基于DQN的不确定车间环境下物料配送实时优化方法
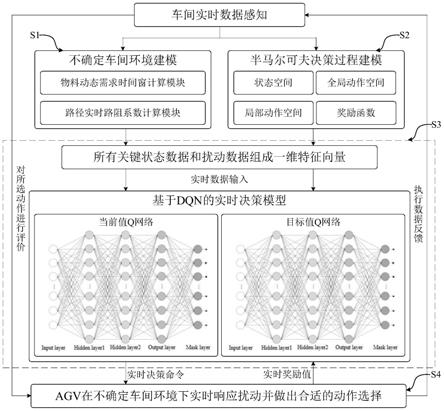
基于dqn的不确定车间环境下物料配送实时优化方法
技术领域
1.本发明涉及一种离散制造车间物料配送技术领域,具体来说涉及一种基于dqn的不确定车间环境下物料配送实时优化方法。
背景技术:
2.通过改善企业车间内部生产物流来提升生产效益,已经成为企业发展的一个重要竞争要素。随着工业物联网(industrial internet of things,iot)和人工智能(artificial intelligence,ai)的快速发展,制造企业的生产方式开始向信息化、智能化方向转变。车间物料配送(material delivery,md)优化问题是生产物流(production logistics,pl)优化问题中的一个重要研究分支,物料准时配送是保障车间生产活动顺利进行的关键。然而离散型制造车间在生产过程中经常存在各种不确定因素,比如设备故障、工件返工、路径临时堵塞和agv失效等。这些不确定因素导致物料需求时间和配送时间难以精确控制,进而增加了企业生产的时间成本。在实际生产过程中,生产系统的不确定因素导致物料需求时间的不确定,车间环境和agv的不确定因素导致物料配送时间的不确定,难以保证物料在合适的时间、以合适的数量、配送到正确的工位。当车间生产过程、设备和环境发生动态变化时,原始物料配送计划难以对各类不确定性事件进行及时响应。
3.目前众多学者对车间物料配送优化问题进行了深入研究,通常将其简化或抽象为一个数学模型,并设计了相应的解决算法,为解决物料配送优化问题提供了理论参考。目前解决物料配送优化问题的主要算法有遗传算法、模拟退火算法、蚁群算法、粒子群算法和混合多目标算法等。然而,传统的静态物料配送优化算法难以完全适应动态的生产状况,在设备故障、工件返工、路径临时堵塞等动态扰动下,预定的配送时间窗和路由失去了最优性,甚至变得不可执行,这意味着静态优化算法对于减少实际生产环境中的物料配送成本几乎没有贡献。
4.随着工业物联网的迅速发展,自动识别技术(射频识别(radio frequency identification,rfid)、超宽带(ultra
‑
wideband,uwb)、条形码和传感器等)人工智能、虚拟仿真等物联网技术在制造车间广泛应用。因此,车间实时制造数据已经变得更容易获取,为不确定环境下车间物料配送动态优化提供了新的解决思路,越来越受到学者们的关注。近年来,基于机器学习的方法由于其优异的学习能力在许多研究领域得到应用。强化学习(reinforcement learning,rl)和深度强化学习(deep reinforcement learning,drl)方法为动态环境中的优化决策提供了一个通用的框架,可以帮助解决组合优化问题。为了实时响应车间环境的变化,采用强化学习(rl)和深度强化学习(drl)方法来实现物料配送的实时决策优化。
技术实现要素:
5.本发明所要解决的技术问题是:提供一种能有效解决不确定车间环境下物料配送存在的动态响应能力弱、配送准确度低和决策实时性不足问题的基于dqn的不确定车间环
境下物料配送实时优化方法。
6.为解决上述技术问题,本发明所采用的技术方案为:一种基于dqn(深度q网络)的不确定车间环境下物料配送实时优化方法,包括以下步骤:
7.s1:不确定车间环境建模
8.考虑到物料需求和配送阶段的动态扰动,以动态时间窗表征物料需求阶段的扰动,以路径实时路阻系数表征物料配送阶段的扰动,以提高物料配送的准确性:
9.s11:建立物料需求动态时间窗计算模块;
10.在物料需求阶段,考虑直接影响工位i的加工时间的扰动因素,包括设备故障、设备疲劳程度、工件返工和工人操作熟练程度,缓存区的传感设备实时感知工位i物料消耗率mv
i
的波动范围和实时物料量realn
i
,根据工位i物料消耗率mv
i
波动数据,结合加权平均法求得工位i加权平均物料消耗率具体表达式如公式(1)所示;工位i物料需求动态时间窗上限t
ib
为工位i物料缓存区实时物料量realn
i
达到其安全物料量safen
i
的时刻;工位i物料需求动态时间窗下限t
ie
等于工位i物料需求动态时间窗上限t
ib
加上工位i物料缓存区安全物料量safen
i
除工位i加权平均物料消耗率的数值,具体表示式如公式(2)所示;当工位i设备发生故障时,工位i物料消耗率mv
i
等于0,因此,工位i新的物料需求动态时间窗(t
ib
,t
ie
)等于其旧的时间窗加上工位i设备的修复时间rt
i
,具体表达式如公式(3)所示:
[0011][0012]
式中:w
j
为工位i实时物料消耗率等于mv
i,j
的数量。
[0013][0014]
(t
ib
+δt,t
ie
+δt)=(t
ib
+rt
i
,t
ie
+rt
i
)
ꢀꢀꢀ
(3)
[0015]
式中:δt表示时间变化量;
[0016]
s12:建立路径实时路阻系数计算模块;
[0017]
在离散制造车间物料配送过程中出现的不同agv的旅行速度不同造成的追击冲突、单向路径下agv旅行方向不同造成的对向冲突和多辆agv要同时通过路口造成的路口冲突,造成agv不能在预期时间将物料配送至相应工位;
[0018]
为了对车间路径路阻系数进行量化,建立了离散制造车间路径路阻函数,具体表达式如公式(4)所示:
[0019][0020]
式中:为某一特定自动导引运输车agvi在路径i上实际旅行时间,在历史数据中获取;为agvi在路径i上理想旅行时间,等于路径i长度pd
i
除agvi的速度av
i
;q
i
为路径i上的agvi和其他移动设备的数量,在历史和实时数据中获取;c
i
为路径i的通行能力,考虑工位数量、单双向路径和路口类型对路径通行能力的影响;α和β为阻滞系数,均为代标定参数;
[0021]
标定路径i的通行能力c
i
,考虑途中工位数量stn
i
、单双向路径ptn
i
和路口类型
mtn
i
三种影响因素,标定的数值越大表示路径通行能力越好;路径i的通行能力c
i
的具体表达式如公式(5)所示:
[0022]
c
i
=0.5
·
ptn
i
+0.3
·
mtn
i
+0.2
·
stn
i
ꢀꢀꢀ
(5)
[0023]
式中,路径i为单向路径ptn
i
取数值为1,双向路径ptn
i
取数值为2;
[0024]
路口类型为路径i两端是两个十字路口时mtn
i
取数值为1;路口类型由一个丁字路口和一个直角路口组成时mtn
i
取数值为5;路口类型由一个十字路口和一个丁字路口组成时mtn
i
取数值为2;路口类型由一个十字路口和一个直角路口组成时mtn
i
取数值为4;路口类型由两个丁字路口组成时mtn
i
取数值为3;
[0025]
maxst为一条路径i途中所能设立的最大工位数,st为一条路径途中设立的工位数,一条路径的通行能力stn
i
与工位数st的关系如公式(a)所示:
[0026][0027]
对参数α和β进行标定,首先对离散制造车间路径路阻函数进行线性化处理,过程如下所示:
[0028][0029]
令:
[0030]
lnα=b,β=a
ꢀꢀꢀ
(8)
[0031][0032]
将式(7)、(8)、(9)带入式(6)可得:y=b+ax,即可进行一元线性回归分析,采用最小二乘法对参数α和β进行标定;
[0033][0034][0035]
式中:x
h
和y
h
表示在历史数据提取的h组数据,和表示在历史数据提取的h组数据的平均值;
[0036]
将式(10)和(11)带入式(8)可标定参数α和β;参数α和β标定后,就可求得每条路径的实时路阻系数realb
i
,具体表示式如公式(12)所示:
[0037][0038]
式中:路径i的通行能力c
i
由公式(5)求得;路径i上的agvi和其他移动设备数量q
i
在实时数据中获取;
[0039]
s2:半马尔可夫决策过程建模
[0040]
s21:状态空间表示;
[0041]
不确定环境下离散制造车间状态空间主要包括工位状态、任务状态、agvi状态和路径状态四要素,由向量s=[s
w
,s
m
,s
a
,s
p
]表示;
[0042]
工位状态用向量s
w
=[realn
i
,t
(i,n=0)
]表示;
[0043]
其中,realn
i
为工位i的物料缓存区实时物料量,用于当agvi到达工位i时奖励的判断条件;t
(i,n=0)
为工位i物料缓存量为0的时刻,用于当agvi到达工位i时计算惩罚成本的条件;
[0044]
任务状态用向量s
m
=[(sx
i
,sy
i
),tp
i
,n
(tp,i)
,(t
ib
,t
ie
)]表示;
[0045]
其中,(sx
i
,sy
i
)表示目标工位i的位置坐标,用来判断是否为本回合终止状态;tp
i
表示目标工位i所需的物料类型,确保物料配送到正确工位;n
(tp,i)
表示目标工位i所需物料的数量,等于工位i物料缓存区最大容量减去工位i的物料缓存区实时物料量;
[0046]
agvi状态用向量s
a
=[as
i
,av
i
,(ax
i
,ay
i
),reala
i
,t
is
]表示;
[0047]
其中,as
i
表示agv i的工作状态,0表示“空闲”,1表示“工作”;av
i
表示agv i的旅行速度,计算奖励值的条件之一;(ax
i
,ay
i
)表示agv i实时位置坐标,ax
i
表示agv i实时位置的x坐标,ax
i
表示agv i实时位置的y坐标;reala
i
表示agv i实时容载量,需满足确保每次物料配送不超过其自身最大容载量;t
is
表示agv i完成工位s配送任务的时刻,是计算agv i到达工位s时的惩罚成本的条件;
[0048]
路径状态用向量s
p
=[d
cd
,pb
i
,realb
i
]表示;
[0049]
其中,d
cd
表示相邻决策点c到d之间的距离,用于计算每次决策的时间成本;pb
i
表示路径i的堵塞状态,1表示“通畅”,∞表示“堵塞”;为了使agvi旅行时间最小化,在agvi走线前应计算考虑障碍物的最短路径;agvi失效、agvi死锁、其他设备占用车道和其他人为因素等都会造成agvi配送路径的临时阻塞;
[0050]
s22:全局动作空间表示;
[0051]
在物料配送过程中,agvi的动作是从等待和各条路径之间做出选择,是离散的;全局动作空间可以表示为:a=[0,1,2,3,
…
,n];0表示agvi停止运行原地等待,1到n表示路径1到路径n;
[0052]
s23:局部动作空间表示;
[0053]
当agvi处于路径i时,部分路径与路径i是没有相连接的,所以只有部分动作是合法的;路径i下合法的局部动作空间可以表示为:
[0054]
a
i
=[0,
…
,g,
…
,h],0<g and h<n,a
i
∈a;
[0055]
s24:奖励函数设计;
[0056]
不确定车间环境下路径的路阻系数不断变化,不同时段的物料配送时间成本不同,及时作出决策响应扰动可降低时间成本;不确定车间环境下物料不能准时送至相应工位会造成工位停工等待,停工等待时间越久惩罚成本越高;agvi从相邻决策点j到k的时间成本agv i完成工位s配送任务总的时间成本和agv i完成工位s配送任务的惩罚成本定义如下所示:
[0057][0058][0059]
式中:c0表示单位时间固定配送成本,reald
jk
表示相邻决策点j到k之间的路阻系数,av
i
表示agv i的旅行速度,表示agv i从决策点j到k的行驶时间,m表示完成工位s配送任务agv i总的决策次数,表示agv i完成工位s配送任务的总行驶时间;
[0060][0061]
式中:realn
s
表示工位s的物料缓存区的实时物料量,c1表示单位时间等待成本,t
isn
表示agvi完成工位s配送任务的延迟时间;具体如下:
[0062]
t
isn
=(t
is
‑
t
(s,n=0)
)
ꢀꢀꢀ
(16)
[0063]
式中,t
is
表示agvi完成工位s配送任务的时刻,t
(s,n=0)
表示工位s物料缓存区物料量为0的时刻,
[0064]
agv i完成工位s配送任务的总成本计算公式如下:
[0065][0066]
另外,根据agv i完成工位s配送任务总的时间成本和agv i完成工位s配送任务的惩罚成本定义总奖励,总奖励r包括dqn与环境交互的主线奖励,具体如公式(18)所示:
[0067][0068]
其中:σ表示惩罚成本系数;
[0069]
s3:基于dqn的实时决策模型的建立
[0070]
s31:两个q值网络的建立;
[0071]
采用两个具有相同神经网络结构的全连接神经网络即评价q网络和目标q网络作为深度q网络dqn的q值函数的逼近器q(s,a,θ)≈q
π
(s,a),其中θ表示相应神经网络的所有参数;通过不断迭代更新神经网络的参数来改进动作状态函数;评价q网络和目标q网络都包括一个输入层、两个隐藏层、一个输出层;
[0072]
s32:dqn实时决策模型的训练
[0073]
在训练过程中,评价q网络负责与环境交互,获取交互数据样本,具体过程如下所述:
[0074]
在状态s下,agvi代理在每一步行动a后获得的环境反馈的总奖励r,并到达下一个状态s
′
,agvi代理将其探索制造车间环境得到的数据以(s,a,r,s
′
)的统一形式存储到回放记忆库中;然后每次学习时从回放记忆库中随机采样数据样本以打破数据之间的相关性;采样数据将分别传输到具有相同网络结构的评价q网络和目标q网络,评价q网络的参数表示为θ,目标q网络的参数表示为θ
′
;在学习过程中,通过评价q网络计算当前动作值函数q
(s,a;θ),通过目标q网络预测下一状态最优动作值函数max
a
′
q(s
′
,a
′
;θ
′
),然后根据贝尔曼方程计算出目标q网络参数下的当前动作值函数q(s,a;θ
′
),再根据两个q网络的误差计算损失函数l(θ),如下所示:
[0075][0076]
l(θ)=e(r+γmax
a
′
q(s
′
,a
′
;θ
′
)
‑
q(s,a;θ))2ꢀꢀꢀ
(20)
[0077]
然后使用随机梯度下降sgd算法更新评价q网络的参数θ,通过不断迭代从而得到最优的q值;
[0078][0079]
最后,每隔n步迭代后目标q网络的参数θ
′
更新为评价q网络的参数θ,即可进行下一阶段的学习;
[0080]
s4:基于dqn的物料配送实时决策优化过程
[0081]
基于dqn的物料配送实时优化方法训练稳定后,指导各个agv在不确定车间环境下实时响应扰动并做出合适的动作选择,以较小的成本快速完成物料配送任务:
[0082]
首先,根据公式(3)计算当前所有任务的物料需求动态时间窗,根据物料需求动态时间窗的下限确定物料配送任务的优先级,优先级高的配送任务被触发;然后根据公式(12)计算当前时刻所有路径的路阻系数;最后,将实时感知到的离散车间所有关键状态数据传输到训练稳定的dqn中;dqn计算出当前状态下的最佳动作,然后传输给各个agv,各个agv接受到命令执行相应动作,直到完成当前选定的物料配送任务;
[0083]
重复以上步骤,直到完成车间所有物料配送任务。
[0084]
作为一种优选的方案,所述步骤s24奖励函数设计中,dqn与环境交互的总奖励还包括辅助奖励,具体如公式(18
‑
2)所示:
[0085][0086]
其中:ε表示时间成本系数,ω表示实时直线距离系数,σ表示惩罚成本系数;reald
ls
表示agvi距离其目标工位s的实时直线距离,具体如公式(b)所示:
[0087][0088]
式中:(ax
i
,ay
i
)表示agv i的实时位置坐标;(sx
s
,sy
s
)表示目标工位s的位置坐标。
[0089]
作为一种优选的方案,所述评价q网络和所述目标q网络还都包括一个设置在相应输出层之后的对全局动作空间中的非法动作进行删除处理的遮掩层。
[0090]
本发明的有益效果是:
[0091]
(1)为了量化车间不确定环境,考虑到物料需求阶段和配送阶段的动态扰动,本发明以动态时间窗表征物料需求阶段的扰动,以路径实时路阻系数表征物料配送阶段的扰动,从而提高不确定车间环境下物料配送的准确性;
[0092]
(2)将深度强化学习应用于车间物料配送领域的关键是将物料配送实时优化问题转化为半马尔可夫决策问题(semi
‑
markov decision process,smdp),详细设计了状态空间、全局动作空间、局部动作空间和奖励函数等关键模型要素,为不确定车间环境下物料配送问题相关状态特征提取提供了参考;
[0093]
(3)通过使用由一个输入层、两个隐藏层、一个输出层和一个遮掩层组成的全连接神经网络来设计dqn的两个q网络,在此基础上提出了基于dqn的车间物料配送实时优化方法。此方法在动作输出层后添加动作遮掩层,保证dqn每次输出的动作都是安全的,提高dqn的训练速度、稳定性和实际应用过程中的安全性。该方法训练稳定后,可以在不确定车间环境状态下快速响应扰动并做出合适的动作选择,为不确定车间环境下物料配送的实时决策优化提供了一个通用的框架。
附图说明
[0094]
图1是本发明的实施例的具体流程图。
[0095]
图2是车间典型路口类型示意图。
[0096]
图3是路径示意图。
[0097]
图4是dqn训练中总奖励的演图。
[0098]
图5是不同规模配送下各优化方法的比较结果图。
[0099]
图6是遮掩层遮掩过程示意图。
具体实施方式
[0100]
下面结合附图1,详细描述本发明的具体实施方案。
[0101]
本发明提出的一种基于dqn的不确定车间环境下物料配送实时优化方法,实施的具体流程图如附图1所示,包括以下步骤:
[0102]
s1:不确定车间环境建模
[0103]
考虑到物料需求和配送阶段的动态扰动,以动态时间窗表征物料需求阶段的扰动,以路径实时路阻系数表征物料配送阶段的扰动,从而提高物料配送的准确性。
[0104]
s11:建立物料需求动态时间窗计算模块;
[0105]
物料需求模糊时间窗(et
ib
,t
ib
,t
ie
,et
ie
)包含可容忍时间范围(et
ib
,et
ie
)和期望配送时间窗范围(t
ib
,t
ie
)。模糊时间窗中的期望配送时间窗范围(t
ib
,t
ie
)是根据工位实际状态计算得出的固定时间范围,但在物料需求阶段出现各种扰动时,期望配送时间窗发生变化,固定的时间范围变得不准确甚至不可用。因此,根据出现的各扰动,及时的调整期望配送时间窗范围,即物料需求动态时间窗,从而提高物料配送准确度。物料需求动态时间窗详细计算过程如下所示:
[0106]
在物料需求阶段,主要考虑的扰动因素有设备故障、设备疲劳程度、工件返工和工人操作熟练程度。以上扰动因素直接影响工位i的加工时间,而加工时间波动直接影响工位i物料消耗率mv
i
,是引起物料需求时间不确定的重要因素。缓存区的传感设备可以实时感知工位i物料消耗率mv
i
的波动范围和实时物料量realn
i
,根据工位i物料消耗率mv
i
波动数据,结合加权平均法求得工位i加权平均物料消耗率具体表达式如公式(1)所示;工位i物料需求动态时间窗上限t
ib
为工位i物料缓存区实时物料量realn
i
达到其安全物料量
safen
i
的时刻;工位i物料需求动态时间窗下限t
ie
等于工位i物料需求动态时间窗上限t
ib
加上工位i物料缓存区安全物料量safen
i
除工位i加权平均物料消耗率的数值,具体表示式如公式(2)所示;当工位i设备发生故障时,工位i物料消耗率mv
i
等于0,因此,工位i新的物料需求动态时间窗(t
ib
,t
ie
)等于其旧的时间窗加上工位i设备的修复时间rt
i
,具体表达式如公式(3)所示。
[0107][0108]
式中:w
j
为工位i实时物料消耗率等于mv
i,j
的数量。
[0109][0110]
(t
ib
+δt,t
ie
+δt)=(t
ib
+rt
i
,t
ie
+rt
i
)
ꢀꢀꢀ
(3)
[0111]
式中:δt表示时间变化量。
[0112]
s12:建立路径实时路阻系数计算模块;
[0113]
在离散制造车间物料配送过程中通常会出现追击冲突(不同agv的旅行速度不同造成的)、对向冲突(单向路径下agv旅行方向不同造成的)和路口冲突(多辆agv要同时通过路口造成的),造成agv不能在预期时间将物料配送至相应工位。为了对车间路径路阻系数进行量化,建立了离散制造车间路径路阻函数,具体表达式如公式(4)所示。
[0114][0115]
式中:为agv在路径i上实际旅行时间,可在历史数据中获取;为agv在路径i上理想旅行时间,等于路径i长度pd
i
除agv的速度av
i
;q
i
为路径i上的agv和其他移动设备的数量,可在历史和实时数据中获取;c
i
为路径i的通行能力,本文主要考虑工位数量、单双向路径和路口类型对路径通行能力的影响;α和β为阻滞系数,均为代标定参数。
[0116]
标定路径i的通行能力c
i
,主要考虑工位数量、单双向路径和路口类型三种影响因素,标定的数值越大表示路径通行能力越好。maxst为一条路径途中所能设立的最大工位数,st为一条路径途中设立的工位数,一条路径的通行能力与工位数的关系如公式(a)所示。
[0117][0118]
路径i为单向路径取数值ptn
i
为1,双向路径取数值ptn
i
为2。路口类型是一个相对复杂的情况,5种典型的路口类型如附图2所示。附图2(a)所示的路口类型是最复杂的,路径i两端是两个十字路口,这种情况下取数值mtn
i
为1。附图2(b)所示的路口类型由一个丁字路口和一个直角路口组成,这种情况下取数值mtn
i
为5。附图2(c)所示的路口类型由一个十字路口和一个丁字路口组成,这种情况下取数值mtn
i
为2。附图2(d)所示的路口类型由一个
十字路口和一个直角路口组成,这种情况下取数值mtn
i
为4。附图2(e)所示的路口类型由两个丁字路口组成,这种情况下取数值mtn
i
为3。综上所述,路径i的通行能力c
i
的具体表达式如公式(5)所示。
[0119]
c
i
=0.5
·
ptn
i
+0.3
·
mtn
i
+0.2
·
stn
i
ꢀꢀꢀ
(5)
[0120]
式中:单双向路径对路径通行能力的影响较大,单向路径的情况下会经常造成对向冲突,进而造成agv死锁堵塞路径,所以其影响权重系数取值为0.5。路口类型越复杂,交通管制时间越多,agv通过路口的时间越久,所以其影响权重系数取值为0.3。路径i上工位数量越多,agv配送越频繁,造成agv等待的可能越大,但在离散制造车间规划时,一条没有路口的路径上一般只规划一个到两个工位,因此,工位数量对路径通行能力的影响较小,所以其影响权重系数取值为0.2。
[0121]
对参数α和β进行标定,首先对离散制造车间路径路阻函数进行线性化处理,过程如下所示:
[0122][0123]
令:
[0124][0125]
lnα=b,β=a
ꢀꢀꢀ
(8)
[0126][0127]
将式子(7)、(8)、(9)带入式子(6)可得:y=b+ax,即可进行一元线性回归分析,采用最小二乘法对参数α和β进行标定。
[0128][0129][0130]
式中:x
h
和y
h
表示在历史数据提取的h组数据,和表示在历史数据提取的h组数据的平均值。将式子(10)和(11)带入式子(8)可标定参数α和β。参数α和β标定后,就可求得每条路径的实时路阻系数,具体表示式如公式(12)所示:
[0131][0132]
式中:路径i的通行能力c
i
由公式(5)求得;路径i上的agv和其他移动设备数量q
i
可在实时数据中获取。
[0133]
s2:半马尔可夫决策过程建模
[0134]
s21:状态空间表示;
[0135]
不确定环境下离散制造车间状态空间主要包括工位状态、任务状态、agv状态和路径状态四要素,可由向量s=[s
w
,s
m
,s
a
,s
p
]表示。
[0136]
工位状态可以用向量s
w
=[realn
i
,t
(i,n=0)
]表示。
[0137]
(1)realn
i
为工位i的物料缓存区实时物料量,用于当agv到达工位i时主线奖励的
判断条件;
[0138]
(2)t
(i,n=0)
为工位i物料缓存量为0的时刻,用于当agv到达工位i时计算惩罚成本的条件。
[0139]
任务状态可以用向量s
m
=[(sx
i
,sy
i
),tp
i
,n
(tp,i)
,(t
ib
,t
ie
)]表示。
[0140]
(1)(sx
i
,sy
i
)表示目标工位i的位置坐标,用来判断是否为本回合终止状态;
[0141]
(2)tp
i
表示目标工位i所需的物料类型,确保物料配送到正确工位;
[0142]
(3)n
(tp,i)
表示目标工位i所需物料的数量,等于工位i物料缓存区最大容量减去工位i的物料缓存区实时物料量。
[0143]
agv状态可以用向量s
a
=[as
i
,av
i
,(ax
i
,ay
i
),reala
i
,t
is
]表示。
[0144]
(1)as
i
表示agv i的工作状态,0表示“空闲”,1表示“工作”;
[0145]
(2)av
i
表示agv i的旅行速度,计算辅助奖励值的条件之一;
[0146]
(3)(ax
i
,ay
i
)表示agv i实时位置坐标,ax
i
表示agv i实时位置的x坐标,ay
i
表示agv i实时位置的y坐标;
[0147]
(4)reala
i
表示agv i实时容载量,确保每次物料配送不超过其自身最大容载量;
[0148]
(5)t
is
表示agv i完成工位s配送任务的时刻,是计算agv i到达工位s时的惩罚成本的条件。
[0149]
路径状态可以用向量s
p
=[d
cd
,pb
i
,realb
i
]表示。
[0150]
(1)d
cd
表示相邻决策点c到d之间的距离,用于计算每次决策的时间成本;
[0151]
(2)pb
i
表示路径i的堵塞状态,1表示“通畅”,∞表示“堵塞”。为了使agv旅行时间最小化,在agv走线前应计算考虑障碍物的最短路径。agv失效、agv死锁、其他设备占用车道和其他人为因素等都会造成agv配送路径的临时阻塞。
[0152]
s22:全局动作空间表示;
[0153]
在物料配送过程中,agv的动作是从等待和各条路径之间做出选择,是离散的。全局动作空间可以表示为:a=[0,1,2,3,
…
,n]。0表示agv停止运行原地等待,1到n表示路径1到路径n。
[0154]
s23:局部动作空间表示;
[0155]
当agv处于路径i时,部分路径与路径i是没有相连接的,所以只有部分动作是合法的。如附图3所示,路径1的合法动作为路径2、路径3、路径4、路径5、路径6和路径7,而路径8、路径9属于非法动作。路径i下合法的局部动作空间可以表示为:a
i
=[0,
…
,g,
…
,h],0<g and h<n,a
i
∈a。
[0156]
s24:奖励函数设计;
[0157]
在强化学习中,奖励函数必须要使智能体在最大化自身奖励的同时也要实现相应的优化目标。本发明旨在最小化物料配送成本和惩罚成本。不确定车间环境下路径的路阻系数不断变化,不同时段的物料配送时间成本不同,及时作出决策响应扰动可降低时间成本。不确定车间环境下物料不能准时送至相应工位会造成工位停工等待,停工等待时间越久惩罚成本越高。时间成本和惩罚成本定义如下所示:
[0158]
[0159][0160]
式中:表示相邻决策点j到k的时间成本,c0表示单位时间固定配送成本,d
jk
是相邻决策点j到k之间的距离,realb
jk
表示相邻决策点j到k之间的路阻系数,av
i
表示agv i的旅行速度,表示agv i从决策点j到k的行驶时间,m表示完成工位s配送任务agv i总的决策次数,表示agv i完成工位s配送任务总的时间成本,表示agv i完成工位s配送任务的总行驶时间。
[0161][0162]
t
isn
=(t
is
‑
t
(s,n=0)
)
ꢀꢀꢀ
(16)
[0163][0164]
式中:表示agv i完成工位s配送任务的惩罚成本,realn
s
表示工位s的物料缓存区的实时物料量,c1表示单位时间等待成本,t
isn
表示agv i完成工位s配送任务的延迟时间。t
is
表示agv i完成工位s配送任务的时刻,t
(s,n=0)
表示工位s物料缓存区物料量为0的时刻,σ表示惩罚成本系数,表示agv i完成工位s配送任务的总成本,为用于验证本发明所提方法的优越性的指标之一。因此,根据时间成本和惩罚成本定义了奖励函数,总奖励r包含dqn与环境交互获得的主线奖励和辅助奖励,具体如公式(18
‑
2)所示:
[0165][0166]
其中:
[0167][0168]
式中:r用于评估agv当前动作的奖励函数,ε表示时间成本系数,reald
is
表示agv i距离其目标工位s的实时直线距离,av
i
表示agv i的旅行速度,ω表示实时直线距离系数,σ表示惩罚成本系数。(ax
i
,ay
i
)表示agv i的实时位置坐标;(sx
s
,sy
s
)表示目标工位s的位置坐标。
[0169]
为了解决稀疏奖励问题,提高数据利用率,加快agv的训练学习速度,本发明设计了辅助奖励,agv没有到达目标工位前,每次动作的辅助奖励是其决策时间成本加实时直线距离的负折扣值,每次选择的动作使agv旅行时间越短和距离目标工位越近得到的辅助奖励就越大。如果物料配送路径被临时堵塞,并且agv选择了等待,其辅助奖励是0,但是agv等待越久,最终的主线奖励越小。主线奖励分两类,一类是agv在规定时间内成功到达目标工位,一类是agv成功到达目标工位。agv在规定时间内成功到达目标工位,即agv到达目标工位时其缓存区物料量大于0,agv会得到100的主线奖励。agv成功到达目标工位,即agv到达目标工位时其缓存区物料已消耗殆尽,agv会得到100减去惩罚成本的主线奖励。在主线奖
励和辅助奖励下agv为了获得更高奖励就会以最短的时间到达目标工位,从而达到快速响应车间动态扰动的目的。
[0170]
s3:基于dqn的实时决策模型的建立
[0171]
s31:两个q值网络的建立;
[0172]
在drl领域神经网络和深度神经网络(dnns)已被证明是有效的函数逼近器。在此基础上,利用神经网络作为dqn的q值函数的逼近器q(s,a,θ)≈q
π
(s,a),其中θ表示相应神经网络的所有参数。通过不断迭代更新神经网络的参数来改进动作状态函数。本发明设计了两个具有相同神经网络结构的神经网络,即评价q网络和目标q网络。本发明详细的设计了状态空间,状态特征已经明确界定,状态信息是一组一维的标量并且很容易获取。因此,所设计的神经网络不需要卷积层和池化层对状态输入进行特征提取。通过使用由一个输入层、两个隐藏层、一个输出层和一个遮掩层组成的全连接神经网络来设计两个q网络。由于在局部车间状态下,全局动作a
t
中有许多动作是不合法的,因此,通过加入遮掩层对不合法的动作进行遮掩。更多q网络结构参数如附表1所示。遮掩过程如附图6所示,神经网络的输出层输出全局动作的q值,局部动作空间表示的是当前环境状态下合法的动作集合,遮掩层结合局部动作空间对全局动作空间中的非法动作进行删除处理,遮掩层处理过后的输出全部为合法动作的q值,利用softmax函数,输出q值最大的合法动作,从而提高dqn的训练速度、稳定性和实际应用过程中的安全性。
[0173]
表1 q网络结构参数
[0174][0175]
s32:dqn实时决策模型的训练
[0176]
在训练过程中,评价q网络负责与环境交互,获取交互数据样本,具体过程如下所述。在状态s下,agv代理在每一步行动a后都将获得环境反馈的辅助奖励,并到达下一个状态s
′
,直到终止状态agv代理会获得主线奖励。但是agv代理并不立刻进行学习,而是将其探索制造车间环境得到的数据以(s,a,r,s
′
)的统一形式存储到回放记忆库中。然后每次学习时从回放记忆库中随机采样数据样本,打破数据之间的相关性,提高训练学习效率和数据样本利用率。采样数据将分别传输到具有相同网络结构的评价q网络和目标q网络,但是两个q网络参数不同,评价q网络的参数表示为θ,目标q网络的参数表示为θ
′
。在学习过程中,通过评价q网络计算当前动作值函数q(s,a;θ),通过目标q网络预测下一状态最优动作值函数max
a
′
q(s
′
,a
′
;θ
′
),然后根据贝尔曼(bellman)方程计算出目标q网络参数下的当前动作值函数q(s,a;θ
′
),再根据两个q网络的误差计算损失函数l(θ),如下所示。
[0177][0178]
l(θ)=e(r+γmax
a
′
q(s
′
,a
′
;θ
′
)
‑
q(s,a;θ))2ꢀꢀꢀ
(20)
[0179]
然后使用随机梯度下降(stochastic gradient descent,sgd)算法更新评价q网络的参数θ,通过不断迭代从而得到最优的q值。
[0180][0181]
最后,每隔n步迭代后目标q网络的参数θ
′
更新为评价q网络的参数θ,即可进行下一阶段的学习。
[0182]
s4:基于dqn的物料配送实时决策优化过程
[0183]
基于dqn的物料配送实时优化方法训练稳定后,指导agv在不确定车间环境下实时响应扰动并做出合适的动作选择,以较小的成本快速完成物料配送任务。首先,根据公式(3)计算当前所有任务的物料需求动态时间窗,根据物料需求动态时间窗的下限确定物料配送任务的优先级,优先级高的配送任务被触发。然后根据公式(12)计算当前时刻所有路径的路阻系数。最后,将实时感知到的离散车间所有关键状态数据传输到训练稳定的dqn中。dqn计算出当前状态下的最佳动作,然后传输给agv,agv接受到命令执行相应动作,直到完成当前选定的物料配送任务。重复以上步骤,直到完成车间所有物料配送任务。
[0184]
dqn每集累积总奖励的演变如附图4所示,训练的前1600集表现相当糟糕,agv代理每集的损失奖励大约为80。然而,agv代理很快就学会了一个有效策略,总的的奖励在1600集到2300集之间快速增长,之后逐渐达到稳定状态,这也意味着agv代理实现了最优动作策略。
[0185]
在400次配送实例中,将本发明所提出的方法与常用的几种方法:传统强化学习算法q
‑
learning和sarsa、结合动态时间窗的两阶段蚁群算法dtaco、结合动态时间窗的蚁群算法daco、结合动态时间窗的遗传算法dga、结合模糊时间窗的两阶段蚁群算法taco、结合模糊时间窗的蚁群算法aco、结合模糊时间窗的遗传算法ga进行对比分析,结果如附表2所示。
[0186]
从物料配送及时性和成本的角度对这些方法进行综合评价,建立了三个评价指标,即工位设备平均利用率配送总成本c
t
和agv总旅行距离d
t
。
[0187]
工位设备利用率的计算方式如下所示:
[0188][0189][0190]
式中:u
i
表示工位i设备利用率,tn
i
表示工位i设备的正常工作时长,ta
i
表示工位i设备的停机等待时长,p表示总工位数。配送总成本的计算方式如下所示:
[0191][0192]
式中:表示agvi完成第s次配送任务的总成本,n为总配送任务数,由公式(17)计算所得。
[0193][0194]
式中:表示agv i完成第s次配送任务的旅行距离。
[0195]
表2本发明所提方法与其他方法各指标的对比结果
[0196][0197][0198]
由表2可知:(1)采用动态时间窗的优化方法dtaco、daco和dga与采用模糊时间窗的优化方法taco、aco和ga比较,工位设备平均利用率提高了1.91%、1.72%和2.09%,配送总成本降低了1182.9、768.9和1085.8个单位。可以看出,本发明提出的动态时间窗与模糊时间窗相比,可以大大降低配送成本。
[0199]
(2)所提方法与统强化学习算法q
‑
learning和sarsa比较,工位设备平均利用率分别提高了3.43%和2.59%,配送总成本分别降低了1081.3和682个单位,agv总旅行距离分别减少了67.3m和173m。
[0200]
(3)所提方法与采用动态时间窗的动态优化方法dtaco比较,工位设备平均利用率提高了6.16%,配送总成本降低了1897.2个单位,agv总旅行距离增加了222.1m。
[0201]
(4)该方法与传统的动态优化方法taco比较,工位设备平均利用率提高了8.07%,配送总成本降低了3080.1个单位,agv总旅行距离增加了98.6m。
[0202]
(5)所提方法与采用动态时间窗的静态优化方法daco和dga比较,工位设备平均利用率分别提高了15.53%和16.32%,配送总成本分别降低了9475.4和11165.9个单位,agv总旅行距离分别增加了5277.9m和5571.7m。
[0203]
(6)所提方法与传统的静态优化方法aco和ga比较,工位设备平均利用率分别提高了17.25%和18.41%,配送总成本分别降低了6043.8和6657.5个单位,agv总旅行距离分别增加了1208m和1121.3m。
[0204]
(7)以上对比结果表明了该方法在对车间动态扰动实时响应和决策方面的优越性,可以有效的提高物料配送准确率,提高设备利用率,降低物料配送成本。
[0205]
如附图5(a)所示,随着配送规模的增加,所提方法与两种经典的rl方法的性能变化不大,而传统的动态优化方法和静态优化方法的性能变化较大。如图5(b)所示,随着配送规模的增加,传统的动态优化方法和静态优化方法的总成本的增幅较大。原因是传统的各优化方法不能及时响应车间的扰动变化,随着任务的不断进行与原计划的偏差不断累积。
如图5(c)所示,所提方法与两种经典的rl方法虽然在agv旅行距离上略有增加,但可以取得更优的整体性能,这也揭示了在不确定车间环境下以最短路径为优化目标的物料配送方法并不能取得较好的优化结果。在不确定的车间环境下,应实时规划出旅行时间最短的配送路径,才能有效的提高物料配送准确率,降低物料配送成本。以上实验结果证明了所提出的方法在不确定环境下的离散制造车间物料配送实时优化中的可行性与有效性。
[0206]
上述的实施例仅例示性说明本发明创造的原理及其功效,以及部分运用的实施例,而非用于限制本发明;应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1