确定实体关系的方法、存储介质及处理器
1.本发明涉及自然语言处理领域,具体而言,涉及一种确定实体关系的方法、存储介质及处理器。
背景技术:
2.基于实体的关系分析是信息提取中的一种重要应用,它的目标是从非结构化的文本中分析出两个实体之间的关系。目前很多模型利用依存关系分析器先得到每个句子的依存关系树,根据得到的依存关系树来找到两个实体之间的最短依存路径,然后根据该路径上的信息来判断两个实体之间的关系。但由于一些关键的信息会出现在最短依存关系路径以外,因此仅仅依靠最短依存路径会出现信息丢失的情况,进而会出现误判。
3.为了解决过度依赖最短依存关系路径的问题,目前还具有一种修剪依存关系树的方法,该方法保留了最短依存关系路径,并且保留最短关系路径上的词的直接联系词,通过图神经网络的运算,从而提取出两个实体词之间的特征,但在依存关系树的质量不好的情况下,仍然直接影响到最终关系的判断,而且依存关系树需要额外的依存关系提取器得到。也即,目前基于依存关系树的方法会出现错误迭代的情况,如果依存关系提取器提取出的依存关系树质量不好,这些错误的关系将难以被后来的神经网络模型纠正。因此,虽然可以依存关系树找到两个实体之间的联系,但是依存关系树的质量会影响最终关系分类的效果,从而导致对实体间关系的误判。
4.针对现有技术中确定实体之间的关系时准确度较低的问题,目前尚未提出有效的解决方案。
技术实现要素:
5.本发明实施例提供了一种确定实体关系的方法、存储介质及处理器,以至少解决现有技术中确定实体之间的关系时准确度较低的技术问题。
6.根据本发明实施例的一个方面,提供了一种确定实体关系的方法,包括:获取待处理文本和待处理文本中的待确定关系的目标实体;获取待处理文本的文本特征信息,以及,与目标实体相关的第一特征信息;通过注意力机制基于文本特征信息和第一特征信息确定第二特征信息;根据第二特征信息对待确定关系的目标实体之间的关系进行分类。
7.根据本发明实施例的另一方面,还提供了一种存储介质,存储介质包括存储的程序,其中,在程序运行时控制存储介质所在设备执行上述的确定实体关系的方法。
8.根据本发明实施例的另一方面,还提供了一种处理器,处理器用于运行程序,其中,程序运行时执行上述的确定实体关系的方法。
9.根据本发明实施例的另一方面,还提供了一种确定实体关系的方法,包括:获取用户数据,并确定用户数据中待确定关系的目标实体,目标实体中包括产品名称;基于关系分类模型对目标实体的关系进行分类,其中,关系分类模型获取用户数据的文本特征信息,以及与目标实体相关的第一特征信息,通过注意力机制基于文本特征信息和第一特征信息确
定第二特征信息,并根据第二特征信息对待确定关系的目标实体之间的关系进行分类;基于分类结果在用户数据中标注出产品名称;根据分类结果对标注出产品名称的用户数据进行情感分析,确定用户偏好,并根据用户偏好向用户进行产品推荐。
10.根据本发明实施例的另一方面,还提供了一种确定实体关系的方法,包括:获取预设平台中的数据信息,并确定数据信息中待确定关系的目标实体,其中,目标实体中包括人物名称;基于关系分类模型对目标实体的关系进行分类,其中,关系分类模型获取数据信息的文本特征信息,以及与目标实体相关的第一特征信息,通过注意力机制基于文本特征信息和第一特征信息确定第二特征信息,并根据第二特征信息对待确定关系的目标实体之间的关系进行分类;基于分类结果标注出数据信息中的人物名称;按照预设的分析策略基于分类结果,对标注出人物名称的数据信息进行分析,得到人物名称对应的分析结果。
11.根据本发明实施例的另一方面,还提供了一种确定实体关系的方法,包括:获取医疗数据信息,并确定医疗数据信息中待确定关系的目标实体,目标实体用于表示医疗名称;基于关系分类模型对目标实体的关系进行分类,其中,关系分类模型获取数据信息的文本特征信息,以及与目标实体相关的第一特征信息,通过注意力机制基于文本特征信息和第一特征信息确定第二特征信息,并根据第二特征信息对待确定关系的目标实体之间的关系进行分类;基于分类结果对医疗数据信息中的目标实体进行突出显示。
12.在本发明实施例中,获取待处理文本和待处理文本中的多个目标实体,目标实体为待确定关系的实体;获取文本特征信息和第一特征信息,其中,文本特征信息包括待处理文本中每个词的文本特征向量,第一特征信息根据多个目标实体的文本特征向量确定;基于文本特征信息和第一特征信息通过注意力机制确定第二特征信息,其中,第二特征信息包含待处理文本的文本特征信息和目标实体的实体特征信息;根据第二特征信息对多个目标实体之间的关系进行分类,得到多个目标实体之间的关系。上述方案提出了一种基于注意力机制的模型,首先这种方案不需要依存关系图来抽取实体之间的关系,从而可以避免因为依存关系抽取器不好而带来的错误迭代,并为了更好的找到两个实体之间共享的文本信息,引入加入了多头的注意力机制,由此可以找到和目标实体更相关的文本信息,进而更准确的判断出目标实体的关系,解决了现有技术中确定实体之间的关系时准确度较低的技术问题。
附图说明
13.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
14.图1示出了一种用于实现确定实体关系的方法的计算设备(或移动设备)的硬件结构框图;
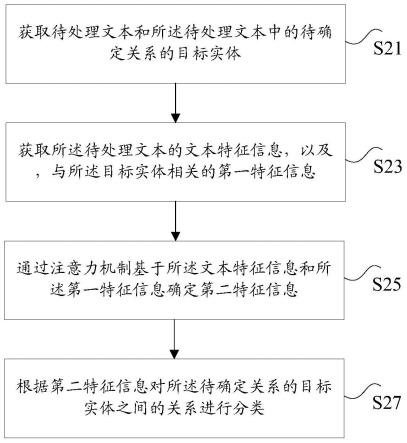
15.图2是根据本技术实施例1的一种确定实体关系的方法的流程图;
16.图3是根据本技术实施例1的一种实体关系分类模型的示意图;
17.图4a是根据本技术实施例1的一种对scierc-ds and conll04-s进行评估的效果比较意图;
18.图4b是根据本技术实施例1的一种对tacred和kbp37评估效果的效果比较示意图;
19.图5a是中tacred数据集中对目标实体之间具有不同数量的上下文的数据进行处
理的结果示意图;
20.图5b是对tacred数据集中包含单一关系和多重关系的句子的处理结果进行比对的示意图;
21.图6是根据本技术实施例2的一种确定实体关系的装置的示意图;
22.图7是根据本发明实施例4的一种计算设备的结构框图;
23.图8是根据本技术实施例6的一种确定实体关系的方法的流程图;
24.图9是根据本技术实施例7的一种确定实体关系的方法的流程图;
25.图10是根据本技术实施例8的一种确定实体关系的方法的流程图;
26.图11是根据本技术实施例9的一种确定实体关系的装置的示意图;
27.图12是根据本技术实施例10的一种确定实体关系的装置的示意图;
28.图13是根据本技术实施例11的一种确定实体关系的装置的示意图。
具体实施方式
29.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
30.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
31.首先,在对本技术实施例进行描述的过程中出现的部分名词或术语适用于如下解释:
32.注意力机制(attention mechanism):一种分析两个个体关系的机制,用于在众多信息中把注意力集中放在重要的点上,选出关键信息,而忽略其他不重要的信息。
33.依存关系树(dependency tree):一种体现词与词之间关系的树状结构图。
34.最短依存路径(shortest dependency path):根据依存关系图找到两个实体之间的最短依存路径。
35.bert(bidirectional encoder representations from transformers):一种文本信息提取模型。
36.bi-lstm(bi-long short-term memory):长短期记忆网络,通常用来提取文本信息。
37.实施例1
38.根据本发明实施例,还提供了一种确定实体关系的方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,
虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
39.本技术实施例一所提供的方法实施例可以在移动终端、计算设备或者类似的运算装置中执行。图1示出了一种用于实现确定实体关系的方法的计算设备(或移动设备)的硬件结构框图。如图1所示,计算设备10(或移动设备10)可以包括一个或多个(图中采用102a、102b,
……
,102n来示出)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)、用于存储数据的存储器104、以及用于通信功能的传输模块106。除此以外,还可以包括:显示器、输入/输出接口(i/o接口)、通用串行总线(usb)端口(可以作为i/o接口的端口中的一个端口被包括)、网络接口、电源和/或相机。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,计算设备10还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
40.应当注意到的是上述一个或多个处理器102和/或其他数据处理电路在本文中通常可以被称为“数据处理电路”。该数据处理电路可以全部或部分的体现为软件、硬件、固件或其他任意组合。此外,数据处理电路可为单个独立的处理模块,或全部或部分的结合到计算设备10(或移动设备)中的其他元件中的任意一个内。如本技术实施例中所涉及到的,该数据处理电路作为一种处理器控制(例如与接口连接的可变电阻终端路径的选择)。
41.存储器104可用于存储应用软件的软件程序以及模块,如本发明实施例中的确定实体关系的方法对应的程序指令/数据存储装置,处理器102通过运行存储在存储器104内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的应用程序的确定实体关系的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至计算设备10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
42.传输模块106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括计算设备10的通信供应商提供的无线网络。在一个实例中,传输模块106包括一个网络适配器(network interface controller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输模块106可以为射频(radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
43.显示器可以例如触摸屏式的液晶显示器(lcd),该液晶显示器可使得用户能够与计算设备10(或移动设备)的用户界面进行交互。
44.此处需要说明的是,在一些可选实施例中,上述图1所示的计算机设备(或移动设备)可以包括硬件元件(包括电路)、软件元件(包括存储在计算机可读介质上的计算机代码)、或硬件元件和软件元件两者的结合。应当指出的是,图1仅为特定具体实例的一个实例,并且旨在示出可存在于上述计算机设备(或移动设备)中的部件的类型。
45.在上述运行环境下,本技术提供了如图2所示的确定实体关系的方法。图2是根据本技术实施例1的一种确定实体关系的方法的流程图。
46.步骤s21,获取待处理文本和所述待处理文本中的待确定关系的目标实体。
47.具体的,上述目标实体可以用于表示实体词,一个句子中的主语和宾语通常均为
实体。例如,小明今年12岁,其中,小明、12岁均为实体。上述待处理文本中包括多个实体,目标实体为待处理文本中的全部实体或部分实体。当需要确定待处理文本中的两个实体之间的关系时,将这两个实体作为上述目标实体。
48.在一种可选的实施例中,上述待处理文本可以为从招聘网络中的自我介绍的文本,可以将自我介绍的文本中与用户相关联的实体标记为目标实体,以确定用户与其他实体之间的关系,进而可以得到与用户相关信息,基于这些信息,可以对用户进行职位推荐等a。
49.在另一种可选的实施例中,上述待处理文本还可以为社会新闻文本,可以将感兴趣的对象标记为目标实体,以确定感兴趣的对象之间的关系,进而可以生成对象之间的关系图谱,其中,上述感兴趣的对象作为图谱中的节点,感兴趣的对象之间的关系作为节点之间的边。在获得上述图谱后,可以基于上述图谱执行预设的下游任务。例如,在特定领域内的评论知识图谱中,给定星巴克以及约会地点,他们之间的关系可以通过“环境”来连接。
50.步骤s23,获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息。
51.具体的,上述文本特征信息可以是文本特征序列。文本特征序列中的每个元素对应待处理文本中一个词的文本特征向量。在一种可选的实施例中,将待处理文本的每个词生成对应的文本特征向量,再将每个词对应的文本特征向量构成上述文本特征信息。生成文本特征向量的方式可以为word2vec等,此处不进行限定。
52.上述第一特征信息可以根据多个目标实体的特征向量确定,在一种可选的实施例中,可以对待处理文本中的每个词获取对应的文本特征向量,得到文本特征信息,再从文本特征信息中抽取目标实体对应的文本特征向量,再对多个目标实体的文本特征向量进行特征融合,得到上述第一特征信息。
53.步骤s25,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息。
54.具体的,第二特征信息包含待处理文本的文本特征信息和目标实体的实体特征信息。
55.上述注意力机制可以是多头注意力机制(multi-head attention),多头注意力是利用多个查询,来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分。在上述方案中,通过多头注意力机制从文本特征信息中选取对应的文本特征向量。
56.上述步骤通过引入注意力机制,将文本特征信息作为多个目标实体的实体间共享文本信息,从而获取到目标实体在待处理文本的语境之中的特征信息,即第二特征信息。以该步骤获得的第二特征信息对多个目标实体之间的关系进行分类,能够在不依赖的依存关系树的情况下基于目标实体在待处理文本中的共享下信息确定二者的关系。
57.步骤s27,根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
58.具体的,上述分类用于表示关系分类,即通过分类来确定目标实体之间的关系可以通过分类器实现。上述方案实际是通过分类来确定目标实体之间的关系的分类问题。
59.在进行情感分类时,通常会使简单的三分类或者五分类问题,但关系分析涵盖更多的类别,比如说出生地,出生日期,工作,职位等等,根据不同的场景可以对类别做出相应的调整。
60.在一种可选的实施例中,上述方案可以用于建立用户资料库。通过关系分类任务查出用户的各种属性,进而构成用户资料库。例如,对于文本“我今年20”,通过关系分类,可以判断出该用户为20岁。因此关系分类可以帮助各平台建立更好的用户资料库,以及帮助在各个领域建立对应的知识图谱,从而可以给不同用户推荐出更合适产品以及服务。
61.本实施例中的上述方案可以通过一个实体关系分类模型来实现上述步骤,该实体关系分类模型中至少包括特征提取层、特征融合层、注意力机制层以及全连接层。其中,特征提取层用于获取待处理文本中每个词的文本特征信息,特征融合层用于对目标实体的文本特征向量进行特征融合得到第一特征信息,注意力机制层用于根据文本特征信息和第一特征信息,通过多头注意力机制获取共享文本信息的第二特征信息,最后由全连接层作为分类器根据第二特征信息对多个目标实体之前的关系进行分类。
62.需要说明的是,如果利用注意力机制来缓解依存关系树质量不好的缺陷,该模型可以获得每个词与词之间的关系,然后通过图神经网络来抽取到实体之间的特征,但仍需要依存关系分析器来得到依存关系图,然后根据依存关系图来初始化神经网络,而如果仅仅利用句子层面的信息来预测实体之间的关系,但由于实体的特征向量含有更多的关系信息,因此使用这样的方式会由于忽略了给定目标实体的信息从而导致模型具有较差的表现,且如果句子里面出现多个目标实体的配对,仅仅利用句子层面的信息不能区别不同的目标实体配对。
63.本技术上述实施例获取待处理文本和所述待处理文本中的待确定关系的目标实体;获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。上述方案提出了一种基于注意力机制的模型,首先这种方案不需要依存关系图来抽取实体之间的关系,从而可以避免因为依存关系抽取器不好而带来的错误迭代,并为了更好的找到两个实体之间共享的文本信息,引入加入了多头的注意力机制,由此可以找到和目标实体更相关的文本信息,进而更准确的判断出目标实体的关系,解决了现有技术中确定实体之间的关系时准确度较低的技术问题。
64.作为一种可选的实施例,在获取待处理文本和所述待处理文本中的待确定关系的目标实体之前,上述方法还包括:抽取待处理文本中的实体,并对实体中的目标实体进行标记;获取待处理文本和所述待处理文本中的待确定关系的目标实体的步骤包括:获取待处理文本,并通过标记确定待处理文本中的目标实体。
65.目标实体为待处理文本中需要获取二者关系的实体。在待处理文本包括多个实体的情况下,并不一定需要获取每个实体之间的关系,因此可以在将对待处理文本中的实体进行关系分类前,先对目标实体进行标记,以使实体关系分类模型能够确定进行关系分类的对象。
66.在一种可选的实施例中,在待处理文本中仅包含两个需要确定二者关系的目标实体的情况下,对两个目标实体进行标记,在待处理文本中包含多个需要确定关系的目标实体的情况下,可以分别进行标记以构成目标实体对,实体关系分类模型根据目标实体对来确定进行关系分类的对象。
67.例如,待处理文本为“小明今年12岁,上六年级”,其中的实体包括“小明”、“12岁”、“六年级”,为了确定“小明”和“12岁”的关系,可以将“小明”和“12岁”标记为目标实体;为了确定“小明”和“六年级”的关系,可以将“小明”和“六年级”标记为目标实体。如果既需要确定“小明”与“12岁”的关系,还需要确定“小明”与“六年级”的关系,则可以将“小明”与“12岁”进行一种标记构成一个目标实体对,并将“小明”与“六年级”进行同一种标记构成一个目标实体对。
68.作为一种可选的实施例,在获取待处理文本和所述待处理文本中的待确定关系的目标实体之前,上述方法还包括:在待处理文本为预设语种的情况下,对待处理文本进行分词,其中,预设语种至少包括汉语。
69.各个语种在构造文本时的结构不同,一些语种的文本以词为最小单位,例如,英语、法语等,因此无需进行分词。但对于一些以字为最小单位的语种,例如中文,则需要先对中文的待处理文本进行分词,再在分词结果中标记出目标实体。
70.作为一种可选的实施例,获取文本特征信息,包括:通过预设的特征提取网络对待处理文本的每个词进行特征提取,得到每个词对应的文本特征向量。
71.具体的,上述步骤可以通过特征提取网络实现。
72.在一种可选的实施例中,可以通过实体关系分类模型对待处理文本中的目标实体的关系进行分类。该实体分类模型包括特征提取层,特征提取层由特征提取网络构成,以对待处理文本中的每个词进行特征提取。该特征提取网络可以为bert或者bi-lstm。
73.图3是根据本技术实施例的一种实体关系分类模型的示意图,结合图3所示,该示例中,待处理文本为“she is 61 years old”,其中的目标实体为“she”和“61”,对“she”和“61”分别标记为e1和e2。首先将bert或bi-lstm作为特征提取网络,对待处理文本中的每个词进行特征提取,得到每个词对应的文本特征向量,即“she”对应的h0、“is”对应的h1、“61”对应的h2、“years”对应的h3以及“old”对应的h4,h0、h1、h2、h3和h4即构成上述的文本特征信息。
74.作为一种可选的实施例,获取与所述目标实体相关的第一特征信息,包括:从文本特征信息中抽取目标实体的文本特征向量;对目标实体的文本特征向量进行最大池化处理,得到降维后的文本特征向量;基于多个目标实体的降维后的文本特征向量确定第一特征信息。
75.由于在对待处理文本进行关系分类前,对待处理文本中的目标实体进行了标记,因此在获取到文本特征信息后,可以在文本特征信息中抽取标记的目标实体对应的文本特征向量。
76.由于每个目标实体的长度不同,使得每个目标实体对应的文本特征向量的维度并不一定相同,因此在获得目标实体的文本特征向量后,通过池化层对目标实体的文本特征向量进行降维,使降维后的目标实体的文本特征向量具有相同的维度,再基于降维后的目标实体的文本特征向量进行特征融合,即可得到上述第一特征信息。
77.在一种可选的实施例中,仍结合图3所示,“she”和“61”对应的文本特征向量分别为h0和h2,h0和h2的维度可能不同,抽取出h0和h2并分别对h0和h2进行池化处理(max-pool)处理以对h0和h2进行降维,得到池化处理后的h
e1
和h
e2
,h
e1
和h
e2
具有相同的维度,进而可以进行特征融合,得到上述第一特征信息。
78.作为一种可选的实施例,基于多个目标实体的降维后的文本特征向量确定第一特
征信息,包括:将多个目标实体的降维后的文本特征向量进行连接,得到连接特征向量;对连接特征向量通过单层神经网络进行特征融合得到第一特征信息。
79.在上述方案中,由于多个目标实体降维后的文本特征向量具有相同的维度,因此可以进行特征相邻的连接,并通过单层神经网络,以对多个目标实体的特征信息进行特征融合,得到上述第一特征信息。
80.在一种可选的实施例中,仍结合图3所示,在经过池化层得到h
e1
和h
e2
后,为了融合两个目标实体的特征信息,可以将两个目标实体的文本特征向量经过拼接然后传递到一个单层神经网络,得到一个融合了两个目标实体的特征信息的特征向量h
dual_e
,h
dual_e
即为上述第一特征信息。例如,h
e1
和h
e2
均为维度为300的特征向量,在进行连接后得到维度为600的连接特征向量,再对连接特征向量通过单层神经网络进行特征提取,以通过降低维度的方式将两个目标实体的文本特征向量进行融合,再次得到维度为300的特征向量,该维度为300的特征向量即为第一特征信息,该实体特征信息包含了“she”和“61”这两个目标实体的特征信息。
81.上述方案通过池化处理的方式得到池化后每个目标实体的文本特征向量h
e1
和h
e2
,将h
e1
和h
e2
进行拼接后经过一个单层神经网络得到融合的第一特征信息h
dual_e
,从而在没有利用依存关系树的情况下,该特征向量也同时融合了待处理文本文本信息以及目标实体的实体信息。
82.作为一种可选的实施例,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,包括:确定第一特征信息为查询参数,文本特征信息为键参数和值参数,通过注意力机制确定第二特征信息。
83.注意力机制的输入包括query和键值对key-value pairs,上述查询参数即为query,键参数和值参数即为key-value。对于一个query来说,attention机制会与每一个key计算注意力分数并进行权重的归一化,输出的向量则是value的加权求和,而每个key计算的权重与value一一对应。
84.在一种可选的实施例中,仍结合图3所示,将文本特征信息h0、h1、h2、h3和h4以及第一特征信息h
dual_e
输入至多头注意力机制(attention),其中,将h
dual_e
作为查询参数,将h0、h1、h2、h3和h4作为键参数和值参数,即可得到多头注意力机制输出的h
dual_e_att
,h
dual_e_att
即为第二特征信息。
85.上述方案首先融合了两个目标实体的文本特征向量,并在不利用依存关系树的情况下,融合了两个目标实体的文本特征向量,得到一个同时融合了文本信息以及实体信息的向量。
86.为了更好的找到两个目标实体之间共享的文本也在信息,上述方案加入了多头的注意力机制,从而可以在待处理文本这一语境中找到和目标实体更加相关的文本特征信息。最后将特征向量h_dual_e_att输入一个分类器即刻进行最后的关系分类。
87.作为一种可选的实施例,不同领域的文本具有对应的分类器和关系集合,根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类,包括:确定待处理文本所属的领域;使用待处理文本所属的领域对应的分类器对根据第二特征信息进行分类,以从对应的关系集合中确定多个目标实体之间的关系。
88.在上述方案中每个领域的分类器用于在其所对应的关系结合中对目标实体的关
系进行分类。此处的领域可以按照不同的领域进行划分。
89.在一种可选的实施例中,可以根据需求进行划分,例如,当场景为求职平台的职位推荐时,可以设置关系结合包括:姓名、学历、工作经验、技能等,该领域的分类器即在这一关系集合中对目标实体的关系进行分类。当场景为电商平台的产品推荐时,可以设置关系结合包括:出生地,出生日期,工作,职位等。
90.图4a是根据本技术实施例的一种对scierc-ds and conll04-s进行评估的效果比较意图,图4b是根据本技术实施例的一种对tacred和kbp37评估效果的效果比较示意图。scierc-ds、conll04-s、tacred和kbp37为四个不同的数据集,其中,dev f1用于表示各个模型开发集(development set)上的f1,p用于表示精确率(precision),r用于表示召回率(recall),可以看出,采用本实施例提出的模型(dual-e-att
bert
)对不同的数据集均具有更好的表现。
91.距离较远的目标实体之间的共享信息更难捕捉,图5a是tacred数据集中对目标实体之间具有不同数量的上下文的数据进行处理的结果示意图。结合图5所示,横坐标表示目标实体之间的上下文数量,纵坐标表示dev f1(%),显然可以看出,相对于其他模型,本技术所提出的模型(dual-e-att
bert
)具有更好的表现。
92.本技术中所提供的方法模型是基于实体间的共享信息的提取,因此当句子里面出现多个实体的时候关系会更加的复杂。图5b是对tacred数据集中包含单一关系和多重关系的句子的处理结果进行比对的示意图,结合图5b所示,横坐标分别为max-p、max-p+ee、dual-e、dual-e、dual-e-att、dual-e-att
bert
、aggcn以及spanbert,纵坐标表示dev f1(%),显然可以看出,在句子里面有更多的目标实体的时候本技术所提出的模型(dual-e-att
bert
)仍然具有很好的表现效果。
93.需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
94.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例的方法。
95.实施例2
96.根据本发明实施例,还提供了一种用于实施上述确定实体关系的方法的确定实体关系的装置,图6是根据本技术实施例的一种确定实体关系的装置的示意图,结合图6所示,该装置600包括:
97.第一获取模块60,用于获取待处理文本和待处理文本中的多个目标实体,其中,目标实体为待确定关系的实体。
98.第二获取模块62,用于获取所述待处理文本的文本特征信息,以及,与所述目标实
体相关的第一特征信息。
99.确定模块64,用于通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息。
100.分类模块66,用于根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
101.此处需要说明的是,上述第一获取模块60、第二获取模块62、确定模块64和分类模块66对应于实施例1中的步骤s21至步骤s27,四个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算设备10中。
102.作为一种可选的实施例,上述装置还包括:抽取模块,用于在获取待处理文本和待处理文本中的多个目标实体之前,抽取待处理文本中的实体,并对实体中的目标实体进行标记;第一获取模块包括:获取子模块,用于获取待处理文本和待处理文本中的至少两个目标实体的步骤包括:获取待处理文本,并通过标记确定待处理文本中的目标实体。
103.作为一种可选的实施例,上述装置还包括:分词模块,用于在获取待处理文本和所述待处理文本中的待确定关系的目标实体之前,在待处理文本为预设语种的情况下,对待处理文本进行分词,其中,预设语种至少包括汉语。
104.作为一种可选的实施例,获取文本特征信息,包括:提取子模块,用于通过预设的特征提取网络对待处理文本的每个词进行特征提取,得到每个词对应的文本特征向量。
105.作为一种可选的实施例,第二获取模块包括:抽取子模块,用于从文本特征信息中抽取目标实体的文本特征向量;池化处理子模块,用于对目标实体的文本特征向量进行最大池化处理,得到降维后的文本特征向量;第一确定子模块,用于基于多个目标实体的降维后的文本特征向量确定第一特征信息。
106.作为一种可选的实施例,第一确定子模块包括:连接单元,用于将多个目标实体的降维后的文本特征向量进行连接,得到连接特征向量;特征提取单元,用于对连接特征向量通过单层神经网络进行特征融合得到第一特征信息。
107.作为一种可选的实施例,确定模块包括:第二确定子模块,用于确定第一特征信息为查询参数,文本特征信息为键参数和值参数,通过注意力机制确定第二特征信息。
108.作为一种可选的实施例,不同领域的文本具有对应的分类器和关系集合,分类模块包括:第三确定子模块,用于确定待处理文本所属的领域;分类子模块,用于使用待处理文本所属的领域对应的分类器对根据第二特征信息进行分类,以从对应的关系集合中确定多个目标实体之间的关系。
109.实施例3
110.本发明的实施例可以提供一种确定实体关系的系统,包括:
111.处理器;以及
112.存储器,与处理器连接,用于为处理器提供处理以下处理步骤的指令:
113.获取待处理文本和所述待处理文本中的待确定关系的目标实体;
114.获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;
115.通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;
116.根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
117.需要说明的是,本实施例中的存储器还用于为处理器提供处理实施例1中的其他步骤的指令,此处不在赘述。
118.实施例4
119.本发明的实施例可以提供一种计算设备,该计算设备可以是计算设备群中的任意一个计算设备。可选地,在本实施例中,上述计算设备也可以替换为移动终端等终端设备。
120.可选地,在本实施例中,上述计算设备可以位于计算机网络的多个网络设备中的至少一个网络设备。
121.在本实施例中,上述计算设备可以执行应用程序的确定实体关系的方法中以下步骤的程序代码:获取待处理文本和所述待处理文本中的待确定关系的目标实体;获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
122.可选地,图7是根据本发明实施例4的一种计算设备的结构框图。如图7所示,该计算设备a可以包括:一个或多个(图中仅示出一个)处理器702、存储器706、以及外设接口708。
123.其中,存储器可用于存储软件程序以及模块,如本发明实施例中的确定实体关系的方法和装置对应的程序指令/模块,处理器通过运行存储在存储器内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的确定实体关系的方法。存储器可包括高速随机存储器,还可以包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器可进一步包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至终端a。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
124.处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:获取待处理文本和所述待处理文本中的待确定关系的目标实体;获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
125.可选的,上述处理器还可以执行如下步骤的程序代码:在获取待处理文本和所述待处理文本中的待确定关系的目标实体之前,抽取待处理文本中的实体,并对实体中的目标实体进行标记;获取待处理文本和所述待处理文本中的待确定关系的目标实体包括:获取待处理文本,并通过标记确定待处理文本中的目标实体。
126.可选的,上述处理器还可以执行如下步骤的程序代码:在获取待处理文本和所述待处理文本中的待确定关系的目标实体之前,在待处理文本为预设语种的情况下,对待处理文本进行分词,其中,预设语种至少包括汉语。
127.可选的,上述处理器还可以执行如下步骤的程序代码:通过预设的特征提取网络对待处理文本的每个词进行特征提取,得到每个词对应的文本特征向量。
128.可选的,上述处理器还可以执行如下步骤的程序代码:从文本特征信息中抽取目标实体的文本特征向量;对目标实体的文本特征向量进行最大池化处理,得到降维后的文
本特征向量;基于多个目标实体的降维后的文本特征向量确定第一特征信息。
129.可选的,上述处理器还可以执行如下步骤的程序代码:将多个目标实体的降维后的文本特征向量进行连接,得到连接特征向量;对连接特征向量通过单层神经网络进行特征融合得到第一特征信息。
130.可选的,上述处理器还可以执行如下步骤的程序代码:确定第一特征信息为查询参数,文本特征信息为键参数和值参数,通过注意力机制确定第二特征信息。
131.可选的,不同领域的文本具有对应的分类器和关系集合,上述处理器还可以执行如下步骤的程序代码:确定待处理文本所属的领域;使用待处理文本所属的领域对应的分类器对根据第二特征信息进行分类,以从对应的关系集合中确定多个目标实体之间的关系。
132.采用本发明实施例,提供了一种文本的处理方案。通过获取待处理文本和所述待处理文本中的待确定关系的目标实体;获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。上述方案提出了一种基于注意力机制的模型,首先这种方案不需要依存关系图来抽取实体之间的关系,从而可以避免因为依存关系抽取器不好而带来的错误迭代,并为了更好的找到两个实体之间共享的文本信息,引入加入了多头的注意力机制,由此可以找到和目标实体更相关的文本信息,进而更准确的判断出目标实体的关系,解决了现有技术中确定实体之间的关系时准确度较低的技术问题。
133.本领域普通技术人员可以理解,图7所示的结构仅为示意,计算设备也可以是智能手机(如android手机、ios手机等)、平板电脑、掌声电脑以及移动互联网设备(mobile internet devices,mid)、pad等终端设备。图7其并不对上述电子装置的结构造成限定。例如,计算设备a还可包括比图7中所示更多或者更少的组件(如网络接口、显示装置等),或者具有与图7所示不同的配置。
134.本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令终端设备相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
135.实施例5
136.本发明的实施例还提供了一种存储介质。可选地,在本实施例中,上述存储介质可以用于保存上述实施例一所提供的确定实体关系的方法所执行的程序代码。
137.可选地,在本实施例中,上述存储介质可以位于计算机网络中计算设备群中的任意一个计算设备中,或者位于移动终端群中的任意一个移动终端中。
138.可选地,在本实施例中,存储介质被设置为存储用于执行以下步骤的程序代码:获取待处理文本和所述待处理文本中的待确定关系的目标实体;获取所述待处理文本的文本特征信息,以及,与所述目标实体相关的第一特征信息;通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息;根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
139.实施例6
140.本技术提供了如图8所示的确定实体关系的方法。图8是根据本技术实施例6的一种确定实体关系的方法的流程图。
141.步骤s81,获取用户数据,并确定所述用户数据中待确定关系的目标实体,所述目标实体中包括产品名称。
142.具体的,上述用户数据可以从电商平台中获取的语料,例如,商品评论信息、用户与商家的沟通信息,以及用户与电商客服的沟通信息等。用户数据中待确定关系的目标实体可以是用户数据中预设的实体词。这些目标实体可以通过对用户数据进行实体词识别而得到。
143.步骤s83,基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述用户数据的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
144.具体的,上述关系分类模型可以通过执行实施例1中的步骤确定目标实体的关系。
145.在一种可选的实施例中,可以识别出用户数据中的多个目标实体,在这些目标实体中包括产品名称的情况下,即可通过上述步骤确定出其他实体与产品名称之间的关系。
146.步骤s85,基于分类结果在所述用户数据中标注出所述产品名称。
147.上述步骤中,在用户数据中标注出产品名称,以确定当前的分析对象。
148.步骤s87,根据所述分类结果对标注出产品名称的用户数据进行情感分析,确定用户偏好,并根据所述用户偏好向所述用户进行产品推荐。
149.具体的,上述标注出产品名称的用户数据即为包含产品的语料。在上述步骤中,标注出的产品名称即为待分析的产品名称。对于标注出产品名称的用户数据,分析用户偏好,即可确定出用户对标注出的产品名称所对于的产品的洗好程度。通过对大量的用户数据进行上述分析,即可得到用户对某个产品的偏好,或用户对某类产品的偏好,以及用户对某个品牌的偏好等。
150.在一种可选的实施例中,可以基于分类得到的其他实体与产品名称的关系,对用户数据进行情感分析,情感分析结果可以为通过(0,1]之间的数值来表示,其中,情感分析结果越接近于1,喜好程度越高;也可以用0和1两种数值来表示,其中,0表示负面情绪,1表示正面情绪。因此基于情感分析结果即可以确定出用户对某个产品的偏好,或用户对某类产品的偏好,以及用户对某个品牌的偏好等。
151.在获得用户偏好后,即可根据预设的推荐算法根据用户偏好向用户进行产品推荐,以提高推荐产品的准确程度。
152.本技术上述实施例获取用户数据,并确定所述用户数据中待确定关系的目标实体,所述目标实体中包括产品名称;基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述用户数据的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;基于分类结果在所述用户数据中标注出所述产品名称;根据所述分类结果对标注出产品名称的用户数据进行情感分析,确定用户偏好,并根据所述用户偏好向所述用户进行产品推荐。上述方案通过使用关系分类模型,对用户数据中的目标实体之间的关系进行分类,从而根据分类结
果对用户数据进行情感分析得到用户的偏好,并根据用户的偏好对用户进行产品推荐,达到了提高产品推荐的准确度技术效果。
153.实施例7
154.本技术提供了如图9所示的确定实体关系的方法。图9是根据本技术实施例7的一种确定实体关系的方法的流程图,该方法包括:
155.步骤s91,获取预设平台中的数据信息,并确定所述数据信息中待确定关系的目标实体,其中,所述目标实体中包括人物名称。
156.具体的,上述预设平台可以是音乐、影视交流平台、售票平台、讨论平台等。数据信息中待确定关系的目标实体可以是数据信息中预设的实体词。这些目标实体可以通过对数据信息进行实体词识别而得到。上述人物名称可以为演员名称、歌手名称、影视剧中的人物名称等。
157.步骤s93,基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述数据信息的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
158.具体的,上述关系分类模型可以通过执行实施例1中的步骤确定目标实体的关系。
159.在一种可选的实施例中,可以识别出数据信息中的多个目标实体,在这些目标实体中包括人物名称的情况下,即可通过上述步骤确定出其他实体与人物名称之间的关系。
160.步骤s95,基于分类结果标注出所述数据信息中的人物名称。
161.上述步骤中,在数据信息中标注出人物名称,以确定当前的分析对象。
162.步骤s97,按照预设的分析策略基于所述分类结果,对标注出人物名称的数据信息进行分析,得到所述人物名称对应的分析结果。
163.在上述步骤中,基于分类结果对数据信息进行分析,可以得到用户对人物名称所表示的人物的关注度,以及用户对这些人物在各个维度的评论,从而可以得到人物热度排名、演技排名、唱功排名等信息。且对于用户来说,还能够分析得到用户对人物的偏好,从而可以根据用户的偏好在预设平台中向用户推荐影视作品。例如,可以分析得到用户对各个人物的喜好排名,并向用户推荐喜好排名较高的人物的作品。
164.由上可知,本技术上述实施例获取预设平台中的数据信息,并确定所述数据信息中待确定关系的目标实体,其中,所述目标实体中包括人物名称;基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述用户数据的文本数据信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;基于分类结果标注出所述数据信息中的人物名称;按照预设的分析策略基于所述分类结果,对标注出人物名称的数据信息进行分析,得到所述人物名称对应的分析结果。上述方案通过对预设平台中包括人物名称的数据信息中的目标实体进行关系分类,从而根据分类结果对各个人物名称进行分析,得到用户对各个人物的偏好,进而可以根据用户对各个人物的偏好向用户推荐相关的作品,达到了提高推荐准确度的效果。
165.实施例8
166.本技术提供了如图10所示的确定实体关系的方法。图10是根据本技术实施例8的
一种确定实体关系的方法的流程图,该方法包括:
167.步骤s101,获取医疗数据信息,并确定所述医疗数据信息中待确定关系的目标实体,所述目标实体用于表示医疗名称。
168.具体的,上述医疗数据信息可以包括诊断书、化验单等。医疗数据信息中待确定关系的目标实体可以是医疗数据信息中预设的实体词。这些目标实体所表示的医疗名称可以通过对医疗数据信息进行实体词识别而得到,例如,医疗名称可以包括:药品名称、疾病名称、治疗名称等。
169.步骤s103,基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述数据信息的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类。
170.具体的,上述关系分类模型可以通过执行实施例1中的步骤确定目标实体的关系。
171.步骤s105,基于分类结果对所述医疗数据信息中的所述目标实体进行突出显示。
172.在上述方案中,基于分类结果对所述医疗数据信息中的医疗名称进行突出显示,可以是将有某种关系的目标实体采用同一种颜色显示,例如,疾病x1的用药为y1,剂量为z1,疾病x2的用药为y2,剂量为z2,确定出的关系为:y1为x1治疗手段,z1为y1的使用方法,y2为x2治疗手段,z2为y2的使用方法,因此x1、y1、z1使用同一种方式显示(同一种颜色、字体或底色),x2、y2、z2使用同一种方式显示。从而可以便于医护人员快速准确的从医疗数据信息中读取有效信息。
173.由上可知,本技术上述实施例获取医疗数据信息,并确定所述医疗数据信息中待确定关系的目标实体;基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述数据信息的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;基于分类结果对所述医疗数据信息中的所述目标实体进行突出显示。上述方案通过对医疗数据信息中的目标实体进行关系分类,并基于关系分类结果在医疗数据信息中标注出医疗名称,从而达到了便于医护人员快速准确的从医疗数据信息中读取有效信息的效果。
174.实施例9
175.根据本发明实施例,还提供了一种用于执行实施例6中的确定实体关系的方法的确定实体关系的装置,图11是根据本技术实施例9的一种确定实体关系的装置的示意图,结合图11所示,该装置1100包括:
176.获取模块1102,用于获取用户数据,并确定所述用户数据中待确定关系的目标实体,所述目标实体中包括产品名称;
177.分类模块1104,用于基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述用户数据的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;
178.标注模块1106,用于基于分类结果在所述用户数据中标注出所述产品名称;
179.分析模块1108,用于根据所述分类结果对标注出产品名称的用户数据进行情感分
析,确定用户偏好,并根据所述用户偏好向所述用户进行产品推荐。
180.此处需要说明的是,上述获取模块1102、分类模块1104、标注模块1106和分析模块1108对应于实施例6中的步骤s81至步骤s87,四个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算设备10中。
181.实施例10
182.根据本发明实施例,还提供了一种用于执行实施例7中的确定实体关系的方法的确定实体关系的装置,图12是根据本技术实施例10的一种确定实体关系的装置的示意图,结合图12所示,该装置1200包括:
183.获取模块1202,用于获取预设平台中的数据信息,并确定所述数据信息中待确定关系的目标实体,其中,所述目标实体中包括人物名称;
184.分类模块1204,用于基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述数据信息的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;
185.标注模块1206,用于基于分类结果标注出所述数据信息中的人物名称;
186.分析模块1208,用于按照预设的分析策略基于所述分类结果,对标注出人物名称的数据信息进行分析,得到所述人物名称对应的分析结果。
187.此处需要说明的是,上述获取模块1202、分类模块1204、标注模块1206和分析模块1208对应于实施例7中的步骤s91至步骤s97,四个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算设备10中。
188.实施例11
189.根据本发明实施例,还提供了一种用于执行实施例8中的确定实体关系的方法的确定实体关系的装置,图13是根据本技术实施例11的一种确定实体关系的装置的示意图,结合图13所示,该装置1300包括:
190.获取模块1302,用于获取医疗数据信息,并确定所述医疗数据信息中待确定关系的目标实体,所述目标实体用于表示医疗名称;
191.分析模块1304,用于基于关系分类模型对所述目标实体的关系进行分类,其中,所述关系分类模型获取所述数据信息的文本特征信息,以及与所述目标实体相关的第一特征信息,通过注意力机制基于所述文本特征信息和所述第一特征信息确定第二特征信息,并根据第二特征信息对所述待确定关系的目标实体之间的关系进行分类;
192.显示模块1306,用于基于分类结果对所述医疗数据信息中的所述目标实体进行突出显示。
193.此处需要说明的是,上述获取模块1302、分析模块1304和显示模块1306对应于实施例8中的步骤s101至步骤s105,四个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算设备10中。
194.上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
195.在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
196.在本技术所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
197.所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
198.另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
199.所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
200.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1