一种面向智能数据可视化的对话式问答实现方法
本发明属于人工智能技术领域,具体涉及一种面向商务智能数据可视化的对话式知识问答实现方法。
背景技术:
随着人工智能(ai)技术的进步,以及大数据的支撑,人工智能(ai)技术开始广泛的应用于各个领域,比如图像识别、物体检测、图像生成、机器翻译、知识图谱、对话问答等领域。ai技术在这些领域的运用可以帮助人们减少重复性劳动,提高工作效率并辅助人们进行创造。在商务智能领域,人们通过对原始数据进行转换,应用分析算法来获得见解,进而帮助决策。目前分析者得到一个分析结果通常需要经历如下的步骤:了解数据结构,转换原始数据,选择分析方法或自行撰写分析函数,制定可视化展示方案,得到结果。而现有技术存在的缺陷是,需要花费大量的时间,并且过程难以复制,造成了很多重复劳动。
技术实现要素:
基于上述现状,研发一种技术方案可以帮助简化步骤,那么分析的复杂性可以被大大简化,分析者可以更加聚焦于了解数据背后的见解,从数据中获得更多的知识,因此,本发明提供了一种面向智能数据可视化的对话式问答实现方法,其包括基于自然语言的算法,进一步为系统问答式知识的图谱可视化打下基础。
本发明采取以下技术方案:
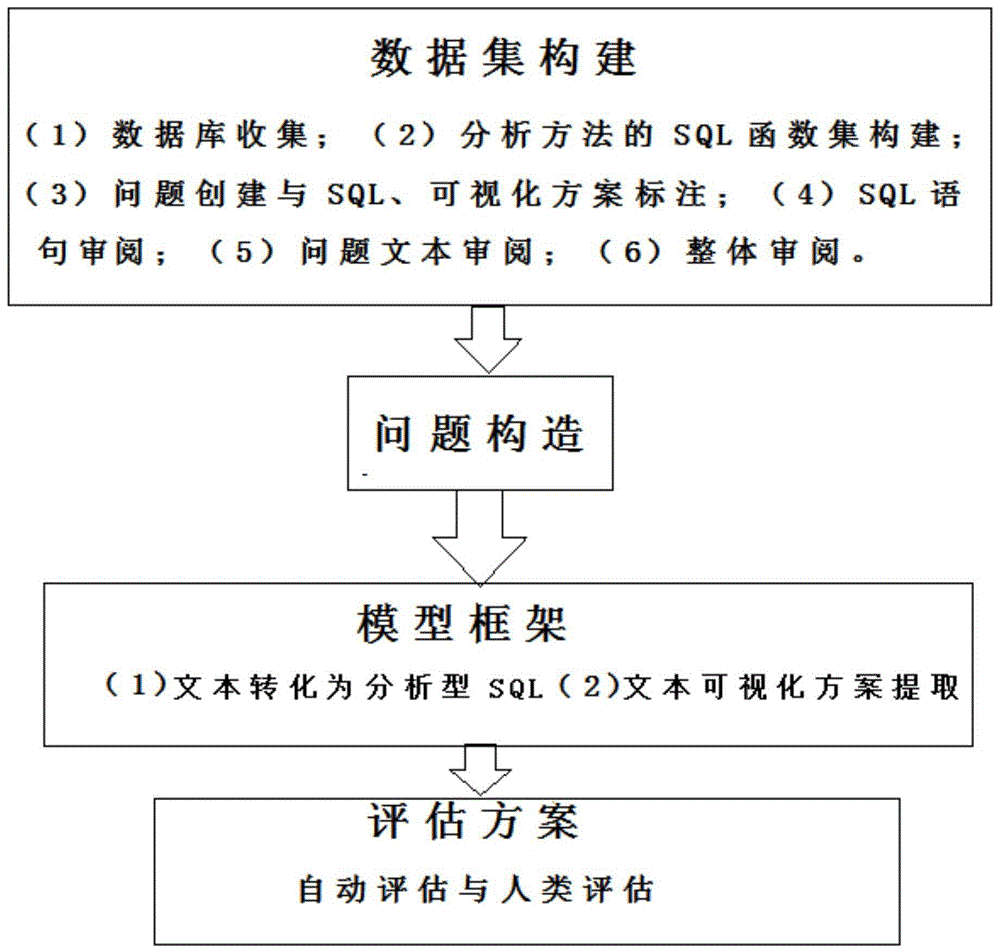
一种面向智能数据可视化的对话式问答实现方法,即实现商务智能分析、及自然语言转化为sql(结构化查询语言)以及自动可视化。将通过商务智能分析方法来构建一个新的包含常见分析方法的nl2sql数据集(nl2bisql数据集),然后利用本发明中的模型,来实现面向商务智能可视化的问答过程,返回可视化结果作为回答。其按如下步骤进行:
第一步:数据集构建:通过数据库收集、分析方法的sql(结构化查询语言)函数集构建、问题创建与sql、可视化方案标注、sql语句审阅、问题文本审阅、整体审阅来构建数据集;
第二步:问题构造:在数据集的基础上,通过具体问题的数学化来构造问题;
第三步:模型框架:建立将文本转化为分析型sql,文本可视化方案提取的模型框架;
第四步:评估方案:自动评估与人类评估的评估方案建立。
进一步的,第一步具体如下:
本发明在spider数据集的基础上进行扩展。其中包含200个数据库,其中每个数据库平均含有5.1个表格。经过检查,虽然该数据集可以泛化至不同的领域,再增加一些商业场景下的数据,能够更直接的验证商务智能场景中的应用效果。
本发明采用描述性分析(descriptivestatistic)与推理统计(inferentialstatistics)来收集常用分析方法,并构建一种机制使使用者能够根据需要扩展。确定了分析方法后,制定默认的可视化方案,最后形成分析方法的sql函数集。
在拥有分析方法的sql函数集后,则可开始生成文本及对应的sql、及可视化。其过程为:首先针对每个数据集生成20-30个sql,这些sql的生成遵循如下规则:1)覆盖50%的分析方法;2)涉及数据库的每一个表格;3)自动根据表格属性生成sql;4)由于对于同一结果,用不同的sql表示,规定sql协议,生成时须符合协议。
对于具有多个可能的sql翻译的问题,审阅者应仔细检查是否根据协议正确选择了sql标签。然后,审阅者检查当前数据库中的所有sql语句是否覆盖50%分析方法,是否涉及数据库中所有表格。
在审阅了sql标签之后,将要求其他注释者检查问题是否清楚,并包含足够的信息来回答查询。
最后,对sql进行复查。如果多个查看者不确定某些注释问题,则此注释者将做出最终决定。
进一步地,第二步具体如下:
在该数据集的基础上,将具体的问题数学化。本发明构造基于rat(关系意识自关注)-sql,并根据本发明的特点进行了修改。具体来说,给定自然语言问题q,一个关系型数据库对象集合s=<c,t>,以及分析方法函数集comp,目标是生成对应的sql查询语句p以及对应的可视化结果vis。问题由单词序列组成q=q1,q2,…,q|q|;数据库对象集合s由列c={c1,c2,...,c|c|}以及表格名称t={t1,t2,...,t|t|}组成;分析方法函数集由多条sql写就的函数组成comp=comp1,comp2,...,comp|comp|。每个列名ci包含单词
模式中的某些列是主键,用于对相应表进行唯一索引,有些是外键,用于引用其他表中的主键列。此外,每一列的类型为τ∈{number,text}。因此,形式上将数据库对象集合表示为有向图g=<v,e>。它的节点v=c∪t是对象集合的列名和表名,每个列和表中都带有其名称中的单词(对于列,将其类型τ放在标签的前面)。它的边e由表1中描述的预先存在的数据库关系定义。
表1有向图g的节点类型及边构建规则。
如果两个节点间符合描述则构建边,并标注相应的标签,如果不存在任何一种关系则不构建边。
有向图g是对于数据库对象集合的编码。为了能够将问题和数据库对象集合中的内容对应,定义一个新的以问题为上下文的数据库对象集合有向图gq=<vq,eq>。其中,vq=v∪q=c∪t∪q,
以上定义后,把问题分为两个子任务:(1)文本转换为分析型sql;(2)文本转换为可视化方案vis。对于文本转换为分析型sql这一任务,它的基本结构为编码器-解码器架构,在选出分析方法comp后(在模型框架中描述),将comp、有向图gq使用编码器fenc编码为ci,ti,qi,comp,其中ci为某一列名的编码,ti为某一表名的编码,qi为问题中某一词汇的编码;解码器fdec以上述内容为输入,计算(p|gq,comp)的分布。
进一步地,第三步具体为:
本发明在rat-sql中提出的关系感知输入编码之上进行改进,提出具有层次的自注意力机制,这是一种针对半结构化输入序列的编码模型。相对于rat-sql,该模型能够更好的共同编码输入中已有的层级关系结构。
自注意力机制的思想是每个元素可以由其与其他元素的关系来表述,即将关系信息编码入元素中。其计算方式为:
yi=selfattn(xi,x);
然而,这种自注意力机制只计算了某两种元素的单层关系,在实际情况中,元素可能与某几个元素的组合有更直接的关系。本发明的算法1如下:
其方法为排除序列中某一元素,计算其他元素的自编码结果,然后将被排除元素包含进来再计算一次自注意力编码,这样则可使层级关系被捕捉到。在任务中,在识别出分析方法词汇的基础上,将问题上下文数据库对象集合有向图gq进行编码。具体来说,首先使用gloveembedding方法对有向图g中的列名ci及表名ti编码得到
初步得到的编码
数据库关系集合链接能够帮助自然语言问题中的表格、列、值引用与数据库关系集合对齐。对齐主要分为两个部分:名称链接与值链接。
名称链接为将列或表格名称与自然语言词汇相匹配。匹配分为全匹配与部分匹配。具体来说,首先计算自然语言问题中长度为1到5的n-grams,然后判断其是否完全匹配列名或表名或该n-gram是列名或表名的子序列,由此得到4种关系,tem(表名全匹配),tpm(表名部分匹配),cem(列名全匹配),cpm(列名部分匹配)。
问题和数据库对象集合的匹配也会出现问题与数据库中的值的匹配,虽然有了问题与列名的匹配就不需要值匹配,但是当问题中列名没有明确提到时则难以找到相应的列,需要使用背景知识来缓解这一问题。数据库中的值即是背景知识的良好来源,因此可以将问题与数据库中的值进行匹配,将该关系定义为cellmatch。数据库中的值匹配需要进行数据库查询,所以使用select、like等sql子句来构造查询语句。
直觉表明,sqlp中出现的列和表在自然语言问题中通常会具有相应的引用。为了捕获模型中的直觉,将关系感知的注意作为y中每个元素与所有列/表之间的指针机制,以计算列及表对齐矩阵
解码器基于抽象语法树(ast)以深度优先的顺序遍历得到结果。使用lstm在每一步输出一个行为,一种行为是扩展最后生成的节点为一个语法规则applyrule;另一种行为是从对象集合中选择列或表,即selectcol或selecttab。解码器生成sql的过程可以表示为p(p|y)=πtp(αt|α<t,y),其中y=fenc(gq)为编码器的最终输出,α<t为第t步之前所有的行为。
本发明使用基于树的lstm对分析方法函数f编码得到femd=lstm(f)。编码器输出修改为:
y=fenc(gq,comp)
本发明中文本可视化方案提取。对可视化方案做了以下的简化,一是只处理二维数据的可视化,二是可视化控制维度只包含可视化类型name(如饼图、折线图)、颜色color以及轴位置axis。
因此,此问题可简化为计算p((name,color,axis)|q,p)。这里将结果sql作为条件的原因是问题中可能不含有可视化的描述,所以这时使用分析方法的默认可视化方案。使用双向lstm对问题进行编码q,然后在最后一步输出可视化方案各维度的离散概率分布p(name),p(color),p(axis)。概率分布的最大值小于某一阈值时,取默认方案;超过阈值时,取最大值对应的名称。
进一步地,第四步具体如下:
本发明利用自动评估来评估生成的分析型sql语句以及可视化方案的准确性。跟随nl2compsql的数据集spider评估的评估方法,本发明从组件匹配、精确匹配、运行精确度三个方面来进行评估。
对于人类评估,本发明提供拟进行横向和纵向两种角度进行评估。横向与自动评估相似,即比较不同人工智能算法下数据回答的完成度与准确度,只是此处由人类来打分;纵向评估指的是评估该系统对于商务智能分析的作用,因此本发明设计方法如下:预定一组数据集,以及分析目标,邀请商务智能分析专家20名,将他们平均分为两组,一组使用普通的商务智能(bi)问答工具(如mspowerbi)来制作可视化得到洞察,另一组使用本系统。记录两组人员的完成时间,满意度,使用体验等。
与现有技术相比,本发明具有如下优点:
1、本发明能够构建一个更加支持分析的数据问答系统,相对于普通bi数据问答系统能够支持更多的分析方法。
2、本发明建立自然语言语法的定义的新颖性。
3、本发明整体评估方法,以及能处理多类型问题的统一框架。
附图说明
图1为本发明的商务智能数据可视化过程图。
图2为本发明数据构建示意图。
图3为系统的测试误差图。纵坐标为误差,横坐标为训练次数。
具体实施方式
下面结合附图对本发明实施例作详细说明。
如图1所示,本实施例分析流程进行一种面向商务智能数据可视化的对话式知识问答方法。分析方法如下:
第一步:分析方法的sql函数集构建。
1)数据库收集
在spider数据集的基础上进行扩展。其中包含200个数据库,其中每个数据库平均含有5.1个表格。经过检查,该数据集可以泛化至不同的领域,再增加一些商业场景下的数据,帮助最后能够更直接的验证商务智能场景中的应用效果。
2)分析方法的sql函数集构建
本发明利用统计分析方法描述性分析(descriptivestatistic)与推理统计(inferentialstatistics)构建一种机制使使用者能够根据需要扩展。确定了分析方法后,请对sql理解深入的同学将其转化为sql函数,并制定默认的可视化方案,最后形成分析方法的sql函数集。
3)问题创建与sql、可视化方案标注
在拥有分析方法的sql函数集后,开始生成文本及对应的sql、可视化。首先针对每个数据集生成20-30个sql,这些sql的生成遵循如下规则:覆盖50%的分析方法;涉及数据库的每一个表格;自动根据表格属性生成sql;由于对于同一结果,可以用不同的sql表示。
4)sql语句及可视化方案审阅
对于具有多个可能的sql翻译的问题,审阅者应仔细检查是否根据协议正确选择了sql标签。然后,审阅者检查当前数据库中的所有sql语句是否覆盖50%分析方法,是否涉及数据库中所有表格。
5)问题文本审阅
在审阅了sql标签之后,将要求其他注释者检查问题是否清楚,并包含足够的信息来回答查询。然后请以英语过6级的学生会审阅并更正每个问题。他们首先检查该问题在语法上是否正确和自然。接下来,他们确保问题反映了其相应sql标签、分析方法及可视化的含义。最后,为了提高问题的多样性,要求注释者为某些问题添加释义的版本。
6)整体审阅
如果多个查看者不确定某些注释问题,则此注释者将做出最终决定。运行脚本来执行和解析所有sql标签,以确保它们正确无误。
第二步:该数据集的基础上,将具体的问题数学化。
给定自然语言问题q,一个关系型数据库对象集合s=<c,t>,以及分析方法函数集comp,目标是生成对应的sql查询语句p以及对应的可视化结果vis。问题由单词序列组成q=q1,q2,...,q|q|;数据库对象集合s由列c={c1,c2,...,c|c|}以及表格名称t={t1,t2,...,t|t|}组成;分析方法函数集由多条sql写就的函数组成comp=comp1,comp2,...,comp|comp|。每个列名ci包含单词
模式中的某些列是主键,用于对相应表进行唯一索引,有些是外键,用于引用其他表中的主键列。此外,每一列的类型为τ∈{number,test}。因此,形式上我们将数据库对象集合表示为有向图g=<v,e>。它的节点v=c∪t是对象集合的列名和表名,每个列和表中都带有其名称中的单词(对于列,将其类型τ放在标签的前面)。它的边e由表1中描述的预先存在的数据库关系定义。
表1有向图g的节点类型及边构建规则
如果两个节点间符合描述则构建边,并标注相应的标签,如果不存在任何一种关系则不构建边。
有向图g是对于数据库对象集合的编码。为了能够将问题和数据库对象集合中的内容对应,我们定义一个新的以问题为上下文的数据库对象集合有向图gq=<vq,eq>。其中vq=v∪q=c∪t∪q,
第三步:文本转化为分析型sql,以及文本可视化。
(1)分析方法识别
这部分的目标是从语句中识别出表示分析方法的词汇。给出问题q,计算每个词汇qi是分析方法的概率p(is_comp|qi)。使用双向lstm(bilstm)结构输出每个词汇为分析方法的概率,将概率值最大的词汇comp作为该问题所描述的分析方法。
(2)基于层次自注意力机制的关系感知输入编码
本发明在rat-sql中提出的关系感知输入编码之上进行改进,提出具有层次的自注意力机制,这是一种针对半结构化输入序列的编码模型。
考虑一组输入
yi=selfattn(xi,x);
softmax:指归一化指数函数。layernorm:层标准化函数。relu:线性整流函数。selfattn:自注意力机制函数。concat:连接多个函数或数组的函数。lsmt:快速分类函数。
然而,这种自注意力机制只计算了某两种元素的单层关系,在实际情况中,元素可能与某几个元素的组合有更直接的关系。因此,本发明提出具有层次的自注意力机制,其算法如下:
其方法为排除序列中某一元素,计算其他元素的自编码结果,然后将被排除元素包含进来再计算一次自注意力编码,这样则可使层级关系被捕捉到。
本发明中,在识别出分析方法词汇的基础上,将问题上下文数据库对象集合有向图gq进行编码。具体来说,首先使用gloveembedding方法对有向图g中的列名ci及表名ti编码得到
初步得到的编码
算法二面向分析方法的层次自注意力机制
(3)数据库关系集合链接
数据库关系集合链接能够帮助自然语言问题中的表格、列、值引用与数据库关系集合对齐。对齐主要分为两个部分:名称链接与值链接。
名称链接为将列或表格名称与自然语言词汇相匹配。匹配分为全匹配与部分匹配。具体来说,首先计算自然语言问题中长度为1到5的n-grams,然后判断其是否完全匹配列名或表名或该n-gram是列名或表名的子序列,由此得到4种关系,tem(表名全匹配),tpm(表名部分匹配),cem(列名全匹配),cpm(列名部分匹配)。
问题和数据库对象集合的匹配也会出现问题与数据库中的值的匹配,虽然有了问题与列名的匹配就不需要值匹配,但是当问题中列名没有明确提到时则难以找到相应的列,需要使用背景知识来缓解这一问题。数据库中的值即是背景知识的良好来源,因此可以将问题与数据库中的值进行匹配,将该关系定义为cellmatch。数据库中的值匹配需要进行数据库查询,所以使用select、like等sql子句来构造查询语句。
sqlp中出现的列和表在自然语言问题中通常会具有相应的引用。为了捕获模型中的直觉,将关系感知的注意作为y中每个元素与所有列/表之间的指针机制,以计算列及表对齐矩阵
(4)解码器
解码器基于yin等提出的抽象语法树(ast)以深度优先的顺序遍历得到结果。使用lstm在每一步输出一个行为,一种行为是扩展最后生成的节点为一个语法规则applyrule;另一种行为是从对象集合中选择列或表,即selectcol或selecttab。
因此,解码器生成sql的过程可以表示为p(p|y)=πtp(at|a<t,y),其中y=fenc(gq)为编码器的最终输出,a<t为第t步之前所有的行为。
(5)使用sql分析函数增强
人类在应用一种分析方法时,通常具有对该分析方法具有类似于函数的抽象化认知,这一抽象认知帮助人类构造复杂的分析语句。因此,有理由认为sql分析函数能够进一步帮助模型构造分析型sql。通过将(1)中识别出来的分析方法对应的sql函数的编码加入到编码器结果中,则可使解码器能够使用分析方法函数来帮助生成最终的sql语句。使用基于树的lstm对分析方法函数f编码得到femd=lstm(f)。编码器输出修改为:
y=fenc(gq,comp)。
第四步:自动评估与人类评估
本发明利用自动评估来评估生成的分析型sql语句以及可视化方案的准确性。跟随nl2compsql的数据集spider评估的评估方法,本发明从组件匹配、精确匹配、运行精确度三个方面来进行评估。
对于人类评估,本发明提供拟进行横向和纵向两种角度进行评估。横向与自动评估相似,即比较不同人工智能算法下数据回答的完成度与准确度,只是此处由人类来打分;纵向评估指的是评估该系统对于商务智能分析的作用,因此本发明设计方法如下:预定一组数据集,以及分析目标,邀请商务智能分析专家20名,将他们平均分为两组,一组使用普通的bi问答工具(如mspowerbi)来制作可视化得到洞察,另一组使用本系统。记录两组人员的完成时间,满意度,使用体验等。
本发明可通过商务智能分析及可视化来实现面向商务智能可视化的多轮对话系统,即用户可与系统进行多轮对话,询问数据问题或知识问题,对于数据问题,系统将返回可视化的回答;对于知识问题,系统直接返回文本答案。
准确地对具有频率相关时延的微分-积分方程求解,准确地分析具有频率相关时延反馈混沌动力学和混沌通信。
本例实施过程中,通过算法可以自动生成回答。该对话系统实现:商务智能分析方法的总结研究,即对商务智能分析者使用的分析方法及分析习惯进行总结,设计一套分析方法的形式表达;可视化自动生成,即选择合适的可视化编码策略,推荐的查询语句并自动生成可视化结果;多轮对话的实现,解决在对话中经常发生的共同指称和信息遗漏,并支持对问句进一步修改或增添限制;多任务统一框架对话问答的研究。由于商务智能系统涵盖了多种数据,用户可能会有不同的提问需求,主要包括数据问答和知识问题;商务智能可视化对话数据集的生成。由于使用人工智能算法,所以需要收集足够的数据来确保训练效果。但限于人力及物力的限制,需要设计省力的方式来生成数据集;评价该课题对bi分析者起到的帮助。设计适当的评价指标,自动和人类评估两个角度来进行评估。
以上对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!