一种基于K-Means参数聚类的城市内涝模拟方法
本发明涉及城市雨洪模拟技术领域,特别是指一种基于k-means参数聚类的城市内涝模拟方法。
背景技术:
近百年来,气候变化愈演愈烈,全球范围内的降水时空格局也发生了较大变化,由此导致的自然灾害发生频率与程度正逐渐加大。上世纪80年代以来,洪灾数量增加近230%,受洪灾影响的人口及损失也在上升。在水循环方面,全球变暖导致海洋、地表蒸发增加,进而导致水文循环过程加快。在降水形成方面,大气温度的上升导致其持水能力增强,大气更难达到饱和,形成降雨条件需要更多的水汽。在这种情况下,某区域一旦发生降雨,降雨强度就会比同期大。另外,潮湿温暖大气稳定性一般较差,易形成暴雨过程,暴雨出现频率也会增大。《中国极端天气气候事件和灾害风险管理与适应国家评估报告》指出,中国极端天气气候事件种类多、频次高、阶段性和季节性明显,区域差异大,影响范围广。近60年我国极端天气气候事件变化显著,高温日数和暴雨日数增加,局部强降雨和城市洪涝增多。根据《中国极端天气气候事件和灾害风险管理与适应国家评估报告》,在中等排放和高排放情景下,我国21世纪暴雨事件将呈增加趋势,21世纪末洪涝灾害风险加大,且城市化和财富积聚会放大气候灾害的风险。
近年来,全球城市规模急剧扩张,气候变化导致城市极端降水频率和强度的升高趋势更加显著,城市洪涝问题日益凸显。21世纪以来,中国城市洪涝灾害频次和程度呈上升趋势,“逢暴雨必涝”已成为中国城市的真实写照,给人民生活带来了生活不便和严重的财产损失。因此,为应对日益严峻的城市洪涝灾害问题,探索精确、高效的城市洪涝模拟方法成为当前城市水文学的研究热点。城市雨洪模拟是城市防洪减灾的关键技术之一,城市雨洪模拟软件swmm、info-works、mikeurban及mouse等在国内外应用较多,其中swmm因代码开源、原理明晰、可操作性强等特点而广泛用于排水防涝计算、城市水文过程模拟、水质模拟和低影响开发措施研究等(原理结构见图2)。国内外分别有应用swmm模型对澳大利亚悉尼市与重庆金佛山、河南郑州市等进行雨洪过程模拟的研究;关于研究排水管网系统和模型参数,peterson、ericw等人分析了swmm模型在喀斯特地区的应用和swmm模型敏感性,发现swmm模型中的入渗率和边坡坡度这两个参数对管渠尺寸和管渠相关的参数不敏感,而swmm模型模拟结果随着曼宁系数的变化将会发生较大的变化。刘兴坡等以swmm模型为基础,通过设置典型情景,分析研究位于镇江市的雨水排放系统的总体性能和在运行过程中的瓶颈。还有其他一些学者采用swmm模型进行城市排水系统规划;国内外学者用swmm模型分析了滞留池和河湾地区的排污状况,进行了削减污染效应研究。
在这些应用研究中,模型子汇水区的划分没有明确的方法,参数取值往往是取典型值或在取值范围内率定后应用于整个研究区,过程繁琐重复并且不同用地属性参数取值的差异性,因此,城市内涝模拟中子汇水区的划分及参数的确定成为现有模型应用的关键。
技术实现要素:
针对上述背景技术中存在的不足,本发明提出了一种基于k-means参数聚类的城市内涝模拟方法,基于swmm模型,结合城市雨洪模型中子汇水单元的划分原则,利用k-means聚类分析城市雨洪模型参数取代传统的参数率定过程,解决了城市雨洪模型参数率定繁琐、效率低下的技术问题。
本发明的技术方案是这样实现的:
一种基于k-means参数聚类的城市内涝模拟方法,其步骤如下:
步骤一:根据研究区城市用地特性划分城市水文响应单元,并提取城市水文响应单元的数字高程数据;
步骤二:根据研究区的每个城市水文响应单元的数字高程数据,对研究区的实际雨水管网进行概化后叠加到城市水文响应单元上得到swmm模型;
步骤三:采用k均值聚类算法对不同城市的每个城市水文响应单元上的不确定性参数的取值进行聚类,得到每个城市水文响应单元的不确定性参数值,并将不确定性参数值输入swmm模型中,得到最终的swmm模型;
步骤四:将实际降雨场次输入最终的swmm模型中进行模拟,以验证最终的swmm模型的内涝模拟结果。
所述城市水文响应单元的划分方法为:
s11、由传感器、摄像头和网络资料获取研究区的遥感影像资料;
s12、根据研究区的遥感影像资料和用地规划图从自然属性和社会属性将研究区划分为工商业区、居民区和公共用地区三类功能区,每个功能区作为一个城市水文响应单元;
s13、分析研究区的地形地势资料,分别确定每一个城市水文响应单元的数字高程数据,其中,数字高程数据包括高程、坡度和坡向信息。
所述步骤三中采用k均值聚类算法对不同城市的每个城市水文响应单元上的不确定性参数的取值进行聚类的方法为:
s31、搜集现有基于swmm模型进行的以中国各地区为研究区的文献的不确定性参数的取值作为样本集,其中,不确定性参数包括不透水区洼蓄量、不透水区曼宁系数、透水区洼蓄量和透水区曼宁系数;
s32、采用k-means聚类算法对不同城市的功能区上的每个不确定性参数进行聚类,设置聚类数目为k;
s33、将样本集分成k个初始类,将这k个类的重心作为初始的类中心点,计算分类后的f值,检验聚类效果。
所述步骤s33中的f值的计算方法为:
f=[ssa/(k-1)]/[sse/(n-k)],
式中,f为平均组间平方和与平均组内平方和之比,k为聚类数,ni为第i个类的样本容量,ssa为组间离差平方和,sse为组内离差平方和,n表示样本总量,xi表示第i个类的样本值,
所述k-means聚类算法的步骤为:
设有m个样本组,每个样本组有p个指标的数据,这m×p个数据构成一个参数聚类观测矩阵,即:
其中,xi′j′为第i′个样本组的第j′个指标参数值,i′=1,2,…,m,j′=1,2,…,p;则有:
式中,
与现有技术相比,本发明产生的有益效果为:本发明通过k-means聚类分析城市雨洪模型不确定性参数,解决了城市雨洪模型参数率定繁琐重复的问题,有助于对未来城市雨洪模型研究拓展新思路。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
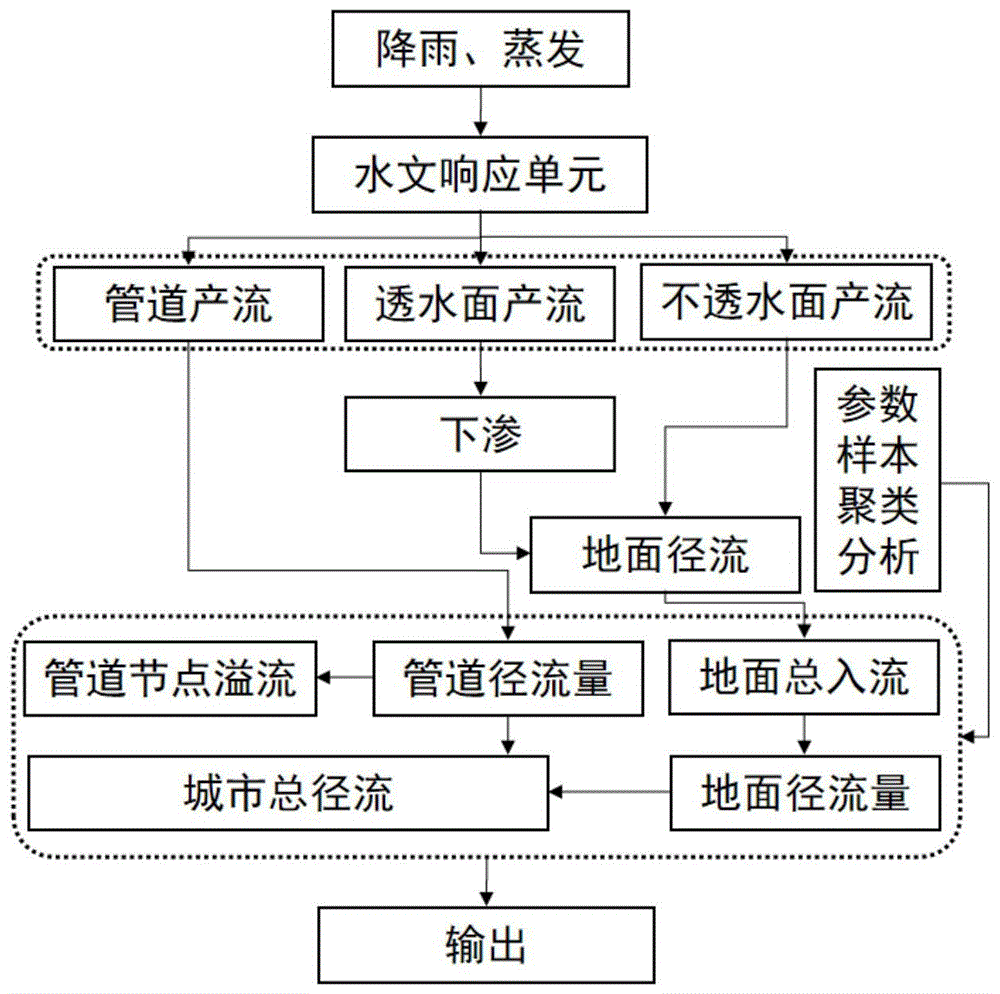
图1为本发明的流程图。
图2为本发明中swmm模型的结构框图。
图3为本发明中城市雨洪模型里子汇水单元划分原则。
图4为本发明子汇水单元划分结果图。
图5为本发明中常见积水点图。
图6为本发明的模型验证图,其中,(a)为20160605场次降雨模拟结果,(b)为20170730场次降雨模拟结果,(c)为20170812场次降雨模拟结果。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明实施例提供了一种基于k-means参数聚类的城市内涝模拟方法,将k-means聚类分析应用于城市雨洪模型不确定性参数选取,解决了城市雨洪模型参数率定繁琐重复的问题,有助于对未来城市雨洪模型研究拓展新思路;具体步骤如下:
步骤一:根据研究区城市用地特性划分城市水文响应单元,并提取城市水文响应单元的数字高程数据;所述城市水文响应单元的划分方法为:
s11、由传感器、摄像头和网络资料获取研究区的遥感影像资料;获取由传感器、摄像头、网络资料等各类数据的有用信息,基于空间尺度1m*1m的遥感影像资料解译提取土地利用信息,结合城市用地特性划分城市水文响应单元,为达到精细刻画城市水文过程提供基础。
s12、根据研究区的遥感影像资料和用地规划图从自然属性和社会属性将研究区划分为工商业区、居民区和公共用地区三类功能区,每个功能区作为一个城市水文响应单元;如图3所示,遥感影像资料和用地规划图可以从自然属性和社会属性两方面显示研究区下垫面情况,反映城市功能分区明显的地表特性,根据这一特性,以建筑物分布、道路和河流水系情况为基础,划分各个子汇水区,并且尽量使一个子汇水区内分布同一种用地类型,城市功能分区是为了区别模型参数在不同地表类型上的取值,若类别太少,则无法区分不同的水文响应单元,若类别过多,难以确定每一细类下的参数取值,考虑这些因素和城市区块化明显的特性,最终把研究区城市功能区分为三类:工商业区、居民区以及公共用地区。
s13、分析研究区的地形地势资料,分别确定每一个城市水文响应单元的数字高程数据,其中,数字高程数据包括高程、坡度和坡向信息。数字高程数据可以反映高程、坡度和坡向信息,分析研究区的地形地势资料,提取坡度,确定汇流路径和方向;子汇水区径流汇入周围子汇水区或邻近管网节点,管网分布资料提供了管段节点的长度和位置信息,由此得到子汇水区径流的汇出位置。
步骤二:根据研究区的每个城市水文响应单元的数字高程数据,对研究区的实际雨水管网进行概化后叠加到城市水文响应单元上得到swmm模型,如图4所示。
s21、根据研究区实际的地形地貌、下垫面情况和区域流水方向,考虑城市雨水管网的布局情况,将现实的雨水管网概化为管网模型,即忽略合并支路的管网并保留主要干道上的管网,使概化后的雨水管网数据符合模型的需要。
s22、swmm模型参数主要分为两种,一种为确定性参数,如面积、坡度、不透水率等可以用gis和envi软件求出,其中下渗模型选择scs双曲线模型;另一种参数为不确定性参数,如不透水区洼蓄量、透水区洼蓄量、不透水区曼宁系数以及透水区曼宁系数。本发明即针对不确定性参数进行聚类分析,具体实施在步骤三中体现。按照swmm模型数据输入要求的格式,将实测降雨资料、子汇水区的资料、城市管网资料输入swmm模型中的径流模块。
其中实测降雨资料指的是实测的研究区出水口的降雨时间序列。城市管网数据指的是包含管道相关数据(管径、水流方向等)的城市排雨水管道现状及规划图。
步骤三:采用k均值聚类算法对不同城市的每个城市水文响应单元上的不确定性参数的取值进行聚类,得到每个城市水文响应单元的不确定性参数值,并将不确定性参数值输入swmm模型中,得到最终的swmm模型;
所述步骤三中采用k均值聚类算法对不同城市的每个城市水文响应单元上的不确定性参数的取值进行聚类的方法为:
s31、搜集现有基于swmm模型进行的以中国各地区为研究区的文献的不确定性参数的取值作为样本集,其中,不确定性参数包括不透水区洼蓄量、不透水区曼宁系数、透水区洼蓄量和透水区曼宁系数;
对大量基于swmm模型进行的以中国各地区为研究区的文献的敏感参数取值进行归纳总结,部分研究的参数取值结果如表1所示。
表1部分文献参数取值
表1中,文献[1]—[董欣,杜鹏飞,李志一,等.swmm模型在城市不透水区地表径流模拟中的参数识别验证[j].环境科学,2008,29(6):1495-1501.];文献[2]—[黄卡,张翔,李鹏.swmm模型在城市洪水中的应用研究[j].企业科技与发展,2008,(10):214-216.];文献[3]—[何福力,胡彩虹,王民,等.swmm模型在城市排水系统规划建设中的应用[j].水电能源科学,2015,(6):48-53];文献[4]—[刘俊.城市雨洪模型研究[j].河海大学学报,1997(06):22-26.];文献[5]—[杨海波,李云飞,王宗敏.不同暴雨与城市化程度情景下城区内涝swmm模拟分析[j].水利水电技术,2014,45(11):15-17+23.];文献[6]—[王雯雯,赵智杰,秦华鹏.基于swmm的低冲击开发模式水文效应模拟评估[j].北京大学学报(自然科学版),2012,48(02):303-309.];文献[7]—[王蓉,秦华鹏,赵智杰.基于swmm模拟的快速城市化地区洪峰径流和非点源污染控制研究[j].北京大学学报(自然科学版),2015,51(01):141-150.];文献[8]—[冯书仓.基于swmm模型的沧州市城区内涝研究[j].水利科技与经济,2016,22(05):92-95+98.];文献[9]—[王文亮,李俊奇,宫永伟,朱明靖,张庆康.基于swmm模型的低影响开发雨洪控制效果模拟[j].中国给水排水,2012,28(21):42-44.];文献[10]—[李阳,何俊仕.基于swmm模型的不透水率与产汇流关系研究[j].水电能源科学,2017,35(02):34-37.];文献[11]—[李霞,石宇亭,李国金.基于swmm和低影响开发模式的老城区雨水控制模拟研究[j].给水排水,2015,51(05):152-156.];文献[12]—[常晓栋,徐宗学,赵刚,等.山前平原型城市雨洪模拟与应用——以济南市为例[j].水力发电学报,2018,(05):107-116.];文献[13]—[朱呈浩,夏军强,陈倩,等.基于swmm模型的城市洪涝过程模拟及风险评估[j].灾害学,2018,(02):224-230.];文献[14]—[赵树旗,晋存田,李小亮,等.swmm模型在北京市某区域的应用[j].给水排水,2009,(35):448-451.];文献[15]—[刘俊,徐向阳.城市雨洪模型在天津市区排水分析计算中的应用[j].海河水利,2001(01):9-11.];文献[16]—[侯倩倩.基于swat与swmm模型的城市内涝预警技术研究[d].杭州师范大学,2017.];文献[17]—[贾赛君.基于swmm的城市暴雨内涝模拟研究[d].辽宁师范大学,2018.];文献[18]—[王石.基于swmm模型的南宁市地表径流及非点源污染精细化模拟研究[d].广西大学,2017.];文献[19]—[李东.贵安新区海绵城市雨洪控制技术研究[d].郑州大学,2019.];文献[20]—[赵磊,杨逢乐,袁国林,王俊松,朱永官.昆明市明通河流域降雨径流水量水质swmm模型模拟[j].生态学报,2015,35(06):1961-1972.];文献[21]—[孙阿丽.基于情景模拟的城市暴雨内涝风险评估[d].华东师范大学,2011.];文献[22]—[王静.基于swmm模型的山地城市暴雨径流效应及生态化改造措施研究[d].重庆大学,2012.];文献[23]—[李霞,石宇亭,李国金.基于swmm和低影响开发模式的老城区雨水控制模拟研究[j].给水排水,2015,51(05):152-156.];文献[24]—[张杰.基于gis及swmm的郑州市暴雨内涝研究[d].郑州大学,2012.];文献[25]—[黄国如,冯杰,刘宁宁,等.城市雨洪模型及应用[m].北京:中国水利水电出版社,2013.];文献[26]—[石赟赟,万东辉,陈黎,郑江丽.基于gis和swmm的城市暴雨内涝淹没模拟分析[j].水电能源科学,2014,32(06):57-60+12.];文献[27]—[黄国如,张灵敏,雒翠,等.swmm模型在深圳市民治河流域的应用[j].水电能源科学,2015,33(4):10-14.];文献[28]—[黄纪萍.城市排水管网水力模拟及内涝预警系统研究[d].华南理工大学,2014.];文献[29]—[史蓉,庞博,赵刚,杜龙刚,钟一丹,左萍.swmm模型在城市暴雨洪水模拟中的参数敏感性分析[j].北京师范大学学报(自然科学版),2014,50(05):456-460.];文献[30]—[马俊花,李婧菲,徐一剑,刘广奇,李迎霞.暴雨管理模型(swmm)在城市排水系统雨季溢流问题中的应用[j].净水技术,2012,31(03):10-15+19.];文献[31]—[李晓燕.swmm模型在西北典型城镇雨洪系统规划中的应用[d].西安建筑科技大学,2013.];文献[32]—[李世豪.郑州市区洪涝风险分析及内涝积水模拟研究[d].郑州大学,2016.]。
s32、采用k-means聚类算法对不同城市的功能区上的每个不确定性参数进行聚类,设置聚类数目为k。
s33、将样本集分成k个初始类,将这k个类的重心作为初始的类中心点,计算分类后的f值,检验聚类效果。
在聚类过程中,确定类的个数是所有聚类方法所面临的共同问题,k-means聚类分析方法通过方差分析来筛选最优的分类数,即定义一个f统计量:
f=[ssa/(k-1)]/[sse/(n-k)],
式中,k为聚类数,ni为第i个类的样本容量,ssa为组间离差平方和,sse为组内离差平方和,n表示样本总量,xi表示第i个类的样本值,
根据研究目的选择合适的聚类指标,对样本数据进行标准化处理以消除量纲的差异。设有m个样本组,每个样本组有p个指标的数据,这m×p个数据构成一个参数聚类观测矩阵,即:
其中,xi′j′为第i′个样本组的第j′个指标参数值,i′=1,2,…,m,j′=1,2,…,p;则有:
式中,
按经验先估计一个范围,即为k的数值,然后将所有样本分成k个初始类,进而将这k个类的重心(均值)作为初始的类中心点。本发明k为用地属性的种类3。经过检验也是k=3的情况下f最大,聚类效果最好。聚类结果见表2。
表2洼蓄量与曼宁系数取值
步骤四:将实际降雨场次输入最终的swmm模型中进行模拟,以验证最终的swmm模型的内涝模拟结果。
s41、将20150502、20170706、20180515和20180626这4场降雨事件输入模型,几乎没有产生积水点,因为它们的平均雨强较小,未超过城市排涝能力。
s42、将20160605、20170730和20170812这3场降雨输入模型,有积水产生,分析模拟结果的合理性。
s43、计算20160605、20170730和20170812这三场降雨事件的综合径流系数,具体见表3。比较模拟结果的综合径流系数与城市排水手册中的综合径流系数经验值,模型模拟的综合径流系数在0.6到0.8之间,依据经验综合径流系数(见表4)进行判断,属于建筑较密的中心区或建筑较密的居住区,与研究区位于郑州市中心城区、建筑密集且居住区集中的实际情况相符。
表3模拟综合径流系数结果表
表4经验综合径流系数取值表
s44、进一步分析模拟结果,统计积水点数量并研究积水点的位置分布情况。从表5可以看出,20160605场次降水量大,产生的积水点数量明显要比其他两场降水多,而综合径流系数第二大的20170812场次降雨产生的积水点数量也大于20170730场次。降雨后常有对积水点进行报道的新闻,一般积水点越多,新闻条数也越多,由网络爬虫获取报道积水的新闻条数情况看,20160605场次共爬取到45条信息,20170730场次共爬取到17条信息,20170812场次共爬取到29条信息,爬取的新闻条数的多少与模型模拟的三场降雨事件里积水点数量的多少顺序一致,说明模拟的积水点数量与实际产生的积水点数量相似。
表5积水点数量
通过郑州市防汛办对全市可能的积水点进行的调查,结合网络爬虫技术捕获的降雨发生后大量新闻报道的积水点,获得研究区常见积水点的位置分布如图5所示。20160605场次的积水点几乎覆盖了所有常见的积水点,如图6(a)所示,且由于降水量大,产生了大量的中等危害和高危害的积水点;而20170812场次的积水点的位置最接近于常见的积水点的分布,如图6(b)所示;尽管20170730场次的积水点数量接近20170812场次,但位置分布差异很大,如图6(c)所示,主要原因是两次降雨的空间分布差异很大。对于20170730场次降雨事件,研究区西北部的降雨量远远多于其他地区,导致研究区西北部的积水点比其他地区更多。所有模拟积水点位置与实际相符合。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!