机载激光雷达点云数据CHM的DBI树顶点探测方法
本发明涉及激光雷达(lightlaserdetectionandranging,lidar)数据处理领域,具体涉及机载激光雷达点云数据冠层高度模型(canopyheightmodel,chm)的dbi(davies-bouldinindex)树顶点探测方法。
技术背景
激光雷达对森林冠层具有很强穿透性,十分有利于森林普查及林分参数获取,能够做到树梢位置和单木树冠精确识别。机载激光雷达技术为精准林业的发展提供理论依据和技术支持,在森林经营管理与生态系统研究中具有广阔应用前景。
目前,由于机载lidar点云生成冠层高度模型图像的复杂性,导致了在树冠位置识别领域的树顶点识别不准确。在已有的传统方法中,研究人员频繁使用固定窗口尺寸探索局部最大值的方法探测树顶,然而,常见的基于窗口探测树顶点的方法容易受到树冠冠径尺寸大小不一的影响,如果窗口太小,会造成一些树冠半径较大的树会被分配多个树顶点;反之如果窗口大小太大,则会造成一些树冠半径小于指定窗口尺寸的树将不会被分配到树顶点。
综上所述,为了解决传统窗口探测树顶点方法的阈值依赖和识别不准确问题,有必要提出一种新的树顶点识别方法,从而解决以上问题。本发明根据冠层高度模型灰度级特点生成前景标记像素,并引入相似度判断因子-类间距之比dbi,即可以解决传统利用窗口探测高度冠层模型的树顶点的阈值依赖,又提高了树冠顶点的识别准确度。
技术实现要素:
本发明的目的是提供一种机载激光雷达点云数据冠层高度模型的树顶位置探测方法,能够有效的解决传统窗口探测树顶点方法的阈值依赖问题,提高树顶点识别准确度。
为实现本发明之目的,本文提出了一种机载激光雷达点云数据chm的dbi树梢位置探测方法,采用以下技术方案予以实现:一种基于冠层高度冠层模型的dbi控制前景像素生成树顶点方法,包括规范冠层高度模型的标记像素生成条件,利用高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除,引入相似度判断因子dbi进行dbi-k(dbi-kmeans)筛选树冠顶点;规范冠层高度模型的标记像素生成条件:(1)标记外像素点的灰度级值都比标记内部的低,(2)前景图像的像素点组成一个连通分量,(3)同一个标记内部的像素点具有相同的灰度级值;利用高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除,结合高度冠层模型图像的灰度变化特点对已经计算求出的前景标志像素做进一步的处理,根据不同图像灰度的差异,对已经出现在前景标记上的背景点进行了过滤;dbi-k(dbi-kmeans)筛选树冠顶点,对前景图像进行dbi-k聚类,当dbi取最小值时得到聚类中心的最优解,将其作为单株树木树梢,算法终止。
本发明的有益效果是:采用一种基于冠层高度冠层模型的dbi控制前景像素生成树顶点,包括规范冠层高度模型的标记像素生成条件,利用高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除,引入相似度判断因子dbi进行dbi-k(dbi-kmeans)筛选树冠顶点,既解决了传统窗口探测树顶点方法的阈值依赖问题,又提高了树顶点识别准确度;一方面,规范冠层高度模型的标记像素生成条件,利用冠层高度模型图像的局部极大值确定感兴趣区域,以此作为前景像素及标记,可以避免穿口探测的阈值依赖问题;另一方面,利用高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除,克服了因纹理与噪声导致前景标记中掺杂了伪极大值(前景标记)的问题;最后,引入相似度判断因子dbi进行dbi-k筛选树冠顶点,解决了基于冠层高度模型的树顶点不明确问题,实现了树顶点的有效识别。
直接进行基于特征的前景标记像素提取,会因纹理与噪声的存在导致前景标记中掺杂了伪极大值。
附图说明
图1是点云数据滤波分类图。
图2是点云数据生成的dem、dsm、chm图。
图3是本发明的原理图。
图4是本发明在规范条件下生成的冠层高度模型的前景图像和前景标记。
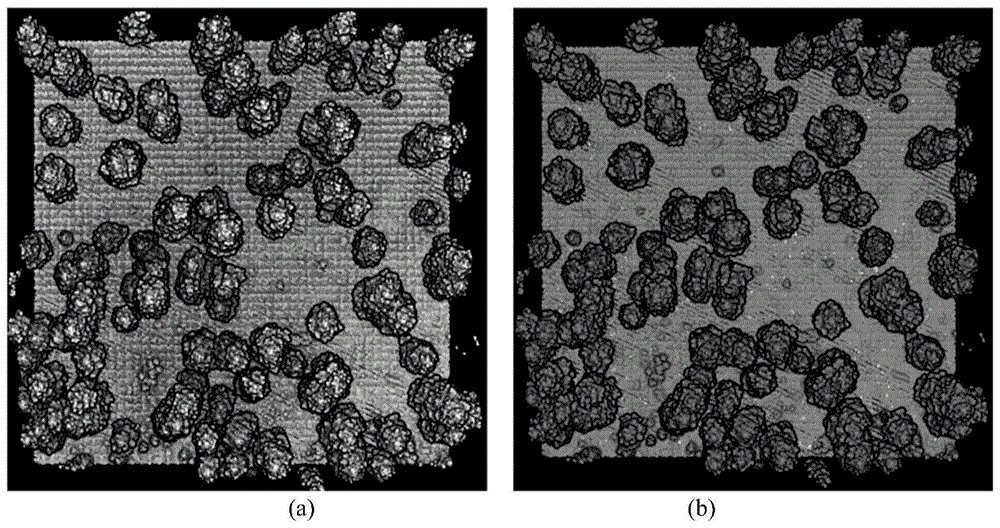
图5是本发明伪前景像素过滤剔除后前景标记图。
图6是本发明dbi-k筛选树冠顶点图。
具体实施方式
下面结合附图对本发明的具体实施方式做进一步说明。
实施例:
步骤1)结合图1,点云数据滤波分类。林区样地地形信息的保留十分重要,在此前提下,为了能够达到更好的滤波效果,本发明采用渐进三角网滤波算法,以下为分离地面点步骤:
(1)设置最大地形坡度:将点云中显示的地形最大坡度设置为80°;
(2)设置迭代角度:将待测地分类点和目前已知的地面分类点之间所有可允许值的转换角度为8°;
(3)设置迭代距离:将待分类点与三角网间的距离阈值设置为1.6m;
利用上述方法,对实验样地进行点云滤波分类,将分离出的地面点类用棕色显示,分离出的植被点类用绿色显示。
步骤2)结合图2,利用滤波分类后的点云数据生成dem、dsm、chm。对非地面激光点云和地面反射激光点云综合利用tin计算方法得出来分别生成了实验林区的dsm和dem。在lidar360中多次实验后发现临界变长设置为1m时生成的三角网较平滑,当设置插入缓冲区的值为2m时三角网结构面包含更多细节,并且设置权重为2。从dsm中减去dem即可得到冠层高度模型,如下列公式所示:
chm=dsm-dem(1)
步骤3)结合图3,一种基于冠层高度冠层模型的dbi控制前景像素生成树顶点,规范条件下冠层高度模型的标记像素生成中,输入冠层高度模型,根据三个规范条件生成冠层高度模型的前景标记像素;利用高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除中,输入冠层高度模型初始前景标记像素,根据局部最大灰度级像素原理过滤剔除掉伪前景标记像素c前;引入相似度判断因子dbi进行dbi-k筛选树冠顶点中,输入滤除伪标记的前景标记像素,并将其作为初始聚类中心,并根据聚类中心公式生成新的聚类中心,根据生成聚类中心的前后相似度判断因子dbi值比较,当dbi最小值时得到聚类中心的最优解,算法终止;输出dbi取最小值时的聚类中心,将其作为单株树木树顶点。
步骤4)结合图4,规范条件下冠层高度模型的标记像素生成。根据3个规范条件生成冠层高度模型的初始前景标记:(1)标记外像素点的灰度级值都比标记内部的低,(2)前景图像的像素点组成一个连通分量,(3)同一个标记内部的像素点具有相同的灰度级值;由于图像的局部极大值确定感兴趣区域,以此作为前景像素及标记。
步骤5)结合图5,高度冠层模型的灰度变化特点对伪前景像素进行过滤剔除。高度灰度冠层模型图像的树冠层区域较其他区域更加明亮,通过灰度图中颜色深浅可以知道冠层相对高度信息,即灰度值越大冠层越高,由此可知树梢(前景标记)为局部灰度极大值像素点;由于灰度冠层高度模型通过中心像元相邻8像素的灰度值表示。需要使r、g、b三者的值相等就可以得到灰度图像(其中,r=g=b=255为白色,r=g=b=0为黑色);当冠层高度模型前景像素的r、g、b分量值之和取最大值且r、g、b分量值相等时,标记像素值取0,其他情况下,标记像素值取1。表示为以下公式:
式中,
步骤6)结合图6,dbi-k(dbi-kmeans)筛选树冠顶点,在生成高度冠层模型的前景标记像素的基础上,利用相似度判断因子对标记像素进一步筛选;通过对输入的冠层高度模型二维灰度图像进行聚类,在k-means聚类方法中加入dbi相似度判断因子,进一步确定前景图像内部的聚类中心m和聚类中心数目k值。
假设给定的样本冠层高度模型前景图像内包含数据集a={ai};将a中n个样本数据集初始分割为k个不同聚簇,保证聚簇内相似度较高,簇外相似度较低。因此,k-means聚类方法的核心理论可以描述为:将数据集a聚类为以k个聚簇组成的集合b,b={bi};可以得到各个聚簇子集的簇内中心为:
式中,a表示样本数据对象,ni表示聚类bi中的样本数。
相似度判断因子dbi的值取最小时,输出dbi相似度判断因子,取得聚类数目k的最优解。
式中,ai表示第i个类内的各个数据对象,mi表示第i个类的聚簇中心,ni表示第i个类内的数据对象个数,wi表示第i个类内各数据对象分散程度,wj表示第j个类内各数据对象分散程度,di,j表示第i个类与第j个类的质心之间欧几里德距离。
公式(1.2)中di,j表示类间距离,表达公式如下:
di,j=||mi-mj||(5)
公式(1.2)中wi表示类内距离,表达公式如下:
如果dbinew<dbilast,则可以形成新的聚簇中心,否则算法终止。迭代结束时确定树顶点及个数k,并将迭代终止产生的聚类中心作为树梢点,聚类k值则作为目标图像的单木株数,将筛选后的聚类中心像元作为描绘每棵树冠的种子点(树梢点)位置。
式中,&&为逻辑关系‘与’,m′为新的中心集合,m1…j…为聚类中心m1至mi,m1...i为聚类中心m1至mj。当dbi取最小值时,获得最优解,此时确定树顶点的个数和位置。
以上所述仅为结合附图描述了本发明的优选实施方式,应当指出,对于本领域内的技术人员来说,可以在所附权利要求的范围内做出各种变形和修改,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!