一种基于深度学习和迁移学习的贫乏信息建筑负荷预测方法与流程
1.本发明属于相连电力网络之间负荷分配的控制领域,尤其涉及一种用于区域综合能源系统的模型预测方法。
背景技术:
2.区域综合能源系统(district integrated energy system,dies)是指分布在用户端的能源综合利用系统,以传统三联供cchp(combined cooling heating and power,亦称冷热电三联供)为基础,结合当地可再生资源,向一定园区或建筑群同时提供冷、热、电和蒸汽需求。
3.在全球范围内,建筑能耗目前约占总能耗的40%,这使得建筑运营性能的优化在当今的世界建筑节能会议中至关重要。以我国建筑能耗为例,我国已成为第二大能源消费国,建筑能耗约占我国能源消耗总量的30%。因此,建筑能耗具有相当大的节能潜力。这就需要对建筑能耗进行准确的预测,因为预测的准确性将直接影响到建筑能源设备的控制策略,从而影响到建筑的潜在节能。因此,准确的建筑能耗预测对电网和需求管理的最终用户都有好处,可以进一步降低电网的运营风险。
4.准确预测建筑能耗可以极大地优化建筑设备的运行策略,释放建筑的节能潜力。随着计算机科学和智能电表的进步,数据驱动的能源预测模型,特别是深度学习模型,因其可以实现良好的预测精度,正变得越来越流行。然而,这些模型需要大量来自预测建筑物的历史数据来进行训练,而这些数据对于新建建筑物或有新测量设备的建筑物(简称为“贫乏信息建筑”)来说很难获得。
5.授权公告日为2020年9月25日,授权公告号为cn 108879692 b的中国发明专利,公开了“一种区域综合能源系统能流分布预测方法及系统”,,该方法包括以下步骤:采集多能流网络数据;构建多能流网络数据表示模型;挖掘能流分布相关的多源时空特征;输出能流分布预测结果。该系统包括以下模块:多能流网络数据表示模块;能流分布空间特征提取模块;能流分布时序特征提取模块;能流分布外部因素特征提取模块;能流分布特征融合模块;能流分布预测输出模块。该加护方案基于网络表示学习方法和深度学习方法对多能流网络数据进行转化和分析,挖掘能流分布相关的时空特征和外部因素特征,为区域综合能源系统能流分布状态预测问题提供新的方法和技术基础。但是,该技术方案首先需要掌握各能源节点能流信息和影响能流分布的外部因素信息,在训练阶段基于历史数据计算各时段的能流时空分布张量预测值和对应实际值的交叉熵损失值,通过交叉熵损失值迭代更新前述步骤中的神经网络模型参数。如前所述,该技术方案需要大量来自预测建筑物的历史数据来进行训练,而这些数据对于新建建筑物或有新测量设备的建筑物来说很难获得。
6.申请公布日为2018年12月4日,申请公布号为cn 108932560 a的发明专利申请,公开了一种“基于模型预测控制的园区综合能源系统优化调度方法”,:根据选定的园区综合能源系统,输入园区综合能源系统的结构和参数;建立园区综合能源系统运行约束;设定园区综合能源系统滚动优化阶段预测域内运行费用和设备启停费用之和最小为目标函数,动
态调整阶段单个时间间隔内运行费用和功率调整惩罚费用之和最小为目标函数;采用基于滚动优化的多时间尺度优化调度方法进行优化调度;输出系统一个调度周期内调度计划:运行费用、太阳能热水系统供热水功率、地源热泵和电锅炉启停指令、运行工况、供能功率、蓄热水箱运行工况和供能功率。该技术方案是在现有园区综合能源系统的基础上,对园区综合能源系统进行优化调度,可有效减小负荷以及可再生能源出力预测误差的影响,经济可靠地满足系统用能需求。但是其不能应用于新建建筑物或有新测量设备的建筑物,在实际应用时受到一定的限制。
7.在区域综合能源系统的规划或设计过程中,基于供需侧动态变化预测,及时调整系统运行方式和运行策略是区域综合能源系统运行的关键技术手段,也是目前区域综合能源系统发展迫切需要解决的问题。在对于新建筑物的能耗预测过程中,如何能够通过对建筑能耗的准确预测,从而减少建筑的总能耗,是一个急待解决的实际技术问题。
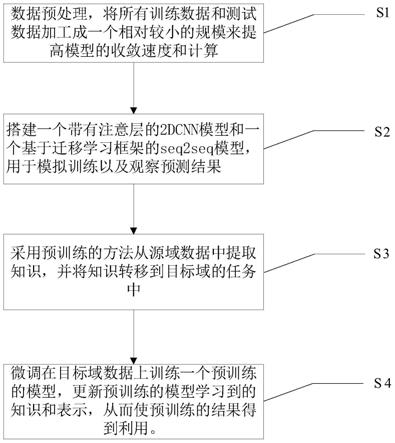
技术实现要素:
8.本发明所要解决的技术问题是提供一种基于深度学习和迁移学习的贫乏信息建筑负荷预测方法。其采用一个带有注意层的2d
‑
cnn模型和一个基于迁移学习框架的seq2seq模型,通过使用来自相似建筑的历史数据,提高目标建筑在信息贫乏情况下的负荷预测的准确性,并通过不同的实验来验证迁移学习模型在不同的预训练数据下的性能,从而提高了传统预测方法的精度。
9.本发明的技术方案,提供了一种基于深度学习和迁移学习的贫乏信息建筑负荷预测方法,其特征在于,包括以下步骤:
10.第一步:数据预处理,将所有训练数据和测试数据加工成一个相对较小的规模,来提高模型的收敛速度和计算;
11.第二步:搭建一个带有注意层的2d
‑
cnn模型和一个基于迁移学习框架的seq2seq模型,用于模拟训练以及观察预测结果;
12.第三步:采用预训练的方法从源域数据中提取知识,并将知识转移到目标域的任务中;数据增强被提出作为一种增加训练数据量的技术,用以提高模型的泛化性和鲁棒性;
13.第四步:微调在目标域数据上训练一个预训练的模型,可以更新预训练的模型学习到的知识和表示,从而使预训练的结果得到利用。
14.具体的,在第一步中所述数据预处理的方法,包括最大最小值法、z
‑
score方法、对数标准化和独热编码one
‑
hot code。
15.具体的,在第二步中,所述带注意层的2d
‑
cnn模型带有注意层作为迁移学习和预测能量消耗的框架,并采用多注意层来捕捉时间依赖性特征;所述的基于迁移学习框架的seq2seq模型作为迁移学习的主要模型,为提高该模型的性能,使其记住长期信息,使用lstm的两层作为编码器和解码器。
16.具体的,在第三步中所述的预训练中,预训练从源域获得一个完整的上下文向量,为了提取足够数量的高级特征,在类似的领域进行训练;在较大的源域上预训练模型,然后冻结一些顶层,并使用目标域数据微调这些层。
17.具体的,在第四步中,所述的微调在目标域数据上训练一个预训练的模型,从而更新预训练学习到的知识和表示,从而使预训练的结果得到利用。
18.与现有技术比较,本发明的优点是:
19.1.本发明的技术方案,将迁移学习应用到训练数据贫乏的区域综合能源系统建筑负荷预测当中,通过使用来自相似建筑的历史数据,将其他相同类型建筑的能耗数据作为训练集的一部分进行训练,以期通过其他建筑的历史数据获取知识,来提高目标建筑在能源相关信息贫乏情况下的负荷预测的准确性;
20.2.本技术方案提出了两个新颖的深度学习模型:一个带有注意层的2d
‑
cnn和一个基于迁移学习框架的seq2seq模型;搭建这些模型的目的是通过使用来自相似建筑的历史数据,提高目标建筑在信息贫乏情况下的负荷预测性能;
21.3.本技术方案采用两种深度学习模型和迁移学习框架对建筑能耗进行预测,通过不同的实验来验证迁移学习模型在不同的预训练数据下的性能,提升目标建筑的预测性能并获得更好的预测精度,而提高了传统预测方法的精度。
附图说明
22.图1为本发明基于深度学习和迁移学习的贫乏信息建筑负荷预测方法的方框图。
23.图2为本发明迁移学习方法示意图。
24.图3为简单的rnn网络图。
25.图4为lstm单元的结构图。
26.图5为本发明seq2seq模型的框架图。
27.图6为本发明2d
‑
cnn框架图。
28.图7为一个简单的数据增强的方法示意图。
29.图8为本发明微调策略示意图。
具体实施方式
30.下面结合附图对本发明做进一步说明。
31.精确预测建筑能耗可以显著优化建筑设备运行策略,释放建筑节能潜力。随着计算机科学和智能电表的进步,数据驱动的能源预测模型,特别是深度学习模型,正变得越来越流行,并且可以实现良好的预测精度。然而,这些模型需要来自预测建筑物的大量历史数据用于训练,这对于新建建筑物或具有新建立的测量设备的建筑物来说是难以获得的。对于新建建筑或新建能耗监测平台的建筑来说,其建筑能耗信息通常来说较为稀缺,不足以单独使用自身的历史负荷数据训练模型。为了在这种不良信息状态下获得令人满意的预测精度,本技术方案中使用其他相同类型建筑的能耗数据作为训练集的一部分进行训练,使用两种不同方向中具有代表性的网络层,提出了两种迁移学习模型:(1)序列到序列(sequence to sequence)模型(以下简写为seq2seq),它使用lstm作为编码器和解码器;(2)结合注意力(attention)机制的二维卷积神经网络(2d convolutional neural network)模型(以下简写为2dcnn);它具有一个关注层,通过转移从类似建筑物中学习的知识来提高预测精度。并转移学习框架以提高目标建筑物的预测精度;以期通过其他建筑的历史数据获取知识,并提升目标建筑的预测性能并获得更好的预测精度。
32.如图1所示,本发明的技术方案,提供了一种基于深度学习和迁移学习的贫乏信息建筑负荷预测方法,包括以下步骤:
33.第一步:数据预处理,将所有训练数据和测试数据加工成一个相对较小的规模来提高模型的收敛速度和计算;
34.第二步:搭建一个带有注意层的2d
‑
cnn模型和一个基于迁移学习框架的seq2seq模型,用于模拟训练以及观察预测结果;
35.第三步:采用预训练的方法从源域数据中提取知识,并将知识转移到目标域的任务中;数据增强被提出作为一种增加训练数据量的技术,用以提高模型的泛化性和鲁棒性;
36.第四步:微调在目标域数据上训练一个预训练的模型,可以更新预训练的模型学习到的知识和表示,从而使预训练的结果得到利用。为了满足迁移学习的要求,从源数据集中提取知识,所述的seq2seq模型和2d
‑
cnn模型需要一个微调过程。
37.其中,步骤s1中数据预处理,将所有训练数据和测试数据加工成一个相对较小的规模来提高模型的收敛速度和计算,是机器学习模型和深度学习模型的关键步骤,可以显著提高模型的性能。如果不进行预处理,模型就会将价值相对较大的特征识别为对模型贡献更大的特征,性能将严重下降,模型可能无法收敛。当数据预处理过程运行时,模型中的每个特性可以保持相似的权重并对模型做出相似的贡献。因此,整个尺度范围的特征可以作为模型不可分割的一部分。
38.本技术方案中的数据预处理主要有四种方法:最大最小值法(min max)、z
‑
score方法、对数标准化(log归一化)和独热编码法(one
‑
hot code)。
39.最小最大方法是机器学习和深度学习领域中最有用的归一化方法之一。对于方差相对较小的数据,能保持数据的稳定性。此外,它可以在稀疏矩阵中保持一个0的条目。最小最大方法由方程表示:
[0040][0041]
式中,其中x为目标特征的值;x
min
和x
max
分别为该特征的最小值和最大值。这个方程限制了特征值,使它在提交给模型之前处于0到1之间;
[0042]
z
‑
score也称为标准化法,是另一种广泛使用的标准化方法。z分数可以表示为:
[0043][0044]
其中μ是所有x值的均值,σ表示它们的标准差。z是标准化x的结果;
[0045]
由于测试数据集中标签的均值和标准差是未知的,因此使用z
‑
score从测试数据集中获得合适的归一化结果可能比较困难,而采用log归一化方法可以解决上述问题,log归一化方法的表达式为:
[0046][0047]
对数规范化可以减轻数值稳定性差所造成的不利影响。此外,对数标准化也有利于物理意义参数的估计。
[0048]
以上的标准化方法往往是对于数值型数据的预处理方法(如温度,湿度,能耗等),但数据中的类别特征(例如是否今日是否放假)往往需要独热编码进行处理。独热编码又称one
‑
hot编码,其方法是使用n位状态寄存器来对n个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。对于每一个特征,如果它有m个可能值,那
么经过独热编码后,就变成了m个二元特征(例如,成绩这个特征,有“好”、“中”、“差”;变成独热编码就是100,010,001)。并且,这些特征互斥,每次只有一个激活。因此,数据的维度会变大,同时也较为稀疏。
[0049]
单热编码对于具有分类值而非连续值的特性的场景是有效的。单热码是一组位,其中唯一合法的值组合是只有一个高(1)位,其他所有位都是低(0)的值。该方法能够对属性数据进行处理,对特征的扩展起到一定的作用。本技术方案中,对每种分类特征采用单热编码。
[0050]
步骤s2中搭建了一个带有注意层的2d
‑
cnn模型和一个基于迁移学习框架的seq2seq模型。
[0051]
由于新建筑物和具有新能源监测平台的建筑物的良好信息的稀疏性,本技术方案使用来自相似建筑物的额外数据作为训练集的一部分,以提高预测性能并获得更好的预测结果。由于两栋建筑的能耗数据互不相同,该任务可归类为归纳迁移学习。
[0052]
图2提供了迁移学习的技术流程,其整体过程大体可以分为五个部分组成:
[0053]
(1)数据预处理:将所有的训练数据与测试数据归一化到一个相对小的范围内,这样有利于加速模型的计算与收敛速度;
[0054]
(2)序列到序列(seq2seq)模型的构建:本技术方案通过构建一种seq2seq模型,用于迁移学习的能耗预测;
[0055]
(3)二维卷积神经网络(2d cnn)与注意力(attention)机制模型的构建:除去seq2seq模型外,本技术方案还将二维卷积神经网络与注意力机制相结合,构建了一种深度学习网络用于迁移学习预测;
[0056]
(4)模型预训练(pretraining)与数据增强(data augmentation)方法:通过对源域的预训练让网络学习源域中的知识,保存权重为迁移学习做好准备,同时针对seq2seq模型使用数据量较大的问题,使用一种数据增强的方法专门解决seq2seq模型数据不足的问题;
[0057]
(5)微调(fine
‑
tuning):模型将源域的知识和权重保存并迁移至目标域的过程。
[0058]
图3所示为一个简单的rnn网络图。其中x和o分别表示输入数据和输出数据;h为隐含层;u为连接输入层和隐含层的权值矩阵;v为隐含层与输出层之间的权值矩阵;w为两个隐含层在不同时间步长的权重矩阵。因此,时间步长t的输出o
t
会受到时间步长t的输入x
t1
和隐含层状态h的影响。因此,隐含层状态的传输过程使一个简单的rnn拥有前一个序列的内存。传统的人工神经网络只能对输入和输出分别进行寻址,并试图了解输入和输出之间的关系。但是,有些任务需要更好的处理序列信息的能力,这意味着前面的输出与后面的输出相关。lstm是一种有效的递归神经网络(rnn)。它可以预测时间序列数据,比简单的rnns更适合于长期时间序列的预测。lstm神经网络由lstm单元组成,lstm单元包含三个特殊的门,分别为遗忘门,输入门,输出门。
[0059]
图4所示为lstm单元的结构图,在lstm中,细胞状态类似于传送带,可以表示为从c
t 1
到c
t
的一条线。细胞状态可以直接在链上运行,只需要很少的线性交互作用。这样,就很容易储存长期信息。然而,这条单线无法添加或删除信息。为了选择信息,lstm单元把信息通过称为门的结构。
[0060]
本发明的技术方案使用seq2seq作为迁移学习的主要模型框架。为了提高模型的
性能,使其能够记住长期信息,本技术方案分别使用lstm的两层作为编码器和解码器。
[0061]
图5显示了该seq2seq模型的结构。图中,x和o分别为模型的输入数据和输出结果,c为编码器中的上下文向量,编码器和解码器中的隐藏状态分别由h
t
和s
t
提供,其方程为:
[0062]
h
t
=lstm
enc
(x
t
,h
t
‑1)
[0063]
s
t
=lstm
dec
(o
t
‑1,s
t
‑1)
[0064]
为了获得高水平的特征,本技术方案采用二维cnn进行特征提取,并提出了一种新的二维cnn模型,该模型带有注意层作为迁移学习和预测能量消耗的框架。在计算机视觉领域,二维cnn是特征提取的有效工具。由于卷积核的灵活性,通过特征映射很容易提取大量的特征。为了利用二维cnn提取特征,将一维数据特征重构为二维数据特征。
[0065]
图6显示了这个特征提取过程是如何运作的。为了实现二维cnn,将原始的一维特征重新塑造为二维特征。在这种情况下,可以灵活地应用不同大小和数量的卷积核来提取高级特征。这些特征可以提高模型的性能,因为卷积核可以设置为不同的大小和不同的位置。该模型采用了多注意力层来捕捉时间依赖性特征。
[0066]
步骤s3中采用预训练的方法从源域数据中提取知识,并将知识转移到目标域的任务中;数据增强被提出作为一种增加训练数据量的技术,用以提高模型的泛化性和鲁棒性。在具有注意力层模型和seq2seq迁移学习模型的2d cnn中,预训练是一个关键步骤,特别是因为预训练可以从源域获得一个完整的上下文向量。
[0067]
图7所示是一个简单的数据增强的方法图。在数据增强之前,t1=m/n;在数据增强之后,t2=m
‑
n;只要t2>t1,这个技术就会增加训练的样本。由于n通常会远远小于m,所以训练数据的数量肯定会增加。另外,在整个过程中,样品窗口的长度是相同的。考虑到办公楼的周期性,lstm模型输入数据的时间步长均为7,即m=7。此外,由于cnn模型将使用一个多注意力层来考虑时间依赖性,这种数据增强将只适用于与lstm层相关的模型。考虑到数据增强后的训练样本数量会远远超过预测目标,本技术方案中在模型的lstm层和卷积层中添加正则化,防止过拟合,增强模型的泛化能力。
[0068]
步骤s4中微调是指在目标域数据上训练一个预训练的模型,可以更新预训练的模型学习到的知识和表示,从而使预训练的结果得到利用。在深度学习和迁移学习领域,微调是一种非常重要的方法,因为它具有可行性和方便性。为了满足迁移学习的要求,从源数据集中提取知识,seq2seq模型和2d
‑
cnn模型需要一个微调过程。在深度神经网络中,较低层通常包含较多的一般性特征。相比之下,顶层可能包含更多的特殊特性。根据神经网络的特点,本技术方案中可能会遇到四种不同的场景,以及四种相应的类别。
[0069]
图8描述了对四种场景进行分类并指出处理每种类型的方法的坐标系统。在图7的象限1中,目标域数据集与源域数据集不同,但大小较大。因此,由于有大量的数据,可以从头开始训练一个新的模型,而不是对预先训练的模型进行微调。该模型可以作为特征提取器。在象限2中,来自目标域的数据集大小较大,与源域的数据集相似。在这种情况下,尽管可能获得一个好的结果与任何策略,使用目标数据来调整预训练模型可能是最有效的,因为模型可以利用知识从源域和微调过程会比从头开始培训。象限3说明了一个非常困难的情况,其中目标数据集很小,并且与源域几乎没有相似之处。因此,可以只考虑对较低的层进行微调,但这可能不会产生令人满意的结果,因为数据集的大小很小。因此,也应该考虑应用数据增强技术。象限4描述与源域数据集类似的小目标数据集。在这里,可以微调模型
的顶层(通常是一个密集的层),以从源领域转移知识。在本技术方案中,当迁移学习中存在seq2seq模型时,预训练的主要目的是训练上下文向量。在预训练完成后,需要从目标集中提取少量相似的数据进行微调。
[0070]
经验算比对可知,与信息状态差的长短期记忆(lstm)网络的结果相比,本技术方案采用seq2seq模型将具有少量数据的建筑物的平均绝对百分比误差(mape)提高了19.69个百分点,采用2d cnn模型平均提高了20.54个百分点。
[0071]
鉴于dies应用现状和风能城市适应性差的问题,本发明的技术方案,将迁移学习应用到训练数据贫乏的建筑负荷预测当中,通过使用来自相似建筑的历史数据,将其他相同类型建筑的能耗数据作为训练集的一部分进行训练,以期通过其他建筑的历史数据获取知识,来提高目标建筑在能源相关信息贫乏情况下的负荷预测的准确性,使用两种深度学习模型和迁移学习框架对建筑能耗进行预测,通过不同的实验来验证迁移学习模型在不同的预训练数据下的性能,提升目标建筑的预测性能并获得更好的预测精度,而提高了传统预测方法的精度。
[0072]
本发明可广泛用于区域综合能源系统的规划或设计领域。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1