基于物理定律和过程驱动的深度学习模型的水质预测方法
1.本发明涉及水质预测领域,尤其涉及一种基于物理定律和过程驱动的深度学习模型的水质预测方法。
背景技术:
2.水质预测是实现水质柔性管理、水污染防治的有效工具。目前,水质预测方法有机理模型方法和非机理模型方法两大类。基于过程的机理模型(例如efdc、swat等)包含了根据几十年的观察和实验发展的对过程和机理的理解,具有较强的泛化能力和适用性,是目前进行水质预测的首选方法。如专利cn107091911b公开了一种基于efdc模型的水质预测方法。但是,基于过程的水质模型实现的只是生态系统过程的一部分,可能会受到模型中其他未考虑的实际过程的强烈影响;模型需要的输入条件和环境参数众多,而且获取困难;建模和参数率定过程复杂,预测效率低;此外,水质模型不能方便快捷地集成其他种类数据,造成数据增长和模型改进之间的滞后。
3.随着观测数据的增多和计算能力的提升,非机理模型也被应用于水质预测。如专利cn103605909b公布了一种基于灰色理论和支持向量机的水质预测方法。由于水环境系统的复杂性、非线性、时滞性和不稳定性,dnn、lstm、seq2seq等深度学习算法更适合于水质预测。如专利cn108334977b公布了一种基于改进的bp神经网络的水质预测方法和系统。专利cn107688871b公布了一种基于lstm模型的水质预测方法。专利cn112330005a公布了一种基于seq2seq模型的水质预测方法。但是深度学习方法没有对数据隐含的过程机理的假设,忽略了已知的定律或理论(如物质守恒定律、能量守恒定律等),这种忽略会带来不真实、不准确的预测,导致模型的泛化能力、适用性和推广性差,特别是其应用超过深度学习模型的训练数据的范围时。此外,由于需要大量的历史数据来学习复杂系统的过程机理,深度学习模型在历史数据匮乏地区难以应用。
技术实现要素:
4.有鉴于此,本发明提供一种基于物理定律和过程驱动的深度学习模型的水质预测方法,包括以下步骤:
5.s1、在损失函数中加入对违反物理定律的预测的惩罚项,实现对深度学习模型的物理约束;
6.s2、使用基于过程的水质模型模拟生成水质指标的模拟时间序列数据,并进行预处理,生成训练数据集和验证集;
7.s3、使用训练集对物理定律约束的深度学习模型进行预训练,学习机理模型中人类对过程机理的理解,根据模型在验证集上的表现最优化模型的超参数,得到prpgdl预训练模型;
8.s4、使用历史实测时间序列数据对prpgdl预训练模型进行训练,得到prpgdl模型;
9.s5、将当前和当前时刻之前预设时间段内的实测时间序列数据输入到训练完成的
prpgdl模型中,输出得到未来水质指标的预测数据。
10.进一步地,prpgdl模型为基于本发明提出的技术体系建立的一类水质预测模型的统称,并不限定为某一个确定的模型。
11.进一步地,步骤s1具体为:
12.s11、根据所要预测的水质指标的特征选择合适的物理定律,对选定的物理定律进行概化,计算预测值对应的物理状态偏离真实值对应的物理状态的程度,计算公式概化为:
13.pr(y
m
,y
p
,**arges)=|s(y
m
,**arges)
‑
s(y
p
,**arges)|
‑
α#(1)
14.其中y
m
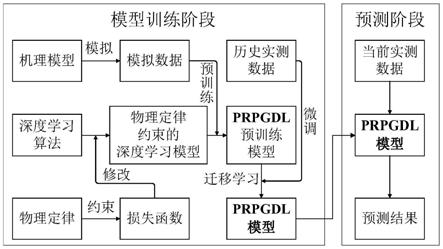
为观测值,y
p
为预测值,**arges为计算选定物理状态的其他变量或参数,s(y,**arges)为计算物理状态的函数,α为根据相关研究确定的偏离程度的阈值;
15.s12、将pr(y
m
,y
p
,**arges)函数集成到深度学习模型的损失函数中,作为损失函数惩罚项的一部分,损失函数修改为:
16.loss function=|pr(y
m
,y
p
,**arges)|
×
loss(y
m
,y
p
)#(2)
17.其中loss(y
m
,y
p
)为深度学习模型未经修改的损失函数,y
m
为观测值,y
p
为预测值。
18.进一步地,所述物理定律包括物质守恒定律、能量守恒定律以及与水体污染物迁移转化过程有关的物理学或湖沼学的定律或规律中的一种或几种。
19.进一步地,步骤s1所述的深度学习模型包括rnn、gru、lstm、lstm
‑
seq2seq、transformer以及这些深度学习模型的常见变体中的一种或几种。
20.进一步地,s2所述的水质模型包括efdc、qual2k、swat以及基于过程的水质模型中的一种或几种。
21.进一步地,所述s2具体过程为:
22.s21:随机生成选定的水质模型所需要的边界条件、参数以及输入变量的模拟数据;
23.s22:将s21生成的边界条件和参数设置为水质模型的边界条件和参数,将输入变量的模拟数据输入到水质模型中,输出得到水质模型的模拟时间序列数据;
24.s23:重复步骤s21和s22,直到生成的模拟时间序列数据的数据量达到设定值;
25.s24:输入变量的模拟数据与水质指标的模拟时间序列数据构成预训练数据集,将预训练数据集按照一定比例划分为训练集和验证集,对训练集、验证集进行标准化处理。
26.进一步地,步骤s21中的输入变量的模拟数据,为随机生成的所选定的水质模型所需要的输入变量的数据,包括气象、水文、地形、地理属性数据以及水质数据中的一种或几种。
27.进一步地,输出的水质指标包括溶解氧、高锰酸盐指数、五日生化需氧量、化学需氧量、叶绿素浓度、氨氮、总氮、总磷、重金属离子的浓度、ph和水温中的一种或几种。
28.本发明提供的技术方案带来的有益效果是:(1)本发明将物理定律、过程驱动的水质机理模型、深度学习模型三者进行结合,充分发挥三者的优点;模型既遵循物理定律规律,又能够体现水质变化的过程机理,还能够具有深度学习模型的灵活性和高效率;
29.(2)相比深度学习模型本发明需要更少的实测数据、准确度更高、泛化能力和推广能力更强,相比基于过程的水质模型本发明需要更少的边界条件和参数数据、有更高的预测准确度和速度,解决了深度学习方法进行水质预测时准确度不高、预测结果可能会违反物理学定律、泛化能力和推广性差、训练数据需求量大、模型可解释性差等问题;
30.(3)本发明为水质预测问题提供了数据要求更少、准确度更高、泛化能力、推广能力、适用性和灵活性更强的方法和技术方案,特别是为资料和数据匮乏地区提供了更适用的水质预测方法。
附图说明
31.图1是本发明一种基于物理定律和过程驱动的深度学习模型的水质预测方法的技术路线图;
32.图2为本发明一种基于物理定律和过程驱动的深度学习模型的水质预测方法的流程图;
33.图3是本发明实施例的一种基于亨利饱和溶解氧公式的过程驱动的lstm
‑
seq2seq模型的溶解氧浓度预测方法的流程图。
具体实施方式
34.为使本发明的目的、技术方案和优点更清楚,下面将结合附图和实施例对本发明的实施方式做进一步的描述。
35.请参考图1,本发明提出一种基于物理定律和过程驱动的深度学习模型的水质预测方法,包括以下步骤:
36.s1、根据相关物理定律修改深度学习模型的损失函数,在损失函数中加入对违反物理规律的预测的惩罚项,实现对深度学习模型的物理约束,具体步骤如下:
37.s11、根据所要预测的水质指标的特征选择合适的物理定律,对选定的物理定律进行概化,计算预测值对应的物理状态偏离真实值对应的物理状态的程度,计算公式概化为:
38.pr(y
m
,y
p
,**arges)=|s(y
m
,**arges)
‑
s(y
p
,**arges)|
‑
α#(1)
39.其中y
m
为观测值,y
p
为预测值,**arges为其他计算选定物理状态的变量,s(y,**arges)为计算物理状态的函数,α为确定偏离程度的阈值;
40.s12、将pr(y
m
,y
p
,**arges)函数集成到深度学习模型的损失函数中,作为损失函数惩罚项的一部分,损失函数修改为:
41.loss function=|pr(y
m
,y
p
,**arges)|
×
loss(y
m
,y
p
)#(2)
42.其中loss(y
m
,y
p
)为深度学习模型未经修改的损失函数,y
m
为观测值,y
p
为预测值。
43.这使得在模型训练过程中,每一次计算损失函数时,都会给对应的物理状态偏离的预测值进行惩罚,通过反向传播和梯度下降算法,在网络参数更新时,会将深度学习模型的连接权重和偏置向偏离程度更小的方向更新,使深度学习模型学习到选定的物理定律,实现物理定律对深度学习模型的约束,保证深度学习模型的预测结果遵守物理定律。
44.选定溶解氧的浓度为本实施例预测的水质指标,使用tensorflow、keras或pytorch建立lstm
‑
seq2seq模型,seq2seq模型的编码器和解码器单元均为lstm单元,其输入数据的时间序列长度为s,输出数据的时间序列长度为t。模型评价指标为纳什效率系数(nse),其计算方式如公式(3)。忽略水中溶质、流速等的影响,根据亨利饱和溶解氧计算公式(公式(4))对lstm
‑
seq2seq模型的损失函数进行修改,如公式(5),每一次计算损失函数时,都根据溶解氧预测数据、溶解氧观测数据、对应预测时间的未经过标准化的水温数据来进行计算,此损失函数会对溶解氧浓度的预测值进行约束,确保其接近预测时刻的水温和
大气压下的饱和溶解氧浓度,避免出现不符合物理规律的预测值。
[0045][0046][0047][0048]
其中,n为预测值的数量,对某一预测时刻,y
m
为溶解氧浓度的观测值,y
p
为其预测值,p为大气压,p0为标准大气压,t为水温,do
f
为饱和溶解氧浓度。
[0049]
s2、使用基于过程的水质模型模拟生成水质指标的模拟时间序列数据进行预处理,形成训练集和验证集;参考图2,具体过程为:
[0050]
s21:随机生成选定的水质模型所需要的边界条件、参数以及输入变量的模拟数据;
[0051]
s22:将s21生成的边界条件、参数等设置为水质模型的边界条件和参数,将输入变量的模拟数据输入到水质模型中,输出得到水质指标的模拟时间序列数据;
[0052]
s23:重复步骤s21和s22,直到生成的模拟时间序列数据的数据量达到设定值;
[0053]
s24:输入变量的模拟数据与水质指标的模拟时间序列数据构成预训练数据集,将预训练数据集按照一定比例划分为训练集和验证集,对训练集、验证集的输入数据进行标准化处理。
[0054]
s2和s22所述的水质指标的模拟时间序列数据,为所选定的水质模型根据模拟条件模拟输出的水质指标的时间序列数据;
[0055]
s2和s23中的预训练数据集,由输入变量的模拟数据和水质指标的模拟时间序列数据分别作为数据集的输入和输出构成;
[0056]
本实施例使用的基于过程的水质模型为efdc模型,进行1000次随机模拟,每次模拟过程,溶解氧和水温为efdc模型的输出变量,模型的参数和边界条件在efdc官方提供的范围内随机生成,随机生成初始条件(输入变量的模拟数据),输入到efdc中,输出得到未来s+t时间段的溶解氧和水温的预测值的时间序列数据。
[0057]
将随机生成的输入变量的模拟数据与对应的efdc模型输出得到的水质指标的模拟时间序列数据构成连续的时间序列数据,构建形状为(batch_size,s,features_num)的输入数据x,batch_size为训练的批次大小,s为输入数据的时间长度,features_num为输入变量的数量。溶解氧的浓度时间序列数据作为输出数据y,其形状为(batch_size,t,1),batch_size为训练的批次大小,与x的batch_size相同,t为预测的溶解氧的时间长度。将x与y对应起来组成预训练数据集,对应的x和y分别为当前时刻至前s时刻的时间序列数据和当前时刻至后t时刻的时间序列数据。
[0058]
将预训练数据集按照8:2的比例分为训练集和验证集,根据训练集输入数据的均值和方差对训练集和验证集的输入数据进行z
‑
score标准化处理,其公式为:
[0059][0060]
其中x
i
为原始数据,为训练集原始数据的均值,std为训练集原始数据的标准差。
[0061]
s3、使用训练集对物理定律约束的深度学习模型进行预训练,学习机理模型中人类对机理过程的理解,根据模型在验证集上的表现选择最优秀的模型超参数,得到prpgdl预训练模型;
[0062]
通过水质模型生成的大量的模拟数据对深度学习模型进行训练,初始化深度学习模型的网络参数,使深度学习模型学习到水质模型中包含的水环境系统的过程和机理,能提高深度学习模型的泛化能力,同时减少了对实测数据的需求。
[0063]
使用训练集对不同超参数的lstm
‑
seq2seq模型进行训练,根据训练好的lstm
‑
seq2seq模型在验证集上的表现(即纳什效率系数),选择在验证集上表现最好的lstm
‑
seq2seq模型,即为prpgdl预训练模型。其中,对每个超参数组合的模型均进行10次重复训练和验证来消除lstm
‑
seq2seq模型参数的随机初始化带来的影响,请参考图3。
[0064]
prpgdl预训练模型具有很强的可推广性和迁移性,可以根据步骤s1选定的物理定律和深度学习模型、步骤s2选定的水质模型满足不同的水质预测需求,可以使用气象、水文、水质等多样的数据,可以对不同的水质指标进行预测,可以得到单个时间点的预测或一段时间序列的预测;根据步骤s4中提供的历史实测数据的来源不同可以适用于不同的流域或地区;prpgdl模型为基于本发明提出的技术体系建立的一类水质预测模型的统称,并不限定为某一个确定的模型。
[0065]
s4、使用历史实测时间序列数据对prpgdl预训练模型进行调整优化训练,得到prpgdl模型;
[0066]
所述的历史实测时间序列数据,为所选定的水质模型的输入变量和输出变量在模型应用地区的历史实测时间序列数据;
[0067]
获取应用地区的水温、溶解氧等使用到的efdc模型的输入变量的历史实测时间序列数据,将其按照预训练集的输入和输出的格式组合成微调数据集,对prpgdl预训练模型进行训练,调整优化模型的网络连接权重和偏置,得到prpgdl模型。
[0068]
s5、将当前和当前时刻之前预设时间段内的实测时间序列数据输入到训练完成的prpgdl模型中,输出得到未来水质指标的预测数据;
[0069]
所述当前和当前时刻之前预设时间段内的实测时间序列数据,为所选定的水质模型的输入变量在模型应用地区的当前和当前时刻之前预设时间段内的时间序列数据。
[0070]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1