用于创建知识图谱的计算机实现的方法和设备与流程
1.本公开涉及用于创建知识图谱的计算机实现的方法和设备。
2.此外,本公开涉及用于训练模型用以在用于创建知识图谱的计算机实现的方法中和/或设备中使用的方法。
背景技术:
3.在基于知识的系统中,知识图谱(knowledge graph)被理解为以知识图谱的形式对知识的结构化存储。知识图谱包括实体并且再现实体之间的关系。实体定义知识图谱的节点。关系定义为两个节点之间的边。
技术实现要素:
4.一种实施方式涉及用于创建知识图谱的计算机实现的方法,其中知识图谱包括尤其是形式为<实体a,实体b,实体a与实体b之间的关系>的多个三元组,其中所述方法包括:提供文本主体,提供用于模型的输入数据,所述输入数据根据文本主体和知识图谱的实体定义,以及利用模型确定分别包括知识图谱的两个实体的三元组,并且利用模型确定用于验证相应三元组的解释(erkl
ä
rung),其中为了确定三元组以及为了确定解释执行以下步骤:对文本主体的相关的区域进行分类,并且丢弃文本主体的不被分类为相关的区域,并且从文本主体的相关的区域中导出(ableiten)第一实体与第二实体之间的关系。
5.因此提出一种层次模型,利用所述层次模型首先从文本主体中提取三元组,并且进一步为相应三元组从文本主体中提取解释。在此,发生文本主体的相关的区域的耦合用于确定相应三元组并且用于确定用于相应三元组的解释。利用在根据本发明的方法中使用的模型确保:相应三元组只能从文本主体的相关的区域中被提取。通过该模型的架构防止:从文本主体的被分类为不相关的区域中提取三元组。该模型改善知识图谱中实体之间的关系或三元组的可解释性。
6.从现有技术中,已知模型和方法,其中使用具有两个输出层的模型。具有两个输出层的模型具有以下缺点:输出层虽然在相同的输入表示上操作,但是其他方面彼此独立。也就是说,已经对这样的模型进行了训练,用以提取三元组并且标记看上去相关的语句。然而,这两个部分不相关联(verbunden)。该模型提取三元组和相关的语句,但是不存确保相关的语句实际上在模型中也导致了该三元组的机制。因此,在从现有技术已知的模型情况下,相关的语句不能被用于解释模型的回答。
7.利用根据本发明的方法,该问题通过模型架构解决,该模型架构确保所提取的三元组只能来自文本主体的被分类为相关的区域。
8.优选地,在模型的第一输出端处输出包括三元组的输出。在该示例中,输出定义包括给定的第一和第二实体以及两个实体之间的关系的三元组、即形式为<实体a,实体b,实体a与实体b之间的关系>的三元组。
9.有利地,在模型的第二输出端处输出包括用于验证三元组的解释的输出。在该示
例中,输出定义用于相应三元组的解释。在此,该解释有利地包括文本主体的至少一个被分类为相关的区域和/或定义文本主体的至少一个被分类为相关的区域的信息。
10.根据一种优选实施方式,相应三元组的解释被定义为元数据,所述元数据分配给知识图谱的相应三元组。在相应三元组的解释中,定义在文本主体中的至少一个被分类为相关的区域的开始和结束。因此,该解释说明文本主体的至少一个区域,所述区域验证三元组。
11.根据一种优选实施方式,文本主体的区域包括至少一个语句和/或至少一个词。
12.根据其他优选实施方式规定,该方法此外包括:迭代地检验相应解释的被分类为相关的区域。在此,有利地是后处理过程,利用该后处理过程能够检验并且必要时能够减少解释的被分类为相关的区域。有利地,进一步限制解释中的被分类为相关的区域,使得解释包括尽可能精确数量的被分类为相关的区域。精确数量在此被理解为以下数量(menge):该数量尽可能小、也就是说尽可能不包括不相关的区域,但仍必要地大、也就是说由解释包括所有在模型中已导致导出相应三元组的区域。例如,利用后处理过程可以从解释中移除冗余的区域或不太相关的区域。
13.根据一种优选实施方式,迭代地检验被分类为相关的区域包括以下步骤:检验不具有被分类为相关的相应区域的解释是否是用于相应三元组的解释,并且根据检验的结果,在解释中保留被分类为相关的相应区域,或从解释中丢弃被分类为相关的相应区域。如果解释在不具有该区域的情况下仍然是用于三元组的解释,也即如果在移除该区域之后仍然能够从解释中提取相应三元组,则有利地从该解释中丢弃被分类为相关的区域。同样地,如果解释在不具有该区域的情况下不是用于三元组的解释,也即如果在移除该区域之后不再能够从解释中提取相应三元组,则在解释中保留被分类为相关的区域。
14.根据一种优选实施方式,在迭代地检验之前,按照升序相关性对解释的被分类为相关的区域进行排序。从被分类为最低相关的(als am geringsten als relevant klassifizierten)片段开始执行迭代式检验。
15.根据一种优选实施方式,只要相应解释至少包括数目n个被分类为相关的区域,其中n=1、2、3、...,并且迭代次数小于或等于被分类的区域的数目,则执行迭代式检验。在满足中止准则时,结束迭代式检验。可以确定数目n。
16.根据一种优选实施方式,通过文本主体、尤其是文档集或文本集的嵌入以及通过知识图谱的实体的嵌入来定义模型的输入数据。文本主体例如是文本集或文档集。从文本主体出发,由此(von der)为各个词或语句例如作为词向量产生嵌入。例如,同样为实体产生词向量。
17.根据一种优选实施方式,利用模型为文本主体的至少一个区域根据文本主体的至少一个其他区域和知识图谱的至少两个实体来确定向量表示。例如,为文本主体的每个词和/或每个语句确定上下文有关的向量表示,该向量表示不仅取决于文本主体的其他语句和/或词而且取决于两个实体。
18.根据一种优选实施方式,该模型包括神经元模型,并且在使用池化层的情况下丢弃文本主体的被分类为不相关的区域。
19.本公开的其他优选实施方式涉及一种用于确定知识图谱的设备,其中所述设备被构造用于执行根据上述实施方式的方法。
20.本公开的其他优选实施方式涉及一种计算机程序,其中所述计算机程序包括机器可读指令,当在计算机上执行所述机器可读指令时执行根据上述实施方式的方法。
21.根据实施方式的方法和/或实施方式的系统还可以被应用于在问答系统的框架内尤其是自动地提取相关的事实。问答系统尤其是在对话系统或辅助系统中起重要作用。在问答系统情况下,用于模型的输入数据根据文本和问题来定义。模型的输出包括对问题的回答以及用于验证回答的解释。通过将相关的事实的提取与系统的回答相耦合,提高系统的可靠性。系统的用户可以根据解释确认:回答是否正确,以及是否也实际上基于所提取的事实给出了回答。
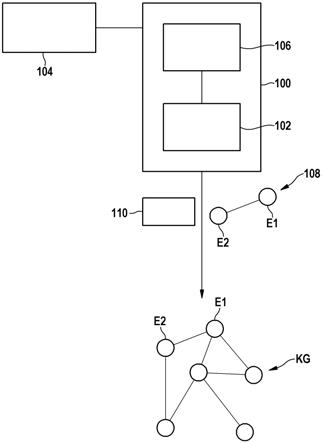
22.此外,也可设想其他应用,诸如尤其是也与文本主体结合地从知识图谱中提取相关的事实,或在图像处理的范围中从图像中提取相关的信息。
23.本公开的其他优选实施方式涉及一种用于训练模型用以在根据上述实施方式的方法中和/或在根据上述实施方式的设备中使用的方法,其中对模型进行训练,用以基于根据文本主体和知识图谱的实体定义的输入数据利用模型确定分别包括知识图谱的两个实体以及实体之间的关系的三元组,并且确定用于验证相应三元组的解释,其中用于训练模型的训练数据的标签包括关于文本主体的相关的区域的信息。因此,训练数据包括用于目标任务、即用于确定三元组的标签,以及包括用于相关的输入部分、即用于确定解释的文本主体的相关的区域的标签,以便能够在目标函数中将它们相互进行比较,其中根据所述目标函数对所述模型进行训练。
24.本发明的其他特征、应用可能性和优点从本发明的实施例的以下描述中得出,所述实施例在附图的图中示出。在此,所描述或示出的所有特征单独地或以任意组合的方式形成本发明的主题,而与其在专利权利要求中的概要或其回引无关以及与其在说明书中或在附图中的表述或表示无关。
附图说明
25.在附图中:图1示出用于创建知识图谱的设备的示意图;图2以流程图示出根据一种实施方式的用于创建知识图谱的方法的步骤的示意图;图3以框图示出根据另一实施方式的方法的步骤的示意图。
具体实施方式
26.在下面示例性地根据图1至3阐述用于创建知识图谱kg的设备100和计算机实现的方法200。
27.在图1中示意性地示出用于创建知识图谱kg的设备100。知识图谱kg可以通过形式为<实体a,实体b,实体a与实体b之间的关系>的多个三元组定义。知识图谱kg的第一实体e1和第二实体e2在图1中示意性地示出。
28.根据模型102确定知识图谱kg。模型102例如是神经模型(neuronales modell)。神经模型102例如包括多个层。
29.提供文本主体104,用于确定知识图谱kg。用于模型102的输入数据106由设备100
提供用于确定知识图谱kg。根据所示的实施方式,用于模型的输入数据根据文本主体104和知识图谱kg的实体来定义。
30.在该示例中,文本主体104是文本集或文档集。从文本主体104出发(ausgehend von
…
),由设备为各个词或语句例如作为词向量产生嵌入(embedding)。此外,由设备为实体例如作为词向量产生嵌入。
31.设备100包括一个或多个处理器和至少一个用于指令的存储器和/或用于模型102的存储器,并且被构造用于执行在下面描述的计算机实现的方法200。根据所示的实施方式,模型102被构造用于确定用于知识图谱kg的三元组,所述三元组包括第一实体e1和第二实体e2以及两个实体之间的关系。
32.参考图2,描述用于创建知识图谱kg的计算机实现的方法200的步骤。
33.在步骤202中,提供第一实体e1和第二实体e2。可以从来自已经存在的知识图谱的多个实体中选择第一和/或第二实体e1、e2。可以由用户经由输入来预先给定第一和/或第二实体。
34.在步骤204中,提供文本主体104。例如,从数据库中读取文本主体104。
35.在步骤206中,提供用于模型102的输入数据106,所述输入数据根据文本主体104、第一实体e1和第二实体e2来定义。在该示例中,通过文本主体104、尤其是文档集或文本集的嵌入并且通过第一和第二实体的嵌入来定义模型102的输入数据106。
36.例如通过词向量作为嵌入代表第一和第二实体e1、e2和文本主体104。例如,为文本主体104的每个词和/或每个语句计算与上下文有关的向量表示,所述向量表示不仅取决于文本主体104的其他语句和/或词而且取决于第一和第二实体e1、e2。
37.在步骤208中,确定三元组108,所述三元组包括实体e1、e2以及两个实体之间的关系。
38.在步骤210中,确定用于验证三元组108的解释110。为了确定210解释110,执行以下步骤。
39.为了确定208三元组108以及为了确定210解释110,执行以下步骤:对文本主体104的相关的区域进行分类208a并且丢弃208b文本主体104的不被分类为相关的区域,并且从文本主体104的相关的区域中导出208c第一实体e1与第二实体e1之间的关系。
40.文本主体104的区域例如包括一个或多个语句和/或一个或多个词。
41.例如在使用池化层的情况下丢弃208b文本主体104的不被分类为相关的区域。池化(pooling)通常用于仅在模型102内转交最相关的数据。
42.例如,在模型102的第一输出端处输出包括三元组108、即第一实体e1、第二实体e2以及第一与第二实体e1、e2之间的关系的输出。
43.例如,在模型102的第二输出端处输出包括用于验证三元组108的解释110的输出。
44.根据所示的实施方式,相应三元组108的解释110被定义为元数据,所述元数据分配给知识图谱kg的相应三元组108。在相应三元组108的解释110中,定义在文本主体104中的至少一个被分类为相关的区域的开始和结束。因此,解释110说明文本主体104的至少一个片段,所述片段验证三元组108。
45.根据所示的实施方式,该方法200此外包括用于迭代地检验相应解释110的被分类
为相关的区域的步骤212。
46.有利地,步骤212是后处理过程,利用所述后处理过程能够检验并且必要时能够减少解释110的被分类为相关的区域。在下面根据图3阐述后处理过程。
47.迭代地检验212被分类为相关的区域包括:检验212a不具有被分类为相关的相应区域的解释110是否是用于相应三元组108的解释110,并且根据检验的结果,在解释110中保留212b被分类为相关的相应区域或从解释110中丢弃212c被分类为相关的相应区域。
48.根据一种优选实施方式,只要相应解释110包括数目n个被分类为相关的区域,其中,n=1、2、3、...,并且迭代次数小于或等于被分类的区域的数目,就执行迭代式检验212。因此,当满足中止准则时,结束迭代式检验212。在所示的实施方式中,n=2。
49.在步骤214中,按照升序相关性对解释110的被分类为相关的区域进行排序(sortieren)。
50.从分类为最低相关的区域开始执行迭代式检验212。
51.根据所示的实施方式,迭代地检验212被分类为相关的相应区域包括以下步骤:检验212a不具有被分类为相关的相应区域的解释110是否是用于相应三元组108的解释110,并且根据检验212a的结果,在解释110中保留212b被分类为相关的相应区域,或者从解释110中丢弃212c被分类为相关的相应区域。
52.如果不具有被分类为相关的相应区域的解释110对于相应三元组108不再是解释110,则在解释110中保留212b被分类为相关的相应区域。在这种情况下,对于解释110而言,用于解释110的相关地分类的区域是必要的,因为在移除该区域之后,将会不再能够从解释110中提取相应的三元组108。
53.如果不具有被分类为相关的相应区域的解释110仍然是用于相应三元组108的解释110,则从解释110中丢弃212c被分类为相关的相应区域。在这种情况下,用于解释110的相关地分类的区域已是多余的,因为在从解释110中移除该区域之后,仍然将会能够从解释110中提取相应的三元组。
54.根据图3,解释110包括四个被分类为相关的区域b1、b2、b2、b3和b4。示例性地,按照升序相关性对区域进行排序,其中区域b1被分级为最少相关的(am wenigstens relevante)区域,而b4被分级为最最相关的(am meisten relevanteste)区域。
55.在用于检验相应解释110的被分类为相关的区域的步骤212的第一迭代中,检验212a不具有区域b1的解释110是否仍然是用于三元组108的解释110。在所示的实施例中,用于三元组108的解释110未被改变,也就是说,解释110在不具有区域b1的情况下仍然是用于三元组的完整解释110。从解释110中丢弃区域b1。
56.在用于检验解释110的被分类为相关的区域的步骤212的下一迭代中,检验212a不具有区域b2的解释110是否仍然是用于三元组108的解释110。在所示的实施例中,用于三元组108的解释110已经被改变,也就是说,解释110在不具有区域b2的情况下不是用于三元组108的完整解释110。区域b3被保留212b在解释110 中。
57.在用于检验解释110的被分类为相关的区域的步骤212的下一迭代中,检验212a不具有区域b3的解释110是否仍然是用于三元组108的解释110。在所示的实施例中,用于三元组108的解释110未被改变,也就是说,解释110在不具有区域b3的情况下仍然是用于三元组108的完整解释110。区域b3从解释110中被丢弃212c。
58.根据所示的实施方式,迭代式检验212现在被中止。在解释110中,仍然剩下两个区域b2和b4。迭代式检验212的迭代次数是三。在这种情况下,满足中止准则。
59.通过执行后处理过程212,三元组108的解释110已经从四个区域b1、b2、b3和b4被减少到两个区域b2和b4。
60.其他实施方式涉及一种用于训练模型102用以在根据实施方式的计算机实现的方法200中和/或在根据实施方式的设备100中使用的方法。
61.在该训练方法中,训练模型102,用以基于根据文本主体104和知识图谱kg的实体e1、e2定义的输入数据来利用模型确定分别包括知识图谱kg的两个实体e1、e2以及两个实体e1、e2之间的关系的三元组108,并且确定用于验证相应三元组108的解释110,其中用于训练模型102的训练数据的标签包括关于文本主体104的相关的区域的信息。因此,训练数据包括用于目标任务、即用于确定三元组108的标签,以及包括用于相关的输入部分、即用于确定解释110的文本主体104的相关的区域的标签,以便能够在目标函数(zielfunktion)中将它们相互进行比较(abgeglichen),其中根据所述目标函数对模型102进行训练(auf die
…ꢀ
trainiert wird)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1