机器学习模型的校验方法和装置与流程
1.本公开涉及计算机技术领域,特别涉及一种机器学习模型的校验方法、机器学习模型的校验装置、终端的算力测试方法、终端的算力测试装置和非易失性计算机可读存储介质。
背景技术:
2.ai(artificial intelligence,人工智能)应用在移动端上的落地,主要受制的因素有两种:一是应用中所用的机器学习模型,尤其是深度学习模型的参数量大,对于移动端本身来说是一种负担;二是移动端的计算能力相对较弱,无法适应计算复杂度高的机器学习模型。
3.为了使移动端能更好地承载ai应用,可以通过压缩机器学习模型来实现加速处理,以保证机器学习模型在端侧的运行效率。
4.但是,压缩处理可能造成不正当加速,从而导致压缩后的机器学习模型性能下降。因此,需要对压缩后的机器学习模型与原机器学习模型的相似程度进行校验,以检测不正当加速。
5.在相关技术中,可以依据压缩后的机器学习模型的输出及其相应的标签计算准确率,根据准确率对压缩后的机器学习模型进行校验。
技术实现要素:
6.本公开的发明人发现上述相关技术中存在如下问题:无法敏锐地检测到一些因不正当加速造成的模型变化导致的输出变化,从而导致校验效果差。
7.鉴于此,本公开提出了一种机器学习模型的校验技术方案,能够提高校验效果。
8.根据本公开的一些实施例,提供了一种机器学习模型的校验方法,包括:利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量,利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量,被测机器学习模型通过对原始机器学习模型进行压缩处理得到;针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量之间的差异;根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
9.在一些实施例中,根据差异,校验被测机器学习模型与原始机器学习模型的相似程度包括:根据任一参考张量与相同编号的测试张量之间的差异,是否小于该参考张量与其他编号的测试张量之间的差异,和/或任一测试张量与相同编号的参考张量之间的差异,是否小于该测试张量与其他编号的参考张量之间的差异,校验相似程度。
10.在一些实施例中,校验方法还包括:为每一个测试集数据设置编号,具有对应关系的测试集数据、参考张量和测试张量具有相同的编号;根据差异,校验被测机器学习模型与原始机器学习模型的相似程度包括:根据各差异,构建差异矩阵,差异矩阵的各行编号为各参考张量的编号、各列编号为各测试张量的编号,每个元素为其行编号对应的参考张量与
其列编号对应的测试张量的差异;根据差异矩阵的对角线元素,校验相似程度。
11.在一些实施例中,根据差异矩阵的对角线元素,校验相似程度包括:根据差异矩阵中各对角线元素,是否为其所在行和/或所在列的极值元素,校验相似程度。
12.在一些实施例中,根据差异矩阵中各对角线元素,是否为其所在行和/或所在列的极值元素,确定相似程度包括:计算差异矩阵的各对角线元素为极值元素的数量;根据该数量在所有对角线元素的数量中的占比与第一阈值的比较结果,校验相似程度。
13.在一些实施例中,根据差异矩阵的对角线元素,校验相似程度包括:将差异矩阵输入分类器模型,将差异矩阵中的各元素分类为相应的参考张量与测试张量的相似元素或非相似元素;在对角元素被分类为相似元素的情况下,标注为正例;在非对角元素被分类为相似元素的情况下,标注为反例;根据正例和反例的标注结果,校验相似程度。
14.在一些实施例中,根据正例和反例的标注结果,校验相似程度包括:根据标注结果,确定机器学习模型的准确率或召回率中的至少一项;根据准确率或召回率中的至少一项,校验相似程度。
15.在一些实施例中,根据准确率或召回率中的至少一项,校验相似程度包括:根据准确率与召回率的乘积、准确率与召回率的加和,确定校验参数,校验参数与乘积正相关,与加和负相关;根据校验参数与第二阈值的比较结果,校验相似程度。
16.在一些实施例中,压缩处理包括模型量化处理、模型裁剪处理、迁移学习处理中的至少一项。
17.在一些实施例中,校验方法还包括:将被测机器学习模型部署在终端上,对终端进行算力测试。
18.根据本公开的另一些实施例,提供一种终端的算力测试方法,包括:将被测机器学习模型部署在终端上,对终端进行算力测试,被测机器学习模型通过对原始机器学习模型进行压缩处理得到,被测机器学习模型通过如下方式进行相似程度校验:利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量,利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量,被测机器学习模型通过对原始机器学习模型进行压缩处理得到;针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量之间的差异;根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
19.根据本公开的又一些实施例,提供一种机器学习模型的校验装置,包括:处理单元,用于利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量,利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量,被测机器学习模型通过对原始机器学习模型进行压缩处理得到;计算单元,用于针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量之间的差异;校验单元,用于根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
20.根据本公开的再一些实施例,提供一种终端的算力测试装置,包括:测试单元,用于将被测机器学习模型部署在终端上,对终端进行算力测试,被测机器学习模型通过对原始机器学习模型进行压缩处理得到,被测机器学习模型通过如下方式进行相似程度校验:利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量,利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量,被测机器学习模型通过对原始机器学习模型进行压缩处理得到;针对每一个测试集数据,计算其对应的参考
张量与其对应的测试张量之间的差异;根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
21.根据本公开的再一些实施例,提供一种机器学习模型的校验装置,包括:存储器;和耦接至存储器的处理器,处理器被配置为基于存储在存储器装置中的指令,执行上述任一个实施例中的机器学习模型的校验方法。
22.根据本公开的再一些实施例,提供一种终端的算力测试装置,包括:存储器;和耦接至存储器的处理器,处理器被配置为基于存储在存储器装置中的指令,执行上述任一个实施例中的终端的算力测试方法。
23.根据本公开的再一些实施例,提供一种非易失性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述任一个实施例中的机器学习模型的校验方法或者终端的算力测试方法。
24.在上述实施例中,根据压缩前后的机器学习模型对同一测试集数据的处理差异,对压缩后的机器学习模型进行相似程度校验。这样,能够敏锐地检测出压缩处理对机器学习模型的改变造成的输出变化,从而提高校验效果。
附图说明
25.构成说明书的一部分的附图描述了本公开的实施例,并且连同说明书一起用于解释本公开的原理。
26.参照附图,根据下面的详细描述,可以更加清楚地理解本公开:
27.图1示出本公开的机器学习模型的校验方法的一些实施例的流程图;
28.图2示出本公开的差异矩阵的一些实施例的示意图;
29.图3示出本公开的机器学习模型的校验方法的一些实施例的示意图;
30.图4示出本公开的机器学习模型的校验装置的一些实施例的示意图;
31.图5示出本公开的机器学习模型的校验装置或终端的算力测试装置的一些实施例的框图;
32.图6示出本公开的机器学习模型的校验装置或终端的算力测试装置的另一些实施例的框图。
具体实施方式
33.现在将参照附图来详细描述本公开的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
34.同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
35.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。
36.对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,技术、方法和设备应当被视为授权说明书的一部分。
37.在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不
是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
38.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
39.如前所述,为了使移动端能更好地承载ai应用,可以通过压缩被测机器学习模型来实现加速处理模型。在端侧深度学习能力测试中,可以采用深度学习模型的输出准确率来校验输出。
40.然而,计算准确率实质上是取分类模型所输出的标签预测概率张量中概率最高的那一维索引所对应的标签与原标签作对比,并没有分析输出张量内的数据分布。因此以准确率作为校验指标,会存在一些异常输出值或输出分布变化被掩盖的风险。
41.在一些实施例中,压缩处理可以包括量化处理、裁剪处理、迁移学习等。
42.例如,可以对已训练好的机器学习模型的参数和/或激活值进行量化处理,以较少的比特数(如格式可以为fp16、int8等)表示机器学习模型的权重或流经模型的张量数据。
43.量化处理可以应用于移动端所支持的机器学习框架中,在对机器学习模型进行量化处理时,将机器学习模型转换成该框架所支持的模型格式。
44.例如,可以通过裁剪处理,剔除机器学模型中不必要的参数,然后以再训练的方式恢复机器学习模型的性能。
45.例如,可以通过迁移学习,将复杂机器学习模型中的有用信息迁移到较简单的机器学习模型中。
46.在一些实施例中,为了对移动端承载深度学习模型的能力进行算力测试,需要设置相应的深度学习能力评测模型。
47.例如,可以通过被测端所支持的机器学习框架,将原数据格式为fp64或fp32的深度学习模型,量化为端侧平台所支持的模型格式(如包括数据格式及模型文件格式等)。可以针对不同的测试场景、测试任务(如图片分类、目标检测、ai算力等)设置不同的评测模型,以测试其相对应的深度学习能力。
48.在一些实施例中,在ai算力测试中,为了尽可能测试出移动端整体所能达到的最高算力,可以采用vgg16_notop模型、vgg19_notop模型等作为评测模型。
49.例如,vgg16_notop为裁剪掉vgg16(visual geometry group,视觉几何组织)图片分类模型中所有fc(fully connected,全连接)层和softmax层后的模型。
50.vgg16_notop为全卷积模型,负责输入的特征提取,所裁剪部分为特征融合和分类结构。因此,相应的测试任务为imagenet图片特征提取,评测模型vgg16_notop将输入图片抽象成维度为(7,7,512)的特征张量。
51.为使评测模型更贴合端侧的计算能力,需要先对评测模型(即原机器学习模型)进行压缩处理得到被测机器学习模型。因此,在选定评测模型之后,在将其加载到端侧之前,可以使用芯片厂商所提供的模型转换工具,对评测模型进行模型压缩及格式转换。
52.在一些实施例中,虽然vgg16_notop模型作为评测模型能较好的表达被测端的算力,但是vgg16_notop模型的输出为分类结果,这为校验压缩前后模型的相似程度带来了一定的困难。若采用vgg16图片分类模型,可依据模型输出的标签来计算分类准确率,从而检测移动端模型在做模型推断时的诚实度,即端侧软硬件是否做了不正当加速。
53.例如,不正当加速可以包括:端侧减少了需要处理的输入数据量,即机器学习模型
没有对测试集内的每条测试集数据进行处理。
54.这样,在实际评测过程中,通过直接复制测试集内被处理的测试集数据的输出结果,得到的未被处理的测试集数据的输出结果。这也难怪,会导致未处理的测试集数据的输出结果异常。
55.例如,不正当加速可以包括:硬件加速省略了过多原机器学习模型中有效的乘、加操作,或者过度修改了原机器学习模型内的参数了得到被测机器学习模型。
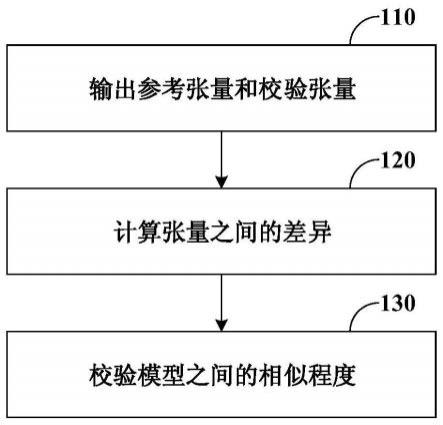
56.这样,会导致被测机器学习模型的输出结果变形,数据处理质量,即模型性能,不能得到保证。若被测机器学习模型(量化模型)的输出结果与原器学习模型的输出结果的差异过大,则表明被测机器学习模型的处理对输出数据的分布有大幅度变动,即反映被测机器学习模型处理过程中的被改动程度较大。
57.在一些实施例中,可以通过在vgg16_notop模型后连接相应的特征融合结构、分类结构等来得到图片标签,以来实现对压缩前后的vgg16_notop模型的相似程度校验。但该方法只适用于分类模型,通用性不强。
58.在一些实施例中,在算力测试任务中,如果模型结构设计合理,可以采用参数随机化的评测模型体现移动端所拥有的ai算力。但是,这种评测模型不具有物理意义,其输出也将不具任何物理意义,在这样的场景中准确率这一验证指标是失效的。
59.而且,仅通过机器学习模型输出结果的准确率进行相似程度评测,无法敏锐地检测到一些因不正当加速所导致的输出变化。这是因为得到准确率的过程,实质上是取分类模型输出的标签预测概率张量中,概率最高的一维索引所对应的标签,与原标签作对比,并没有对输出张量内的数据分布作分析比对。若仅以准确率为校验指标,则会存在一些异常输出值或输出分布变化被掩盖的风险。
60.针对上述技术问题,由于量化操作对模型输出值及其分布的影响不大,本公开以同一测试集为基础,比较原机器学习模型的输出张量与被测机器学习模型的输出张量之间的相似性或差异性来进行相似程度校验。
61.本公开的技术方案不仅可以应用到算力测试这一场景。对于其场景也可采用本公开的类似方案,校验机器学习模型在激活值/参数变动、结构调整、格式转换等处理前后的被改动程度。
62.例如,对于图片分类模型,可提取其softmax层输出的概率张量作为比较对象;对于目标检测模型,可提取其特征提取结构的终点输出的特征张量作为比较对象。
63.例如,可以通过如下的实施例实现本公开的技术方案。
64.图1示出本公开的机器学习模型的校验方法的一些实施例的流程图。
65.如图1所示,在步骤110中,利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量;利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量。
66.在一些实施例中,为每一个测试集数据设置编号,具有对应关系的测试集数据、参考张量和测试张量具有相同的编号。例如,可以将测试集内的测试集数据进行编号,如1,2,..,n,形成有序的测试集数据。每条测试集数据可以均不相同。
67.在一些实施例中,可以基于有序的测试集数据,在可信设备(如个人计算机端)上运行原深度学习模型,得到有序的参考张量集。输出的各参考张量与其对应的输入的测试
集数据的编号相同。
68.在一些实施例中,可以基于有序的测试集,在被测终端上运行被测深度学习模型,得到有序的测试张量集。输出的各测试张量与其对应的输入的测试集数据的编号相同。例如,编号可以是序号,输出的各测试张量以其输出顺序进行编号。
69.在一些实施例中,被测机器学习模型通过对原始机器学习模型进行压缩处理得到。例如,压缩处理包括模型量化处理、模型裁剪处理、迁移学习处理中的至少一项。
70.在步骤120中,针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量之间的差异。
71.在步骤130中,根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
72.在一些实施例中,根据任一参考张量与相同编号的测试张量之间的差异,是否小于该参考张量与其他编号的测试张量之间的差异校验相似程度。或者根据任一测试张量与相同编号的参考张量之间的差异,是否小于该测试张量与其他编号的参考张量之间的差异校验相似程度。
73.在一些实施例中,根据任一参考张量与相同编号的测试张量之间的差异,是否小于该参考张量与其他编号的测试张量之间的差异,以及任一测试张量与相同编号的参考张量之间的差异,是否小于该测试张量与其他编号的参考张量之间的差异校验相似程度。
74.在一些实施例中,根据各差异,构建差异矩阵;根据差异矩阵的对角线元素,校验相似程度。差异矩阵的各行编号为各参考张量的编号、各列编号为各测试张量的编号;差异矩阵的每个元素为其行编号对应的参考张量与其列编号对应的测试张量的差异。
75.例如,可以通过图2中的实施例构建差异矩阵。
76.图2示出本公开的差异矩阵的一些实施例的示意图。
77.如图2所示,计算每个测试张量qi(1≤i≤n)与每个参考张量fj(1≤j≤n)的差异。所得差异值组成大小为n
×
n的差异矩阵。差异值计算函数diff(fj,qi)着重于张量之间在数值上的差异。
78.例如,可以采用l2-norm(欧式距离)或针对二维输出张量的ssim(structural similarity,结构相似性)等计算差异。
79.相同编号的两个输出张量的差异值排列在差异矩阵的对角线位置,即对角线元素。在参考机器学习模型与被测机器学习模型间的参数和结构(在运行模型时可以指运算操作)较接近的情况下,相同编号的参考张量和测试张量的差异值应该更小。
80.在这种情况下,这些更小的差异值作为差异矩阵中每行、每列的极相似点(即极值元素)应该排列在对角线上。
81.在第一实施例中,参考机器学习模型为vgg16_notop,经量化处理所得的被测机器学习模型在移动端上运行。所得的各测试张量与各参考张量的差异组成差异矩阵。
82.例如,在以欧氏距离或ssim构建差异矩阵的情况下,对角线点的数量和极相似点的数量都为1000。
83.参考机器学习模型与被测机器学习模型之间的参数和结构越接近,则差异矩阵中行、列的极值,即极相似点,为对角线点的数量就越多。该特征可以称为对角线特征。
84.在第二实施例中,在参数固定的情况下,裁掉vgg16_notop中的最后一层卷积层,
得到参考机器学习模型,被测机器学习模型及其运行环境不变。
85.在这种情况下,参考机器学习模型与被测机器学习模型之间的结构变化较大,得到的差异矩阵中行、列的极相似点为对角线点的数量很少,即对角线特征消失。
86.在第三实施例中,,当参考机器学习模型与被测机器学习模型的参数和结构不同,但都是基于同一训练集训练所得时,差异矩阵的对角线特征仍存在。但是,在这种情况下,差异矩阵中行、列的极相似点为对角线点的数量相对于第一实施例更少。
87.在一些实施例中,vgg19_notop模型相比vgg16_notop模型在模型结构上多了三个卷积层。当两者都为imagenet图集训练所得时,两个模型对同一图片所提取的特征具有一定的相似性。
88.当参考机器模型为vgg19_notop模型,被测机器学习模型为vgg16_notop模型经量化后所得的模型时,在以欧氏距离构建差异矩阵的情况下,对角线点的数量为989,极相似点的数量为1000;在以ssim构建差异矩阵的情况下,对角线点的数量为811,极相似点的数量为1000。
89.在一些实施例中,根据差异矩阵中各对角线元素,是否为其所在行的极值元素或者其所在列的极值元素中的至少一个,校验相似程度。例如,在差异矩阵中的元素为张量之间的差异性指标(如欧氏距离等)时,极值元素为一行或一列中的最小值;在差异矩阵中的元素为张量之间的相似性指标(如结构相似性等)时,极值元素为一行或一列中的最大值。
90.例如,计算差异矩阵的各对角线元素为极值元素的数量;根据该数量在所有对角线元素的数量中的占比与第一阈值的比较结果,校验相似程度。
91.在一些实施例中,差异矩阵中每行极相似点是否处于对角线位置的判断方法如下。
92.若diff(fj,qi)为差异性度量函数,如l2-norm等,需满足对角点是其所在行j的极小值,即:
[0093][0094]
若diff(fj,qi)为相似性度量函数,如ssim等,需满足对角点是其所在行j的极大值,即:
[0095][0096]
当差异矩阵内对角线点是其所在行、列的极相似点的数量在对角线点总数中的占比小于第一阈值α时,判断被测机器学习模型本身被篡改,或在其被测运行环境中被篡改,校验不通过,不需要进行后续步骤。例如,α∈[0,1],数值根据实际应用场景确定。
[0097]
在一些实施例中,将差异矩阵输入分类器模型,将差异矩阵中的各元素分类为相应的参考张量与测试张量的相似元素或非相似元素;在对角元素被分类为相似元素的情况下,标注为正例;在非对角元素被分类为相似元素的情况下,标注为反例;根据正例和反例的标注结果,校验相似程度。
[0098]
例如,分类器模型可以为svm(support vector machine,支持向量机)模型、逻辑回归模型等,也可以为利用较小型训练集训练的roc(receiver operating characteristic,受试者工作特征)曲线模型。roc曲线模型可以用于确定用于分类的最佳
临界阈值。
[0099]
例如,相似元素为相应的参考张量与所有测试张量的极值元素,或者为相应的测试张量与所有参考张量的极值元素中的至少一个。
[0100]
在一些实施例中,可以利用二分类器区分差异矩阵中各像素是否为强相似点(即相似元素)。例如,强相似点可以为差异值小于预设阈值的极值元素。
[0101]
例如,通过多个可信测试模型以及可信测试环境,得到强相似点的二分类器所需要的训练数据。训练数据可以为差异矩阵中所有值,对角线上的点为强相似点则标记为正例,其余点为强相似点则标记为反例。二分类器可以为svm模型等。
[0102]
在一些实施例中,根据标注结果,确定机器学习模型的准确率或召回率中的至少一项;根据准确率或召回率中的至少一项,校验相似程度。
[0103]
例如,根据准确率与召回率的乘积、准确率与召回率的加和,确定校验参数;根据校验参数与第二阈值的比较结果,校验相似程度。校验参数与乘积正相关,与加和负相关。
[0104]
在一些实施例中,可以计算强相似点分类任务中的调和平均值作为校验参数。
[0105]
例如,计算被二分类器确定为强相似点的差异矩阵元素中为对角线元素在所有元素中的占比,以得到准确率p;计算被二分类器确定为强相似点的对角线元素在所有对角线元素中的占比,以得到召回率r;将二者的调和平均值f1∈[0,1]作为校验参数:
[0106][0107]
f1越高则被测机器学习模型与被测环境的可信度越高,原机器学习模型被改动的程度越小。若得到的f1小于第二阈值μ∈(0,1),则校验不通过。例如,第二阈值可以根据p-r曲线确定。
[0108]
通过二分类器判断拥有相同编号的两个输出张量qi和fi是否显著相似,是对张量间值与分布差异的更加细化的描述。这样,更能体现所比较的两个机器学习模型在处理相同输入数据时的差异。
[0109]
在一些实施例中,根据欧氏距离差异矩阵,对某品牌手机ai进行算力评测。
[0110]
例如,在上述第一实施例的情况下,准确率为99.40%、召回率为99.40%、f1为0.994。第二阈值可以为0.958334。
[0111]
例如,在上述第三实施例的情况下,准确率为94.66%、召回率为17.72%、f1为0.299。
[0112]
在一些实施例中,将被测机器学习模型部署在终端上,对终端进行算力测试。例如,可以将通过了上述校验的被测机器学习模型部署在终端上。还可以利用部署在终端上的被测机器学习模型处理图像数据、语音数据、文本数据等。
[0113]
在上述实施例中,采用的校验方法更具通用性,适用于各种深度学习模型结构,且不以模型的实际功能和输出所带有的物理意义为限制。即使采用参数随机化的模型,仍可用该方法进行输出校验,因此可适应更多的场景。
[0114]
而且,能更加敏锐地反映出由于模型参数、激活值、结构或是格式变化所导致的输出差异。
[0115]
在上述实施例中,为了反映模型间的差异,利用相似模型输出间差异矩阵所拥有的对角线特征,将校验转换为矩阵内极相似点分布问题和强相似点二分类问题。而且,以分
类结果的f1作为模型差异的表征,能够从准确率、召回率等多个角度进行校验,提高了校验的准确性。
[0116]
图3示出本公开的机器学习模型的校验方法的一些实施例的示意图。
[0117]
如图3所示,首先要构建测试集数据。例如,可以为每一个测试集数据设置编号,具有对应关系的测试集数据、参考张量和测试张量具有相同的编号。例如,可以将测试集内的测试集数据进行编号,如1,2,..,n,形成有序的测试集数据。每条测试集数据可以均不相同。
[0118]
然后,对参考机器学习模型进行量化处理,得到被测机器学习模型;可以利用参考机器学习模型和被测机器学习模型处理测试集数据。
[0119]
可以基于有序的测试集数据,在可信设备(如个人计算机端)上运行原深度学习模型,得到有序的参考张量集。输出的各参考张量与其对应的输入的测试集数据的编号相同。
[0120]
可以基于有序的测试集,在被测终端上运行被测深度学习模型,得到有序的测试张量集。输出的各测试张量与其对应的输入的测试集数据的编号相同。例如,编号可以是序号,输出的各测试张量以其输出顺序进行编号。
[0121]
计算每个测试张量qi(1≤i≤n)与每个参考张量fj(1≤j≤n)的差异。所得差异值组成大小为n
×
n的差异矩阵。差异值计算函数diff(fj,qi)着重于张量之间在数值上的差异。例如,可以采用l2-norm或针对二维输出张量的ssim等计算差异。
[0122]
相同编号的两个输出张量的差异值排列在差异矩阵的对角线位置,即对角线元素。在参考机器学习模型与被测机器学习模型间的参数和结构(在运行模型时可以指运算操作)较接近的情况下,相同编号的参考张量和测试张量的差异值应该更小。
[0123]
在这种情况下,这些更小的差异值作为差异矩阵中每行、每列的极相似点(即极值元素)应该排列在对角线上。因此,可以判断
[0124]
在第一实施例中,参考机器学习模型为vgg16_notop,经量化处理所得的被测机器学习模型在移动端上运行。所得的各测试张量与各参考张量的差异组成差异矩阵。
[0125]
例如,在以欧氏距离或ssim构建差异矩阵的情况下,对角线点的数量和极相似点的数量都为1000。
[0126]
参考机器学习模型与被测机器学习模型之间的参数和结构越接近,则差异矩阵中行、列的极值,即极相似点,为对角线点的数量就越多。该特征可以称为对角线特征。
[0127]
在第二实施例中,在参数固定的情况下,裁掉vgg16_notop中的最后一层卷积层,得到参考机器学习模型,被测机器学习模型及其运行环境不变。
[0128]
在这种情况下,参考机器学习模型与被测机器学习模型之间的结构变化较大,得到的差异矩阵中行、列的极相似点为对角线点的数量很少,即对角线特征消失。
[0129]
在第三实施例中,当参考机器学习模型与被测机器学习模型的参数和结构不同,但都是基于同一训练集训练所得时,差异矩阵的对角线特征仍存在。但是,在这种情况下,差异矩阵中行、列的极相似点为对角线点的数量相对于第一实施例更少。
[0130]
在一些实施例中,vgg19_notop模型相比vgg16_notop模型在模型结构上多了三个卷积层。当两者都为imagenet图集训练所得时,两个模型对同一图片所提取的特征具有一定的相似性。
[0131]
当参考机器模型为vgg19_notop模型,被测机器学习模型为vgg16_notop模型经量
化后所得的模型时,在以欧氏距离构建差异矩阵的情况下,对角线点的数量为989,极相似点的数量为1000;在以ssim构建差异矩阵的情况下,对角线点的数量为811,极相似点的数量为1000。
[0132]
例如,计算差异矩阵的各对角线元素为极值元素的数量;根据该数量在所有对角线元素的数量中的占比与第一阈值的比较结果,校验相似程度。
[0133]
在一些实施例中,差异矩阵中每行极相似点是否处于对角线位置的判断方法如下。
[0134]
若diff(fj,qi)为差异性度量函数,如l2-norm等,需满足对角点是其所在行j的极小值,即:
[0135][0136]
若diff(fj,qi)为相似性度量函数,如ssim等,需满足对角点是其所在行j的极大值,即:
[0137][0138]
当差异矩阵内对角线点是其所在行、列的极相似点的数量在对角线点总数中的占比小于第一阈值α时,判断被测机器学习模型本身被篡改,或在其被测运行环境中被篡改,校验不通过,不需要进行后续步骤。例如,α∈[0,1],数值根据实际应用场景确定。
[0139]
在一些实施例中,可以先判断对角线元素是否为其所在行的极值元素;如果是,则根据预设阈值确定差异矩阵中的相似元素;如果否,则不通过校验。
[0140]
在一些实施例中,可以统计差异矩阵中每行的极相似点为对角线点的数量k;再判断k与对角线点的总数量n的比值是否大于等于第一阈值;如果大于等于,则根据预设阈值确定差异矩阵中的相似元素;如果不大于等于,则不通过校验。例如,强相似点可以为差异值小于预设阈值的极值元素。
[0141]
在一些实施例中,可以利用二分类器区分差异矩阵中各像素是否为强相似点(即相似元素)。
[0142]
例如,通过多个可信测试模型以及可信测试环境,得到强相似点的二分类器所需要的训练数据。训练数据可以为差异矩阵中所有值,对角线上的点为强相似点则标记为正例,其余点为强相似点则标记为反例。二分类器可以为svm等。
[0143]
在一些实施例中,可以计算强相似点分类任务中的调和平均值作为校验参数。
[0144]
例如,计算被二分类器确定为强相似点的差异矩阵元素中为对角线元素在所有元素中的占比,以得到准确率p;计算被二分类器确定为强相似点的对角线元素在所有对角线元素中的占比,以得到召回率r;将二者的调和平均值f1∈[0,1]作为校验参数:
[0145][0146]
f1越高则被测机器学习模型与被测环境的可信度越高,原机器学习模型被改动的程度越小。若得到的f1小于第二阈值μ∈(0,1),则校验不通过。例如,第二阈值可以根据p-r曲线确定。
[0147]
通过二分类器判断拥有相同编号的两个输出张量qi和fi是否显著相似,是对张量
间值与分布差异的更加细化的描述。这样,更能体现所比较的两个机器学习模型在处理相同输入数据时的差异。
[0148]
在一些实施例中,根据欧氏距离差异矩阵,对某品牌手机ai进行算力评测。
[0149]
例如,在上述第一实施例的情况下,准确率为99.40%、召回率为99.40%、f1为0.994。第二阈值可以为0.958334。
[0150]
例如,在上述第三实施例的情况下,准确率为94.66%、召回率为17.72%、f1为0.299。
[0151]
在一些实施例中,可以在某芯片中进行ai算力测试的模型输出相似程度校验。
[0152]
例如,在算力测试中,校验被测端是否为追求高算力而采用了不正当加速手段是十分必要的。
[0153]
测试集可以为1000张自选的互不相同的imagenet图片;根据vgg16_notop模型在被测端处理测试集时所用的推断时间和乘、加操作次数,得到被测端的ai算力估值。模型输出的特征张量可以用于模型间相似程度校验。
[0154]
在检验所得差异矩阵是否具有对角线特征的过程中,α值可以设为1。即对角线上的点必须都是其所在行、列的极相似点。原机器学习模型经过量化处理后,其输出的测试张量及其分布的改变是相对较少的。
[0155]
而且,这样的设置亦可以有效地排除被测端为加速推断而故意跳过少量输入图片的问题。例如,只跳过一张图片,模型准确率最多下降0.1%,且易被错误归因为量化算法的问题。
[0156]
例如,在算力测试的校验过程中,由被测端所支持的机器学框架将格式为fp64的vgg16_notop量化处理为in8格式的vgg16_notop测试模型。
[0157]
若diff(fj,qi)为差异性度量函数,差异矩阵需满足对角线上所有点都是其所在行或列的极小值;若diff(fj,qi)为相似性度量函数,差异矩阵需满足对角线上所有点都是其所在行或列的极大值。
[0158]
在一些实施例中,上述任一个实施例中的校验方法也可应用于模型安全校验。例如,校验模型的参数、激活值和结构等是否被恶意篡改。
[0159]
在上述实施例中,针对深度学习模型“黑盒“性质,提出了模型压缩前后的校验方法,能够以模型输出张量值、分布的差异来判断模型间的差异程度。
[0160]
该校验方法利用相似模型输出间差异矩阵所拥有的对角线特征,判断深度学习模型是否被篡改。
[0161]
将校验转换为矩阵内极相似点分布问题和强相似点二分类问题,并以分类结果的f1作为模型差异的表征。
[0162]
图4示出本公开的机器学习模型的校验装置的一些实施例的示意图。
[0163]
如图4所示,机器学习模型的校验装置4包括处理单元41、计算单元42、校验单元43。
[0164]
处理单元41利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量;利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量。被测机器学习模型通过对原始机器学习模型进行压缩处理得到。
[0165]
计算单元42针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量
之间的差异。
[0166]
校验单元43根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
[0167]
在一些实施例中,校验单元43根据任一参考张量与相同编号的测试张量之间的差异,是否小于该参考张量与其他编号的测试张量之间的差异,和/或任一测试张量与相同编号的参考张量之间的差异,是否小于该测试张量与其他编号的参考张量之间的差异,校验相似程度。
[0168]
在一些实施例中,处理单元41为每一个测试集数据设置编号,具有对应关系的测试集数据、参考张量和测试张量具有相同的编号;校验单元43根据各差异,构建差异矩阵,差异矩阵的各行编号为各参考张量的编号、各列编号为各测试张量的编号,每个元素为其行编号对应的参考张量与其列编号对应的测试张量的差异;根据差异矩阵的对角线元素,校验相似程度。
[0169]
在一些实施例中,校验单元43根据差异矩阵中各对角线元素,是否为其所在行和/或所在列的极值元素,校验相似程度。
[0170]
在一些实施例中,校验单元43计算差异矩阵的各对角线元素为极值元素的数量;根据该数量在所有对角线元素的数量中的占比与第一阈值的比较结果,校验相似程度。
[0171]
在一些实施例中,校验单元43将差异矩阵输入分类器模型,将差异矩阵中的各元素分类为相应的参考张量与测试张量的相似元素或非相似元素;在对角元素被分类为相似元素的情况下,标注为正例;在非对角元素被分类为相似元素的情况下,标注为反例;根据正例和反例的标注结果,校验相似程度。
[0172]
在一些实施例中,校验单元43根据标注结果,确定机器学习模型的准确率或召回率中的至少一项;根据准确率或召回率中的至少一项,校验相似程度。
[0173]
在一些实施例中,根校验单元43根据准确率与召回率的乘积、准确率与召回率的加和,确定校验参数,校验参数与乘积正相关,与加和负相关;根据校验参数与第二阈值的比较结果,校验相似程度。
[0174]
在一些实施例中,压缩处理包括模型量化处理、模型裁剪处理、迁移学习处理中的至少一项。
[0175]
在一些实施例中,校验装置还包括测试单元,用于将被测机器学习模型部署在终端上,对终端进行算力测试。
[0176]
在一些实施例中,终端的算力测试装置,包括:测试单元,用于将被测机器学习模型部署在终端上,对终端进行算力测试。被测机器学习模型通过对原始机器学习模型进行压缩处理得到。
[0177]
例如,被测机器学习模型通过如下方式进行相似程度校验:利用原始机器学习模型处理各测试集数据,输出各测试集数据对应的参考张量,利用被测机器学习模型处理各测试集数据,输出各测试集数据对应的测试张量,被测机器学习模型通过对原始机器学习模型进行压缩处理得到;针对每一个测试集数据,计算其对应的参考张量与其对应的测试张量之间的差异;根据差异,校验被测机器学习模型与原始机器学习模型的相似程度。
[0178]
图5示出本公开的机器学习模型的校验装置或终端的算力测试装置的一些实施例的框图。
[0179]
如图5所示,在一些实施例中,机器学习模型的校验装置5包括:存储器51以及耦接
至该存储器51的处理器52,处理器52被配置为基于存储在存储器51中的指令,执行本公开中任意一个实施例中的机器学习模型的校验方法。
[0180]
在一些实施例中,算力测试装置5包括:存储器51以及耦接至该存储器51的处理器52,处理器52被配置为基于存储在存储器51中的指令,执行本公开中任意一个实施例中的算力测试方法。
[0181]
其中,存储器51例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序boot loader、数据库以及其他程序等。
[0182]
图6示出本公开的机器学习模型的校验装置或终端的算力测试装置的另一些实施例的框图。
[0183]
如图6所示,在一些实施例中,机器学习模型的校验装置6包括:存储器610以及耦接至该存储器610的处理器620,处理器620被配置为基于存储在存储器610中的指令,执行前述任意一个实施例中的机器学习模型的校验方法。
[0184]
在一些实施例中,算力测试装置6包括:存储器610以及耦接至该存储器610的处理器620,处理器620被配置为基于存储在存储器610中的指令,执行前述任意一个实施例中的算力测试方法。
[0185]
存储器610例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序boot loader以及其他程序等。
[0186]
校验装置或者算力测试装置还可以包括输入输出接口630、网络接口640、存储接口650等。这些接口630、640、650以及存储器610和处理器620之间例如可以通过总线860连接。其中,输入输出接口630为显示器、鼠标、键盘、触摸屏、麦克、音箱等输入输出设备提供连接接口。网络接口640为各种联网设备提供连接接口。存储接口650为sd卡、u盘等外置存储设备提供连接接口。
[0187]
本领域内的技术人员应当明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用非瞬时性存储介质包括但不限于磁盘存储器、cd-rom、光学存储器等上实施的计算机程序产品的形式。
[0188]
至此,已经详细描述了根据本公开的机器学习模型的校验方法、机器学习模型的校验装置、终端的算力测试方法、终端的算力测试装置和非易失性计算机可读存储介质。为了避免遮蔽本公开的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
[0189]
可能以许多方式来实现本公开的方法和系统。例如,可通过软件、硬件、固件或者软件、硬件、固件的任何组合来实现本公开的方法和系统。用于方法的步骤的上述顺序仅是为了进行说明,本公开的方法的步骤不限于以上具体描述的顺序,除非以其它方式特别说明。此外,在一些实施例中,还可将本公开实施为记录在记录介质中的程序,这些程序包括用于实现根据本公开的方法的机器可读指令。因而,本公开还覆盖存储用于执行根据本公开的方法的程序的记录介质。
[0190]
虽然已经通过示例对本公开的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本公开的范围。本领域的技
术人员应该理解,可在不脱离本公开的范围和精神的情况下,对以上实施例进行修改。本公开的范围由所附权利要求来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1