通过深度学习和矢量场估计的特征检测的制作方法
1.本公开一般涉及用于从图像提取特征的系统和方法,并且更具体地,涉及用于使用深度学习神经网络和矢量场估计过程从图像提取特征的系统和方法。
背景技术:
2.机器人执行包括拾取和放置操作的多个任务,其中机器人拾取对象并将对象从一个位置(例如传送带)移动到另一位置(例如收集箱),其中对象的位置和取向,称为对象的3d姿态,略微不同。因此,为了使机器人有效地拾取对象,机器人通常需要知道对象的3d姿态。为此目的确定对象的3d姿态的各种技术使用实时获得对象的3d图像的3d相机,其中3d图像识别到相机的视场中的许多点的距离测量,其被发送到机器人控制器。这些技术可使用结构化光构建场景的3d地图,然后通过识别对象的3d特征来搜索地图中的对象。使用3d照相机来确定用于机器人应用的对象的3d姿态已经被证明是有效的。然而,3d相机是昂贵的设备,并且通常比预期运行得更慢。
3.本领域已知的为机器人应用获得对象的3d姿态的一种技术采用2d相机。该技术拍摄场景的单个2d彩色图像,并使用全卷积架构来处理该图像。一种算法将图像划分成包括s
×
s个单元的2d网格并识别单元中的对象。该算法在图像中的每个对象周围投影边界框,并且预测该框的八个角的2d位置。然而,用于预测边界框的角的这种技术具有准确度的限制和对遮挡的低鲁棒性。
4.上面提到的用于确定对象的3d姿态的一些过程采用人工智能(ai),人工智能是计算机科学的一部分,其采用允许软件应用从其环境学习并从其作出决策以实现特定结果的算法。机器学习是ai的一部分,机器学习采用软件应用,该软件应用通过以迭代方式分析大量原始输入数据,以从数据中提取模式并允许软件应用学习执行任务而无需被专门编程来执行该任务,从而获取其自身知识。深度学习是一种特定类型的机器学习,其通过将特定的真实世界环境表示为日益复杂的概念的层次结构来提供更强的学习性能。
5.深度学习通常采用包括执行非线性处理的若干层神经网络的软件结构,其中每个连续层接收来自前一层的输出。通常,这些层包括接收来自传感器的原始数据的输入层、从数据中提取抽象特征的多个隐藏层、以及基于来自隐藏层的特征提取来识别特定事物的输出层。神经网络包括神经元或节点,每个神经元或节点具有"权重",该权重乘以节点的输入以获得某物是否正确的概率。更具体地说,每个节点具有一个权重,该权重是一个浮点数,该浮点数与该节点的输入相乘,以生成该节点的输出,该输出是该输入的某一比例。通过使神经网络在监督处理下分析一组已知数据,并通过最小化成本函数以允许网络获得正确输出的最高概率,来初始"训练"或设置权重。
6.深度学习神经网络经常被用来提供图像特征提取和变换,以用于图像中的对象的视觉检测和分类,其中视频或图像流可以由网络分析以识别和分类对象并且通过该过程进行学习以更好地分辨对象。因此,在这些类型的网络中,系统可以使用相同的处理配置来检测某些对象,并且基于算法如何学习识别对象来对这些对象进行不同的分类。
技术实现要素:
7.以下讨论公开并描述了使用深度学习神经网络和矢量场估计处理从对象的2d图像提取多个特征的系统和方法。该方法包括从2d图像提取对象上的多个可能特征点,生成限定对象所位于的2d图像中的像素的掩模图像,以及针对每个提取的特征点生成单独的矢量场图像,该矢量场图像包括针对2d图像的每个像素具有x方向值和y方向值的箭头,其中每个箭头的方向朝向2d图像中的提取的特征点,并且其中提取可能特征点、生成掩模图像和生成矢量场图像在深度学习神经网络中执行。该方法还包括通过将掩模图像中的像素与矢量场图像中的对应像素相乘,使得丢弃2d图像中的与具有对象的一部分的像素不相关联的那些箭头,来生成矢量提取图像,并且通过识别用于2d图像中的两个像素的每个组合的箭头相交的交点来生成矢量相交图像。该方法根据两个像素的每个组合的每个像素与交点的距离来为每个交点分配得分,并生成得分网格,并生成点投票图像,该点投票图像从多个聚集点中识别特征位置。
8.结合附图,从以下描述和所附权利要求,本公开的附加特征将变得显而易见。
附图说明
9.图1是包括机器人的机器人系统的示意图,该机器人从传送带拾取对象并将它们放置在料箱中,其中该系统采用用于拍摄对象的2d图像的2d相机和用于使用2d图像计算对象的3d姿态的控制器;
10.图2是示出了使用2d相机从对象获得数据集以训练神经网络的过程的流程图;
11.图3是包括多个节点的神经网络的示意图,每个节点具有可调整的权重;
12.图4是示出了基于学习的神经网络过程的流程图,该过程用于使用经训练的神经网络,以使用对象的2d图像和神经网络来估计对象的3d姿态;
13.图5是描述了用于在图4所示的过程中用于确定对象的3d姿态估计的透视n点(pnp)过程的示意图;
14.图6是使用多个照相机来成像对象的照相机系统的示意图;
15.图7是用于使用多个2d相机来估计对象的3d姿态的系统的框图;
16.图8是描述了用于在图7所示的系统中估计对象的3d姿态估计的pnp过程的示意图;以及
17.图9是示出了用于预测对象上的特征点的矢量场估计过程的流程图。
具体实施方式
18.以下对本公开的实施例的讨论涉及用于使用深度学习神经网络和矢量场估计过程从图像提取特征的系统和方法,这些讨论本质上仅是示例性的,并且决不旨在限制本发明或其应用或用途。例如,该系统和方法具有用于确定由机器人抓持的对象的位置和取向的应用。然而,该系统和方法可以具有其他应用。
19.图1是机器人系统10的示意图,机器人系统10包括从传送带16拾取对象14并将它们放置在收集箱18中的机器人12。系统10意在表示可以从这里的讨论中受益的任何类型的机器人系统,其中机器人12可以是适合于该目的任何机器人。当对象14在传送带16上向下移动时,每个对象14在传送带16上相对于其它对象14具有不同的取向和位置。为了使机器
人12有效地抓持和拾取对象14,需要能够在抓持对象14之前以适当位置和取向将末端执行器20放置在机器人12上。为了实现这一点,系统10包括相对于对象14设置在期望位置处的2d相机22,其向控制机器人12以移动末端执行器20的机器人控制器24提供2d图像。如下面将详细讨论的,机器人控制器24采用算法将来自相机22的2d图像转换成对象14的3d姿态,以便正确地引导末端执行器20。
20.如将要讨论的,为了使控制器24准确地确定对象14的3d姿态,在一个实施例中,在控制器24中运行的提取对象特征的算法和软件中采用基于学习的神经网络,其中神经网络需要用从代表性对象获得的数据来训练。图2是流程图30,其示出了使用2d相机40从与系统10中的对象14相同的对象32获得将用于训练神经网络的图像数据的过程。对象32被放置在具有适当数量的标记36的标记板34上,并且测量由线38表示的标记34和对象32之间的偏移距离,所述标记36具有特殊的可检测设计,其将被用于标识对象32的真实或实际位置,其中在板34上仅示出一个标记36。
21.相机40以不同的角度提供标记板34的一个或多个2d图像42,这里是四个图像。然后,该过程对图像42执行投影,以确定由坐标框架44标识的各个标记36中的一个的旋转和位置。然后,该算法将先前测量的标记36和对象32之间的偏移加到标记36的旋转和位置上,以确定对象32的旋转和位置。一旦确定了对象32的真实位置,就可以使用已知的特征点提取过程来计算对象32上的诸如拐角之类的特征点46的位置,其中需要最少四个特征点。采用例如高斯分布过程的算法查看在图像42中标识的每个特征点46并且生成该点46的"热图"48,其中每个热图48通过颜色强度来标识对象32的各个特征点中的一个存在于某个位置的概率。例如,图像42中的在其中特征点被认为存在的位置,诸如在区域50,将被分配某种颜色,诸如红色,并且随着特征点存在于远离区域50的位置处的概率降低,诸如在区域52中颜色变为例如蓝色。
22.然后,由2d图像42提供的数据和由图30中所示的过程生成的相应热图48被用来使用已知的ai训练方案来训练神经网络,所述ai训练方案然后将在系统10中用来识别对象14的3d姿态。图3是包括多个节点62的神经网络60的示意图,每个节点具有可调整的权重w,其中网络60旨在一般地表示本文所讨论的神经网络。神经网络60包括从2d图像接收单独像素数据的输入层64、识别2d图像的像素数据中的特征的多个残余块层66和68以及多个卷积层70,其中卷积层70中的每个节点62提供热图。注意,卷积层70和残余块层66和68是在深度学习领域中使用的标准模块。这些类型的卷积层由多个滤波卷积核组成,所述滤波卷积核对图像或先前卷积层的输入执行卷积操作,使得可从该输入中提取边缘、纹理或轮廓信息。残余块层是包含两个具有跳过连接的卷积层的结构,其中第二卷积层的输出被添加到第一卷积层的输入以用作块输出。
23.图4是流程图80,示出了在控制器24中运行的算法,该算法根据由照相机22拍摄的对象14的2d图像82,采用基于学习的神经网络78使用已训练的神经网络来估计对象14的3d姿态。图像82被提供给输入层84和多个连续的残余块层86和88,其包括在控制器24中的ai软件中运行的神经网络78中的前馈回路,该ai软件使用滤波过程提供图像82中的对象14上的可能的特征点的特征提取,例如梯度、边缘、轮廓等。包括所提取的特征的图像被提供给神经网络78中的多个连续卷积层90,其将从所提取的特征获得的可能特征点限定为一系列热图92,每个特征点一个热图,热图基于热图92中的颜色示出该特征点在对象14上存在的
可能性。使用对象14的图像82来生成图像94,其包括来自所有热图92的所有特征点的多个特征点96,其中基于每个特征点96的热图92的颜色给该特征点分配置信度值,并且其中不使用置信度值不高于特定阈值的那些特征点96。
24.然后,在姿态估计处理器98中,将图像94与具有相同特征点的对象14的标称或虚拟3d cad模型进行比较,以提供对象14的估计的3d姿态100。用于将图像94与cad模型进行比较的一种合适的算法在本领域中称为透视n点(pnp)。一般来说,pnp过程在给定世界坐标系中的对象的一组n个3d点及其在来自相机的图像中的对应2d投影的情况下估计对象相对于经校准相机的姿势。姿态包括由对象相对于相机坐标系的旋转(滚动、俯仰和偏航)和3d平移组成的六个自由度(dof)。
25.图5是在该示例中如何实现pnp过程以获得对象14的3d姿态的示意图104。该示意图104示出了在真正或真实位置处的表示对象14的3d对象106。对象106由表示相机22的相机112观察,并在2d图像平面110上投影为2d对象图像108,其中对象图像108表示图像94,并且其中图像108上的点102是神经网络78预测的表示点96的特征点。示意图104还示出了对象14的在与特征点96相同位置处具有特征点132的虚拟3d cad模型114,其被随机放置在相机112前面并且在2d图像平面110上被投影为还包括所投影的特征点118的2d模型图像116。cad模型114在相机112前面旋转和平移,该相机旋转和平移模型图像116,以试图最小化模型图像116上的每个特征点118和对象图像108上的相应特征点102之间的距离,即,对准图像116和108。一旦模型图像116与对象图像108尽可能最佳地对准,cad模型114相对于相机112的姿态就是对象14的估计的3d姿态100。
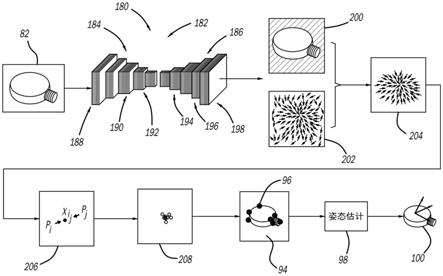
26.对于图像108和116之间的各个对应特征点中的一个,该分析由等式(1)描述,其中等式(1)用于图像108和116的所有特征点。其中,v
i
是cad模型114上的各个特征点132中的一个,ν
i
是模型图像116中的相应投影特征点102,α
i
是对象图像108上的各个特征点102中的一个,r是cad模型114相对于相机112的旋转,t是cad模型114相对于相机112的平移,符号'是矢量转置,并且是指具有索引i的任何特征点。通过用优化解算器求解方程(1),可以计算最优的旋转和平移,从而提供对象14的3d姿态100的估计。
27.采用基于学习的神经网络估计对象14的3d姿态的上述过程提供了很高的准确性。然而,可以进行改进。例如,对象14在图像平面110上的2d投影在与相机112的光学z轴正交的x或y轴上的小像素误差导致z轴上的相对大的误差,这可能显著地产生对象位置不确定性并降低3d姿态估计性能。因此,本公开还提出一种3d姿势估计过程,其通过使用多个相机来减少z轴不确定性。
28.图6是包括相对于x、y和z坐标框架定向的第一相机122和第二相机124的相机系统120的示意图,其中z轴沿着相机122和124的光轴。示出了不确定区域126,其描述了来自相机122的图像能够估计对象14的位置的准确度限制,并且示出了不确定区域128,其描述了来自相机124的图像能够估计对象14的位置的准确度限制。如图所示,相机122和124在x和y轴上都是高度准确的,但是在z轴上的准确度是有限的,其中所有轴上的准确度取决于相机
122或124与被成像的对象14之间的距离。然而,通过融合由相机122和124两者提供的3d姿态估计,估计对象14在z轴上的3d姿态的准确度被显著提高,如不确定区域130所示。换句话说,对于该示意图,相机122和124中的一个的z轴是另一相机122和124的x轴,使得估计过程的一般不确定性是x轴方向上的不确定性。
29.在该非限制性实施例中,相机122和124被定向成使得相机122和124的光轴彼此正交,并且具有从相机122或124到对象14的最佳距离,以提供最小不确定性区域130。然而,真实系统可能受限于相机122和124可以相对于彼此以z轴定位以及相机122或124与对象14之间的距离,以及可能导致非正交光轴和其他限制的其他限制因素,诸如照明、所使用的相机的类型等。在那些系统中,可能需要采用两个以上相机以将不确定性区域的大小减小到更接近于最小不确定性区域130。
30.图7是用于使用2d相机122和124以及上述类型的基于学习的神经网络来估计对象14的3d姿态的系统140的框图。以它们各自的角度,相机122提供对象14的2d图像142和相机124提供对象14的2d图像144。图像142被提供给处理器146和图像144被提供给处理器148,处理器146和148分别生成从它们的角度看类似于图像94的特征点图像150和152,其中处理器146和148使用例如输入层84、多个连续残余块层86和88、和多个连续卷积层90来生成热图,这些热图然后被用于以上述方式生成图像150和152。图像150和152在姿态估计块154中被融合,该姿态估计块生成比单个相机22所能提供的更准确的对象14的估计3d姿态156,其中姿态估计过程也使用如上所述的pnp算法。
31.图8是与示意图104类似的示意图160,其中相同的元件由相同的附图标记标识,其描述了如所讨论的在块154中的用于图像融合的pnp过程。在示意图160中,相机162表示相机122,相机164表示相机124。示意图160示出了具有特征点172的2d模型图像166,其是cad模型114在相机164的2d图像平面170上的投影,以及具有特征点174的2d对象图像168,其是3d对象106在相机164的图像平面170上的投影。cad模型114在相机162和164前面旋转和平移,以同时获得相机162和164两者的最佳模型姿态,其中图像平面110上的模型图像116上的特征点118尽可能靠近对象图像108上的特征点102,并且图像平面170上的模型图像166上的特征点172尽可能靠近对象图像168上的特征点174。一旦这被获得,就获得了3d模型114的最佳取向,其表示对象14的3d姿态。
32.对于图像108和116与图像166和168之间的各个对应特征点中的一个,该分析由等式(2)描述,其中等式(2)用于图像108和116以及图像166和168的所有特征点。式(2)描述,其中等式(2)用于图像108和116以及图像166和168的所有特征点。式(2)描述,其中等式(2)用于图像108和116以及图像166和168的所有特征点。其中u
i
是模型图像166上的各个特征点172之一,b
i
是对象图像168上的对应特征点174。
33.上述用于使用基于学习的神经网络从2d图像提取特征以获得对象14的3d姿态估计的技术是一种合适的特征提取技术。还有其它的方法。以下讨论描述了采用深度学习和向量场估计的特征提取技术,该技术也可以用令人满意的结果来代替基于学习的技术。如
下文将详细论述的,向量场估计过程用向量场估计元素替换包括输入层84、多个连续残余块层86和88以及产生热图92的多个连续卷积层90的神经网络78。然而,要强调的是,尽管这里描述了矢量场估计过程用于获得对象的3d姿态,但是该过程将应用于需要从图像中提取特征的任何合适的过程。
34.图9是流程图180,示出了在控制器24中操作的矢量场估计过程,用于使用由相机22拍摄的对象14的2d图像82来生成对象14的3d姿态,其中相同的元件由相同的附图标记标识。图像输入是由三维矩阵n*n*3限定的三通道rgb(红
‑
绿
‑
蓝)图像,其中n是图像82的高度和宽度。图像82被提供给编码器/解码器神经网络182,其包括提取图像82中的可能关键特征的编码器网络184和从所提取的特征来生成图像以识别对象14上的可能特征点的解码器网络186,如下所述,其中网络184和186两者都包括多个上述类型的神经网络层。特别地,在一个非限制性实施例中,编码器网络184中的神经网络层包括卷积层188、批量归一化(bn)层190和整流线性单元(relu)层192,并且解码器网络186中的神经网络层包括池化层194、上采样层196和softmax层198。
35.网络182对图像82的三维矩阵进行处理,从该三个通道生成每个识别出的特征点的一维(n*n*1)的掩模图像200和二维(n*n*2)的矢量场图像202。为了生成掩模图像200,网络182根据对象14的部分是否存在于特定像素中而给图像82中的每个像素分配数字1或0,其中掩模图像200的亮区域中的像素具有数字1,而掩模图像200的暗区域中的像素具有数字0。每个矢量场图像202包括多个箭头,每个箭头由为图像82中的每个像素提供的x方向矢量值和y方向矢量值限定,其中箭头的方向朝向图像82中的各个特征点中的一个,并且因此图像82中的每个像素具有预测到该特征的方向的能力。掩模图像200中的各个像素的值乘以矢量场图像202中的对应像素的值,使得丢弃与具有对象14的一部分的像素不相关联并且不提供到特征点的有用方向的那些箭头,如矢量场提取图像204所示。
36.矢量场提取图像204中的每个箭头提供到多个特征点中的一个的方向,但是不提供到该特征点的距离。因此,对于矢量场提取图像204中具有值的两个对象像素p
i
和p
j
的每个组合,该过程识别它们的矢量v
i
和v
j
将相交的点x
ij
,如矢量相交图像206所示。根据像素p
i
和点x
ij
之间的距离、像素p
j
和点x
ij
之间的距离以及像素p
i
和p
j
处的梯度幅值,每个点x
ij
被分配一个得分。例如,像素p
i
和点x
ij
之间以及像素p
j
和点x
ij
之间较小的距离提供较高的得分,并且像素p
i
和p
j
处较高的梯度幅值提供较高的得分。结果是具有许多点x
ij
的网格,每个点具有得分,其中图像中具有大部分点x
ij
的区域将标识可能的特征点位置,如点投票图像208所示。
37.矢量场图像202示出了由网络182识别的各个可能特征点中的一个的矢量箭头。网络182还将为每个可能的特征点生成与掩模200相乘的单独的矢量场图像202。将所有点投票图像208的所有特征点组合成单个图像,例如包括特征点96的图像94,其中,由各个点投票图像208中的一个提供每个单独的特征点96。图像94然后可以在姿态估计处理器98中进行pnp过程,以按照上述方式生成3d姿态100。此外,由于如上所述的沿单个相机的光轴的不确定性,可以采用多个相机,其中来自那些相机的各个图像每一个将由矢量场估计过程来处理。
38.如所提到的,矢量场估计过程可以应用于需要特征点提取的其它过程。例如,机器人技术中的一个应用寻找由机器人拾取的对象的中心,其中对象的取向不是必需的。另一
个应用可以是为了质量保证目的而确定对象的测量。
39.如本领域技术人员将充分理解的,这里讨论的描述本发明的若干和各种步骤和过程可以指由计算机、处理器或其他电子计算设备执行的操作,其使用电现象来操纵和/或变换数据。那些计算机和电子设备可以采用各种易失性和/或非易失性存储器,包括其上存储有可执行程序的非瞬态计算机可读介质,所述可执行程序包括能够由计算机或处理器执行的各种代码或可执行指令,其中存储器和/或计算机可读介质可以包括所有形式和类型的存储器和其他计算机可读介质。
40.前述讨论仅公开和描述了本公开的示例性实施例。本领域技术人员将容易地从这样的讨论和从附图和权利要求认识到,在不偏离如在所附权利要求中限定的本公开的精神和范围的情况下,可以在其中进行各种改变、修改和变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1