一种用于目标检测的多示例主动学习方法
本发明属于主动学习与计算机视觉技术领域,具体涉及一种用于目标检测的多示例主动学习方法,其通过计算未标注样本的不确定性挑选需要学习的样本,实现利用少量已标注样本达到较高性能的目标检测。
背景技术:
深度神经网络例如卷积神经网络(cnn)已经在计算机视觉、目标检测中取得了巨大成就,其很大程度上依赖于网络在大数据集的训练。然而,在有些目标检测任务中,标注大数据集的目标边界框耗时费力、成本昂贵且不切实际。现有技术中多采用主动学习的方法来解决这一问题。
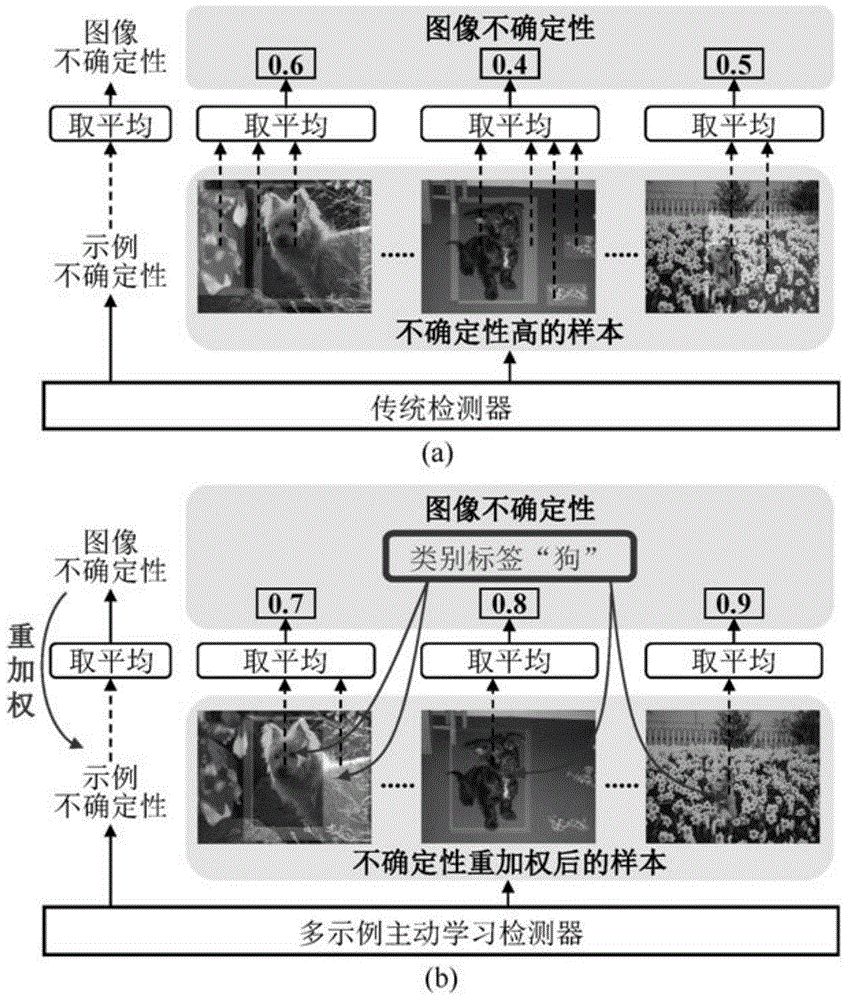
主动学习的关键思想是:如果允许一个机器学习算法选择它想要学习的数据,那么它就可以通过较少的训练样本来达到更好的性能。主动目标检测的目的是选择信息量最大的图像进行检测器训练,但是,目前的主动学习方法大多通过简单地将示例或像素的不确定性综合或平均为图像的不确定性来解决该问题。这样会忽略已标注集和未标注集之间存在的分布偏差,以及忽略目标检测中负示例所产生的较大的不平衡,导致背景中存在大量噪声高的示例,并干扰图像不确定性的学习,如图1中的(a)所示。
因此,亟需提供一种专门适用于目标检测的主动学习方法,其能够有效利用无标注数据,提高相等已标注数据量下神经网络对图像的检测精度。
技术实现要素:
为了克服上述问题,本发明人进行了锐意研究,设计出一种用于目标检测的多示例主动学习方法,所述方法利用插入在检测网络顶部的两个对抗性示例分类器来学习未标注示例的不确定性,通过最大化两个示例分类器的预测差异预测示例的不确定性,通过最小化分类器的差异学习特征,从而减少已标注和未标注示例之间的分布偏差。然后,引入了一个与示例分类器并列的多示例学习模块,将每个未标注的图像视为一个示例包,并通过评估各个图像之间的示例外观一致性来进行示例不确定性的重加权。通过反复进行示例不确定性的学习和重加权缩小示例级观察和图像级评估之间的差距。本发明提供的方法能够有效利用无标注数据,提高了相等已标注数据量下神经网络对图像的检测精度,从而完成了本发明。
具体来说,本发明的目的在于提供以下方面:
第一方面,提供一种用于目标检测的多示例主动学习方法,所述方法包括训练部分和测试部分,其中,所述训练部分包括以下步骤:
步骤1,建立用于目标检测的网络模型,并进行数据初始化;
步骤2,对已标注集进行训练;
步骤3,减少已标注集和未标注集之间的分布偏差;
步骤4,对齐已标注集和未标注集的示例分布;
步骤5,对网络模型进行迭代训练。
第二方面,提供一种计算机可读存储介质,所述存储介质存储有用于目标检测的多示例主动学习训练程序,所述程序被处理器执行时,使得处理器执行所述用于目标检测的多示例主动学习方法的步骤。
第三方面,提供一种计算机设备,包括存储器和处理器,所述存储器存储有用于目标检测的多示例主动学习训练程序,所述程序被处理器执行时,使得处理器执行所述用于目标检测的多示例主动学习方法的步骤。
本发明所具有的有益效果包括:
(1)本发明提供的用于目标检测的多示例主动学习方法,能高效利用数据标注,减少了神经网络训练的数据标注量,降低了人工成本;
(2)本发明提供的用于目标检测的多示例主动学习方法,有效利用了无标注数据,提高了相等已标注数据量下神经网络对测试图像的检测精度;
(3)本发明提供的用于目标检测的多示例主动学习方法,通过建模示例不确定性和图像不确定性之间关系的方法,改善了主动目标检测中示例和图像间存在间隔的问题;
(4)本发明提供的用于目标检测的多示例主动学习方法,通过示例不确定性重加权,提高了主动目标检测的精度,对于主动学习、半监督学习等有重要意义,对于复杂背景下自然图像的目标检测具有应用价值。
附图说明
图1示出本发明所述方法与传统检测器的比较图,其中,(a)示出了传统检测器的检测原理图,(b)示出了本发明所述方法的检测原理图;
图2示出本发明所述用于目标检测的多示例主动学习方法的检测过程图;
图3示出本发明示例不确定性学习的网络架构图,其中,(a)、(b)和(c)示出了不同阶段的已标注数据和未标注数据的状态;
图4示出本发明示例不确定性重加权的网络架构图,其中,(a)、(b)和(c)示出了不同阶段的已标注数据和未标注数据的状态;
图5示出本发明实施例1中不同方法在各数据集上不同基网下的性能比较图;
图6示出本发明实施例1中示例不确定性和图像分类分数的可视化图;
图7示出本发明实施例1中各主动学习周期中选择的真实正示例数量统计图。
具体实施方式
下面通过优选实施方式和实施例对本发明进一步详细说明。通过这些说明,本发明的特点和优点将变得更为清楚明确。
在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。
本发明的第一方面,提供了一种用于目标检测的多示例主动学习方法,所述方法包括训练部分和测试部分,其中,所述训练部分包括以下步骤,如图1中的(b)和图2所示:
步骤1,建立用于目标检测的网络模型,并进行数据初始化;
步骤2,对已标注集进行训练;
步骤3,减少已标注集和未标注集之间的分布偏差;
步骤4,对齐已标注集和未标注集的示例分布;
步骤5,对网络模型进行迭代训练;
步骤6,在未标注集内选择信息量最大的图像,合并到已标注集内,形成新的已标注集;
步骤7,利用新的已标注集重新初始化和训练网络模型。
以下进一步详细描述所述训练部分的步骤:
步骤1,建立用于目标检测的网络模型,并进行数据初始化。
根据本发明一种优选的实施方式,所述建立的用于目标检测的网络模型,包括基础网络和示例分类器。
其中,所述基础网络可以为一般深度检测网络,例如retinanet神经网络、ssd神经网络等。根据本发明的实施例,可以使用基网为resnet-50的retinanet神经网络和基网为vgg-16的ssd神经网络作为基础的检测器。
在进一步优选的实施方式中,所述示例分类器包括一个差异学习示例分类器和一个多示例学习分类器。
其中,上述两个示例分类器的结构与基础网络的结构相同,但分别进行初始化。
在本发明中,在一般深度检测网络的基础上加入另一个结构相同但独立初始化的示例分类器以实现差异学习(即示例不确定性学习,instanceuncertaintylearning,简称iul),然后再平行地添加一个多示例学习分类器以计算同一图像中多个示例的图像分类得分(即示例不确定性重加权,instanceuncertaintyreweighting,简称iur)。
在更进一步优选的实施方式中,在训练集中随机挑选固定数量的一组图像,用于已标注集的初始化。
具体地,根据本发明的实施例,对于retinanet检测器,使用从训练集中随机选择的5.0%的图像作为pascalvoc已标注集的初始化;对于mscoco数据集,使用训练集中随机选择的2.0%的图像作为已标注集的初始化。对于ssd检测器,选择pascalvoc数据集中的1000张图像作为已标注集的初始化。
步骤2,对已标注集进行训练。
在本发明中,如图3中的(a)和图4中的(a)所示,将现有的已标注图像输入到目标检测的训练网络,优选利用两个示例分类器之间的预测差异来学习未标注集上的示例不确定性。
根据本发明一种优选的实施方式,通过优化检测损失来训练目标检测的网络模型,
其中,所述网络模型的检测损失通过下式(一)获得:
其中,
在本发明中,f1表示差异学习示例分类器,f2表示多示例学习分类器。
根据本发明一种优选的实施方式,所述多示例学习分类器将每个图像视为一个示例包,利用示例分类预测来估计包标签,
优选地,通过下式(二)来估计包标签:
其中,
在本发明中,仅在示例xi属于类别c(式(二)中的第一项,
在进一步优选的实施方式中,步骤2中,通过最小化图像分类损失获得初始的多示例学习分类器;
优选地,通过下式(三)最小化图像分类损失:
其中,
在本发明中,通过上式(三)的最小化优化,能够使多示例学习分类器激活具有较大多示例学习得分
步骤3,减少已标注集和未标注集之间的分布偏差。
在本发明中,如图3中的(b)和图4中的(b)所示,在已标注集可以准确表示未标注集之前,通常在已标注集和未标注集之间会存在分布偏差,信息丰富的示例位于有偏差的分布区域。
本发明人发现,通过在基础网络中引入差异学习示例分类器f1和多示例学习分类器f2(二者为对抗性示例分类器),能够有效解决分布偏差的问题,它们在靠近类别边界的示例上更倾向于有更大的预测差异,即更大的示例不确定性。
在本发明中,优选按照包括以下步骤的方法减少已标注集和未标注集之间的分布偏差:
步骤3-1,优化预测差异损失,最大化示例不确定性。
在本发明中,为了找出信息量最大的示例,需优化预测差异损失,以最大化对抗性分类器(f1和f2)的预测差异,同时还可以保持在已标注集上的检测性能。
根据本发明一种优选的实施方式,通过下式(四)优化预测差异损失,以最大化对抗性分类器的预测差异:
其中,
步骤3-2,对示例不确定性进行重加权。
在本发明中,为了确保示例不确定性与图像不确定性相一致,优选对示例不确定性进行重加权,使得网络将会优先估计具有较大图像分类得分示例的差异,而抑制具有较小图像分类得分示例的差异。
根据本发明一种优选的实施方式,经过示例不确定性重加权后,通过下式(五)获得预测差异损失:
其中,
在进一步优选的实施方式中,通过下式(六)获得最大化示例不确定性重加权损失:
其中,
在本发明中,利用插入在检测基础网络顶部的两个对抗性示例分类器(f1和f2)来学习未标注示例的不确定性,最大化两个示例分类器的预测差异可预测示例的不确定性。
步骤4,对齐已标注集和未标注集的示例分布。
在本发明中,如图3中的(c)和图4中的(c)所示,在步骤3的基础上,需要最小化两个示例分类器的预测差异,以对齐已标注集和未标注集的示例分布。
优选地,所述步骤4包括以下子步骤:
步骤4-1,最小化示例不确定性并对示例不确定性进行重加权。
其中,对示例不确定性进行重加权,即采用最大期望算法来重加权包与包之间的示例不确定性,以突出显示具有相同类别的信息量大的物体示例。
根据本发明一种优选的实施方式,通过下式(七)获得最小化示例不确定性的损失:
在进一步优选的实施方式中,经过示例不确定性重加权后,通过下式(八)获得最小化示例不确定性重加权损失:
在本发明中,通过最小化示例分类器的差异可学习特征。
步骤4-2,通过图像伪标签估计缩小示例级不确定性和图像级不确定性之间的差距。
在本发明的多示例学习中,根据未标注集中的图像类别标签(或伪标签)定义的分类损失,示例不确定性和图像不确定性被强制一致性地进行学习。
优选地,所述伪图像标签是使用示例分类器的输出估计的,优选通过下式(九)获得:
其中,
在本发明中,通过优化图像级的分类损失,有助于抑制噪声高的示例,同时突出显示真正具有代表性的示例。
步骤5,对网络模型进行迭代训练。
在本发明中,所述对网络模型进行迭代训练即为重复步骤2~步骤4。具体地:在每个主动学习周期中,最大化-最小化预测差异的过程会重复几次,以便学习示例的不确定性,并逐步对齐已标注集和未标注集的示例分布。
本发明所述的迭代训练过程实际上为一种无监督的学习过程,该过程利用了未标注集的信息(即预测差异)来改善检测模型。
根据本发明的实施例,当采用retinanet检测器时,在每个主动学习周期中,最小批尺寸为2,学习率为0.001,共迭代训练26个时期,20个时期后,学习率降低至0.0001,动量和权重衰减分别设置为0.9和0.0005;当使用ssd检测器时,共迭代训练300个时期,前240个时期的学习率是0.001,后60个时期的学习率是0.0001。
步骤6,在未标注集内选择信息量最大的图像,合并到已标注集内,形成新的已标注集。
在本发明中,优选地,在每个主动学习周期中,在步骤3和4之后(即示例不确定性学习和示例不确定性重新加权之后),通过观察每个图像中部分不确定性较高的示例,从未标注集内选择信息量最大的图像。
本发明人研究发现,在经过示例不确定性学习和示例不确定性重新加权之后,噪声高的示例已经被抑制掉,且示例不确定性与图像不确定性相一致,选出的图像将合并到已标注集,用于下一个主动学习周期。
根据本发明一种优选的实施方式,将每个图像的
优选地,将每个图像中前k高的示例不确定性作为选择依据,其中,k是超参数,优选设定为10000。
本发明人研究发现,将每个图像中前k高的示例不确定性作为选择依据(k优选设定为10000),能够最大限度地滤除背景信息。
在本发明中,通过反复进行示例不确定性的学习和重加权,缩小了示例级观察和图像级评估之间的差距,以便选择信息量最大的图像进行训练。
在步骤6中,将选出的图像合并到已标注集,获得新的已标注集。
步骤7,利用新的已标注集重新初始化和训练网络模型。
根据本发明一种优选的实施方式,在获得新的已标注集之后,重复步骤2~步骤6,迭代进行主动学习,即重新初始化与训练网络模型,选择下一个主动学习周期所需的样本,直至已标注图像的数量达到标注预算。
具体地,所述迭代进行主动学习的过程为:
在步骤1的初始化中,已经生成了一个较小的图像集合
经过步骤2~步骤5之后,基于用已标注集
在更新后的已标注集
检测模型训练和样本选择过程重复几个周期,直到已标注图像的数量达到标注预算。
优选地,所述标注预算由不同的检测任务及数据集决定,例如,根据本发明的实施例,对于retinanet检测器,在每个主动学习周期中从未标注集内选择2.5%的图像,直到已标注的图像数量达到训练集的20.0%。对于mscoco数据集,在每个周期中从未标注集内选择2.0%的图像,直到已标注集达到训练集的10.0%。对于ssd检测器,在每个周期中各选择1000张图像,直到已标注集达到10000张图像。
本发明所述用于目标检测的多示例主动学习方法,训练部分采用示例不确定性学习(iul)和示例不确定性重加权(iur)实现,具体在给定已划分好的已标注集和未标注集下,利用已标注集训练用于目标检测的网络模型,从未标注集内选出信息量最大的图像集,合并到已标注集中,直到已标注的图像数量达到标注预算。
根据本发明一种优选的实施方式,所述测试部分为在每个主动学习周期的步骤之前,将训练得到的模型应用到测试集的目标检测任务上,以验证模型的有效性。
在进一步优选的实施方式中,在每个主动学习周期中,所选用的测试数据完全一致。
本发明提供的用于目标检测的多示例主动学习方法,减少了神经网络训练的数据标注量,降低了人工成本;通过建模示例不确定性和图像不确定性之间的关系,改善了主动目标检测中示例和图像间存在间隔的问题;通过进行示例不确定性重加权,进一步提高了主动目标检测的精度。
本发明的第二方面,提供了一种计算机可读存储介质,存储有用于目标检测的多示例主动学习训练程序,所述程序被处理器执行时,使得处理器执行所述用于目标检测的多示例主动学习方法的步骤。
本发明中所述的用于目标检测的多示例主动学习方法可借助软件加必需的通用硬件平台的方式来实现,所述软件存储在计算机可读存储介质(包括rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机、计算机、服务器、网络设备等)执行本发明所述方法。
本发明的第三方面,提供了一种计算机设备,包括存储器和处理器,所述存储器存储有用于目标检测的多示例主动学习训练程序,所述程序被处理器执行时,使得处理器执行所述用于目标检测的多示例主动学习方法的步骤。
实施例
以下通过具体实例进一步描述本发明,不过这些实例仅仅是范例性的,并不对本发明的保护范围构成任何限制。
实施例1
1、数据集
本实施例中将pascalvoc2007和2012数据集的trainval集用作训练集,分别包含5011张和11540张图像;将pascalvoc2007数据集的test集用于评估检测性能。
使用mscoco数据集11.7万张图像的train集进行主动学习,使用0.5万张图像的val集来评估检测性能。其中,mscoco数据集包含80个具有挑战性的物体类别,体现在密集物体、有遮挡的小物体等。
2、任务描述
主动目标检测,使用从训练集中随机选择的部分图像作为已标注集的初始化进行训练测试,在每个主动学习周期中从其余未标注集内选择固定数量的图像加入到已标注集中训练测试,直到已标注集中图像的数量达到训练集的固定比例为止,实现主动学习的目标检测;每次测试使用平均精确率(map)或平均精度(ap)进行性能评测。
在本实施例中,将所有实验重复5次并使用性能的平均值,与其他方法比较时共享相同的随机种子和初始化以实现公平性。
具体地,所述训练部分:
步骤1,建立用于目标检测的网络模型,并进行数据初始化:对于retinanet检测器,使用从训练集中随机选择的5.0%的图像作为pascalvoc已标注集的初始化;对于mscoco数据集,使用训练集中随机选择的2.0%的图像作为已标注集的初始化。对于ssd检测器,选择pascalvoc数据集中的1000张图像作为已标注集的初始化
步骤2,对已标注集进行训练:
训练网络时的检测损失为:
利用示例分类预测来估计包标签的具体过程为:
最小化图像分类损失的损失函数为:
步骤3,减少已标注集和未标注集之间的分布偏差:
最大化示例不确定性的损失函数为:
其中,
经过示例不确定性重加权后的预测差异损失为:
最大化示例不确定性重加权损失函数为:
步骤4,对齐已标注集和未标注集的示例分布:
最小化示例不确定性的损失函数为:
最小化示例不确定性重加权损失函数为:
伪图像标签通过下式获得:
步骤5,对网络模型进行迭代训练:当使用retinanet检测器时,在每个主动学习周期中,最小批尺寸为2,学习率为0.001,共迭代训练26个时期,20个时期后,学习率降低至0.0001,动量和权重衰减分别设置为0.9和0.0005。当使用ssd检测器时,共迭代训练300个时期,前240个时期的学习率是0.001,后60个时期的学习率是0.0001。
步骤6,在未标注集内选择信息量最大的图像,合并到已标注集内,形成新的已标注集:将每个图像中前k高的示例不确定性作为选择依据,其中,k设定为10000。
步骤7,利用新的已标注集重新初始化和训练网络模型:对于retinanet检测器,在每个主动学习周期中从未标注集内选择2.5%的图像,直到已标注的图像数量达到训练集的20.0%。对于mscoco数据集,在每个周期中从未标注集内选择2.0%的图像,直到已标注集达到训练集的10.0%。对于ssd检测器,在每个周期中各选择1000张图像,直到已标注集达到10000张图像。
测试部分:每个主动学习周期的步骤6之前,将训练得到的模型应用到测试集的目标检测任务上,以验证模型的有效性。
其中,pascalvoc数据集的评测指标为平均精确率(map),即各个类别的平均精度对于类别的均值,mscoco数据集的评测指标为平均精度(ap)。
3、结果与分析
本实施例中使用基网为resnet-50的retinanet神经网络和基网为vgg-16的ssd神经网络作为基础的检测器,在pascalvoc、mscoco数据集上进行学习与评测,检测结果如表1。
表1pascalvoc测试性能
其中,“最大”和“平均”分别代表图像不确定性由最大或平均示例不确定性所表示,“√”表示使用此模块。
由表1可知,在使用iul模块(即差异学习示例分类器)的情况下,在最后一个周期中,检测性能提高到了70.1%,比基线高出3.0个百分点(从67.1%到70.1%);在使用iur模块(即多示例学习分类器)的情况下,检测性能将会提高到72.0%,比基线高出4.9个百分点(从67.1%到72.0%)。当使用标注比例为100%的图像进行训练时,带有iur的检测器比没有iur的检测器性能高出1.1个百分点(从77.3%到78.4%)。上述表明了本发明所述方法的有效性。
进一步地,将本实施例所述方法(mial)与现有的多个主动目标检测方法进行性能比较,结果如表2和图5所示。
表2pascalvoc数据集上的时间消耗比较结果
其中,随机采样方法(即基线方法)为随机选择图像并使用retinanet网络直接训练;
熵采样方法(即ll4al)具体如文献“yood,kweonis.learninglossforactivelearning[c]//proceedingsoftheieee/cvfconferenceoncomputervisionandpatternrecognition.2019:93-102”中所述;
core-set具体如文献“senero,savareses.activelearningforconvolutionalneuralnetworks:acore-setapproach[c]//internationalconferenceonlearningrepresentations.2018”中所述;
cdal具体如文献“agarwals,arorah,anands,etal.contextualdiversityforactivelearning[c]//europeanconferenceoncomputervision.springer,cham,2020:137-153.”中所述。
由表2可以看出,本实施例所述的多示例主动学习虽然在后期几个周期(15.0%、17.5%、20.0%)会花费略多的时间,但在早期几个周期(5.0%、7.5%、10.0%、12.5%)花费的时间更少。
图5示出了本实施例所述方法与现有技术的方法在不同数据集不同及网下的性能比较。由图5可以看出,无论使用retinanet还是ssd检测器,本实施例所述的多示例主动学习都能以明显的优势胜过现有技术的最新方法。具体地,在pascalvoc数据集上使用retinanet神经网络时,特别是在使用5.0%、7.5%和10.0%的样本时,本实施例方法的性能分别比最新方法高出18.08、7.78和5.19个百分点。在最后一个周期中,mial使用20.0%的样本达到了72.27%的检测平均精确率,比cdal显著高出3.20个百分点。当使用ssd检测器时,本实施例所述的多示例主动学习在几乎所有周期中都优于最新方法。在mscoco数据集上使用retinanet神经网络时,特别是当使用2.0%、4.0%和10.0%的已标注图像时,它分别比core-set高出了0.6、0.5和2.0个百分点,比cdal高出了0.6、1.3和2.6个百分点。以上数据均表明了本发明所述方法超过了当前最新技术的性能,且在一般目标检测器上具有普遍适用性。
更进一步地,对学习到和重加权后的示例的不确定性和图像分类分数进行了可视化分析,如图6所示,可以看出,仅使用iul模块时,会存在来自背景(第1行)或真实正示例(第2行)周围的干扰示例,结果往往会遗漏真实正示例(第3行)或示例的一部分(第4行)。多示例学习可以在抑制背景的同时为感兴趣的示例分配较高的图像分类分数。在此基础上,iur模块可利用图像分类分数对示例重加权,以实现准确的示例不确定性预测。
统计计算在每个主动学习周期中选择的真实正示例的数量,结果如图7所示,可以看出,在所有学习周期中,本发明所述的多示例主动学习选用了明显更多的真实正样本。说明本发明所述的方法可以在滤除干扰示例的同时更好地激活真实正目标,从而为选择信息量大的图像以供检测器训练提供了便利。
以上结合具体实施方式和范例性实例对本发明进行了详细说明,不过这些说明并不能理解为对本发明的限制。本领域技术人员理解,在不偏离本发明精神和范围的情况下,可以对本发明技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!