一种基于深度学习的高动态范围图像隐写和恢复方法
文档序号:25784812发布日期:2021-07-09 10:29阅读:94来源:国知局
导航: X技术> 最新专利>计算;推算;计数设备的制造及其应用技术
1.本发明涉及图像处理领域,具体涉及一种基于深度学习的高动态范围图像隐写和恢复方法。
背景技术:
2.互联网的飞速发展给人们的生活带来天翻地覆的变化,然而我们在享受网络所带来的便利的同时,也承担着信息泄露、账号被盗等众多风险。图像隐写作为信息安全领域的一项重要技术,利用图像载体的冗余特性,将需要传播的秘密信息隐藏于载体图像之中,而不引起第三方的怀疑,最终实现秘密信息的隐秘传播。
3.传统的隐写方法都是通过对载体图像做一些修改实现秘密信息的嵌入,但是修改操作都会在一定程度上改变原始载体图像的统计特性,隐写技术的对立面—隐写分析技术正是利用图像修改前后统计特征的变化来区分载体图像和隐写图像,随着隐写分析特征的维度不断增大,使隐写分析技术向深度学习领域扩展。深度学习是机器学习领域中的一个较为流行的方法,通过模拟人脑来自主学习数据的各种特征,实现数据的分类或者回归,在数字图像处理和计算机视觉等领域有广泛的应用。基于深度学习的隐写分析技术可以更好地捕捉图像的各维特征,在一个训练过程中同时完成特征提取和分类任务,逐渐取得了比传统隐写特征更好的检测准确率。
4.由于隐写技术与隐写分析技术在不断的对抗过程中,相互促进,相互发展。传统的隐写方法越来越难以抵抗基于深度学习的隐写分析检测,且深度学习中“生成对抗”的思想与隐写和隐写分析之间十分类似,让研究学者尝试将深度学习应用于隐写技术中。2017年首次提出的以图藏图的深度学习隐写网络,用基于自动编码器框架的图像隐写模型实现将图片隐藏到另一张相同尺寸的图片中,为本申请的研究提供了新的思路。
5.现有的基于深度学习的隐写技术采用的图像载体均为低动态范围(low dynamic range,ldr)图像,随着高动态范围(high dynamic range,hdr)图像逐渐普及,以hdr图像为载体的隐写技术受到了越来越多的关注。由于hdr图像能够提供更大的动态范围,展现更自然真实的画面,对于隐写技术来说,这意味着hdr图像有更多的冗余空间来嵌入秘密信息,同时hdr图像不同的存储格式也为图像隐写技术带来新的切入点,因此用hdr图像进行图像隐写有着极大的研究价值和研究意义。
6.hdr图像与ldr图像最大的不同是像素是由单精度浮点数表示的,范围不仅仅局限于0
‑
255,且在存储过程中,使用了不同的图像存储格式,这些格式有效节省了hdr图像的存储空间,但也使得基于ldr图像的隐写算法不能直接移植到hdr图像上。与此同时,现有方法生成的嵌入秘密图像后的隐写图像和恢复出的秘密图像大多存在颜色失真和图像质量下降等,为解决这些不足并将高动态范围图像作为隐写载体,需要对高动态范围图像的存储格式进一步研究,分析深度学习网络模型,设计一种基于深度学习的高动态范围图像的隐写算法。
技术实现要素:
7.针对现有技术中的上述不足,本发明提供的一种基于深度学习的高动态范围图像隐写和恢复方法解决了现有方法生成的嵌入秘密图像后的隐写图像和恢复出的秘密图像大多存在颜色失真和图像质量下降的问题。
8.为了达到上述发明目的,本发明采用的技术方案为:一种基于深度学习的高动态范围图像隐写和恢复方法,包括以下步骤:
9.s1、构建hdr图像数据集和ldr秘密图像数据集;
10.s2、对hdr图像数据集中的hdr图像进行预处理,得到多张不同的载体图像、hdr图像的符号位和hdr图像的指数位;
11.s3、通过concat操作将一张不同的载体图像与一张ldr秘密图像在通道维度上连接在一起,并输入嵌入模型,得到隐写图像;
12.s4、将隐写图像、hdr图像的符号位和hdr图像的指数位合并为hdr隐写图像;
13.s5、对hdr隐写图像做预处理,得到hdr隐写图像小数空域的后八位比特平面;
14.s6、将hdr隐写图像小数空域的后八位比特平面输入提取模型,得到恢复的ldr秘密图像。
15.进一步地,步骤s2包括以下分步骤:
16.s21、将hdr图像数据集中每张hdr图像输入preprocess预处理模块中,提取hdr图像小数空域m、符号位s和指数位e;
17.s22、提取hdr图像小数空域m的后八位比特平面,得到后八位比特平面图像;
18.s23、对后八位比特平面图像进行随机裁剪,得到标准尺寸图像;
19.s24、对标准尺寸图像进行数据增强操作,得到多张不同的载体图像。
20.进一步地,步骤s3中嵌入模型包括依次连接的输入层、layer1层、layer2层、layer3层、layer4层、layer5层、layer6层、layer7层、layer8层、layer9层和output层;
21.所述layer1层、layer2层、layer3层和layer4层均包括:残差模块resblock1和最大池化层maxpool;所述残差模块resblock1的输入端作为layer1层、layer2层、layer3层或layer4层的输入端,其输出端与最大池化层maxpool的输入端连接;所述最大池化层maxpool的输出端作为layer1层、layer2层、layer3层或layer4层的输出端;
22.所述layer5层为残差模块resblock2;
23.所述layer6层、layer7层、layer8层和layer9层均为卷积模块convblock1;
24.所述output层为卷积模块convblock2。
25.进一步地,残差模块resblock1和残差模块resblock2均包括:3*3卷积层conv1、3*3卷积层conv2、1*1卷积层conv3和激活函数层leakyrelu1;
26.所述3*3卷积层conv1的输入端与1*1卷积层conv3的输入端连接,并作为残差模块resblock1或残差模块resblock2的输入端;
27.所述3*3卷积层conv1的输出端与3*3卷积层conv2的输入端连接;
28.所述3*3卷积层conv2的输出端与激活函数层leakyrelu1的第一输入端连接;
29.所述1*1卷积层conv3的输出端与激活函数层leakyrelu1的第二输入端连接;
30.所述激活函数层leakyrelu1的输出端作为残差模块resblock1或残差模块resblock2的输出端。
31.进一步地,卷积模块convblock1包括依次连接的3*3卷积层conv4、归一化层bn1、激活函数层leakyrelu2、3*3卷积层conv5、归一化层bn2和激活函数层leakyrelu3;所述3*3卷积层conv4的输入端作为卷积模块convblock1的输入端;所述激活函数层leakyrelu3的输出端作为卷积模块convblock1的输出端;
32.所述卷积模块convblock2包括:3*3卷积层conv6和sigmoid激活函数层;
33.所述3*3卷积层conv6的输入端作为卷积模块convblock2的输入端,其输出端与sigmoid激活函数层的输入端连接;所述sigmoid激活函数层的输出端作为卷积模块convblock2的输出端;
34.所述3*3卷积层conv6的步长为1,其padding为0。
35.进一步地,提取模型包括依次连接的输入层、5个中间层和output层;
36.所述5个中间层均为卷积模块convblock3;
37.所述卷积模块convblock3均包括依次连接的3*3卷积层conv7、归一化层bn3和relu激活函数层;
38.所述提取模型的output层为卷积模块convblock4;
39.所述卷积模块convblock4依次包括:3*3卷积层conv7和sigmoid激活函数层;
40.所述3*3卷积层conv7的步长为1。
41.进一步地,嵌入模型和提取模型在训练过程中的损失函数l为:
[0042][0043]
其中,c
i,j
为输入的载体图像的第i行第j列的像素点,c
′
i,j
为隐写图像的第i行第j列的像素点,c
j
为载体图像中第j个rgb像素向量,c
′
j
为隐写图像中第j个rgb像素向量,s
j
为ldr秘密图像中第j个rgb像素向量,s
′
j
为恢复的秘密图像中第j个rgb像素向量,为隐写图像的均值,μ1为载体图像的均值,为恢复的ldr秘密图像的均值,μ2为ldr秘密图像的均值,w为图像的宽度,h为图像的高度,σ
cov1
为载体图像和隐写图像之间的协方差,σ
cov2
为ldr秘密图像和恢复的ldr秘密图像之间的协方差,、β和γ为权衡因子,用来权衡结构相似性指标在损失函数中所占的比重,β用来权衡余弦相似性指标在损失函数中所占的比重,γ用来权衡提取模型的损失函数在整个隐写方法模型的损失函数中所占的比重,s
i,j
为输入的ldr
秘密图像的第i行第j列的像素点,s
′
i,j
为恢复的ldr秘密图像的第i行第j列的像素点,c1和c2为超参数,用于防止分母为0,为隐写图像的方差,σ1为载体图像的方差,为恢复的ldr秘密图像的方差,σ2为ldr秘密图像的方差。
[0044]
上述进一步方案的有益效果为:
[0045]
在以上损失函数的约束下,网络模型的训练时间有所加快,不仅关注了图像对之间对应像素点的差异,还亮度、结构和对比度三方面对图像相似性进一步进行限制,与此同时,将图像向量化之后,图像对之间夹角的余弦值也作为衡量标准,最终得到尽可能相似的图像。
[0046]
综上,本发明的有益效果为:
[0047]
本发明利用hdr图像的一种常用存储格式openexr,通过提取hdr图像所有像素点的小数部分m,将m的第3比特到第10比特单独提取出来作为隐写的载体,把载体和要传递的秘密图像共同输入到嵌入模型中,生成隐写图像,最终将隐写图像输入到提取模型中,得到恢复的秘密图像。本发明采用的载体是以openexr格式存储的256*256大小的hdr图像,秘密图像是相同尺寸的ldr图像,能够实现嵌入量为8bpp(bit per pixel)的隐写操作,生成的隐写图像仍然保持很好的图像质量,与原始的载体图像在像素值的统计特性方面很相似,因此能够抵抗隐写分析的攻击,安全性较高。
附图说明
[0048]
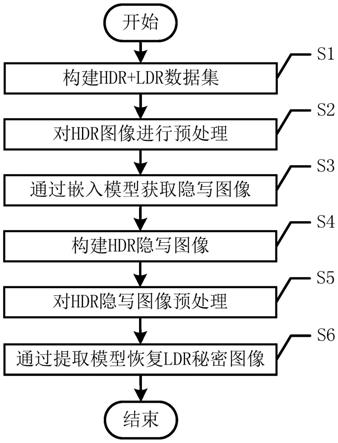
图1为一种基于深度学习的高动态范围图像隐写和恢复方法的流程图;
[0049]
图2为一种基于深度学习的高动态范围图像隐写和恢复方法的详细流程图;
[0050]
图3为openexr编码格式位分布图;
[0051]
图4为原始的.exr格式的hdr图像;
[0052]
图5为对应hdr图像提取出的小数空域的后八位比特平面;
[0053]
图6为残差模块的结构示意图;
[0054]
图7为卷积模块convblock1的结构示意图;
[0055]
图8为输入的.exr格式的hdr图像;
[0056]
图9为生成的隐写图像;
[0057]
图10为传递的秘密图像;
[0058]
图11为恢复的秘密图像;
[0059]
图12为主观视觉结果图;
[0060]
图13为各组图像对之间的残差图像;
[0061]
图14为各组图像对之间的直方图;
[0062]
图15为roc曲线图。
具体实施方式
[0063]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0064]
如图1~2所示,一种基于深度学习的高动态范围图像隐写和恢复方法,包括以下步骤:
[0065]
s1、构建hdr图像数据集和ldr秘密图像数据集;
[0066]
s11、构建hdr图像数据集的方法为:
[0067]
使用已经搜集的hdr图像资源,通过人工筛选,剔除有较多坏像素或不符合要求的高质量hdr图像数据。将不同存储格式的hdr图像数据使用图像格式转换工具转为openexr格式,最终得到的hdr图像数据集包含的所有文件均为.exr格式的hdr图像。
[0068]
s12、构建ldr秘密图像数据集的方法为:
[0069]
选用2018年图像超分辨率比赛中所使用的div2k数据集作为图像隐写的秘密图像,其中div2k_train_hr和div2k_valid_hr中分别包括800张、100张不同分辨率的png图像。
[0070]
s2、对hdr图像数据集中的hdr图像进行预处理,得到多张不同的载体图像、hdr图像的符号位和hdr图像的指数位;
[0071]
步骤s2包括以下分步骤:
[0072]
s21、将hdr图像数据集中每张hdr图像输入preprocess预处理模块中,提取hdr图像小数空域m、符号位s和指数位e;
[0073]
openexr格式是hdr图像一种常用的存储格式,图像保存的文件扩展名是.exr。openexr格式有r、g、b三个彩色通道,每个通道的像素值都是16位半精度浮点数,位分布如图3所示。与ieee754标准类似,16位半精度浮点数包括1位符号位sign,5位指数位exponent和10位小数位mantissa。
[0074]
在表征一个像素点的16位二进制比特流中,5位指数位e基本上表示了原始图像中的亮度信息及大部分语义信息,而10位小数位m是对图像信息的补充和扩展。将原始hdr图像每个像素点均表示为二进制比特流后,由于在对小数空域m的不同比特位进行修改时,像素的改变量为即在openexr格式中,像素值改变的精度为1/1024,因此,可以选用小数空域m中的后八位比特平面作为嵌入秘密图像的新载体,实现隐写操作。
[0075]
s22、提取hdr图像小数空域m的后八位比特平面,得到后八位比特平面图像;
[0076]
提取hdr图像小数空域m后再提取m的后八位比特平面,得到后八位比特平面图像m2‑
10
作为载体图像,如图4~5所示,根据图5可知,可见m2‑
10
只包含原始图像的少部分细节,可以通过修改其像素值实现隐写而最大程度的减少对原始图像统计特性的破坏。
[0077]
s23、对后八位比特平面图像进行随机裁剪,得到标准尺寸图像;
[0078]
由于建立的数据集中hdr图像的分辨率普遍很大,受限于算力以及计算机内存,需要将原始的载体图像进行随机裁剪,从而适应于网络模型的输入(本发明中模型使用的尺寸为256*256),之后通过随机水平和竖直翻转以及随机噪声添加等数据增强方式来提高模型的泛化能力。
[0079]
s24、对标准尺寸图像进行数据增强操作,得到多张不同的载体图像。
[0080]
s3、通过concat操作将一张载体图像与一张ldr秘密图像在通道维度上连接在一起,并输入嵌入模型,得到隐写图像;
[0081]
步骤s3中嵌入模型包括依次连接的输入层、layer1层、layer2层、layer3层、
layer4层、layer5层、layer6层、layer7层、layer8层、layer9层和output层;
[0082]
所述layer1层、layer2层、layer3层和layer4层均包括:残差模块resblock1和最大池化层maxpool;所述残差模块resblock1的输入端作为layer1层、layer2层、layer3层或layer4层的输入端,其输出端与最大池化层maxpool的输入端连接;所述最大池化层maxpool的输出端作为layer1层、layer2层、layer3层或layer4层的输出端;
[0083]
所述layer5层为残差模块resblock2;
[0084]
所述layer6层、layer7层、layer8层和layer9层均为卷积模块convblock1;
[0085]
所述output层为卷积模块convblock2。
[0086]
表1嵌入模型的具体结构
[0087]
层级模块输出尺寸及通道数input 256*256*6layer1resblock1+maxpool128*128*64layer2resblock1+maxpool64*64*128layer3resblock1+maxpool32*32*256layer4resblock1+maxpool16*16*512layer5resblock216*16*512layer6convblock116*16*256layer7convblock132*32*128layer8convblock164*64*64layer9convblock1128*128*32outputconvblock2256*256*3
[0088]
表1中maxpool用于对特征图进行下采样,用残差模块进行残差连接,使得模型具有更好的学习特征残差。
[0089]
如图6所示,残差模块resblock1和残差模块resblock2均包括:3*3卷积层conv1、3*3卷积层conv2、1*1卷积层conv3和激活函数层leakyrelu1;所述3*3卷积层conv1的输入端与1*1卷积层conv3的输入端连接,并作为残差模块resblock1或残差模块resblock2的输入端;所述3*3卷积层conv1的输出端与3*3卷积层conv2的输入端连接;所述3*3卷积层conv2的输出端与激活函数层leakyrelu1的第一输入端连接;所述1*1卷积层conv3的输出端与激活函数层leakyrelu1的第二输入端连接;所述激活函数层leakyrelu1的输出端作为残差模块resblock1或残差模块resblock2的输出端。
[0090]
如图7所示,卷积模块convblock1包括依次连接的3*3卷积层conv4、归一化层bn1、激活函数层leakyrelu2、3*3卷积层conv5、归一化层bn2和激活函数层leakyrelu3;所述3*3卷积层conv4的输入端作为卷积模块convblock1的输入端;所述激活函数层leakyrelu3的输出端作为卷积模块convblock1的输出端;
[0091]
所述卷积模块convblock2包括:3*3卷积层conv6和sigmoid激活函数层;
[0092]
所述3*3卷积层conv6的输入端作为卷积模块convblock2的输入端,其输出端与sigmoid激活函数层的输入端连接;所述sigmoid激活函数层的输出端作为卷积模块convblock2的输出端;
[0093]
所述3*3卷积层conv6的步长为1,其padding为0。
[0094]
卷积模块convblock2用于将32维度特征向量压缩为3维特征向量,得到与载体图像相同尺寸藏有秘密图像的隐写图像。
[0095]
s4、将隐写图像、hdr图像的符号位和hdr图像的指数位合并为hdr隐写图像;
[0096]
s5、对hdr隐写图像做预处理,得到hdr隐写图像小数空域的后八位比特平面;
[0097]
s6、将hdr隐写图像小数空域的后八位比特平面输入提取模型,得到恢复的ldr秘密图像。
[0098]
提取模型包括依次连接的输入层、5个中间层(即下面表2中的layer1~layer5)和output层;
[0099]
所述5个中间层均为卷积模块convblock3;
[0100]
所述卷积模块convblock3均包括依次连接的3*3卷积层conv7、归一化层bn3和relu激活函数层;所述提取模型的output层为卷积模块convblock4;
[0101]
所述卷积模块convblock4依次包括:3*3卷积层conv7和sigmoid激活函数层;所述3*3卷积层conv7的步长为1,输出通道数为3。
[0102]
表2提取模型的具体结构
[0103]
层级模块输出尺寸input 256*256*3layer1convblock3256*256*64layer2convblock3256*256*128layer3convblock3256*256*256layer4convblock3256*256*128layer5convblock3256*256*64outputconvblock4256*256*3
[0104]
表2中每一层的输出均保持图像尺寸大小不变,最终输出提取出的彩色秘密图像。
[0105]
嵌入模型和提取模型在训练过程中的损失函数l为:
[0106][0107][0108]
其中,c
i,j
为输入的载体图像的第i行第j列的像素点,c
′
i,j
为隐写图像的第i行第i
列的像素点,c
j
为载体图像中第j个rgb像素向量,c
′
j
为隐写图像中第j个rgb像素向量,s
j
为ldr秘密图像中第j个rgb像素向量,s
′
j
为恢复的秘密图像中第j个rgb像素向量,为隐写图像的均值,μ1为载体图像的均值,为恢复的ldr秘密图像的均值,μ2为ldr秘密图像的均值,w为图像的宽度,h为图像的高度,σ
cov1
为载体图像和隐写图像之间的协方差,σ
cov2
为ldr秘密图像和恢复的ldr秘密图像之间的协方差,α、β和γ为权衡因子,用来权衡结构相似性指标在损失函数中所占的比重,β用来权衡余弦相似性指标在损失函数中所占的比重,γ用来权衡提取模型的损失函数在整个隐写方法模型的损失函数中所占的比重,s
i,j
为输入的ldr秘密图像的第i行第j列的像素点,s
′
i,j
为恢复的ldr秘密图像的第i行第j列的像素点,c1和c2为超参数,用于防止分母为0,为隐写图像的方差,σ1为载体图像的方差,为恢复的ldr秘密图像的方差,σ2为ldr秘密图像的方差。
[0109]
通过上述损失函数l训练嵌入模型和提取模型,在模型收敛时,采用一组图像在训练好的嵌入模型和提取模型上进行测试,输入的测试图像以及输出结果如图8~11所示。
[0110]
图8为输入的.exr格式的hdr图像,图9为对应的生成的隐写图像(经色调映射后展示),可以看出生成的隐写图像与原始载体图像在视觉上差异很小,保留着原图大部分的语义和亮度信息;图10为要传递的秘密图像,以及最终恢复的秘密图像(图11),恢复的秘密图像与原图相比稍有模糊,图像中存在一些噪点,但仍保留原图的语义和亮度信息。
[0111]
实验结果
[0112]
为验证本发明的效果,本发明从视觉质量,客观评价结果,以及隐写分析攻击三个方面对生成的隐写图像和恢复的秘密图像进行评估。以下是评估结果:
[0113]
1、主观视觉结果:
[0114]
图12中,每一行分别为一次完整的隐写过程,第一列为hdr载体图像,第二列为嵌入秘密信息后的隐写图像(均经色调映射后展示),第三列为传递的秘密图像,第四列为恢复出的秘密图像。可看出,生成的隐写图像与原始载体图像保持极大的相似程度,恢复出的秘密图像中存在一些噪点,但仍保留语义和细节信息。图13中,第一行是图12中三组hdr图像与隐写图像之间的残差图像,第二行是图12中三组中秘密图像与恢复图像之间的残差图像,从对应的图像对之间的残差图像可以看出,由于对载体图像的修改操作是在小数空域进行的,因此载体图像整体的失真很小,而恢复的秘密信息不是无损恢复,添加了一些噪声扰动。
[0115]
2、客观评价指标:
[0116]
psnr是使用最广泛的、用来衡量图像质量的一个指标;ssim通过亮度、对比度和结构三个方面衡量两幅图片的相似度;针对hdr图像而言,psnr和ssim指标需要经过感知均匀性(pu)编码的处理,hdr
‑
vdp
‑
2中的q
vdp
指标也作为评价标准进行测试。表3为图12中三组载体图像及隐写图像对应的pu
‑
psnr,pu
‑
ssim以及q
vdp
指标和秘密图像及恢复图像的psnr和ssim指标展示。
[0117]
表3指标评价
[0118][0119]
由表3可看出,生成隐写图像在pu
‑
psnr,pu
‑
ssim以及q
vdp
三个指标上都取得了较好的结果,图像质量较好,原始hdr图像和隐写图像之间的误差不可察觉,本发明具有很好的不可见性。由于图像具有冗余特性,秘密图像经过传输之后虽然不能无损恢复,但仍然保持着较高的质量,psnr指标在30db左右,ssim指标也反映出恢复的信息与原始秘密图像在亮度、结构、对比度方面均有有极大的相似性。
[0120]
3、隐写分析攻击
[0121]
以本发明主观结果中的第一组图像为例,分别统计hdr载体图像与hdr隐写图像,ldr秘密图像与恢复的ldr秘密图像之间的像素分布,如图14所示。可看出两组图像对中,像素的总体分布趋势几乎没有发生变化,并且像素误差很小,图像的统计特征没有较大改变。
[0122]
34671维度的srm特征是当前使用较为频繁的通用隐写分析特征,在图像特征提取阶段,分别使用不同的滤波器对图像进行处理,提取图像的6类残差进行分类。本发明将1000张载体图像和对应的隐写图像输入基于srm特征的隐写分析器中,得到最终分类结果的受试者工作(roc)曲线,如图15所示。可看出roc曲线的auc值为0.4948,近似为0.5,即隐写分析器以0.4948的概率成功区分出隐写图像,也就是随机猜想,可说明本发明所提方法能够有效抵抗基于srm特征的隐写分析器的攻击。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:霍永青;乔彦;刘曜辉;甘静
- 技术所有人:电子科技大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....