基于密度的加权模糊C-均值聚类方法
本发明属于计算机技术应用领域,涉及一种基于密度的加权模糊c-均值聚类方法。
背景技术:
近年来,随着数据挖掘技术的迅速发展,数据挖掘技术已经在很多领域得到广泛的应用,例如经济、环境、医疗金融等领域。聚类是数据挖掘中的一种无先验条件的无监督分析方法,它是将数据集中的数据根据各自的特征分成不同的簇,各个簇之间尽可能的相异,簇内中的数据尽可能相似。聚类的方法多种多样,经典的聚类方法有基于划分的聚类方法、基于密度的聚类方法、基于网格的聚类方法、基于层次的聚类方法以及基于模型的聚类方法。
基于划分的聚类方法中最经典的方法就是模糊c-均值聚类方法,即fcm聚类方法。它是在聚类的基础上引入了模糊理论。基本思想是使得被划分到同一簇的对象之间的相似度最大,而不同簇之间的相似度最小。模糊c-均值聚类算法是普通c均值算法的改进,它是利用隶属度函数来确定某一数据对象的划分类别,然后根据聚类中心函数来确定聚类中心,最终完成聚类的目的。
随着数据的不断增加,传统的模糊c-均值聚类方法在处理数据时,导致聚类结果精度较低,聚类效果不佳。
技术实现要素:
鉴于此,本发明主要解决随着数据的多样性,导致传统模糊c-均值聚类方法的精度低的问题。本发明主要使用了基于密度的方法筛选出初始聚类中心,然后将kl-距离加入到模糊c-均值聚类方法中,构造一个新的目标函数,从而达到聚类的目的。
综上,现有的模型很难从自身上来提高对数据中异常值和噪声的鲁棒性。
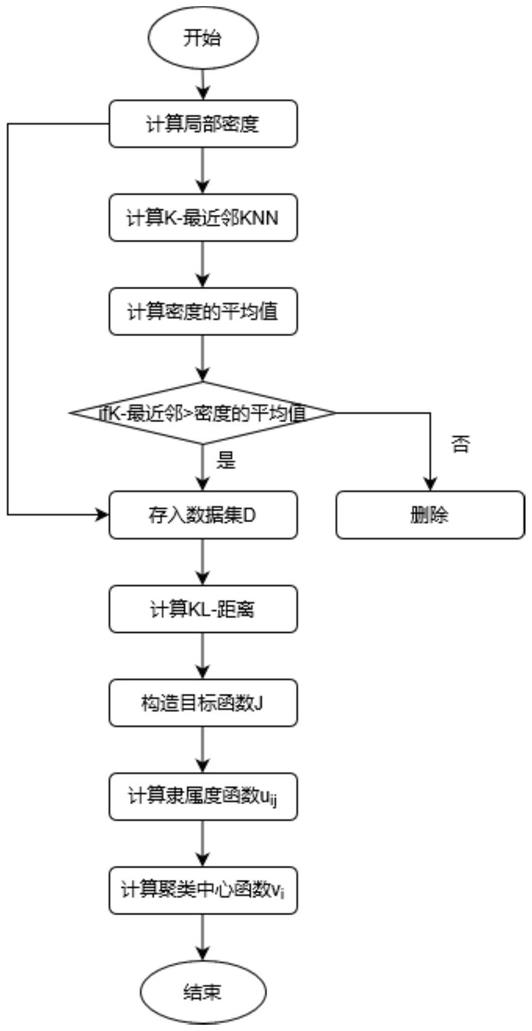
为了达到上述目的,本发明基于密度的聚类方法对传统的模糊c-均值聚类方法进行了改进,其算法步骤如下:
步骤一:定义待说明的数据集d={x1,x2,…,xn}∈rs。
步骤二:先使用基于密度的方法来计算数据集中每个数据对象xi的局部密度
步骤三:计算数据集d中的每个数据对象的k-最近邻knnk(xi)={pj∈x|index_dist(xi,xj)≤k}。
步骤四:进一步地,计算数据集d中数据对象的密度平均值
步骤五:进一步,使用快速排序的方法将局部密度按照从小到大的顺序进行排序,选取局部密度最大的点,作为初始聚类中心。
步骤六:进一步地,将k-最近邻的值与密度的平均值进行比较,如果k-最近邻的值大于密度的平均值,则保留簇中的数据;否则,将该数据对象从所属的簇中删除。
步骤七:重复第六步,直至将数据集d中的数据对象比较结束。
步骤八:计算每个簇中每个数据对象的kl-距离
步骤九:构造一个新的模糊聚类的目标函数:
步骤十:使用拉格朗日乘子法构造拉格朗日函数,并对构造的拉格朗日函数进行求导,得到隶属度函数uij,其表达式为
步骤十一:将计算得到的隶属度函数带入到构造的拉格朗日函数中,可以进一步得到聚类中心函数vi,其表达式为
步骤十二:将每个隶属度的值构造一个隶属度函数。
步骤十三:计算聚类中心,得到最终的聚类中心集,完成数据的聚类。
附图说明
图1为本发明基于密度的加权模糊c-均值聚类方法的流程图。
具体实施方式
下面将结合本发明实施的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实例仅仅是本发明一部分实施例子,而不是全部实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供了一种基于密度的加权模糊c-均值聚类方法,其基本实现过程如下:
1、输入数据预处理。
输入数据集d={x1,x2,…,xn}∈rs。
2、使用基于密度的聚类方法完成初始聚类中心的筛选。
先使用基于密度的方法来计算数据集中每个数据对象xi的局部密度
计算数据集d中的每个数据对象的k-最近邻knnk(xi)={pj∈x|index_dist(xi,xj)≤k}。
计算数据集d中数据对象的密度平均值
使用快速排序的方法将局部密度按照从小到大的顺序进行排序,选取局部密度最大的点,作为初始聚类中心。
3、比较k-最近邻与密度的平均值。
将k-最近邻的值与密度的平均值进行比较,如果k-最近邻的值大于密度的平均值,则保留簇中的数据;否则,将该数据对象从所属的簇中删除。
重复上述步骤,直至将数据集d中的数据对象比较结束。
4、判断数据集d中数据对象的相似度。
计算每个簇中每个数据对象的kl-距离
5、构造基于密度的加权的模糊c-均值聚类方法的目标函数。
构造一个新的模糊聚类的目标函数:
使用拉格朗日乘子法构造拉格朗日函数,并对构造的拉格朗日函数进行求导,得到隶属度函数uij,其表达式为
将计算得到的隶属度函数带入到构造的拉格朗日函数中,可以进一步得到聚类中心函数vi,其表达式为
6、将每个隶属度的值构造一个隶属度函数。
7、计算聚类中心,得到最终的聚类中心集,完成数据的聚类。
综上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!