基于图像和深度数据进行对象3D定位的计算机实现方法与流程
基于图像和深度数据进行对象3d定位的计算机实现方法
技术领域
1.本发明涉及图像处理、尤其涉及基于图像和深度数据进行对象的3d定位的领域。
背景技术:
2.对于要与环境互动的服务、家用和工业机器人,由计算机实现的对3d空间中的个体和对象的检测必不可少。最近的进展已基本解决了关于2d图像的单模2d对象识别问题。着重于2d检测还研究了融合多种传感器模式、例如图像和深度数据的不同策略。
3.但是,这些检测模型的一个具体问题是,如果个体/对象在三维空间中具有不可忽略的空间尺寸,则要定位由图像和深度数据表示的该个体或对象的3d对象参考点、例如3d形心。此外,使用3d地面实况注释用于3d检测的大规模真实世界训练数据集是缺乏且昂贵的,这使得检测模型应特别被配置为能够通过较小的训练数据集进行训练而表现出色的检测质量。
4.对于基于图像数据的对象识别,诸如yolo v3一级检测的高性能算法是公知的。yolo v3算法允许获取对象轮廓数据、例如表示所检测的个体/对象位于其中的2d区域的边界框。但是,由于待检测的个体/对象在深度尺寸上可能也有很大的延伸,因此,许多应用、例如在机器人应用中都需要确定对象边界内的3d对象参考点、例如个体/对象的质心或3d形心。用于2d对象检测的常规算法不提供这样的3d对象参考点。它们还没有充分利用可以使用现有传感器同时获取的附加深度数据。
技术实现要素:
5.根据本发明,提供了一种基于图像数据和深度数据使用检测模型进行个体或对象的3d定位的计算机实现的方法、一种用于训练这种检测模型的计算机实现的方法、一种根据其他的独立权利要求的系统和移动主体。
6.在从属权利要求中示出了其他实施例。
7.根据第一方面,提供了一种基于图像数据和指示由图像数据表示的图像的像素的距离信息的深度数据进行对象的3d定位的计算机实现的方法,其中,所述方法应用具有第一组连续的层、第二组连续的层和第三组连续的层的卷积神经网络,每个层均被配置为具有一个或两个以上滤波器,其中,所述卷积神经网络被训练为能够将对对象的识别/分类和针对所识别/分类的对象的相应的3d定位数据与图像数据项和深度数据项相关联,所述方法包括以下步骤:
8.‑
应用所述卷积神经网络的第一组的层从图像数据提取一个或两个以上图像数据特征;
9.‑
应用所述卷积神经网络的第二组的层从深度数据提取一个或两个以上深度数据特征;
10.‑
融合所述一个或两个以上图像数据特征和所述一个或两个以上深度数据特征,以获得至少一个融合特征图;
11.‑
通过应用所述卷积神经网络的第三组的层来对所述至少一个融合特征图进行处理,以对对象进行识别/分类,并提供针对所识别/分类的对象的3d定位数据,其中,所述3d定位数据包括对象参考点数据。
12.上述方法应用卷积神经网络来从图像数据和深度数据提取3d定位数据。图像和深度数据可以对应于像素矩阵,其中,特别是图像数据可以被设置为rgb数据。对于图像数据,像素通常指示亮度和/或颜色,深度数据指示其每个像素的距离信息。
13.卷积神经网络被配置为能够分别从图像数据和深度数据单独执行特征提取。这由许多连续的(卷积)层来完成,每个层都具有相关联的一个或两个以上滤波器,使得从提供的输入数据中单独提取图像数据特征和深度数据特征。
14.在融合阶段,将图像数据特征和深度数据特征进行组合以获得融合特征图,然后通过应用第三组连续的层对融合特征图进行进一步处理。卷积神经网络的第一、第二和第三组的层通过训练数据进行训练的,所述训练数据包括图像数据和相应的深度数据以及待识别/分类的对象的3d定位数据,其中,3d定位数据包括指示代表性的3d位置(3d像素)的对象参考点数据。即使对象被部分遮挡,对象参考点数据也适合于表示对象的相关点。
15.卷积神经网络的上述架构是灵活的,事实证明可以使用合成的图像和深度数据对其进行有效训练,以学习包括对象参考点数据的3d定位。
16.特别地,为了训练卷积神经网络,可以利用对象轮廓数据相应的调整通过放大和缩小来对基于图像和深度数据的样本图像进行裁剪和扩展。这之后可以将结果图像的尺寸调整到固定大小的矩形输入图像,以获得用于训练卷积神经网络的输入数据。但是,直接对图像和深度数据应用裁剪/扩展增强并对其进行尺寸调整会扰乱在感知环境中对对象度量比例的理解,而这对于准确进行3d定位至关重要。因此,为了生成训练数据,可设置为通过根据增强过程中裁剪或扩展的缩放程度来适配深度数据,以保留原始图像的度量比例和长宽比。
17.此外,为了进行训练,可以使用预先训练的rgb yolo v3检测器模型作为起点,该模型已使用大规模2d对象检测数据集进行了训练。对于第一和第三组的层,可以从预训练的模型中复制权重。来自第一组的层的权重也可以被转移到第二组的层,而从头开始随机初始化第二组的获取单通道深度图像的第一层。
18.此外,融合的步骤可以包括:将图像数据特征和深度数据特征进行连结,随后应用具有调整数量的滤波器的1x1卷积层,以保持通道的原始数量。
19.可这样设置,将连结的特征图的尺寸减小到所述一个或两个以上图像数据特征的尺寸。
20.此外,对象参考点数据可以包括指示对象的几何中心的3d坐标的3d形心或对象的质心。
21.可以执行通过应用卷积神经网络的第三组的层来对至少一个融合特征图进行处理的步骤,以获得指示所识别/分类的对象的轮廓的边界数据。
22.可这样设置,第一、第二和/或第三组的层包括一个或两个以上激活层和/或一个或两个以上具有跳跃连接的残差块。
23.根据另一方面,提供了一种卷积神经网络,所述卷积神经网络具有第一组连续的层、第二组连续的层和第三组连续的层,每个层均被配置为具有一个或两个以上滤波器,其
中,融合层被配置为能够融合由第一组的层获得的一个或两个以上图像数据特征和由第二组的层获得的一个或两个以上深度数据特征,其中,所述卷积神经网络被训练为能够将图像数据项和深度数据项与对对象的识别/分类和针对所识别/分类的对象的相应的3d定位数据相关联,其中,所述3d定位数据包括对象参考点数据。
24.根据另一方面,提供了一种用于训练上述卷积神经网络的方法,其中,使用训练数据来训练所述卷积神经网络,其中,每个训练数据项包括图像数据和深度数据以及3d定位数据,其中,训练数据项的至少一部分是合成生成的。
25.特别地,合成生成的训练数据使用3d图形引擎利用前景和背景随机化来渲染,其中,一个或两个以上前景对象被包括在每个训练数据项中。
26.根据一个实施例,通过以下步骤从训练数据项的图像数据项和对应的深度数据项生成另外的训练数据项:
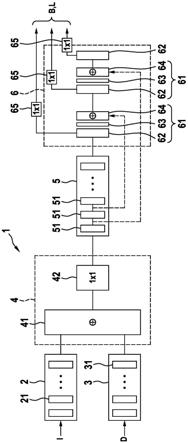
27.‑
随机裁剪或扩展来自训练数据项的图像数据,同时保持长宽比;
28.‑
通过应用基于训练数据项的图像数据的尺寸和裁剪后的图像数据的尺寸的缩放因子,将裁剪/扩展后的图像数据项尺寸调整到训练数据项的图像数据的尺寸;
29.‑
基于所述缩放因子适配深度数据项和所识别/分类的对象的相关联的3d定位数据,以获得所述另外的训练数据项。
30.根据另一方面,提供了一种基于图像数据和指示由图像数据表示的图像的像素的距离信息的深度数据进行对象/个体的3d定位的装置,其中,卷积神经网络被配置为具有第一组连续的层、第二组连续的层和第三组连续的层,每个层均被配置为具有一个或两个以上滤波器,其中,融合层被配置为能够融合由第一组的层获得的一个或两个以上图像数据特征和由第二组的层获得的一个或两个以上深度数据特征,以获得至少一个融合特征图以由所述第三组的层进一步处理,其中,所述卷积神经网络被训练为能够将对对象的识别/分类和针对所识别的对象的相应的3d定位数据与图像数据项和深度数据项相关联,其中,所述装置还被配置为能够执行以下步骤:
31.‑
应用所述卷积神经网络的第一组的层从图像数据提取一个或两个以上图像数据特征;
32.‑
应用所述卷积神经网络的第二组的层从深度数据提取一个或两个以上深度数据特征;
33.‑
融合所述一个或两个以上图像数据特征和所述一个或两个以上深度数据特征,以获得至少一个融合特征图;
34.‑
通过应用所述卷积神经网络的第三组的层来对所述至少一个融合特征图进行处理,以对对象进行识别,并提供针对所识别的对象的3d定位数据,其中,所述3d定位数据包括对象参考点数据。
附图说明
35.结合附图更详细地描述实施例,其中:
36.图1是训练为用于从图像数据项和相应的深度数据项确定3d定位数据的检测模型的卷积神经网络的架构的示意图。
具体实施方式
37.图1示意性地示出了用于处理包括诸如rgb数据的图像数据和相应的深度数据的输入数据的卷积神经网络1的架构。每个图像数据项都与一个深度数据项相关联,以使得它们都指代相同的场景。可以借助于例如相机来获取图像数据。图像数据可包括一个或两个以上像素矩阵通道、例如rgb数据的颜色通道等。
38.深度数据可以通过基于激光雷达(lidar)、雷达、超声波传感器或其他传感器的适当深度传感器来获得,这些传感器能够捕获像素矩阵,其中,每个像素与距离值相关联。
39.网络架构可类似于yolo v3网络,该yolo v3网络被修改为还考虑深度数据并估算3d定位数据。
40.大体上,卷积神经网络1包括第一组2连续的层21。第一组2的层21可以包括连续的卷积层、激活层和标准化层以及残差块,其相应的配置是公知的。第一组2的连续的卷积层的数量可以在4至60之间、优选地在5至30之间。图像数据项i被馈送到第一组的层21的输入中。第一组2的层21用作图像数据项i的特征提取器,以获取一个或两个以上图像数据特征。
41.此外,设置有第二组3连续的层31。第二组3的层31可以包括连续的卷积层、激活层和对应的标准化层以及残差块,其配置是公知的。第二组3的连续的卷积层31的数量可以在5至30之间。深度数据项d被馈送到第二组3的层31的输入中。第二组3的层31用作深度数据项d的特征提取器,以获取一个或两个以上深度数据特征。
42.图像数据特征和深度数据特征借助于融合层4而融合。特别地,应用连结层41以沿着通道维度连结特征图。使用1x1卷积层42,通过将通道数减半到原始通道尺寸来减少连结特征图的增加大小。
43.融合层4的输出在第三组5连续的层51中被进一步处理。第三组5的层51可以包括连续的卷积层、激活层和相关的标准化层以及残差块,其配置是公知的。第三组5的连续的卷积层的数量可以在5至30之间。第三组5的层51用作组合的图像和深度数据特征的特征提取器。
44.第三组5的层51的输出被馈送到输出块6。
45.输出块6的层可以被包括在连续的卷积层62的块的一个或两个以上级61中,每个级61特别地包括用于相应卷积层的激活层和/或关联的标准化层,随后是上采样层63和连结层64,连结层64将上采样层63的结果与第三组的层51的残差块的输出连结起来。残差块的配置在本领域中是公知的。输出块6中每个块的连续的卷积层62的数量可以在5至30之间。每个块的卷积层62的输出被输入到1x1输出层65。
46.输出块6的一个或两个以上连结层64可以使用跳跃连接(skip connection)来组合来自第三组5的层51的特征图。此外,可以设置上采样层63,特别地,可以将上采样层63直接设置在连结层64之前。
47.上采样层63在宽度和高度尺寸上增加了特征图的大小,因此是对于特征提取器中减少特征图大小的原始卷积的相配部。上采样可经由反卷积实现。整个构造(先降低分辨率,然后再提高分辨率)类似于“功能金字塔”。
48.像原始的yolo v3中一样,上采样层允许获得三种不同比例的预测。上采样层63的功能是公知的yolo v3架构的一部分。
49.来自输出块6的一个或两个以上层61的特征图被分接并提供到提供表示边界数据
和3d定位数据的输出的1x1卷积层。1x1输出层65被配置为能够计算回归目标tcu、tcv、tcz和用于2d边界框的现有目标。这可以完全从数据来学习。在以下等式中,描述了如何使用1x1层的输出(tcu、tcv、tcz是其中的一部分)来计算cu、cv、cz,然后计算cx、cy、cz。在网络前传完成后,这会在后处理步骤中发生。
50.边界数据b可以对应于表示所提供的图像和深度数据中已经识别出对象的区域的边界框数据。对于每个所识别/分类的对象,已经确定了表示对象参考点l的3d定位数据。对象参考点表示由边界数据(边界框)限定的区域内的重要位置。因此,对象参考点可以表示3d形心、质心、几何中心、人体关节等。
51.为了估算对象参考点的度量3d坐标c
x
、c
y
、c
z
,可以从像素坐标c
u
、c
v
推断出c
x
和c
y
坐标。像素坐标c
u
、c
v
相对于具有左上角b
u
、b
v
以及宽度和高度b
w
、b
h
的预测2d边界框来表示。使用s形函数来使得对象参考点位于2d边界框内。回归目标tc
u
、tc
v
是此s型函数的变量,而不是直接回归c
u
、c
v
。相反,c
z
经由回归目标tc
z
以度量比例直接回归:
[0052][0053][0054][0055]
在计算了c
u
、c
v
和c
z
之后,可以通过使用c
z
和给定的相机矩阵k反映射c
u
和c
v
来获得c
x
和c
y
坐标。在计算机视觉中,相机矩阵或(相机)投影矩阵是描述针孔相机从现实世界3d点到图像中2d点的映射的矩阵。这在计算机视觉中是公知的概念,通常是通过对相机进行校准而获得的。
[0056]
输出参数结构基本上可以对应于标准yolo v3配置,其中输出级的最终1x1卷积被扩展以预测每个边界框的回归目标tc
u
、tc
v
、tc
z
。训练基于在训练过程中被最小化的损失(即,向后传递以计算梯度所需的)。例如,tc
z
可以使用11损失,tc
u
和tc
v
可以使用s型二进制交叉熵损失。
[0057]
为了训练卷积神经网络1,可以应用基本上随机的梯度下降,其可选地具有不同的学习率。基本上,训练是通过训练数据集进行的,所述数据集包括图像数据、深度数据以及由边界数据、例如边界框和由3d定位数据、例如对象参考点来表示的关联对象。
[0058]
训练数据集可以从真实环境设置中获得,或者可以合成生成、例如基于cad模型或摄影测量3d扫描合成生成。为了获得足够多样化的训练数据集,可以通过例如更改对象姿态、对象数和照明条件来执行域随机化。特别地,可以使用半真实感计算机图形引擎来生成合成图像和深度数据项,来至少部分地渲染训练数据集。一些传感器效果、例如噪声模式可被模拟在rgb和/或深度数据中。关联对象的边界数据和3d定位数据可以直接从cad模型中获得。
[0059]
训练过程可能涉及2d数据增强步骤,该步骤包括利用边界数据(边界框)的相应调整来进行随机选择的图像部分的裁剪和扩展,以使得可以放大和缩小包含对象的图像部分。然后获得的图像部分被尺寸调整到固定的像素矩阵尺寸,以对用于卷积神经网络1的图像和深度数据尺寸进行标准化。直接应用这种现有的裁剪和扩展的增强的形式以及到训练数据的像素矩阵尺寸的尺寸调整可能扭曲在感知环境中对对象矩阵比例的“理解”,所以这种增强被加强到成为深度感知,以使得关联对象的边界数据和3d定位数据适用于当前缩放
因子。
[0060]
缩放因子基于用于到训练卷积神经网络所需的像素矩阵尺寸的尺寸调整的因子。对于d
n
xd
n
像素的正方形的输入分辨率,选择大小为d
c
x d
c
的随机正方形裁剪。在具有已知相机矩阵k的单个图像传感器的假设下,可应用缩放因了将裁剪尺寸调整到输入尺寸d
n
xd
n
。由于缩放通常归因于焦距的变化并使固有参数保持不变,因此将比例缩放施加于深度值,使得
[0061][0062]
其中,x、y、z是在图像传感器帧中解析的3d点,是输入图像像素(u,v)处的新的比例缩放后的深度。
[0063]
除了进行深度比例缩放以用于生成具有图像数据项和相应深度数据项的训练数据集外,还对关联对象的3d定位数据进行比例缩放。
[0064]
此外,可以应用转移学习策略,该转移学习策略可以受益于现有的大规模2d对象检测数据集。从而,第一组和第三组的层21、51可以借助于以现有的2d对象检测数据集预训练的现有的yolo v3 rgb检测器权重来初始化。这意味着可以最初为第一组2的层21和第三组5的层来设置权重,而对于第二组3的层31,则复制第一组2的层21的权重。然而,可以从头开始初始化第二组3的层31中的第一层。
[0065]
在训练开始时,对融合层4进行初始化,以便将第一组2的层21的输出处的图像数据特征不变地转发到第三组5的层51的输入。输出块的新添加的神经元的权重被随机初始化,而原始2d检测权重保持不变。
[0066]
借助于这种初始化策略,不管网络架构如何发生变化,仍可以保持预先训练的2d性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1