一种基于多级缓存循环利用的卷积运算处理单元及系统
本发明属于卷积神经网络技术领域,涉及一种基于多级缓存循环利用的卷积运算处理单元及系统。
背景技术:
卷积神经网络在计算机视觉领域发挥着不可替代的作用,基于深度学习算法的数字图像处理技术已广泛应用于人脸识别、安防监控等领域。但是限于模型庞大的计算量与参数量,使得其难以在移动端硬件平台上高效实时实现,严重限制了通用硬件处理器的效率。因此,在硬件端高效快速实现卷积神经网络是数字图像处理领域的一个重要研究方向。
当前对于卷积神经网络硬件加速的主要手段有:针对数据访存方式进行优化,如脉动阵列通过数据复用的方式在使用较小存储带宽下获得了较大的运算吞吐量,但是只有在数据流经整个阵列后才能输出最终结果,难以在计算元素较少的情况下充分发挥优势。针对运算单元的优化,如将输入输出通道完全并行处理,使用循环展开和流水线实现卷积的方式进行片上计算加速。但是,这种优化手段对数据流的控制和访存效率提出了较高要求,若计算吞吐未能很好匹配内存带宽就无法获得最优性能。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供了一种基于多级缓存循环利用的卷积运算处理单元及系统。本发明要解决的技术问题通过以下技术方案实现:
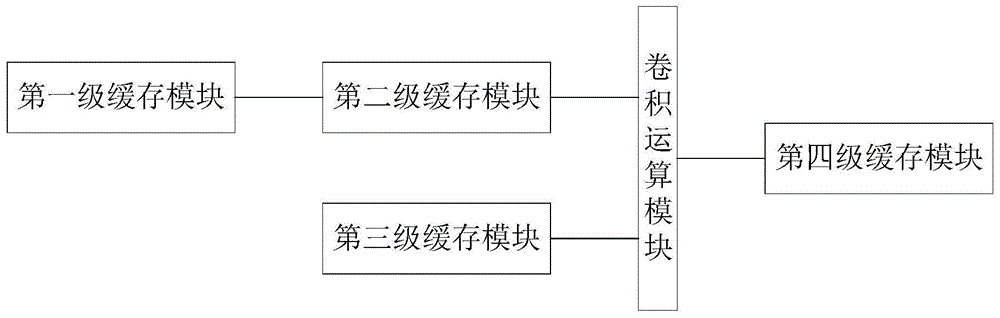
一种基于多级缓存循环利用的卷积运算处理单元,包括:
第一级缓存模块,用于存储中间层的特征图数据;
第二级缓存模块,用于对所述第一级缓存模块输出的若干行或若干列相邻的所述特征图数据进行缓存;
第三级缓存模块,用于存储卷积核参数;
卷积运算模块,用于接收所述第二级缓存模块缓存的所述特征图数据和所述第三级缓存模块缓存的所述卷积核参数,并对所述特征图数据和所述卷积核参数进行卷积运算得到下一层特征图的特征图数据;
第四级缓存模块,用于接收所述卷积运算模块输出的下一层特征图的特征图数据并进行缓存,同时将所述下一层特征图的特征图数据存储至所述第一级缓存模块。
在本发明的一个实施例中,所述第一级缓存模块包括2n个数据cache,第j个所述数据cache用于按照顺序存储特征图上每隔2n行或列后的一行或一列所述特征图数据,其中,n为行或列的并行度,1≤j≤2n。
在本发明的一个实施例中,所述第二级缓存模块包括2n+k-1个linebuffer,每个所述linebuffer用于存储从所述第一级缓存模块输出的一行所述特征图数据,k为卷积核尺寸大小。
在本发明的一个实施例中,所述第四级缓存模块包括2n个输出级寄存器,每个所述输出级寄存器用于存储一行或一列所述卷积运算模块输出的所述下一层特征图的特征图数据,并将所述下一层特征图的特征图数据对应存储至所述数据cache中。
在本发明的一个实施例中,在第一时间单元,所述数据cache中的前n+k-p-1行特征图数据对应写入前n+k-1个所述linebuffer中,其中,若p=1,则第1个所述linebuffer中全部填0,所述数据cache中的前n+k-p-1行特征图数据对应写入第2个所述linebuffer至第n+k-1个所述linebuffer中,若p=0,则将所述数据cache中的前n+k-1行特征图数据对应写入前n+k-1个所述linebuffer中,其中,p=1或者p=0。
在本发明的一个实施例中,在第二时间单元,将前n+k-1个所述linebuffer中的特征图数据和所述第三级缓存模块中的卷积核参数送入卷积运算模块进行运算,以得到下一层特征图的n行特征图数据,并将该所述下一层特征图的n行特征图数据对应存放于前n个所述输出级寄存器中,与此同时,保留后k-1个所述linebuffer中的特征图数据,按照顺序将接下来的n个所述数据cache中的n行特征图数据写入剩下的n个所述linebuffer中。
在本发明的一个实施例中,在第三时间单元,将所述第二时间单元的n+k-1个linebuffer中的特征图数据送入卷积运算模块进行运算,以得到下一层特征图的n行特征图数据,并将该所述下一层特征图的n行特征图数据对应存放于后n个所述输出级寄存器中,与此同时,保留后k-1个所述linebuffer中的特征图数据,按照顺序从n个所述数据cache中向未存放所述第三时间单元的特征图数据的n个linebuffer中写入接下来的n行所述特征图数据,并且同时将所述第二时间单元前n个所述输出级寄存器中的下一层特征图的n行特征图数据按照顺序读出至此时未向所述linebuffer写入特征图数据的n个数据cache的对应位置中,之后按照所述第一时间单元、所述第二时间单元和所述第三时间单元的方式循环执行直至所有特征图数据处理完毕。
在本发明的一个实施例中,所述卷积运算模块包括若干用于并行运算的dsp,每个所述dsp在一个时钟周期内完成(a×c)和(b×c)两次乘法,其中,当a、b分别对应不同特征图数据时,c对应同一卷积核参数,当a、b分别对应不同卷积核参数时,c对应同一特征图数据。
在本发明的一个实施例中,利用移位寄存器对a的数据位左移16位作为高16位,b的数据直接作为低8位,将高16位和低8位组合为24位输入乘法因子完成编码过程,c的数据位直接作为另一输入乘法因子,接下来将两个乘法因子同时送入dsp中完成乘法运算得到乘积结果,利用移位寄存器对所述乘积结果的高16位进行移位取出,对所述乘积结果的低16位直接取出完成解码,根据乘积结果的符号位得出两次乘法的最终结果,将所述最终结果送入加法器对应相加完成卷积运算。
本发明一个实施例还提供一种基于多级缓存循环利用的卷积运算处理系统,包括上述任一项实施例所述的卷积运算处理单元。
与现有技术相比,本发明的有益效果:
本发明基于多级缓存循环利用机制设计实现了一种卷积运算处理单元,可以最大程度实现高效访存与数据级并行与流水线计算,充分隐藏数据搬移时间和提升卷积运算效率。
与现有的硬件结构相比,本发明能够基于可配置的多级缓存机制灵活适应不同并行度和不同滤波器尺寸的传统卷积运算以及depthwise卷积运算,并通过多级缓存循环复用的方式充分提高各存储资源利用率,从而在更少消耗资源的前提下获取更快的速度。
通过以下参考附图的详细说明,本发明的其它方面和特征变得明显。但是应当知道,该附图仅仅为解释的目的设计,而不是作为本发明的范围的限定,这是因为其应当参考附加的权利要求。还应当知道,除非另外指出,不必要依比例绘制附图,它们仅仅力图概念地说明此处描述的结构和流程。
附图说明
图1为本发明实施例提供的一种基于多级缓存循环利用的卷积运算处理单元的结构示意图;
图2为本发明实施例提供的另一种基于多级缓存循环利用的卷积运算处理单元的结构示意图;
图3为本发明实施例提供的一种传统卷积数据级并行计算方式的示意图;
图4为本发明实施例提供的一种depthwise卷积数据级并行计算方式的示意图;
图5为本发明实施例提供的一种流水线单元结构的示意图;
图6为本发明实施例提供的一种高低位编解码运算机制的示意图;
图7为本发明实施例提供的一种系统整体结构的示意图。
具体实施方式
下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
实施例一
请参见图1,图1为本发明实施例提供的一种基于多级缓存循环利用的卷积运算处理单元的结构示意图。本发明实施例提供了一种基于多级缓存循环利用的卷积运算处理单元,该卷积运算处理单元包括四级ram(randomaccessmemory,随机存取存储器)缓存和运算模块,分别为第一级缓存模块、第二级缓存模块、第三级缓存模块、卷积运算模块和第四级缓存模块,其中:
第一级缓存模块,用于存储中间层的特征图数据;
第二级缓存模块,用于对第一级缓存模块输出的若干行或若干列相邻的特征图数据进行缓存;
第三级缓存模块,用于存储卷积核参数;
卷积运算模块,用于接收第二级缓存模块缓存的特征图数据和第三级缓存模块缓存的卷积核参数,并对特征图数据和卷积核参数进行卷积运算得到下一层特征图的特征图数据;
第四级缓存模块,用于接收卷积运算模块输出的下一层特征图的特征图数据并进行缓存,同时将下一层特征图的特征图数据存储至第一级缓存模块。
需要说明的是,以下为了便于叙述,均以行为例进行说明,而列的情况与行的情况相同。
本实施例的卷积运算处理单元主要作用是控制数据流的高效传输,循环利用多级缓存合理隐藏掉数据的写入与读出时间以实现高效访存,是本实施例的高级处理单元。循环利用的多级缓存基于可灵活配置的行缓存机制实现,开辟了四级ram缓存。
具体地,请参见图2,第一级缓存模块包括2n个数据cache(高速缓冲存储器),第j个数据cache用于按照顺序存储特征图上每隔2n行或列后的一行或一列特征图数据,其中,n为行或列的并行度,1≤j≤2n。
也就是说,第1个数据cache用于按照顺序存储特征图的第1行特征图数据、第2n+1行特征图数据、第4n+1行特征图数据等,第2个数据cache用于按照顺序存储第2行特征图数据、第2n+2行特征图数据、第4n+2行特征图数据等,第3个数据cache用于按照顺序存储第3行特征图数据、第2n+3行特征图数据、第4n+3行特征图数据等,依此类推,例如,当n为2时,则有4个数据cache,第1个数据cache用于按照顺序存储特征图的第1行特征图数据、第5行特征图数据、第9行特征图数据等,第2个数据cache用于按照顺序存储第2行特征图数据、第6行特征图数据、第10行特征图数据等,第3个数据cache用于按照顺序存储第3行特征图数据、第7行特征图数据、第11行特征图数据等,第4个数据cache用于按照顺序存储第4行特征图数据、第8行特征图数据、第12行特征图数据等。
其中,n为数据级运算单元中行或列的并行度。
优选地,n的取值范围为1~5。
具体地,请参见图2,第二级缓存模块包括2n+k-1个linebuffer(行缓存),每个linebuffer用于存储从第一级缓存模块输出的一行特征图数据。
也就是说,每次若干个数据cache会将对应的特征图数据对应传输至linebuffer中,每个linebuffer存储一行特征图数据。
具体地,请参见图2,第三级缓存模块为权重cache,用于存储卷积核参数。
具体地,请参见图2,第四级缓存模块包括2n个输出级寄存器,每个输出级寄存器用于存储一行或一列卷积运算模块(即pe)输出的下一层特征图的特征图数据,并将下一层特征图的特征图数据对应存储至数据cache中。
也就是说,卷积运算模块通过卷积运算后会对应得到下一层特征图的特征图数据,而下一层特征图的每行特征图数据对应存储至一个输出级寄存器,从而使得输出级寄存器中存储的特征图数据能够传输至数据cache中,从而实现循环利用缓存。
需要说明的是,在本实施例中,上述参数可根据要处理的具体网络结构和硬件平台资源灵活配置,以最大程度发挥平台算力。
在本实施例中,中间层的整张特征图数据以行为单位分为2n块交替存储于不同的数据cache,所有卷积核参数存放于权重cache中,每个linebuffer深度为一整行所有数据长度(包含所有通道维),输出级寄存器用于存放每次输出的n个运算结果。
在一个具体地实施例中,卷积运算处理单元的卷积运算步骤包括:
步骤1、在第一时间单元,数据cache中的前n+k-p-1行特征图数据对应写入前n+k-1个linebuffer中,其中,若p=1,则第1个linebuffer中全部填0,数据cache中的前n+k-p-1行特征图数据对应写入第2个linebuffer至第n+k-1个linebuffer中,若p=0,则将数据cache中的前n+k-1行特征图数据对应写入前n+k-1个linebuffer中,其中,p=1或者p=0。
在本实施例中,p代表是否padding(填充),padding表示在特征图的四周填充一圈0,若padding,则p=1,则表示填充0,若不padding,则p=1,则表示不用填充。
例如,n=2,k=3,p=1,则n+k-p-1=3,则将第1个linebuffer中全部填0,第1个数据cache至第3个数据cache中的前3行特征图数据对应写入第2个linebuffer至第4个linebuffer中。
步骤2、在第二时间单元,将前n+k-1个linebuffer中的特征图数据和第三级缓存模块中的卷积核参数送入卷积运算模块进行运算,以得到下一层特征图的n行特征图数据,并将该下一层特征图的n行特征图数据对应存放于前n个输出级寄存器中,与此同时,保留后k-1个linebuffer中的特征图数据,按照顺序将接下来的n个数据cache中的n行特征图数据写入剩下的n个linebuffer中。
也就是说,在第二时间单元,将第一时间单元的前n+k-1个linebuffer中的特征图数据和第三级缓存模块中存储的对应的卷积核参数送入卷积运算模块以便于进行卷积运算(即乘加运算),从而可以得到下一层特征图的n行特征图数据,例如,n=2,k=3,p=1,则前4个linebuffer的特征图数据和第三级缓存模块中存储的对应的卷积核参数送入卷积运算模块,前3个linebuffer的特征图数据会和卷积核参数得到1行下一层特征图的特征图数据,后3个linebuffer的特征图数据会和卷积核参数得到1行下一层特征图的特征图数据,从而可以得到两行下一层特征图的特征图数据,由此,两行下一层特征图的特征图数据按照顺序对应存储至输出级寄存器中。且在第二时间单元,为了便于后续的运算,需要保留第一时间单元的前n+k-1个linebuffer中的后k-1个linebuffer中的特征图数据,例如保留后2个linebuffer中的特征图数据,前n个linebuffer中的特征图数据则清空,然后按照顺序将第一时间单元中前n+k-p-1行特征图数据之后的n个数据cache中的n行特征图数据写入剩下的n个linebuffer中(即保留的k-1个linebuffer之后的n个linebuffer中)。
步骤3、在第三时间单元,将第二时间单元的n+k-1个linebuffer中的特征图数据送入卷积运算模块进行运算,以得到下一层特征图的n行特征图数据,并将该下一层特征图的n行特征图数据对应存放于后n个输出级寄存器中,与此同时,保留后k-1个linebuffer中的特征图数据,按照顺序从n个数据cache中向未存放第三时间单元的特征图数据的n个linebuffer中写入接下来的n行特征图数据,并且同时将第二时间单元前n个输出级寄存器中的下一层特征图的n行特征图数据按照顺序读出至此时未向linebuffer写入特征图数据的n个数据cache的对应位置中,之后按照第一时间单元至第三时间单元的方式循环执行直至所有特征图数据处理完毕。
也就是说,在第三时间单元,将所保留的k-1个linebuffer中的特征图数据和其后面的n个linebuffer中的特征图数据送入卷积运算模块以便于进行卷积运算,从而得到下一层特征图对应的n行特征图数据,并将所得到的该n行特征图数据对应存放于还未存放特征图数据的输出级寄存器中,与此同时,再保留第三时间单元中n+k-1个linebuffer中的后k个linebuffer特征图数据以便于进行后续的运算,并且同时还要继续按照顺序从n个数据cache提取第二时间单元之后的n行特征图数据写入到未存放第三时间单元的特征图数据的n个linebuffer中,同时,还需要将第二时间单元前n个输出级寄存器中的下一层特征图的n行特征图数据按照顺序读出至此时未向所述linebuffer写入特征图数据的n个数据cache的对应位置中,例如将下一层特征图的第1行特征图数据存入第1个数据cache用于存储当前层特征图的第1行特征图数据的位置,下一层特征图的第2行特征图数据存入第2个数据cache用于存储当前层特征图的第2行特征图数据的位置,下一层特征图的第3行特征图数据存入第3个数据cache用于存储当前层特征图的第3行特征图数据的位置,下一层特征图的第4行特征图数据存入第4个数据cache用于存储当前层特征图的第4行特征图数据的位置,下一层特征图的第5行特征图数据存入第1个数据cache用于存储当前层特征图的第5行特征图数据的位置,下一层特征图的第6行特征图数据存入第2个数据cache用于存储当前层特征图的第6行特征图数据的位置,依此类推,由此,第三时间单元已完全实现写入、计算、读出的并行。
接下来,只需循环各级缓存重复完成步骤1至步骤3直至所有行特征图数据处理完毕。
在本实施例中,2n+k-1个linebuffer轮流复用数据cache中缓存的特征图数据,输出级寄存器轮流将运算结果送回数据cache中,每处理完一行数据将linebuffer和输出级寄存器依次交换位置,这种循环利用的多级缓存机制在最大程度节约硬件资源的前提下实现了高效访存,充分节省了输入和输出的数据传输时间。
在一个具体实施例中,卷积运算模块是一种数据级并行计算模块,其是将权重cache存放的cin×cout×k×k个卷积核参数,和这些卷积核参数对应的h或w行特征图同时送入下一级寄存器模块以准备进行完全并行的数据乘法运算,其中cin、cout、k、h、w分别为完全并行处理的输入通道维度、输出通道维度、卷积核尺寸大小、特征图高度、特征图宽度。
需要说明的是,在本实施例中,这些卷积核参数可根据要处理的具体网络结构和硬件平台资源灵活配置,以最大程度发挥平台算力。
数据级并行计算模块完成了对一组数据的完全并行处理,但由于硬件平台资源有限,无法对所有的卷积核参数和特征图数据同时完成并行处理。因此将所有数据分成数据量相同的若干组,将其分别送入数据级并行运算模块进行处理。不同组之间的数据处理采用流水线的方式实现,通过合理利用存储资源,将此流水线启动间隔(initiationinterval,ii)优化至一个时钟周期以最大程度提升硬件性能。
具体地,请参见图3、图4、图5和图6,卷积运算模块包括若干用于并行运算的dsp,每个dsp在一个时钟周期内完成(a×c)和(b×c)两次乘法,其中,当a、b分别对应不同特征图数据时,c对应同一卷积核参数,当a、b分别对应不同卷积核参数时,c对应同一特征图数据,其中,a、b、c为已量化为8位整型的数据,在depthwise卷积中a、b分别对应不同特征图数据,c对应同一卷积核参数,而在pointwise卷积和传统卷积中a、b分别对应不同卷积核参数,c对应同一特征图数据,其中传统卷积例如为输入32通道、输出32通道、卷积核3×3、步长为1的卷积结构。
进一步地,首先根据乘法因子符号位判定乘积结果的符号位,将其暂存于寄存器。然后取绝对值作为数据位参与运算,具体地,利用移位寄存器对a的数据位左移16位作为高16位,数据b直接作为低8位,将a的高16位和b的低8位组合为24位输入乘法因子完成编码过程,c的数据位直接作为另一输入乘法因子,接下来将两个乘法因子同时送入dsp(如dsp48e2)模块完成乘法运算得到乘积结果。利用移位寄存器对乘积结果的高16位进行移位取出,低16位直接取出完成解码,根据乘积结果的符号位得出两次乘法的最终结果,将所有最终结果送入加法器对应相加完成整个卷积运算得到卷积结果。根据各网络层结构,利用选择器判定是否将卷积结果送入bn和relu非线性校正单元,最后将最终的卷积结果存入至输出级寄存器组。
本发明提出了一种高速处理卷积运算的卷积运算处理单元,并可根据网络结构和硬件平台资源灵活配置,基于socfpga平台进行了验证。相较于其他方法,该卷积运算处理单元能够更快的处理整个卷积过程。
本发明的卷积运算处理单元可用于基于卷积神经网络的图像处理任务加速中。
本发明基于多级缓存循环利用机制设计实现了一种卷积运算处理单元,可以最大程度实现高效访存与数据级并行与流水线计算,充分隐藏数据搬移时间和提升卷积运算效率。
与现有的硬件结构相比,本发明能够基于可配置的多级缓存机制灵活适应不同并行度和不同滤波器尺寸的传统卷积运算以及depthwise卷积运算,并通过多级缓存循环复用的方式充分提高各存储资源利用率,从而在更少消耗资源的前提下获取更快的速度。
实施例二
本实施例在上述实施例的基础上还提供一种卷积运算处理系统,该卷积运算处理系统包括权实施例一所述的卷积运算处理单元。
具体地,请参见图7,该硬件整体系统(即卷积运算处理系统)基于socfpga实现,是本发明的最高级处理单元。该硬件整体系统为嵌入式系统,该嵌入式系统分为负责系统级任务控制的ps模块和可编程电路的pl模块两部分,arm核心控制整个系统工作,pl实现对卷积运算的加速处理。将图像和权重数据预先缓存于ddrdram中。
其中,ps模块包括arm和ddr(例如为ddr4),其中arm用于用于控制整个系统的工作,ddr用于存储特征图数据和权重(即卷积核参数)数据,pl模块包括axidma模块、数据cache、权重cache、数据buffer(即linebuffer)和输出buffer,本实施例通过配置axi4总线协议实现ps模块与pl模块之间的通信,配置axidma模块实现数据高效搬移。首先将图像数据和权重数据分别通过数据fifo和权重fifo缓存由ddr传入至数据buffer和权重cache,再送入processelement(pe)单元进行网络第一层处理,pe单元具体实现方式如实施例一所述。第一层结果处理完成后存入数据cache,再将此结果送入pe单元进行网络下一层处理,以此类推。当所有层推理完成后,将数据cache中数据送入输出buffer中,再通过输出fifo缓存由axi4传输至ps端的ddr中,完成整个处理过程。数据buffer和输出buffer两级缓存可用于处理存在残差结构的网络模型,可将中间层结果暂存于此,便于后续的残差单元处理,进一步增强了本发明的灵活普适性。
本发明的效果可以通过以下仿真实验进一步说明。
下面通过单张特征图的处理时间来量化对照本发明中的硬件处理单元和传统专用硬件结构性能。均对256×256×32特征图分別进行普通卷积操作处理和深度可分离卷积操作处理,输出通道均为32,普通卷积核和depthwise卷积核尺寸均为3×3,同时将bn层和relu激活单元也进行处理。实验平台均为xilinxzynqzcu102开发板,主频均为150mhz,实验结果如表1所示。
表1专用硬件结构性能对比表
由表1可见:
经本发明提出的硬件处理单元处理传统卷积和深度可分离卷积的时间均明显小于传统硬件结构,说明经本发明硬件处理单元实现卷积运算的性能更优,速度更快。
下面通过单张特征图传统卷积和深度可分离卷积的处理时间指标来量化对照本发明中的硬件处理单元和通用处理器结构的性能,各实验条件与上一实验相同。实验结果见表2。
表2通用硬件结构性能对比表
由表2可见,本发明系统在处理卷积运算时比通用处理器平台具有更快的处理速度。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。此外,本领域的技术人员可以将本说明书中描述的不同实施例或示例进行接合和组合。
尽管在此结合各实施例对本申请进行了描述,然而,在实施所要求保护的本申请过程中,本领域技术人员通过查看所述附图、公开内容、以及所附权利要求书,可理解并实现所述公开实施例的其他变化。在权利要求中,“包括”(comprising)一词不排除其他组成部分或步骤,“一”或“一个”不排除多个的情况。单个处理器或其他单元可以实现权利要求中列举的若干项功能。相互不同的从属权利要求中记载了某些措施,但这并不表示这些措施不能组合起来产生良好的效果。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!