹配的逆向思维,所谓反向,就是从字符串右边反向扫描,取出子串与词典进行匹配;反向最大匹配算法主要分为三个步骤:第一,对于第i篇(i=1,2,......,n)投诉描述,从右向左取该篇投诉中max个字符作为匹配字段,max为词典库中最长词条个数;第二,将这个切分的匹配字段在词典库中查找并进行匹配;若匹配成功,则将这个匹配字段作为一个词切分出来;若匹配不成功,则将这个匹配字段的最前一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配;第三,重复以上过程,直到被切分字符串长度为0,即切分出所有词为止;
25.步骤3.3正反向结果匹配:双向最大匹配是将正向最大匹配得到的分词结果和逆向最大匹配得到的结果进行比较,决定正确的分词方法;正反向结果匹配,主要分为2个步骤:第一,如果正反向分词结果词数不同,则取分词数量较少的那个;第二,如果分词结果词数相同;若分词结果相同,可取任意一个;若分词结果不同,取其中单字较少的那个。
26.作为优选:步骤4具体包括如下步骤:
27.步骤4.1词频统计特征集:对投诉信息分割集进行去重统计,即每个词语只保留一次、保留的词语间两两不相同,形成的唯一词汇集记作假设中有t个元素,记作统计投诉信息分割集中每篇投诉信息分割集对应于中每个元素的出现次数,对于第i篇投诉信息分割集记对应的词频统计特征集为记对应的词频统计特征集为其中表示中包含词语s
t
的个数,i=1,2,......,n,则投诉信息分割集对应的词频统计特征集对应的词频统计特征集
28.步骤4.2词频比例特征集:统计投诉信息分割集中每篇投诉信息分割集对应于中每个元素的出现比例,定义为对应于中每个元素出现的次数除该篇投诉信息分割集的长度,即分割集中包含词语的个数;对于第i篇投诉信息分割集记对应的词频比例特征集为集为其中表示中包含词语s
t
的比例,i=1,2,......,n,则投诉信息分割集对应的词频比例特征集对应的词频比例特征集
29.步骤4.3词频展示:词云图,是对文本中出现频率较高的词汇予以视觉化的展现,因此会过滤掉大量的低频低质的文本信息,使得浏览者通过词云图直观的领略文本的主旨;基于全量投诉信息,统计中各个元素出现的次数,对于中的第j个元素s
j
,假设全量投诉信息中出现的次数为p
j
,j=1,2,......,t;记全量投诉信息的词频集为则采用python的词云展示包wordcount,可直接构建的词云图。
30.作为优选:步骤5具体包括如下步骤:
31.步骤5.1初始核心样本标记:首先设置dbscan算法的两个核心参数eps和min_sample,其中eps表示∈
‑
邻域的距离阈值,取值为浮点类型;min_samples表示样本点要成为核心对象所需要的∈
‑
邻域的样本数阈值,取值为正整数;首选任意选取一个点,然后找
到与这个点距离小于等于eps的所有的点;
32.步骤5.2簇标签分配:如果距起始点的距离在eps之内的数据点个数小于min_samples,那么这个点被标记为噪声;如果距离在eps之内的数据点个数大min_samples,则这个点被标记为核心样本,并被分配一个新的簇标签;然后访问该点在距离eps以内的所有邻居;如果它们还没有被分配一个簇,那么就将刚刚创建的新的簇标签分配给它们;如果它们是核心样本,那么就依次访问其邻居,以此类推;簇逐渐增大,直到在簇的eps距离内没有更多的核心样本为止;
33.步骤5.3收敛训练:选取另一个尚未被访问过的点,并重复初始核心样本标记和簇标签分配的过程,直到所有的点都被标记完成为止;
34.步骤5.4模型结果输出:dbscan模型将输出每个点所属集群的标签;对于第i篇投诉内容的聚类结果y
i
,y
i
=
‑
1或正整数,
‑
1代表噪声点,其余正整数表示当前点所属集群的标签编号,其中i=1,2,......,n。
35.作为优选:步骤6具体包括如下步骤:
36.步骤6.1分簇抽样:对于dbscan算法的输出结果y,计算其所有向量元素的最大值,记作d;那么dbscan算法聚类结果有d类,假设第r类的聚类样本标签为m
r
,其中包含u
r
个元素,其中n=u1+u2+......+u
d
;r=1,2,......,d;则投诉信息集c={c1,c2,......,c
n
},聚类之后的结果投诉信息聚类集之后的结果投诉信息聚类集指定抽样比例h,0<h<1,对投诉信息聚类集进行分层抽样,形成投诉信息聚类抽样集进行分层抽样,形成投诉信息聚类抽样集其中包含的元素个数为nh个;
37.步骤6.2人工定性:对投诉信息聚类抽样集中每个元素进行标记,其中1表示恶意投诉,0表示普通投诉;记打标之后的投诉信息聚类抽样打标集为投诉,0表示普通投诉;记打标之后的投诉信息聚类抽样打标集为投诉,0表示普通投诉;记打标之后的投诉信息聚类抽样打标集为其中或0,r=1,2,......,d;i=1,2,......,nh;统计中每一簇中恶意投诉的比例,即对于第r簇聚类结果m
r
计算恶意投诉人数为该簇中恶意投诉比例记作该簇中恶意投诉比例记作记投诉信息恶意投诉比例集为息恶意投诉比例集为
38.步骤6.3恶意投诉簇打标:计算中中的最大值,记作该最大值对应的簇m
et
则为恶意投诉簇,该簇里面的所有投诉均为恶意投诉;其余簇的元素合并成正常投诉簇并记作m
ot
;则投诉信息集c={c1,c2,......,c
n
}对应的恶意投诉模型分类结果为型分类结果为其中u
et
+u
ot
=n;至此,所有的恶意投诉就被识别出来了。
39.为解决上述问题,本发明还公开了一种基于文本聚类的恶意投诉识别系统,包括
投诉网站投诉信息爬虫模块、自定义文本特征加工模块、双向匹配分词模块、词频特征集及可视化模块、基于dbscan算法的密度聚类模块和恶意投诉簇确定模块;通过界面配置指定投诉网站以及主题参数,后台通过爬虫技术采集满足一定条件的投诉内容;
40.投诉网站投诉信息爬虫模块,用于通过界面配置指定投诉网站以及主题参数,后台通过爬虫技术采集满足一定条件的投诉内容;
41.自定义文本特征加工模块,用于将爬虫的投诉信息存储在关系数据库中,并进行用户自定义的文本特征加工;假设采集了n篇投诉内容;主键字段名为id,定义为自增主键,取值为1,2,......,n;投诉信息集合记作c={c1,c2,......,c
n
},其中c
i
表示第i篇投诉的内容,i=1,2,......,n;假设文本加工的特征集为x1,自定义文本特征有m个特征,记作
42.双向匹配分词模块,用于本文中假定投诉描述主要为中文,本文采取中文分词的方法对每篇投诉内容进行分词;中文分词将每篇投诉描述切分成一个一个单独的词;通过双向匹配分词法对投诉描述内容进行分词处理;双向最大匹配法是一种基于词典的分词方法,基于词典的分词方法是按照一定策略将待切分的汉字串与一个词典库中的词条进行匹配,若在词典中找到某个字符串,则匹配成功;对于采集的n篇投诉舆情,假设将第i篇投诉分割成k
i
个词语组成的向量,记作个词语组成的向量,记作对于投诉信息集c,切词之后形成的投诉信息分割集记作形成的投诉信息分割集记作形成的投诉信息分割集记作其中i=1,2,...,n;
43.词频特征集及可视化模块,用于对于步骤3的分词结果进行词频统计,即统计全量投诉信息中每个词出现的次数,并形成词云图;统计每篇投诉信息每个词出现的次数,以及在该篇投诉信息内容中的占比,并形成词频统计特征集和词频比例特征集
44.基于dbscan算法的密度聚类模块,用于合并上述加工的文本特征集x1、词频统计特征集和词频比例特征集合计m+2nt个特征变量,记作聚类特征集合计m+2nt个特征变量,记作聚类特征集合计m+2nt个特征变量,记作聚类特征集
45.将作为dbscan算法的入参,对每篇投诉内容进行分类,假设模型输出结果的分类变量为y,对于第i篇投诉内容的聚类结果为y
i
,y={y1,y2,......,y
n
},i=1,2,......,n;
46.恶意投诉簇确定模块,用于对于dbscan算法的聚类结果进行分层抽样,基于抽样结果进行人工“是否恶意投诉”的打标判断,最终通过每族中恶意投诉的比例来确认恶意投诉簇的标签,修正恶意投诉模型的聚类结果。
47.作为优选:投诉网站投诉信息爬虫模块包括主题参数配置和采集网站配置2个子模块;
48.主题参数配置子模块,用于主题参数模块主要设置爬虫的条件内容,包括监控主题、主题编码、采集频率、关键词配置4个参数;监控主题为本次爬虫需要指定的主题内容;主题编码为监控主题的唯一主键,由数字、字符及下划线组成;采集频率指定爬虫的采集条件,需要设置信息采集的间隔时长;关键词配置指定爬虫内容的过滤条件,满足该条件的内
容才进行采集;
49.采集网站配置子模块,用于采集网站模块通过界面的方式设置需要爬虫的网站,需要指定网站名称和网站地址;同时可添加多个采集信息源。
50.作为优选:自定义文本特征加工模块包括数据存储、基础属性、统计特征和比例特征4个子模块;
51.数据存储子模块,用于将爬虫来的投诉信息存储在关系数据库mysql中,创建投诉信息数据表,以投诉编号为主键;
52.基础属性子模块,用于基础属性指的是投诉信息关联的基础属性字段;
53.统计特征子模块,用于统计特征指的是统计投诉信息内容中满足某些条件的文本数量;
54.比例特征子模块,用于比例特征指的是统计投诉信息内容中满足某些条件的文本数量占比。
55.由于采用上述技术方案,本发明有着如下有益效果:
56.1、本系统综合应用自然语言技术和无监督学习技术,构建了基于投诉网站投诉信息爬虫、自定义文本特征加工、双向匹配分词、词频特征集及可视化、基于dbscan算法的密度聚类、恶意投诉簇确定6大闭环化流程模块,实现对恶意投诉内容的自动识别。
57.2、本文巧妙的将自定义文本特征加工集、词频统计特征集以及词频比例特征集合并作为dbscan密度聚类算法的特征工厂,最大程度的挖掘了文本内容中的显著信息,极大的提升了恶意投诉识别模型的准确率。
58.3、本文采用dbscan密度聚类算法对投诉信息进行聚类分析,不仅不需要先验地设置簇的个数,而且划分具有复杂形状的簇,还可以找出不属于任何簇的点,大大提升了聚类的效果;同时,采用分簇分层抽样的方式进行标记,极大的校准了模型结果。
附图说明
59.图1是基于文本聚类的恶意投诉识别系统框架图;
60.图2是爬虫配置系统图示。
具体实施方式
61.以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
62.为更具体说明此方法,以下提供一个识别“聚投诉”中“新网银行”恶意投诉用户识别案例。
63.步骤1:投诉网站投诉信息爬虫。通过界面配置指定投诉网站,以及主题参数,后台通过爬虫技术采集满足一定条件的投诉内容。
64.步骤1.1:主题参数配置。主题参数模块主要设置爬虫的条件内容,包括监控主题、主题编码、采集频率、关键词配置4个参数。监控主题设置为“新网银行恶意投诉识别”;主题编码为监控主题的唯一主键,设置为“xwbank_jts_eyts”;采集频率指定爬虫的采集条件,配置为每隔5分钟采集;关键词配置指定爬虫内容的过滤条件,配置为“新网银行&&投诉”。
65.步骤1.2:采集网站配置。采集网站模块通过界面的方式设置需要爬虫的网站,配
置网站名称为“聚投诉”和网站地址“https://ts.21cn.com/”。
66.步骤2:自定义文本特征加工。将爬虫的投诉信息存储在关系数据库中,并进行用户自定义的文本特征加工。假设采集了n篇投诉内容;主键字段名为id,取值为自增主键,取值为1,2,......,n。投诉信息集合记作c={c1,c2,......,c
n
},其中c
i
表示第i篇投诉的内容,i=1,2,......,n。假设文本加工的特征集为x1,自定义文本特征有m个特征,记作该模块包括数据存储、基础属性、统计特征和比例特征4个子模块。
67.步骤2.1:数据存储。将爬虫来的投诉信息存储在关系数据库mysql中,创建投诉信息数据表,以投诉编号为主键,包含:投诉时间、投诉者姓名、爬虫时间、投诉对象、投诉问题、相关方、涉诉金额、投诉描述等内容。
68.步骤2.2:基础属性。基础信息指的是投诉信息关联的基础属性字段,如投诉时点、涉诉金额、投诉诉求、投诉进度等内容。
69.步骤2.3:统计特征。统计特征指的是统计投诉信息内容中满足某些条件的文本数量。如:统计投诉描述的总字数、统计投诉描述中包含“投诉”的字数、统计投诉描述中出现“举报”的字数、统计投诉进度为“跟进中”的数量、统计投诉回复条数等。
70.步骤2.4:比例特征。比例特征指的是统计投诉信息内容中满足某些条件的文本数量占比。如:统计投诉描述中包含“投诉”的字数在全文中的比例、统计投诉描述中出现“举报”的字数在全文中的比例等。
71.步骤3:双向匹配分词。中文分词将每篇投诉描述切分成一个一个单独的词,词是最小的、能独立活动的、有意义的语言成分。为深度挖掘投诉信息之间的关联性,通过双向匹配分词法对投诉描述内容进行分词处理。双向最大匹配法是一种基于词典的分词方法。基于词典的分词方法是按照一定策略将待切分的汉字串与一个词典库中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。对于采集的n篇投诉舆情,假设将第i篇投诉分割成k
i
个词语组成的向量,记作个词语组成的向量,记作对于投诉信息集c,切词之后形成的投诉信息分割集记作的投诉信息分割集记作的投诉信息分割集记作其中i=1,2,......,n。
72.步骤3.1:正向最大匹配分词。所谓正向,就是从字符串左边正向扫描,取出子串与词典进行匹配。正向最大匹配算法主要分为三个步骤:第一,对于第i篇(i=1,2,......,n)投诉描述,从左向右取该篇投诉中max个字符作为匹配字段,max为词典库中最长词条个数。第二,将这个切分的匹配字段在词典库中查找并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配。第三,重复以上过程,直到切分出所有词为止。
73.步骤3.2:反向最大匹配分词。该算法是正向最大匹配的逆向思维。所谓反向,就是从字符串右边反向扫描,取出子串与词典进行匹配。反向最大匹配算法主要分为三个步骤:第一,对于第i篇(i=1,2,......,n)投诉描述,从右向左取该篇投诉中max个字符作为匹配字段,max为词典库中最长词条个数。第二,将这个切分的匹配字段在词典库中查找并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最前一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配。第三,重复以上
过程,直到被切分字符串长度为0,即切分出所有词为止。
74.步骤3.3正反向结果匹配。双向最大匹配是将正向最大匹配得到的分词结果和逆向最大匹配得到的结果进行比较,决定正确的分词方法。sunm.s.和benjamin k.t.(1995)的研究表明:90%左右的中文切分字符串,正向最大匹配法和逆向最大匹配法完全重合且正确,其余10%存在差异。正反向结果匹配,主要分为2个步骤:第一,如果正反向分词结果词数不同,则取分词数量较少的那个。第二,如果分词结果词数相同。若分词结果相同,可取任意一个;若分词结果不同,取其中单字较少的那个。
75.步骤4:词频特征集及可视化。对于步骤3的分词结果进行词频统计,即统计全量投诉信息中每个词出现的次数,并形成词云图,以便直观的观察投诉内容的分布。统计每篇投诉信息每个词出现的次数,以及在该篇投诉信息内容中的占比,并形成词频统计特征集和词频比例特征集
76.步骤4.1:词频统计特征集。对投诉信息分割集进行去重统计,即每个词语只保留一次、保留的词语问两两不相同,形成的唯一词汇集记作假设中有t个元素,记作统计投诉信息分割集中每篇投诉信息分割集对应于中每个元素的出现次数,对于第i篇投诉信息分割集记对应的词频统计特征集为记对应的词频统计特征集为其中表示中包含词语s
t
的个数,i=1,2,......,n。则投诉信息分割集对应的词频统计特征集。对应的词频统计特征集。
77.步骤4.2:词频比例特征集。统计投诉信息分割集中每篇投诉信息分割集对应于中每个元素的出现比例,定义为对应于中每个元素出现的次数除该篇投诉信息分割集的长度(即分割集中包含词语的个数)。对于第i篇投诉信息分割集记对应的词频比例特征集为集为其中表示中包含词语s
t
的比例,i=1,2,......,n。则投诉信息分割集对应的词频比例特征集对应的词频比例特征集
78.步骤4.3:词频展示。词云图,是对文本中出现频率较高的词汇予以视觉化的展现,因此会过滤掉大量的低频低质的文本信息,使得浏览者通过词云图直观的领略文本的主旨。基于全量投诉信息,统计中各个元素出现的次数,对于中的第j个元素s
j
,假设全量投诉信息中出现的次数为p
j
,j=1,2,......,t。记全量投诉信息的词频集为则采用python的词云展示包wordcount,可直接构建的词云图。
79.步骤5:基于dbscan算法的密度聚类。dbscan,即具有噪声的基于密度的聚类方法,是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中可以发现任意形状的簇类。合并上述加工的文本特征集x1、词频统计特征集和词频比例特征集合计m+2nt个特征变量,记作聚类特征集
80.将作为dbscan算法的入参,对每篇投诉内容进行分类,假设模型输出结果的分类变量为y,对于第i篇投诉内容的聚类结果为y
i
,y={y1,y2,......,y
n
},i=1,2,......,n。
81.步骤5.1:初始核心样本标记。首先设置dbscan算法的两个核心参数eps和min_sample,其中eps表示∈
‑
邻域的距离阈值,设置eps=0.5;min_sample表示样本点要成为核心对象所需要的∈
‑
邻域的样本数阈值,设置min_sample=5。首选任意选取一个点,然后找到与这个点距离小于等于eps的所有的点。
82.步骤5.2:簇标签分配。如果距起始点的距离在eps之内的数据点个数小于min_samples,那么这个点被标记为噪声。如果距离在eps之内的数据点个数大min_samples,则这个点被标记为核心样本,并被分配一个新的簇标签。然后访问该点的所有邻居(在距离eps以内)。如果它们还没有被分配一个簇,那么就将刚刚创建的新的簇标签分配给它们。如果它们是核心样本,那么就依次访问其邻居,以此类推。簇逐渐增大,直到在簇的eps距离内没有更多的核心样本为止。
83.步骤5.3:收敛训练。选取另一个尚未被访问过的点,并重复初始核心样本标记和簇标签分配的过程,直到所有的点都被标记完成为止。
84.步骤5.4:模型结果输出。dbscan模型将输出每个点所属集群的标签。对于第i篇投诉内容的聚类结果y
i
,y
i
=
‑
1或正整数,
‑
1代表噪声点,其余正整数表示当前点所属集群的标签编号,其中i=1,2,......,n。
85.步骤6:恶意投诉簇确定。对于dbscan算法的聚类结果进行分层抽样,基于抽样结果进行人工“是否恶意投诉”的打标判断,最终通过每族中恶意投诉的比例来确认恶意投诉簇的标签,修正恶意投诉模型的聚类结果。
86.步骤6.1:分簇抽样。对于dbscan算法的输出结果y,计算其所有向量元素的最大值,记作d。那么dbscan算法聚类结果有d类,假设第r类的聚类样本标签为m
r
,其中包含u
r
个元素,其中n=u1+u2+......+u
d
;r=1,2,......,d。则投诉信息集c={c1,c2,......,c
n
},聚类之后的结果投诉信息聚类集类之后的结果投诉信息聚类集指定抽样比例h,0<h<1,对投诉信息聚类集进行分层抽样,形成投诉信息聚类抽样集进行分层抽样,形成投诉信息聚类抽样集其中包含的元素个数为nh个。
87.步骤6.2:人工定性。对投诉信息聚类抽样集中的每个元素进行标记,其中1表示恶意投诉,0表示普通投诉。记打标之后的投诉信息聚类抽样打标集为恶意投诉,0表示普通投诉。记打标之后的投诉信息聚类抽样打标集为恶意投诉,0表示普通投诉。记打标之后的投诉信息聚类抽样打标集为
88.其中或0,r=1,2,......,d;i
=1,2,......,nh。统计中每一簇中恶意投诉的比例,即对于第r簇聚类结果m
r
计算恶意投诉人数为该簇中恶意投诉比例记作该簇中恶意投诉比例记作记投诉信息恶意投诉比例集为诉信息恶意投诉比例集为
89.步骤6.3:恶意投诉簇打标。计算中中的最大值,记作该最大值对应的簇m
et
则为恶意投诉簇,该簇里面的所有投诉均为恶意投诉;其余簇的元素合并成正常投诉簇并记作m
ot
。则投诉信息集c={c1,c2,......,c
n
}对应的恶意投诉模型分类结果为模型分类结果为其中u
et
+u
ot
=n。至此,所有的恶意投诉就被识别出来了。
90.以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1