基于人工智能AI的文档处理器的制作方法
基于人工智能ai的文档处理器
1.优先权
2.本技术要求于2020年5月12日提交的印度专利申请号202014020088的优先权,并且本技术是于2019年8月5日提交的美国非临时申请号16/531,848的部分继续申请,其又要求于2018年11月2日提交的美国非临时申请号16/179,448的优先权,其又要求于2018年5月21日提交的美国临时专利申请号62/674,367的优先权。本技术也是于2018年3月15日提交的美国非临时申请15/922,567(现在为美国专利10,489,502)的部分继续申请,该申请是于2018年1月24日提交的美国非临时申请序列号15/879,031的部分继续申请,其又要求于2017年6月30日提交的美国临时申请序列号62/527,441的优先权,这些申请的公开内容通过整体引用明确地并入本文。
背景技术:
3.人工智能(ai)和机器学习(ml)技术的发展使机器能够接管许多手动过程。许多组织通过采用认知技术和ml技术实现不同过程的自动化来在该方向上取得重大的进步。诸如计算机之类的机器拥有与人类员工不同的技能,因为这些机器在精度和一致性方面都很好。然而,在需要上下文理解和复杂通信的任务上,机器往往表现不如员工。因此,移动要由机器处置的一连串重复任务在提高重复任务的效率方面具有优势;然而,当被应用于复杂任务和/或需要上下文理解的任务时,这些机器通常表现很差。
4.组织内的许多过程由文档驱动,这些文档不仅充当这些过程的输入,而且还被用于整理过程的输出。因此,各种任务的自动化可以主要基于任务中涉及的文档的处理。基于纸质文档的许多旧有系统已被数字化并在线移动以实现过程自动化。各种类型的表单或文档被广泛用于这些目的。文档可以包括处理器可读文档,包括具有结构化和非结构化数据以及扫描的图像、照片等的处理器可读文档,在收集和分析其数据以驱动过程自动化之前,这些文档需要由机器进一步处理。
附图说明
5.本公开的特征通过以下附图所示的示例来图示。在以下附图中,相同的数字指示相同的元件,其中:
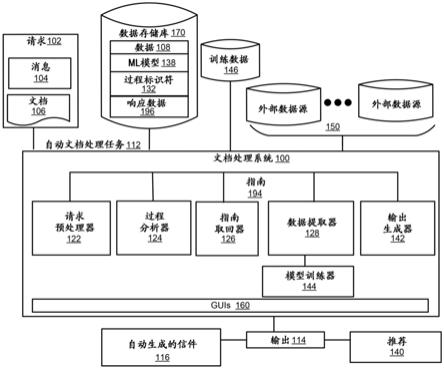
6.图1示出了根据示例的基于ai的文档处理系统的框图。
7.图2示出了根据本文公开的示例的请求预处理器的详细框图。
8.图3示出了根据本文公开的示例的数据提取器的详细框图。
9.图4示出了根据本文公开的示例的输出生成器的框图。
10.图5示出了根据本文公开的示例的详述执行自动文档处理任务的方法的流程图。
11.图6示出了根据本文公开的示例的详述使用多个ml模型提取响应数据的方法的流程图。
12.图7示出了根据本文公开的示例的详述训练多个ml模型来提取数据的方法的流程图。
13.图8示出了根据本文公开的示例的详述管理库存的方法的流程图。
14.图9示出了根据本文公开的示例的与由文档处理系统生成的提供方否认(denial)相关联的示例图形用户界面(gui)。
15.图10示出了根据本文公开的示例的自动生成的提供方否认申诉信件。
16.图11图示了根据本文描述的示例的可以被用于实现文档处理系统的计算机系统。
具体实施方式
17.出于简单性和说明性目的,本公开是通过主要参照其示例来描述的。在以下描述中,许多特定细节被陈述以提供对本公开的透彻理解。然而,将容易明显的是,本公开可以被实践而不限于这些特定细节。在其他实例中,一些方法和结构未被详细描述,以免不必要地混淆本公开。在整个本公开中,术语“一”和“一个”旨在表示特定元件中的至少一个。如本文所使用的,术语“包括(includes)”是指包括但不限于,术语“包括(including)”是指包括但不限于。术语“基于”是指至少部分地基于。
18.根据本文描述的一个或多个示例,描述了一种基于人工智能(ai)的文档处理系统,用于至少基于在执行自动文档处理任务的请求中传达的信息来执行自动文档处理任务。该请求可以包括文本通信、语音通信或其他数据通信,其提供关于并寻求自动文档处理任务的执行的输出或结果的一些标识记号。如果请求是作为语音数据接收的,那么到文本应用编程接口(api)的话音可以被用于获得文本格式的请求。该请求可以附加地包括一个或多个支持文档。该请求通过解析、令牌化并生成令牌的词性(pos)数据来预处理。令牌和pos数据被用于从文档处理系统可以被配置的多个自动文档处理任务标识要被执行的特定自动文档处理任务。在一个示例中,自动文档处理任务可以基于过程标识符来标识,该过程标识符可以通过从请求生成的令牌来确定。在一个示例中,通过预处理请求生成的数据可以被用于标识可以提供过程标识符的一个或多个外部数据源。
19.在标识出要被执行的特定自动文档处理任务时,用于执行的指南(guideline)从一个或多个外部数据源被取回。指南可以包括要求(requirement),诸如用于执行自动文档处理任务的数据要求。多个机器学习(ml)模型被用于提取响应于要求的数据。ml模型中的每个ml模型都对应于相应指南,并且被训练以提取完成指南要求的数据。基于不同算法的不同ml模型可以被训练以提取响应数据。对应于指南的ml模型将取决于响应于该指南的数据类型。在示例中,多个ml模型可以在由主题专家针对多个ml模型中的每个ml模型生成的标注的训练数据上被训练。在示例中,来自历史记录中的不同文档的标注的训练数据包括被标识为响应于给定指南的要求中的每个要求的数据。
20.然后,由多个ml模型提取的响应数据被分析,以用于确定它是否满足阈值条件,该阈值条件又确定了自动文档处理任务的输出。在示例中,阈值条件可以关于要由响应数据满足的指南或要求的最小数量。然而,指南/要求可以被加权。在这种实例中,例如通过聚合由响应数据满足的每个要求的加权分数,批准(approval)分数可以针对响应数据来计算。如果最小批准分数由响应数据实现,则自动文档处理任务被执行以生成第一类型的输出。如果响应数据无法满足要求,并且请求未实现最小批准分数,那么自动文档处理任务被执行以生成第二类型的输出。在一个示例中,因此生成的输出可以包括批准或拒绝该请求的推荐。在一个示例中,包括自动生成的信件的输出也可以由文档处理系统产生,该信件包括
批准或拒绝决定。
21.与常规技术相比,本文公开的基于ai的自动文档处理系统通过实现更准确的数据提取来提供技术改进,从而提供更好的过程自动化。许多过程自动化系统接收某些数据输入,分析接收到的数据并产生某些输出,或者基于对接收到的输入的分析自动执行某些任务。自动执行的任务可以包括但不限于生成推荐或自动向预配置的参与者发出某些通知或通信等。在本文公开的基于ai的文档处理系统中,自动执行的任务还包括自动生成的信件,诸如用于提供方否认的申诉信件。由于所生成的输出取决于所提供的数据输入,因此数据输入的更高准确性确保了更准确的输出。然而,信息可以以各种形式被输入到这些自动化系统,包括图像、文档、数据库、语音文件、视频文件等。从具有多种格式的数据源中准确地提取数据以满足复杂过程指南中的要求(诸如索赔处理、库存管理等)可能是一个挑战。通过采用本文公开的多个ml模型,确保了准确数据是针对该指南提取的。例如,每个ml模型可以被选择和训练,以满足指南中的每个指南的一个或多个要求。事实上,ml模型可以基于要被提取的数据类型来选择以进行训练,以满足指南要求。因此,文档处理系统确保了输入数据的准确提取。因此,诸如推荐、通信、自动生成的信件等输出基于准确的输入信息。在一些实例中,这种输出还可以被用于驱动下游过程/系统,诸如机器人过程自动化(rpa)系统、企业资源规划(erp)系统等。因此,基于ai的文档处理系统确保了准确的数据提取,导致在组织的各个级别进行高效的过程自动化。
22.图1示出了根据示例的基于ai的文档处理系统100的框图。系统100接收关于系统100可以被配置为执行的多个自动化文档处理任务中的一个自动化文档处理任务的请求102。在一些示例中,多个文档处理任务可以包括处理与伤残保险和/或伤亡保险保单相关联的索赔。在另一示例中,诸如处理保险索赔的提供方否认等文档处理任务也可以由系统100作为多个自动化文档处理任务中的一个自动化文档处理任务自动执行。请求102可以经由不同的形态来由系统100接收,包括但不限于电子邮件、消息收发服务、gui、数据存储库、与文档处理系统100相关联的门户、社交网络平台等。请求102可以包括具有特定内容的消息104,并且可以可选地包括与消息104中传达的信息相关联的一个或多个文档106。如果请求102是以书面格式接收到的,那么消息104的文本内容可以被直接提取。然而,如果请求102是以语音/视频格式接收到的,那么来自消息104的文本内容可以使用语音转文本应用编程接口(api)来提取。消息104和文档106可以包括多种信息类型/结构的某些文本内容。消息104和文档106中的一个或多个中的文本内容可以被呈现为具有良好格式化的信息结构(诸如表格、列表、编号列表、缩进的文本内容)的结构化数据或者非结构化数据(诸如逗号分隔值(csv)数据、电子表格等)。例如,如果请求102关于工人的赔偿要求,则消息104可以包括关于提出索赔的一方的细节、索赔标识细节,诸如索赔号、保单号、日期等。与索赔相关联的文献106可以包括索赔人的工作标识、索赔人的医疗记录、来自医疗提供方(诸如医生)的信件等。类似地,如果请求102关于与例如盗窃相关联的伤亡保险索赔,则消息104可以包含描述索赔的文本,包括索赔细节,诸如索赔号、保单号、索赔人名字、与盗窃相关联的地点、索赔人地址等。文档106可以包括警察报告、被盗物品的正式估价、保单文档的副本等。
23.文档处理系统100处理消息104和/或文档106以提取执行由请求102指定的自动化文档处理任务所需的数据108。如果自动化文档处理任务关于处理工人的赔偿或伤亡保险
索赔,则文档处理系统100可以分析来自请求102和一个或多个外部数据源150的信息,以生成关于索赔是否可以被批准的推荐140。外部数据源150可以包括关于实现中的各种保单、保单持有者、与保单相关联的要求以及各种保单持有者的历史交易数据等的信息。外部数据源150可以包括具有结构化或非结构化数据(包括关于特定保单的信息)的数据源。例如,如果自动文档处理任务关于解决工人的赔偿索赔,那么由数据处理系统100访问的外部数据源可以关于数据库,该数据库包括关于工人的赔偿保单和这种保单的订户的信息。类似地,如果自动数据处理任务关于伤亡保险保单,那么由数据处理系统100选择的外部数据源可以包括与伤亡保险保单相关的信息、与保单相关联的指南、这种保单的订户等。因此,一个或多个外部数据源150可以基于从请求102获得的保单细节来选择以用于信息提取。
24.数据处理系统100的各个组件可以访问或生成可以被用于各种用户交互的一个或多个图形用户界面(gui)160。例如,gui 160中的一个gui 160可以被用于传输请求102,而gui中的另一gui显示从请求102提取的数据108。所生成的输出114可以取决于由文档处理系统100执行的自动化数据处理任务。如果自动化文档处理任务112与保险索赔相关,那么输出114可以包括推荐140。如果自动化文档处理任务与索赔的提供方否认相关,则输出114可以附加地包括自动生成的信件116,该信件与必需文献一起对提供方的否认提出申诉。在示例中,信件116随附的文献可以包括从请求102中提取的文档或从外部数据源150获得的文档。基于系统100的给定配置,输出114可以包括其他类型的数据和/或信息。
25.文档处理系统100包括请求预处理器122、过程分析器124和输出生成器142。请求预处理器122处理请求102以获得请求102中所包括的数据108。在示例中,请求预处理器122可以采用诸如但不限于对消息104和/或文档106内所包括的文本进行解析、令牌化和词性(pos)标记等技术。在示例中,文档处理系统100可以被耦合至数据存储库170,以存储在各种自动文档处理任务的执行期间由文档处理系统100生成和使用的信息。因此,由请求预处理器122获得的数据108可以被存储在数据存储库170内。
26.过程分析器124访问由请求预处理器122获得的数据108,以标识要被执行的自动文档处理任务。如上面提及的,数据108可以包括与要被执行的过程相关的过程标识符132。取决于要被执行的自动文档处理任务,一个或多个过程标识符132(例如某些关键字、会员标识符等)。虽然本文中的描述通常将过程标识符132称为启用自动文档处理任务的标识,但是根据本文公开的一些示例,其他过程标识符也可以被使用。在示例中,保单可以关于与工人的赔偿索赔相关联的保险保单。在过程标识符132标识出关于请求102的保单时,指南取回器126取回与该保单相关联的指南194。在示例中,指南194可以从关于该保单的外部数据源150中的一个外部数据源150中取回。因此,不同的保单可能需要从不同的外部数据源取回指南194。在示例中,在执行自动文档处理任务112期间,从外部数据源150中的一个外部数据源150取回的指南194可以被临时缓存在数据存储库170上。指南194可以包括如果自动文档处理任务将被执行则需要被满足的某些数据要求。再次参照工人的赔偿请求示例,对应的指南可以包括对索赔人信息的数据要求,诸如名字、社会保险号、地址、雇主信息、作业类型、受伤日期、受伤性质等。另外,指南194还可以包括对索赔人的临床数据和医疗历史的要求。每个指南194的要求的响应数据196是由数据提取器128使用多个ml模型138从数据108和外部数据源150中的一个或多个中提取的。在示例中,要求和/或指南194中的每一个可以与对应的ml模型相关联,该ml模型被训练以标识响应于要求的信息。例如,如果指南包
括多个要求,那么相应的多个ml模型被用于提取响应于该指南的数据。如果该指南仅包括一个要求,那么单个ml模型可以被用于提取该指南的响应数据。响应信息可以包括由对应的ml模型从不同的数据源采集的多个数据。响应信息可以经由gui 160中的一个gui 160来呈现以进行验证。
27.在示例中,输出生成器142可以被配置为呈现来自数据提取器128的结果以进行验证。输出生成器142还可以被配置为基于响应数据196生成批准或拒绝请求102的推荐,并且信件可以被自动生成以传达输出114。如果请求102关于工人的赔偿索赔或伤亡保险索赔,则输出生成器142可以被配置为确定请求102是否满足某些阈值标准。基于请求102满足阈值标准,批准或拒绝请求的推荐140可以被生成。某些自动动作可以由文档处理系统100在验证响应数据196时执行。这些自动动作可以基于请求102中指定的文档处理任务的类型来执行。在示例中,批准请求102的推荐可以使文档处理系统100产生自动生成的信件116以包括对请求的批准,而拒绝请求102的推荐可以使文档处理系统100产生自动生成的信件116并拒绝该请求102。而且,当自动文档处理任务112关于处理提供方否认时,输出生成器142可以配置为执行的另一自动动作包括产生自动生成的信件116以对提供方否认提出申诉。
28.文档处理系统100还包括用于训练多个ml模型138的模型训练器144。模型训练器144可以采用训练数据146来训练多个ml模型138以提取指南194的响应数据196。在一个示例中,多个ml模型138是经由监督训练方法来训练的。通过从不同的数据源标识出响应于该要求的各种信息,用于监督训练的训练数据146可以针对指南194内的每个要求来生成。实际上,可能发生的是,相同的信息可能以不同的格式被传达。例如,受伤证明可以被提供作为描述受伤的文本或受伤的图像。因此,多个ml模型138中的多个ml模型可以被训练以标识相同要求的响应数据。当处理批准/拒绝阈值时,针对该要求的多个ml模型的贡献可以根据请求102在该要求下被指派的权重来考虑。
29.在标识用于相同条件的不同词语时,标识文本信息的ml模型可以使用上下文数据标识条件等来训练。在示例中,标识关于条件的图像的ml模型可以在从不同的人和不同的角度拍摄的该条件的不同图像上被训练,该图像附有图像关于特定条件的指示。类似地,ml模型可以在训练数据146内可以发生的特定数据类型的多个数据实例上被训练。随着更新的指南和数据要求被添加/更新,或者更新的保险产品被引入,新的ml模型可以被训练,或者现有的ml模型可以根据本文概述的方法被升级,以提取响应于更加新的指南的数据。
30.图2示出了请求预处理器122的详细框图。请求预处理器122可以包括文档提取器202、解析器204、令牌化器206和pos标记器208。文档提取器202提取与请求102相关联的文档。基于自动文档处理任务112,不同文档可以与请求102相关联。当请求102在电子邮件中被接收到时,文档106可以作为附件被传输,或者例如当请求102经由聊天窗口或gui或门户被接收到以上传文档106时,可以作为随附消息被传输。解析器204解析消息104和请求102的文档106中的一个或多个中所包括的文本。令牌化器206可以从解析器204的输出产生词语令牌。令牌可以被进一步处理以移除停止词语、标点等。pos标记器208用pos信息标记令牌中的每个令牌。关于不同的自动文档处理任务的不同保单(例如工人的赔偿)可能具有与伤亡保险的标识符不同的字符串类型的标识符。因此,具有特定字符串类型的保单标识符(充当过程标识符132)可以基于令牌经由模式匹配技术来标识,并且要被执行的自动文档处理任务可以从该特定保单标识符中标识。来自请求预处理器122的令牌以及pos信息使得
能够获得过程标识符132以及诸如过程关键字等其他信息,这些信息允许过程分析器124标识要被执行的自动文档处理任务112。指南取回器126可以选择与自动文档处理任务112相对应的外部数据源150中的一个外部数据源150,以获得关于过程标识符132的细节,诸如关联的指南。
31.图3示出了数据提取器128的详细框图。数据提取器128包括模型选择器302和响应取回器304。所取回的指南194包括各种要求,这些要求将被满足处理请求102。这些要求可以包括用于标识索赔人信息的数据要求、自动文档处理任务112是否关于工人赔偿索赔或健康相关索赔的医疗细节、提供方数据、与索赔相关联的日期、雇主信息等。如果过程标识符132关于伤亡保险索赔,例如财产盗窃,那么指南194可能对索赔人的细节具有离散的数据要求,诸如名字、地址、社会保险号、关于(多个)被盗物品的信息、盗窃发生的日期、盗窃发生的位置、购买被盗物品的日期、关于被盗物品的警察报告的投诉号、被盗物品的图像、标识被盗物品的记号或属性的颜色或其他等。如上面所提及的,某些数据要求可以具有多个响应数据项。响应于数据要求的每个离散数据可以具有被训练为标识该离散数据的多个ml模型138中的对应的ml模型。多个ml模型138可以包括诸如支持向量机(svm)等分类模型、随机森林、诸如k均值等线性分类模型、逻辑回归模型等。基于所确定的响应于特定数据要求的数据的类型,诸如卷积神经网络(cnn)、递归神经网络(rnn)、长短期记忆(lstm)甚或集成模型(ensemble model)等ml模型可以被训练以标识响应数据196。例如,基于cnn的模型可以被训练以标识图像,而作为rnn的特殊类别的lstm可以被用于理解整个段落/句子内的上下文,以确定条件是否需要被呈现给编码器以与特定条件代码相关联。逻辑回归模型可以被训练以提取关于类别变量的数据,其中类别变量至少构成指南中的一个指南的响应数据196的一部分。
32.模型选择器302可以被配置为从多个ml模型138中选择一个或多个ml模型352的子集,以获得在指南194中指定的要求的响应数据196。在示例中,模型选择器302可以被配置为针对给定的离散数据选择对应训练的ml模型。例如,如果数据要求关于社会保险号,则被训练以从请求102或关联的外部数据源150中的一个或多个标识社会保险号的特定ml模型由模型选择器302选择。如果包括特定断骨的x射线的图像数据是要针对要求标识的响应数据,那么被训练以从请求和外部数据源150中的一个或多个标识该特定断骨的图像的ml模型(诸如cnn)可以由模型选择器302选择。
33.响应取回器304在请求102和外部数据源150中的一个或多个上采用ml模型352的子集,以提取响应数据196。在示例中,具有或没有文档106的请求102可以包括所有响应数据196。在示例中,请求102可以是跟进通信,该跟进通信继续关于与自动文档处理任务112相关联的问题的对应关系。例如,请求102可以是关于工人赔偿索赔的提醒。因此,请求102可以包括最小过程标识信息,诸如索赔号。在这种实例中,从请求102中提取的索赔号或其他标识记号可以被用于从一个或多个外部数据源150获得附加信息,这些外部数据源可以存储关于生成响应数据196的请求102的其他所需信息。可以了解的是,可能有来自外部数据源150的对应于请求102的特定数据源。例如,当索赔号对应于工人赔偿索赔时,只有与工人赔偿产品相对应的数据源由一个或多个ml模型352处理。与请求102相关联的元数据(诸如请求102被接收的日期/时间、请求被接收的形态(即,电子邮件、传真传输等)、请求102的发送者、请求102中所包括的(多个)任何名字(如果与请求的发送者不同)等)也可以被用于
确定响应数据196。因此取回的响应数据被传输给输出生成器142,以根据自动文档处理任务112进行呈现。
34.图4示出了根据本文公开的示例的输出生成器142的框图。输出生成器142包括推荐生成器402、数据验证器404和信件生成器406。推荐生成器402包括阈值分析器422和推荐提供器424。如果自动文档处理任务112关于结算保险索赔,则推荐生成器402可以被配置用于基于响应数据196生成批准或拒绝索赔的推荐。阈值分析器422确定批准阈值452是否被满足以生成批准推荐。阈值分析器422可以基于所满足的指南194来分析不同的条件。批准阈值452可以包括计算响应数据的批准分数和针对要被批准的索赔被满足的最小批准分数。批准分数可以包括取决于响应数据196被指派给要求中的每个要求的权重。指南中的要求的总权重可以被指明为批准分数。在示例中,最小批准分数可以由人工审核者根据经验设置。在另一示例中,最小批准分数可以使用系统100或另一设备以编程方式设置。
35.回到工人的赔偿示例,与外部数据源150上的记录中的数据相匹配的诸如索赔人的名字、地址、雇主等数据中的每个数据可以被指派有某些点。另外,所满足的任何医疗要求还可以被指派有某些点。例如,指南194中的一个指南可以与关于索赔人的工作时间段的管理要求相关联,而指南中的另一指南可以与关于索赔人的慢性医疗条件的确认的医疗要求相关。与医疗要求相比,管理要求可以减轻重量。即使针对相同的要求(例如管理要求),正面和负面的响应也可以携带不同的点。因此指派给指南194中的每个指南194的点还可以乘以指南的对应权重,并在指南194上聚合以获得批准分数。基于批准分数与最小批准分数的比较,阈值分析器422确定批准阈值452是否被满足。如果是,则推荐提供器424生成用于批准索赔的推荐,否则用于拒绝索赔的推荐可以被生成。
36.由数据提取器136获得的响应数据196以及推荐140可以经由由数据验证器404生成的验证gui 454来呈现以用于验证。在示例中,验证gui 454可以以可编辑的格式呈现来自响应数据196的一个或多个离散数据项,使得进行验证的人工审核者可以对数据进行任何必要的改变。在示例中,验证gui 454可以包括两个部分,其中所提取的数据是在第一部分中呈现的,并且从请求102或数据被提取的外部数据源获得的原始数据源的对应视图(诸如文档、数据库表格或图像等)可以被显示在第二部分中。在示例中,验证gui 454还可以包括批准或拒绝与请求102相关联的索赔的推荐140。人工验证者可以同意或不同意推荐140。来自人类验证者的反馈(包括对响应数据196的任何编辑)可以被提供给文档处理系统100,以进行进一步训练。
37.输出生成器142附加地包括文档生成器,诸如信件生成器406,其可以针对某些自动文档处理任务(诸如提供方否认)而被激活。当医疗保险索赔(例如工人的赔偿索赔)被否认时,自动文档处理任务112可以关于分析否认。如果文档处理系统100如本文所公开的那样在分析指南194和响应数据196时生成撤回否认的推荐140,则自动信件生成器406可以被激活以自动生成申诉信件,即,自动生成的信件116对否认进行申诉。在示例中,自动生成的信件116可以通过将来自响应数据196的一个或多个数据项替换为信件模板来生成。
38.图5示出了根据本文公开的示例的详述执行自动文档处理任务112的方法的流程图500。该方法开始于502,接收用于执行自动文档处理任务112的请求102。该请求102包括诸如消息104和文档106中的一个或多个等信息。该请求102在504中被预处理以提取文档106(如果有的话),并且获得诸如令牌或pos标记等数据108。在506中,因此提取的数据108
被分析以获得过程标识符132。过程标识符132被用于标识要被执行的过程。在示例中,数据108可以包括过程标识符132,该过程标识符132可以在508中被用于确定要被执行的自动文档处理任务112。
39.包括对自动文档处理任务112的执行的要求的指南194在510中被检索。在示例中,指南194可以包括针对特定方案下的所有保单的要求。然而,指南194也可以包括特定于由过程标识符132表示的保单的数据要求。例如,在执行自动文档处理任务112必不可少的某些数据要求未在早先通信中被提供的实例中,对指南194的保单特定数据要求可以以编程方式或经由人工审核者来添加。在512中,指南194的响应数据196是至少使用多个ml模型138的子集从请求102和外部数据源150中的一个或多个中提取的。所选的ml模型子集中的每个子集被训练以提取响应于指南194中的一个指南194的数据。在514中,响应数据196被评估以确定它是否满足或满足用于确定自动文档处理任务112的输出的批准阈值452。如果自动文档处理任务112关于保险索赔,则批准阈值452可以表示由索赔取得的一定分数,该分数导致索赔有资格被批准。如果响应数据196满足批准阈值452,则自动文档处理任务112(诸如生成批准与请求102相关联的索赔的推荐)在516中被执行。自动生成的信件116可以在520中被产生以包括索赔批准/不批准。例如,包括索赔批准的第一自动生成的信件或包括索赔拒绝的第二自动生成的信件可以在520中被产生。类似地,在批准阈值452在诸如提供方申诉等实例中由响应数据196满足时,申诉信件可以被自动生成。
40.如果在514中确定批准阈值452未被满足,那么关于拒绝与请求102相关联的索赔的推荐的输出114可以在518中被产生,以推荐索赔否认。在提供方申诉的情况下,当响应数据196未能满足批准阈值452时,对提供方否认提出申诉的自动生成的信件116不会被产生。
41.图6示出了根据本文公开的示例的详述使用ml模型352的子集提取响应数据196的方法的流程图600。尽管该方法描述了为数据提取而串行地应用ml模型,但是可以了解的是,这仅出于说明的目的,并且ml模型352的子集可以被同时(例如并行地)用于数据提取。在602中,与指南194中的每个指南194相对应的多个ml模型138被访问,这些ml模型138被训练以标识响应于指南194的要求的数据。在604中,指南194中的一个指南194被选择以进行处理。在606中,被训练以提取响应于所选的指南的数据的(多个)对应ml模型被进一步选择。例如,如果所选的指南包括对多于一个数据项的要求,那么多于一个ml模型可以在606中被选择以提取数据。在示例中,模型选择器302可以存储诸如表格等数据结构,该数据结构指定要针对给定指南选择的(多个)ml模型,并且选择可以根据表格中的信息来执行。每次要求以及与该要求相关联的ml模型中的一个或多个被更新时,表格都可以被对应地更新。在608中,所选的(多个)ml模型被应用于请求102和外部数据源150中的一个或多个,并且响应于要求的数据被获得。在610中,确定是否还有更多指南要被处理。如果是,则该方法移动到604以选择处理器的下一指南。如果在610中确定没有更多的指南用于处理,则该方法在结束框中终止。
42.图7示出了根据本文公开的示例的详述训练多个ml模型138来提取数据的方法的流程图700。在702中,对应于指南194中的一个指南194的多个ml模型138中的一个ml模型138被访问。指南194中的每个指南194可以具有多个ml模型138中的对应的一个或多个ml模型138,这些ml模型138被训练以基于预计的数据类型来提供响应于指南的数据。如果指南预计文本数据采用特定模式,诸如社会保险号、日期、保单号等,那么适合于文本数据预测
的分类ml模型可以被选择,并且被训练以标识特定模式下的文本数据。如果指南要求图像数据被标识,那么图像分类ml模型(诸如cnn、深度学习网络(dln)等)可以被使用。在某些其他示例中,基于两个或多个ml算法的集成模型也可以被采用。因此,针对多个ml模型138中的每个ml模型138的大量训练数据(对应于要由ml模型预测的数据类型)需要被生成。在704中,在与文档处理任务112类似的先前文档处理任务期间采集和/或生成的数据可以被访问。例如,关于先前批准、结算或拒绝的保险索赔的文档可以被数字化(即,被扫描并且使得文本机器可读和机器可搜索),并且被用于生成训练数据146。因此生成的训练数据146可以被拆分为训练数据和测试数据。所收集的数据被用于训练多个ml模型138,并且测试数据可以被用于测试训练后的ml模型。通常,所收集的数据被分区,使得80%的数据为训练数据,而20%的数据被用于测试训练后的模型。
43.训练数据在706中被标注为对指南的准确或不准确的响应,并在708中被提供以训练ml模型以用于监督学习。在710中,训练后的ml模型是利用测试数据准确测试的。在712中确定足够水平的准确性是否被实现。如果足够的准确性被获得,则训练后的模型由文档处理系统100用作多个ml模型138中的一个ml模型138,以在714中进行数据提取,否则,在716中,ml模型被进一步训练并且其准确性被再次确定。该循环可以被重复,直到ml模型的满意准确性被实现为止。
44.文档处理系统100可以被用于在诸如保险公司、医院、药房等不同组织中执行各种自动文档处理任务。可以由医院、医生办公室等中的文档处理系统100执行的自动任务中的一个自动任务包括库存管理。
45.图8示出了根据本文公开的示例的详述通过执行库存管理任务管理库存的方法的流程图800。文档处理系统100接收请求102,该请求102可以与关于库存中的产品(例如注射器或其他医疗设备)的订单大小的查询相关。在804中,关于库存查询和与查询相关联的产品的数据108由请求预处理器122从请求102中提取。来自请求预处理器122的令牌、pos标记和其他输出由过程分析器124访问,以在806中使用例如产品id或产品代码来确定自动文档处理任务112关于获得在请求102中指定的产品的需求推测。过程分析器124可以使用诸如不限于自然语言处理(nlp)等技术来分析请求预处理器122的输出并标识要被执行的过程。用于执行获得产品的需求推测的过程的指南194在808中使用产品id来取回。指南194可以包括对由产品id标识的产品的当前库存水平的要求以及基于当前要求在预定时间段内对产品的预期需求的预测的要求。因此,诸如数据库访问脚本、ml模型等不同编程构造可以被用于获得针对指南194的响应数据196。当前库存水平或存货水平可以经由针对库存数据库运行查询来获得,而被训练以预测产品的预期需求的一个或多个ml模型352的子集是在810中从多个ml模型138中选择的。包括产品的当前库存水平和产品的预期需求的响应数据196在812中被获得。基于诸如但不限于时间序列、线性回归、特征工程和随机森林等方法的ml模型可以被训练以使用当前要求来推测产品的预期需求。鉴于当前库存水平,在814中产生的推荐140可以包括要被订购以满足预期需求的产品数量。
46.图9示出了示例gui 900,根据本文公开的示例,该示例gui 900可以是由文档处理系统100生成的用于与提供方否认相关联的自动文档处理任务的gui 160。gui 900包括可以跨针对各种文档处理任务生成的gui 160被共同实现的某些特征。这些特征可以包括左侧(lhs)面板902,其提供对从与提供方否认文档处理任务相关地接收和处理的各种文档中
提取的信息的不同区段的访问。例如,这些区段可以包括索赔历史922、被否认的细节924和临床审核926。由于gui 900关于提供方否认过程,因此如果推荐140建议提供方否认是不正确的,或者如果人类验证者将提供方否认视为不正确的,则lhs面板902上的生成信件按钮952可以被激活,以自动生成对否认提出申诉的信件。gui 900还包括右侧(rhs)面板904,其基于在lhs面板902中做出的选择来显示相关信息。在示例中,通过相关信息被提取的原始文档或原始数据源,相关信息可以在rhs面板904中被示出。而且,rhs面板904可以突出显示与文档处理任务相关联的实体的不同属性942。gui 900显示与提供方否认过程相关联的订户的属性942,诸如但不限于订户id、姓氏、名字、医保号、电话号码、出生日期等。因此,伴随请求的文档106的可搜索表示被生成,并被显示在gui 900上。
47.图10示出了根据本文公开的示例自动生成的提供方否认申诉信件1000。申诉信件1000包括患者细节区段1002,该区段将自动填充从患者文件或文档中采集的属性942。除了诸如患者名字、出生日期、会员id等一般属性外,关于与诸如医院、服务日期、账单金额等否认事项相关的特定服务的特定细节也被包括在患者细节区段1002中。在示例中,信件的模板可以被存储在数据存储库170中的一个数据存储库170中,或者外部数据源150可以被取回。模板包括预定或标准语言,以标准语言内的占位符对提供方否认提出申诉,以至少接收从请求102和外部数据源150中的一个或多个中提取的响应数据的子集。例如,患者细节区段1002可以包括这种占位符,这些占位符以从请求102和/或外部数据源150中取回的对应患者细节完成。在示例中,与占位符相对应的令牌可以使用命名实体标识(ner)、来自响应数据196的令牌来标识,并且信件1000被生成,其中令牌被插入或包括在对应的占位符中。
48.信件1004的正文包括患者否认的服务的细节以及由文档处理系统100标识的相关信息,其中作为撤回否认的原因中的一个原因,66岁的john被归类为50岁。再次,模板可以包括可以被配置有脚本的占位符,以接收相关的患者细节。当人类审核者按下提交按钮1006时,否认申诉信件1000将被提交给健康计划提供方。
49.可以了解的是,尽管自动生成的信件116在本文中被描述为其中插入了数据的文档,但是自动生成的信件的其他示例可以包括以数字或硬拷贝形式包含相关信息的任何文档、文件等。
50.除了上述的自动化文档处理任务之外,文档处理系统100可以在不同领域中被用于自动执行各种文档处理任务,如下面概述的。
51.本发明的实施例可以被配置为解决诸如提供方索赔和争议等健康支付者用例。例如,文档处理系统100可以被配置为审核提供方争议和索赔。例如,来自索赔否认的提供方响应可以被审核以进行裁决。如上所述,用于提供方否认的申诉信件或其他信件可以被自动生成。文档处理系统100的另一健康支付者应用可以包括提供方数据管理。例如,文档处理系统100可以被配置为鉴于维护、终止或添加新的提供方数据所需的文档,诸如医生、护士、实验室技术员等的数据。请求102中的消息104可以包括特定关键字,诸如但不限于“维护”、“终止”或“添加”新的提供方数据,这些新的提供方数据可以在消息104或文档106中的一个或多个中被指定。在取回特定过程的指南194并且提取响应数据196时,外部数据源150中的对应信息可以被更新。
52.在一些示例中,文档处理系统100可以被用于解决健康提供方用例,诸如开始和医疗保健有效性数据和信息集(hedis)图表审核。雇主和个人使用hedis来测量健康计划的质
量。hedis测量健康计划如何为会员赋予服务和护理。除了评估医疗保健计划外,文档处理系统100还可以被配置为审核医疗记录和七级健康(hl7)消息以用于质量度量。国际hl7指定了各种医疗保健系统可以彼此通信的许多灵活的标准、指南和方法。这种指南或数据标准是允许信息以统一且一致的方式被共享和处理的规则集合。这些数据标准旨在允许医疗保健组织轻松共享临床信息。再次,请求102可以包括医疗记录和/或hl7消息,同时质量度量(即,指南194)可以从外部数据源150来取回。文档处理系统100可以针对在质量度量中指定的要求提取响应数据196,并生成关于医疗记录或hl7消息是否满足质量度量要求的推荐140。
53.文档处理系统100还找到了在风险调整图表审核中的应用。例如,文档处理系统100可以被配置为审核医疗记录和/或hl7消息。指南194可以包括确定是否风险调整补偿被接收到的要求。基于由数据提取器128取回的响应数据196,输出114可以包括关于是否风险调整补偿被接收到的推荐。
54.在健康提供方用例中的文档处理系统100的另一应用包括使用管理文档摄取。文档处理系统100可以被配置为执行授权表单的索引,以进行先前、后期和同时的审核。
55.文档处理系统100也可以被用于将非结构化数据重构为电子医疗记录(emr)。emr通常包含一般信息,诸如关于患者的治疗和医疗历史。通过实现emr,患者数据可以在较长的时间段内由多个医疗保健提供方追踪。非结构化的数据和文档可以使用文档处理系统100被重构为emr配置文件。
56.文档处理系统100可以被配置用于临床编码/开单以审核国际疾病分类(icd)10代码(或icd 9代码,以适用者为准)和收费标志。icd
‑
10代码被分解为章节和子章节,并在小数点左边包括字母加两个数字,然后在右边加一个数字。新系统允许进行更具体的诊断。当医疗服务提供方向保险提交账单以进行补偿时,每个服务均由通用程序技术(cpt)代码描述,该代码与icd代码相匹配。文档处理系统100可以在请求102中接收提供方的账单。数据108是从请求102中提取的。指南194包括要求,其中来自请求102中的账单的cpt代码与对应的icd代码对准。如果两个代码无法彼此正确地对准,则推荐可以被生成以拒绝付款。换言之,如果该服务不是通常为具有该诊断的人提供的服务,则保险将不予支付。因此,文档处理系统100可以分析代码并使测试与诊断相关以确保正确的补偿。如果有任何差异,则补偿可以被否认,并且此时提供方否认过程可以被激活。
57.文档处理系统100可以被配置为处理健康的社会决定因素来隔离决定因素以改进健康结果。
58.文档处理系统100可以被配置用于精密医学中来隔离决定因素以获得更好的健康结果,并基于低至基因组水平的可用临床数据为个体提供定制的治疗。
59.文档处理系统100的非临床应用可以包括如上所述的用于预报医疗用品使用的供应链管理、保险凭证、自动索赔处理、抵押/贷款申请处理、保险数据管理等。例如,文档处理系统100可以被配置为对授权表单执行临床审核,以进行先前、后期和同时的审核。
60.文档处理系统100可以在汽车行业中被使用,以审核所提供的支持汽车保险索赔的信息。请求102可以包括与汽车保险索赔相关的信息和文档。基于在请求102中传达的信息,如本文公开的那样,过程标识符132以及指南194被取回。数据提取器128可以使用多个模型138来提取响应数据196,该模型138可以如上所述在先前的汽车保险索赔数据上被训
练。取决于响应数据196是否满足批准阈值452,推荐140可以建议批准或拒绝汽车保险索赔。
61.文档处理系统100可以被配置为审核文档以支持又一非临床应用中的贷款或抵押申请。基于在请求102中传达的信息,该信息可以包括支持贷款/抵押申请的文档106,如本文所公开的,指南194是使用ner和nlp中的一个或多个来取回的。数据提取器128可以使用多个模型138来提取响应数据196,该模型138可以如上所述在先前的贷款/抵押数据上被训练。取决于响应数据196是否满足批准阈值452,推荐140可以建议批准或拒绝贷款/抵押申请。
62.文档处理系统100可以被配置用于管理与用例中的保险保单、申请和索赔相关的结构化和非结构化信息。
63.文档处理系统100的另一用例可以包括标识保险索赔中的潜在欺诈。
64.文档处理系统100可以被配置用于从非结构化文档中提取数据,并将其变换为证据,以便在又一用例中进行决定。如果请求102包括非结构化数据形式的消息104和文档106中的一个或多个,则请求预处理器122和数据提取器128可以被配置为提取响应数据196,这使得能够基于满足指南194中的要求的响应数据196生成关于请求102的推荐140,该指南194提供了对存在或不存在真实证据的要求。
65.文档处理系统100还找到了在临床研究和患者匹配领域中的应用。文档处理系统100可以被配置用于挖掘科学著作并匹配适当的患者以进行临床试验。如果请求102包括消息104和关于患者的文档106中的一个或多个。用于临床试验的标识符可以被提取以取回用于为临床试验选择患者的指南194。关于患者中的每个患者的响应数据196可以使用在指南194中概述的要求的多个ml模型138从以下一项或多项被提取:外部数据源150或与请求102一起提供的信息。多个ml模型138可以在先前的患者记录上被训练,以标识患者记录内的条件,这些条件会使患者成为特定临床试验的良好候选。数据与通过批准阈值452确定的要求相匹配的那些患者可以由输出生成器142推荐用于临床试验。
66.法规遵从形成文档处理系统100的又一用例。具体地,文档处理系统100可以被配置为在可以在请求102中接收的法规文档内查找、突出显示和提取关键数据。指南194可以指定法规遵从的要求。数据提取器128可以采用多个ml模型138,其被训练以根据要求提取响应数据196。因此,关键数据(即,响应数据196)可以从法规文档中提取。
67.文档处理系统100的其他用例包括精密医学、药物发现和药物警戒。
68.在精密医学领域中,文档处理系统100可以被配置用于基于低至基因组水平的可用临床数据为个体提供定制的治疗。
69.通过使用nlp提取先前发现的化学反应来评估实验需求,文档处理系统100可以被配置用于药物发现。
70.作为用于药物警戒的应用,文档处理系统100可以被配置用于在药物开发过程的早期标识潜在的安全机会,并实现更快的药物不良反应(adr)和医疗设备报告(mdr)确定和改进的安全配置文件。
71.文档处理系统100的其他临床用例包括处理赔偿和退休金、医疗研究、医疗记录处理等。
72.文档处理系统100可以被配置为审核与请求102一起提供的临床信息,包括消息
104和文档106中的一个或多个,以确定赔偿和退休津贴。包括针对赔偿和津贴要满足的要求的指南194被取回。响应数据196是从由消息和一个或多个外部数据源150提供的信息中提取的。基于由响应数据196满足的(多个)阈值,候选的赔偿和津贴可以在推荐140中提供。
73.文档处理系统100可以被用于医保和医疗补助服务中心、军事健康系统等的医疗记录处理以及在用例中用于风险调整数据验证。文档处理系统100可以被配置为审核医疗记录以在例如医保和医疗补助服务中心(cms)、军事健康系统等中进行处理。此外,文档处理系统100还可以被用于风险调整数据验证(radv)。用于审核医疗记录的请求102由文档处理系统100接收,并且医疗记录可以与请求102一起接收或者可以基于请求102中的信息从外部数据源150访问。如本文所描述的,用于审核医疗记录的指南194被取回,并且响应数据196是使用多个ml模型138来提取的。医疗记录可以基于本文讨论的批准阈值来审核,以确定它们是否满足指南194中的要求。
74.文档处理系统100的非临床使用可以包括诸如采购、客户参与等功能。
75.文档处理系统100可以被配置为审核文档和合同条款以推荐购买决定。请求102可以包括诸如产品列表、价格等信息。指南194可以包括合同条款,并且数据提取器128从请求102中提取响应数据196。如果响应数据196与由批准阈值452指示的合同条款(即,指南194)所陈述的要求相匹配,那么购买产品的推荐可以由输出生成器142生成。如果响应数据196未能与指南194所陈述的要求相匹配,那么针对购买产品的推荐可以由输出生成器142生成。
76.文档处理系统100可以被配置有语音转文本api,使得请求102不仅可以以文本/文档格式被接收,而且也可以作为语音消息被接收。nlp处理可以对从语音消息中提取的文本实现,以处理客户津贴请求和问题。
77.图11图示了可以被用于实现文档处理系统100的计算机系统1100。更具体地,可以被用于生成或访问对应于非结构化文档及其组成文档的不可编辑的文件的计算机器(诸如台式计算机、膝上型计算机、智能手机、平板计算机、可穿戴设备等)可以具有计算机系统1100的结构。计算机系统1100可以包括未示出的附加组件,并且所描述的一些组件可以被移除和/或修改。在另一示例中,计算机系统1100可以在外部云平台上被实现,诸如但不限于亚马逊web服务、云或内部公司云计算集群或组织计算资源等。
78.计算机系统1100包括(多个)处理器1102(诸如中央处理单元、asic或其他类型的处理电路)、输入/输出设备1112(诸如显示器、鼠标键盘等)、网络接口1104(诸如局域网(lan)、无线802.11x lan、3g、4g或5g、移动wan或wimax wan)以及计算机可读存储介质1106。这些组件中的每个组件可以被可操作地耦合至总线1108。计算机可读存储介质1106可以是参与向(多个)处理器1102提供指令以供执行的任何合适的介质。例如,计算机可读存储介质1106可以是非瞬态或非易失性介质(诸如磁盘或固态非易失性存储器)或者易失性介质(诸如ram)。存储在计算机可读介质1106上的指令或模块可以包括由(多个)处理器1102执行以执行文档处理系统100的方法和功能的机器可读指令1164。
79.文档处理系统100可以被实现为具有由一个或多个处理器执行的处理器可执行指令的存储在非瞬态计算机可读介质上的软件。例如,计算机可读介质1106可以存储诸如mac os、ms windows、unix或linux等操作系统1162以及用于文档处理系统100的代码或机器可读指令1164。操作系统1162可以是多用户的、多处理的、多任务的、多线程的、实时的等。例
如,在运行时间期间,操作系统1162正在运行,并且文档处理系统100的代码由(多个)处理器1102执行。
80.计算机系统1100可以包括数据存储装置1110,其可以包括非易失性数据存储装置。数据存储装置1110存储由文档处理系统100使用的任何数据。数据存储装置1110可以被用于存储与由文档处理系统100执行的过程相关联的实时数据,诸如接收到的请求、要被执行的各种自动文档处理任务、最初从请求中提取的数据108、ml模型138、响应数据196、推荐和自动生成的信件等。
81.网络接口1104例如经由lan将计算机系统1100连接至内部系统。而且,网络接口1104可以将计算机系统1100连接至互联网。例如,计算机系统1100可以经由网络接口1104连接至web浏览器以及其他外部应用和系统。
82.本文已经被描述和图示的是示例及其一些变型。本文使用的术语、描述和附图仅以说明的方式被陈述,并且并不意味着限制。在主题的精神和范围内许多变型是可能的,其旨在由以下权利要求及其等效物来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1