一种落石梯度优化算法的制作方法
本发明涉及梯度优化算法领域,具体涉及一种落石梯度优化算法。
背景技术:
梯度下降法在sebastianruder.anoverviewofgradientdescentoptimizationalgorithms[eb/ol]提出之后,衍生出了很多优秀的算法,梯度下降算法的概念如下:
假设多元线性回归模型:
其中,
针对实例(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m)),训练模型过程就是求θ0,θ1,θ2,…,θn直至模型对训练数据的拟合程度最佳的过程,每一次训练都会得到拟合值和真实值的差值,即损失值,这个值用于评估模型拟合程度,值越小表示拟合程度越好。
在多元线性回归中,将均方误差(meansquareerror,mse)作为损失函数:
其中,y(i),(i=1,2…,m)为样本真实值,
若公式所得结果大于零,即mse(θ)与θ成正比关系,欲最小化mse(θ),在迭代过程中应该减小θ;反之,应该增大θ。因此,结合符号的正负,减小方向应为公式的相反方向,通过该方向结合步长来更新的每一次迭代的模型参数,找到损失函数的最小值点,即:
其中,α为学习率,也称为寻优步长。通过公式求得下一次迭代的模型参数,将结果带入第一个公式求得下一次的预测值,这就是梯度下降算法的迭代过程。
确定学习率和选择寻优方向是梯度下降算法研究的核心。经过近三年的相关研究,国内外已经取得大量研究成果,研究主要涵盖以下两个方面:(1)梯度下降算法的学习率相关研究提高了算法的收敛速度,解决了非凸目标函数陷入局部次优的问题;(2)基于动量和方差缩减的sgd相关研究解决了sgd的不稳定性。
由于多元线性模型的损失函数是一个凸函数,不存在波峰与波谷,意味着只存在一个全局最小值,不存在局部最小值,虽然这可以解决算法容易陷入局部最小值的问题,但是机器学习中的模型种类繁多,目标函数复杂,使用梯度下降法的效果并不是很好。
在目标函数非凸的情况下,huo,z.等huo,z.,huang,h.asynchronousmini-batchgradientdescentwithvariancereductionfornon-convexoptimization[j]首次基于非凸优化方差约简的异步小批量梯度下降算法的收敛速度进行了理论分析。异步随机梯度下降法(asysgd)已广泛应用于深度学习优化问题,并证明了其在非凸优化问题中的收敛速度为
在模型非线性的情况下,simons.du等simons.du,jasond.lee,haochuanli,etal.gradientdescentfindsglobalminimaofdeepneuralnetworks[eb/ol]证明了训练深度神经网络模型能够得到全局最小值。研究表明了对于具有残差关联的超参数深度神经网络,梯度下降在多项式时间内达到零训练损失,这依赖于由神经网络结构所诱导出的gram矩阵的特殊结构。这种结构证明gram矩阵在整个训练过程中是稳定的,这种稳定性意味着梯度下降算法的全局最优性。
研究进一步将分析扩展到残差深度卷积神经网络,并且得到了相似的收敛结果。
此外,j.flieg等j.fliege,a.i.f.vaz,l.n.vicente(2019)complexityofgradientdescentformultiob-jectiveoptimization[j].optimizationmethodandsoftware,2019,34(5):949-959提出了一些一阶光滑多目标优化方法,并证明了这些方法在某种形式上具有一阶临界全局收敛性。分析了光滑无约束多目标优化问题的梯度下降收敛速度,并用于非凸、凸、强凸向量函数。这些全局速率与单目标优化中的梯度下降率相同,并且适用于最坏复杂度界限的情况。
从前面算法的介绍可以得知:如果学习率太低,算法需要经过大量的迭代后才能收敛,这将会耗费大量的时间;反之,算法可能会陷入局部而无法搜索到全局最小值,甚至搜索结果会大于初始值,必然导致算法发散。另外,模型参数的每个更新都设置同一个学习率也不利于搜索全局最优。当前的解决思路之一通过制定学习率规划(learningrateschedules):算法开始的学习率较大,这有助于跳出局部最优,后来在每次迭代中逐渐减小,慢慢搜索全局最小值。但是更多的研究聚焦在学习率自适应性的问题上。
王功鹏等王功鹏,段萌,牛常勇.基于卷积神经网络的随机梯度下降算法[j].计算机工程于设计,2018,39(2):441-445在解决cnn中学习率设置不恰当对sgd算法的影响,提出了一种学习率自适应sgd的优化算法,该算法随着迭代使得学习率呈现周期性的改变。研究结果表明,通过将这种自适应学习率优化算法与所选择的激活函数相结合,可以加快神经网络模型收敛速度,提升cnn的学习准确率。
严晓明一种逻辑回归学习率自适应调整方法[j].福建师范大学学报(自然科学版),2019,35(3):24-28在使用梯度下降解决logistic回归模型分类问题时,提出一种自适应学习率的调整方法:在不引入新模型参数的同时,根据样本数据集分类准确率的变化对学习率进行更新。在梯度下降稍快时,增大学习率以加快收敛速率,反之则减小学习率以减少算法最优解附近的振荡。
相比于使用固定学习率的神经网络,朱振国等基于权值变化的bp神经网络自适应学习率改进研究[j].计算机系统应用,2018,27(7):205-210提出基于权重变化的自适应学习率更新方法,改进了传统bp神经网络受人为因素限制的缺陷,证明了改进的神经网络具有更快的收敛速度和更高的误差精度。
由于sgd的振荡性,因此目标参数会在目标函数的最小值附近游走,这样的情况下,动量(momentum)在随机梯度下降距离中加入上一次迭代动量更新项,将它作为更新模型参数的下降距离,即:
其中,γ(γ<1)为动量超参数,这意味着在更新模型参数累积了前面所有的动量,对于当前梯度方向与上一次梯度方向一致的参数,下降速度越来越快,反之则速度减慢,因此动量可以加快收敛速度并减少振荡。对于目标函数非光滑优化问题,程禹嘉等heavy-ball型动量方法的最优个体收敛速率[j].计算机研究与发展,2019,56(8):1686-1694通过灵活设置步长,证明了由polyak提出的heavy-ball型动量方法具有最优的单个收敛速率,从而证明了heavy-ball型动量方法可以将投影子梯度方法的个体收敛速率提高至最优。
由于每一次迭代的梯度下降非常快,在损失函数由凸转为凹时会迅速选择凹的路段,因此涅斯捷罗夫梯度加速(nesterovacceleratedgradient,nag)在此基础上进行了优化,它在计算模型参数梯度时,在损失函数中减去了动量项,估计了下一次参数的所在位置:
针对bp神经网络存在的问题,景立森等基于nag的bp神经网络的研究与改进[j].计算机应用与软件,2018,35(11):272-277在nag动量更新的基础上,建立了一种基于黄金比例动量确定隐层神经元的加速梯度策略,并应用于mnist手写字体识别,取得了较好的收敛速度和预测评估结果。
改进的随机方差消减梯度法(stochasticvariancereductiongradient,svrg)可以解决sgd因受到噪声干扰只能达到次线性收敛率问题,王建飞等分布式随机方差消减梯度下降算法topksvrg[j].计算机科学与探索,2018,12(07):1047-1054设计了一种基于svrg算法思想的分布式实现算法topksvrg:在每次迭代时,收敛速率随着参数k的递增而增加,k的减小可以保证算法收敛。研究理论分析了算法的线性收敛性,并通过实验对相关算法的进行比较,证明topksvrg算法有良好的高精度收敛性。张晋晶基于随机梯度下降的神经网络权重优化算法[d].西南大学,2018:1-59提出了移动随机方差消减算法,将梯度移动的平均值作为平均梯度,该算法在学习率很大的情况下,依然能够保证分类的准确率。
上述描述的经典的梯度迭代算法收敛速度和收敛精度不能达到统一。
技术实现要素:
本发明的目的是提出了一种落石梯度优化算法,其精度相对于梯度下降法有了明显的提高。
本发明具体采用如下技术方案:
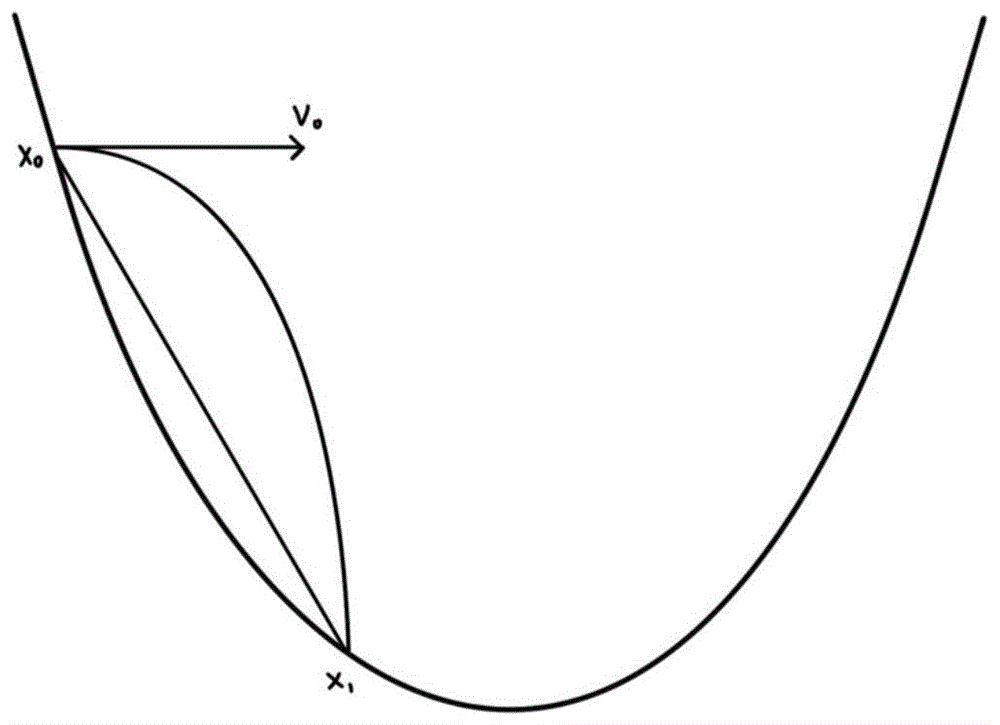
一种落石梯度优化算法,设山谷函数为f(x),求得山谷的最低点即求函数的最小值,包括以下过程:
随机产生初始点x0,初始水平方向速度v0,重力加速度为g,开始做一次平抛运动,石头落在(x1,f(x1))处,从零点平抛的函数表达式为式(1)所示:
则从(x0,f(x0))点平抛的函数表达式为式(2)所示:
如果得到x0和x1的迭代表达式,就能通过一次次迭代求出谷底,即函数的最小值;平抛函数通过山谷函数上的(x1,f(x1)),将x=x1,y=f(x1)带入平抛函数表达式得到式(3)
f(x1)在x0处的处的泰勒展开式为式(4)
取泰勒展开式的前两项的近似,带入方程得式(4)
简化得到式(5)
便得到了落石模型下的迭代式(6)
它形似梯度迭代算法,其中
s是动能损失率,由梯度方向的方向导数变化得出,计算式为(8)
算法是一种变步长的梯度算法,为了防止步长过长导致算法发散,通过函数将速度通过函数映射在步长范围内,选取式(9)所示的函数作为映射函数
λmax为在收敛范围内的最大值,此映射函数能保证在速度大的时候,步长比较大,收敛速度快,并且小于λmax步长的最大值,保持不发散。
本发明具有如下有益效果:
在刚开始落石算法保持着比较高的步长和下降速度,在40步之后迭代速度变慢,迭代精度提高,在最后第80步迭代时两种算法都达到收敛。其中落石迭代算法的精度相对于梯度下降法,提高了近41%,落石梯度优化算法能在参数合适的情况下达到初期迭代速度快后期迭代精度高的效果。
附图说明
图1为山谷函数为f(x)的示意图;
图2为采用时延系统检测落石梯度优化算法的结果示意图;
图3为更换误差之后,以现有参数重新迭代后的落石梯度优化算法的结果示意图;
图4为落石梯度优化算法中迭代速度示意图。
具体实施方式
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
一种落石梯度优化算法,结合图1,设山谷函数为f(x),求得山谷的最低点即求函数的最小值,包括以下过程:
随机产生初始点x0,初始水平方向速度v0,重力加速度为g,开始做一次平抛运动,石头落在(x1,f(x1))处,从零点平抛的函数表达式为式(1)所示:
则从(x0,f(x0))点平抛的函数表达式为式(2)所示:
如果得到x0和x1的迭代表达式,就能通过一次次迭代求出谷底,即函数的最小值;平抛函数通过山谷函数上的(x1,f(x1)),将x=x1,y=f(x1)带入平抛函数表达式得到式(3)
f(x1)在x0处的处的泰勒展开式为式(4)
取泰勒展开式的前两项的近似,带入方程得式(4)
简化得到式(5)
便得到了落石模型下的迭代式(6)
它形似梯度迭代算法,其中
s是动能损失率,由梯度方向的方向导数变化得出,能反应出在这个位置的斜率情况,并且在高维空间同样适用。他会随着函数斜率变化而变化,在动能越大时损失率越大,在动能越小时损失率越小,计算式为(8)
算法是一种变步长的梯度算法,为了防止步长过长导致算法发散,通过函数将速度通过函数映射在步长范围内,选取式(9)所示的函数作为映射函数
λmax为在收敛范围内的最大值,此映射函数能保证在速度大的时候,步长比较大,收敛速度快,并且小于λmax步长的最大值,保持不发散。
基于上述算法,采用时延系统检测算法效果,其中当前时刻的系统受前三秒的输出和前两秒的输入影响。因此,参数的维度是5。由此产生1000组随机数据,并人为增加随机误差。参数设置:g=10v0=10初始速度并不影响最后的收敛效果,图2所示。
映射函数参数设置:b=0.8c=190。
更换误差之后,以现有参数重新迭代,效果如图3所示。
在此模型中,将其与正常的梯度迭代算法相比,传统梯度下降法的步长为定值。在刚开始落石算法保持着比较高的步长和下降速度,在40步之后迭代速度变慢,迭代精度提高,在最后第80步迭代时两种算法都达到收敛。其中落石迭代算法的精度相对于梯度下降法,提高了近41%。
结合图4,落石优化算法中,主要部分为速度的迭代公式,其中下一时刻的速度收上一时刻的速度,前一时刻的参数θt-1和此时刻的θt和损失率s的影响。此算法能够智能识别模型曲面,在遇到较平滑曲面时并不会快速减速,仍保持着比较高的迭代速度。
传统的梯度迭代算法在面对中间具有光滑曲线的函数时,会有可能达到收敛,取决于平滑程度,此算法能智能识别函数曲线,并保持一定的速度惯性,动能只能在碰撞中损失,意味着只有足够多数量的碰撞才能使函数收敛。
以后的发展过程中,可以落石优化算法的基础上融入冲量算法的思想,通过设置方向惯性参数,始算法在落入局部最小值的时候,有几率冲出局部最小值的范围。这样算法相当于同时具有步长惯性和方向惯性。能控制速度的大小不至于发散是重要的改进方向,由于速度过大导致原始算法发散,此算法使用的是映射函数将函数映射在传统的步长范围内。如果有更好的控制速度的办法,就能实现前期速度快后期精度高的理想效果。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!