本发明属于网络优化技术领域,尤其涉及一种基于粒子群优化算法的增量贝叶斯网学习系统。
背景技术:
目前:贝叶斯网络(bayesiannetwork,bn)理论为不确定性知识的表示、节点间复杂关系的表达和信息融合推理提供了有效的模型框架。然而,与其它图形化模型学习方法类似,bn也存在研究对象节点增加导致候选结构数量呈指数级增长的问题。因此,从大规模候选结构集合中快速、准确地获得一个与数据样本匹配程度最优的结构模型是bn结构学习亟待解决的问题之一。
在现实世界中很多数据是由数据源持续性、增量式生成的,增量学习是以新数据顺序更新学习结果的在线学习过程,它不丢弃已有学习结果,而是不断地利用新数据更新和求精已经学习到的结果,很适合处理这类情况。近年来,很多学者研究了贝叶斯网的增量学习方法。但传统贝叶斯网增量学习方法往往假定目标概率分布不变,但领域问题本身时常固有动态变化特性,当目标概率分布发生变化时,已有学习方法难以有效处理。
通过上述分析,现有技术存在的问题及缺陷为:现有的贝叶斯网学习方法效率不佳,精度不佳。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于粒子群优化算法的增量贝叶斯网学习系统。
本发明是这样实现的,一种基于粒子群优化算法的增量贝叶斯网学习系统,所述基于粒子群优化算法的增量贝叶斯网学习系统包括:
数据采集模块、数据处理模块、中央控制模块、拓扑结构确定模块、参数学习模块、优化模块、输出模块以及存储模块;
数据采集模块,与中央控制模块连接,用于采集获取相应的网络训练样本数据;
中央控制模块,与数据采集模块、数据处理模块、拓扑结构确定模块、参数学习模块、优化模块、输出模块以及存储模块连接,用于利用单片机或控制器控制各个模块正常工作;
所述利用单片机或控制器控制各个模块正常工作包括:
通过灰色模型进行控制;所述灰色模型是由一组灰色微分方程组成的动态模型,建立所述灰色模型gm(1,1)模型,所述建模包括:
x(0)为原始非负数据序列:x(0)=[x(0)(1),x(0)(2),...,x(0)(n)],对x(0)进行一次累加生成操作,得到x(0)的1-ago序列,x(1)=[x(1)(1),x(1)(2),...,x(1)(n)],其中,
对序列x(1)进行紧邻均值生成操作,得到x(1)的紧邻均值生成序列z(1),其中z(1)(k)=0.5[x(1)(k)+x(1)(k-1)],k=1,2,...,n;
得到gm(1,1)的灰色微分方程:x(0)(k)+az(1)(k)=u,以及相应的白化方程:其中,a为发展系数,u为灰色作用量;
进行a、u的求解:采用最小二乘法其中,yn=[x(0)(2)x(0)(3)...x(0)(n)]t;白化方程的解为相应的灰色微分方程的时间响应序列为:即k时刻的值
对序列进行累减生成操作,即累加生成的逆运算,记为iago,可得预测序列其中,
k+d时刻的预测值为:d为系统滞后时间;
拓扑结构确定模块,与中央控制模块连接,用于基于预处理后的样本数据进行增量式结构学习,得到贝叶斯网络的拓扑;
参数学习模块,与中央控制模块连接,用于基于处理后的训练样本,结合方法份贝叶斯网络的拓扑进行参数学习,得到所述贝叶斯网络的参数;
优化模块,与中央控制模块连接,用于利用粒子群优化算法对得到的贝叶斯网络拓扑结构以及参数进行优化,得到最优贝叶斯网络。
进一步,所述基于粒子群优化算法的增量贝叶斯网学习系统还包括:
数据处理模块,与中央控制模块连接,用于对采集的相应的训练样本数据进行预处理;
输出模块,与中央控制模块连接,用于输出得到的最优的贝叶斯网络及相应参数;
存储模块,与中央控制模块连接,用于利用存储器存储处理的相应数据得到的最优贝叶斯网络及相应参数。
进一步,所述利用粒子群优化算法对得到的贝叶斯网络拓扑结构以及参数进行优化,得到最优贝叶斯网络包括:
(1)将等效为粒子的备选解随机分配至多层基本结构以及参数中,每层基本结构包括至少一个粒子;
(2)计算所述粒子的适应度值,更新所述每层基本结构以及参数的惯性权值,并依据所述适应度值及所述惯性权值更新各粒子速度值和各粒子位置值;
(3)判断所述每层基本结构以及参数中的各个粒子是否满足预设变异规则,对所述满足所述变异规则的粒子进行变异处理;依据所述适应度值、所述各粒子速度值及所述各粒子位置值获取最优粒子;
(4)判断所述最优粒子是否满足预设的选取规则,如果是,获取所述最优粒子中的最优解,否则,依据所述适应度值及所述惯性权值重新更新所述每层基本结构各粒子速度值和各粒子位置值,并依据所述适应度值及所述重新更新的各粒子速度值和各粒子位置值,获取最优粒子,即为最优贝叶斯网络结构及参数。
进一步,所述判断所述每层基本结构以及参数中的各个粒子是否满足预设变异规则,对所述满足所述变异规则的粒子进行变异处理包括:
计算种群适应度方差,根据方差及种群全局最优值,确定变异操作粒子数概率p,变异操作粒子数概率p取值规则如下:
其中,pmax为粒子最大变异概率;pmin为粒子最小变异概率;
若p∈[pmin,pmax],则按p进行变异操作,否则再考虑粒子群方差值σ2是否超出设定最大方差值σ2d,粒子群的最优值适应度值f(gbest)是否超出设定的最优适应度值fd,若满足变异操作粒子数概率p以固定概率β进行变异操作,否则不进行变异操作,其操作过程如下公式:
其中fd为设定的最优适应度值;f(gbest)为此次优化过程中最优适应度值;σ2d为设定最大方差值;σ2为此次优化过程中方差值;β为常数,固定概率。
进一步,所述依据所述适应度值、所述各粒子速度值及所述各粒子位置值获取最优粒子包括:
初始化所述每层基本结构以及参数中的群体最优值和各个粒子的个体最优值及全体最优值;
依据所述适应度值、所述各粒子速度值及所述各粒子位置值,更新所述每层基本结构以及参数中各个粒子的个体最优值;
依据所述适应度值和所述每层基本结构以及参数中各个粒子的个体最优值,更新所述每层基本结构以及参数的群体最优值;
将所述每层基本结构以及参数中与该层基本结构以及参数的群体最优值相对应的粒子依据预设的交流规则传送至表层结构及参数中;
依据所述表层结构及参数中的粒子的个体最优值及所述全体最优值,获取最优粒子。
进一步,所述对采集的相应的训练样本数据进行预处理包括:
剔除原始样本数据中的异常数据;将原始样本进行总体的正则化,并记录总体样本的均值和方差及其他正则化参数信息。
进一步,所述剔除原始样本数据中的异常数据包括:
根据所述待处理数据的分布状态确定异常值检测方法;根据所述异常值检测方法检测所述原始样本数据中的异常值;删除检测到的原始样本数据中的异常值。
本发明的另一目的在于提供一种信息数据处理终端,其特征在于,所述信息数据处理终端用于实现所述基于粒子群优化算法的增量贝叶斯网学习系统。
本发明的另一目的在于提供一种存储在计算机可读介质上的计算机程序产品,包括计算机可读程序,供于电子装置上执行时,提供用户输入接口以应用所述基于粒子群优化算法的增量贝叶斯网学习系统。
本发明的另一目的在于提供一种计算机可读存储介质,储存有指令,当所述指令在计算机上运行时,使得计算机应用所述基于粒子群优化算法的增量贝叶斯网学习系统。
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明将粒子群算法应用于贝叶斯网络学习中,并模拟现实中数据增长的环境,将普通的一次性学习过程改为增量学习过程,使网络模型的结构和参数随时间动态更新,以适应新数据的不断到来。
本发明通过计算参与寻优的粒子适应度值,更新每层基本基本结构及参数的惯性权值,使得在参与寻优的粒子较少时,避免寻优获取的个体最优值对应的粒子趋于具有共同特征值的粒子,即趋同性,从而避免获取的最优粒子的最优解误差偏大,提高了最优解的准确性。
本申请发明通过对参与寻优的粒子进行变异判断,并对变异的粒子进行校正处理,更进一步的避免由于粒子变异被忽略导致的寻优结果趋同性的情况,提高了最优解的准确性。
本发明在粒子群算法的基本框架中增加了由种群适应度方差以及粒子数确定的随机变异算子和通过对最优适应度值得判断而确定固定变异算子来提高粒子群跳出局部最优解的能力且增加了粒子群的多样性,从而使其全局搜索能力增强,算法的鲁棒性也得到了较大提高。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
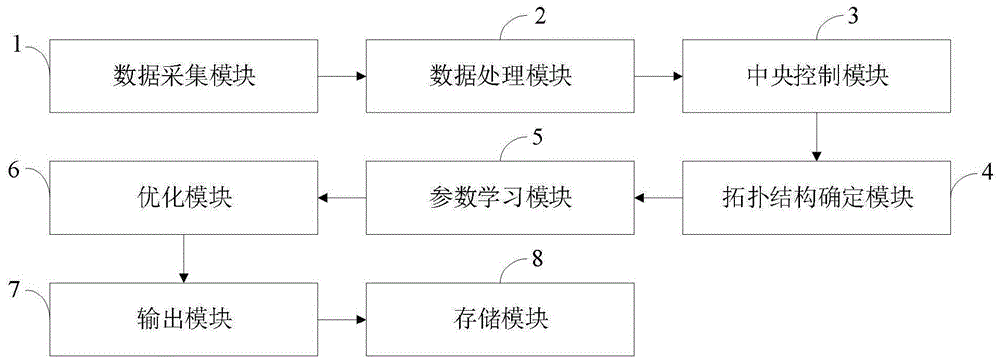
图1是本发明实施例提供的基于粒子群优化算法的增量贝叶斯网学习系统结构示意图;
图中:1、数据采集模块;2、数据处理模块;3、中央控制模块;4、拓扑结构确定模块;5、参数学习模块;6、优化模块;7、输出模块;8、存储模块。
图2是本发明实施例提供的利用粒子群优化算法对得到的贝叶斯网络拓扑结构以及参数进行优化,得到最优贝叶斯网络的方法流程图。
图3是本发明实施例提供的依据所述适应度值、所述各粒子速度值及所述各粒子位置值获取最优粒子的方法流程图。
图4是本发明实施例提供的对采集的相应的训练样本数据进行预处理的方法流程图。
图5是本发明实施例提供的剔除原始样本数据中的异常数据的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对现有技术存在的问题,本发明提供了一种基于粒子群优化算法的增量贝叶斯网学习系统,下面结合附图对本发明作详细的描述。
如图1所示,本发明实施例提供的基于粒子群优化算法的增量贝叶斯网学习系统包括:
数据采集模块1,与中央控制模块3连接,用于采集获取相应的网络训练样本数据;
数据处理模块2,与中央控制模块3连接,用于对采集的相应的训练样本数据进行预处理;
中央控制模块3,与数据采集模块1、数据处理模块2、拓扑结构确定模块4、参数学习模块5、优化模块6、输出模块7以及存储模块8连接,用于利用单片机或控制器控制各个模块正常工作;
拓扑结构确定模块4,与中央控制模块3连接,用于基于预处理后的样本数据进行增量式结构学习,得到贝叶斯网络的拓扑;
参数学习模块5,与中央控制模块3连接,用于基于处理后的训练样本,结合方法份贝叶斯网络的拓扑进行参数学习,得到所述贝叶斯网络的参数;
优化模块6,与中央控制模块3连接,用于利用粒子群优化算法对得到的贝叶斯网络拓扑结构以及参数进行优化,得到最优贝叶斯网络;
输出模块7,与中央控制模块3连接,用于输出得到的最优的贝叶斯网络及相应参数;
存储模块8,与中央控制模块3连接,用于利用存储器存储处理的相应数据得到的最优贝叶斯网络及相应参数。
本发明实施例提供的利用单片机或控制器控制各个模块正常工作包括:
通过灰色模型进行控制;所述灰色模型是由一组灰色微分方程组成的动态模型,建立所述灰色模型gm(1,1)模型,所述建模包括:
x(0)为原始非负数据序列:x(0)=[x(0)(1),x(0)(2),...,x(0)(n)],对x(0)进行一次累加生成操作,得到x(0)的1-ago序列,x(1)=[x(1)(1),x(1)(2),...,x(1)(n)],其中,
对序列x(1)进行紧邻均值生成操作,得到x(1)的紧邻均值生成序列z(1),其中z(1)(k)=0.5[x(1)(k)+x(1)(k-1)],k=1,2,...,n;
得到gm(1,1)的灰色微分方程:x(0)(k)+az(1)(k)=u,以及相应的白化方程:其中,a为发展系数,u为灰色作用量;
进行a、u的求解:采用最小二乘法其中,yn=[x(0)(2)x(0)(3)...x(0)(n)]t;白化方程的解为相应的灰色微分方程的时间响应序列为:即k时刻的值
对序列进行累减生成操作,即累加生成的逆运算,记为iago,可得预测序列其中,
k+d时刻的预测值为:d为系统滞后时间。
如图2所示,本发明实施例提供的利用粒子群优化算法对得到的贝叶斯网络拓扑结构以及参数进行优化,得到最优贝叶斯网络包括:
s101,将等效为粒子的备选解随机分配至多层基本结构以及参数中,每层基本结构包括至少一个粒子;
s102,计算所述粒子的适应度值,更新所述每层基本结构以及参数的惯性权值,并依据所述适应度值及所述惯性权值更新各粒子速度值和各粒子位置值;
s103,判断所述每层基本结构以及参数中的各个粒子是否满足预设变异规则,对所述满足所述变异规则的粒子进行变异处理;依据所述适应度值、所述各粒子速度值及所述各粒子位置值获取最优粒子;
s104,判断所述最优粒子是否满足预设的选取规则,如果是,获取所述最优粒子中的最优解,否则,依据所述适应度值及所述惯性权值重新更新所述每层基本结构各粒子速度值和各粒子位置值,并依据所述适应度值及所述重新更新的各粒子速度值和各粒子位置值,获取最优粒子,即为最优贝叶斯网络结构及参数。
本发明实施例提供的判断所述每层基本结构以及参数中的各个粒子是否满足预设变异规则,对所述满足所述变异规则的粒子进行变异处理包括:
计算种群适应度方差,根据方差及种群全局最优值,确定变异操作粒子数概率p,变异操作粒子数概率p取值规则如下:
其中,pmax为粒子最大变异概率;pmin为粒子最小变异概率;
若p∈[pmin,pmax],则按p进行变异操作,否则再考虑粒子群方差值σ2是否超出设定最大方差值σ2d,粒子群的最优值适应度值f(gbest)是否超出设定的最优适应度值fd,若满足变异操作粒子数概率p以固定概率β进行变异操作,否则不进行变异操作,其操作过程如下公式:
其中fd为设定的最优适应度值;f(gbest)为此次优化过程中最优适应度值;σ2d为设定最大方差值;σ2为此次优化过程中方差值;β为常数,固定概率。
如图3所示,本发明实施例提供的依据所述适应度值、所述各粒子速度值及所述各粒子位置值获取最优粒子包括:
s201,初始化所述每层基本结构以及参数中的群体最优值和各个粒子的个体最优值及全体最优值;
s202,依据所述适应度值、所述各粒子速度值及所述各粒子位置值,更新所述每层基本结构以及参数中各个粒子的个体最优值;
s203,依据所述适应度值和所述每层基本结构以及参数中各个粒子的个体最优值,更新所述每层基本结构以及参数的群体最优值;
s204,将所述每层基本结构以及参数中与该层基本结构以及参数的群体最优值相对应的粒子依据预设的交流规则传送至表层结构及参数中;
s205,依据所述表层结构及参数中的粒子的个体最优值及所述全体最优值,获取最优粒子。
如图4所示,本发明实施例提供的对采集的相应的训练样本数据进行预处理包括:
s301,剔除原始样本数据中的异常数据;
s302,将原始样本进行总体的正则化,并记录总体样本的均值和方差及其他正则化参数信息。
如图5所示,本发明实施例提供的剔除原始样本数据中的异常数据包括:
s401,根据所述待处理数据的分布状态确定异常值检测方法;
s402,根据所述异常值检测方法检测所述原始样本数据中的异常值;删除检测到的原始样本数据中的异常值。
以上所述,仅为本发明较优的具体的实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。