一种通过三维测量技术测算汽车行驶速度的方法与流程
本发明涉及智慧交通技术领域,具体为一种通过三维测量技术测算汽车行驶速度的方法。
背景技术:
车辆的运行速度测量是智能交通领域的热点之一,目前常用的测速方法主要采用硬件装置,如地感线圈测速,在间隔一定距离的路面下埋设地感线圈,利用已知距离和车辆经过的时间计算车速,又如激光雷达测速,利用激光反射的时间差计算目标距离,再通过距离差来计算其运动速;
无论是雷达还是地感线圈,由于其测速原理的限制,监控的往往只是一个相对固定且范围较小的区域,又由于硬件设施的价格较高,实际中这些设施也往往只安装在主要路口、高速卡口等重点位置。
技术实现要素:
本发明提供一种通过三维测量技术测算汽车行驶速度的方法,可以有效解决上述背景技术中提出无论是雷达还是地感线圈,由于其测速原理的限制,监控的往往只是一个相对固定且范围较小的区域,又由于硬件设施的价格较高,实际中这些设施也往往只安装在主要路口、高速卡口等重点位置的问题。
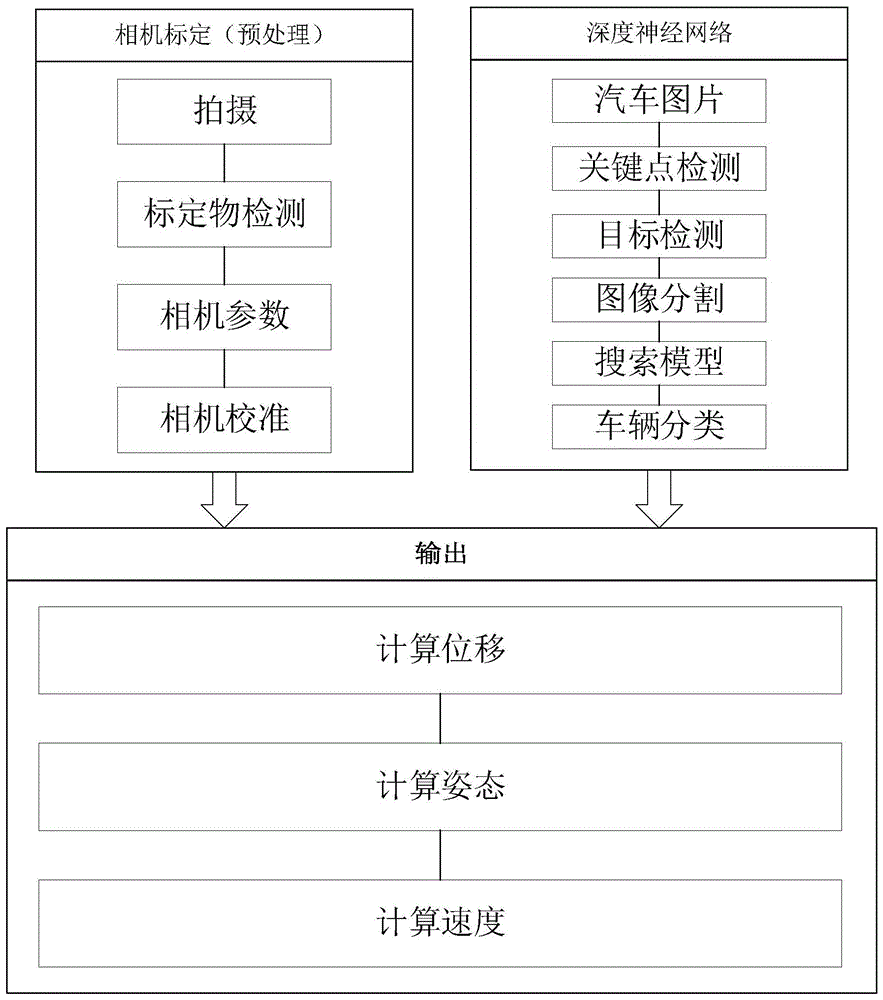
为实现上述目的,本发明提供如下技术方案:一种通过三维测量技术测算汽车行驶速度的方法,包括如下步骤:
s1:前期准备:需要准备一台相机,一台汽车,一个特定标定物,一个包含不同种类汽车的三维模型库;
s2、关键点检测技术;
s3、验证关键点;
s4、计算汽车速度。
根据上述技术方案,所述s1的具体步骤如下:
a1、将标定物部署在待测区域上;
a2、利用相机对标定物进行拍照并选定图片上一个固定点o作为三维坐标原点;
a3、测量出标定物上的角点的三维坐标;
a4、通过角点检测技术对图片中的标定物进行角点检测,从而得到每个角点的二维坐标;
a5、将标定物角点的二维坐标与其三维坐标对应起来,利用相应的标定技术,可以计算出相机的内参数矩阵、外参数矩阵和畸变矩阵;
a6、在汽车三维模型库中,对每辆车选定汽车上的n个特定点作为关键点p={p1,p2,p3,...,pn},并测量每个点的三维坐标。
根据上述技术方案,所述s2中该步骤具体流程如下:
b1、利用相机拍摄一段待测汽车在o点附近行驶的视频;
b2、对视频进行截图,从而得到一系列图片,每张图片中必须包含o点;
b3、利用上一步得到畸变矩阵对每张图片进行校正;
b4、使用分类网络对每张图片上的每辆汽车进行检测以及分类,记录下类别;
b5、使用关键点检测网络对每张图片的每辆车进行关键点检测,得到每个关键点的二维坐标;
b6、使用图像分割网络对车辆区域进行分割,得到车辆的掩膜(mask);
b7、通过上一步得到的每一辆车的类别,将每辆车的关键点的二维坐标与该类别下的三维模型的关键点三维坐标进行匹配,找到误差最小的模型,该模型即为该车的近似三维模型;
b8、通过结合该模型掩膜图像,以关键点的二维和三维坐标,及得相机的内外参数矩阵,利用姿态估计算法得到当前该车的姿态信息和该车的三维坐标信息。
根据上述技术方案,所述s3该步骤具体流程如下:
c1、通过上一步骤得到的汽车的姿态信息,估算该姿态下的关键点是否为可见点;
c2、根据关键点是否可见,评估上一步骤得到的关键点信息是否可信,若不可信,则返回上一步骤,若都不可信,则选择只依赖分割的车辆掩膜图像匹配姿态。
根据上述技术方案,所述s4该步骤具体流程如下:
d1、利用追踪网络,对每张图片的每辆车进行识别并对所有的检测框进行匹配,得到不同图片的同一辆车;
d2、由于图片是截取是包含有时间顺序的,并且时间间隔是已知的,得到不同图片的同一辆车再根据以上信息,可以得到每辆车的运行轨迹,也就是汽车的位移;
d3、根据图片之间的时间间隔和位移数据,从而可以计算出在该视频时间内,汽车的平均速度。
根据上述技术方案,所述s1中标定的目的是为了求出相机的内参数(k)、外参数(m)和畸变参数,由于每个镜头的畸变程度都不相同,需要通过标定来获取特定镜头的相关参数来对其拍摄的照片进行校正,而校正的结果直接影响到后续工作的精度;
标定的具体流程如下:
标定板角点检测,该检测直接影响到获取参数的精度,而得到角点c的原理,若c为理想的角点位置,p为其邻域的一个点,并且该点的梯度向量为gp,则可以满足
在本步骤还提到三维模型库,可以通过网络收集或者实车进行三维重建等操作,得到大量车辆的三维模型,其应该包含常见车辆类型的模型,并且每个类别可以有多种品牌的不同车型的模型,模型库越全面,最终得到的速度信息越准确,
根据上述技术方案,所述s2中提及到三个神经网络,分别是分类网络和关键点检测网络,该步骤得到的关键点位置信息为二维坐标信息,将其与相应点的三维坐标进行对应才可以进行下一步骤的姿态估计;
姿态估计算法的姿态即为当前目标在三维坐标中的一系列三维信息,当前目标的三维旋转角度(俯仰角、方位角、翻滚角)信息;
还需要上一步得到的相机的外参数矩阵m;具体流程如下:
选取n个关键点,例如车前窗的2个边角,后窗的2个边角,发动机的2个边角,车轮等特定的点,测量这些选定的点的三维坐标并与其通过相机拍照的图片上的可见点的二维坐标对应上;
投影误差可以定义为以下公式:
其中θ向量为物体的姿态矩阵,n为关键点的个数,
其中k为相机投影矩阵,m为姿态矩阵,θr为旋转向量,其顺序为:z→y→x,θt为平移向量,将上一步的误差公式作为损失函数,选定优化器adam来对以上损失函数进行迭代,经过一段时间的迭代之后,得到使得误差j最小的姿态矩阵θ,即:
θ*=argmin(j(θ))。
根据上述技术方案,所述s3中考虑到车辆的种类繁杂,车型相近,网络得到的数据需要得到的一定程度的验证,该步骤采用的方法为,由于车辆的姿态,呈现在图片的情况,不会是所有的关键点都是可见点,通过关键点检测的到的点得到的模型姿态在反推该点是否可见,如果两者矛盾,即可判别该关键点是否可信。
根据上述技术方案,所述s4中通过深度学习技术训练卷积神经网络,该网络分为三个部分,一个部分为检测网络,可以在图片中找到相应的目标检测框,在这一部分中,车辆的检测框信息可以由上文提及的分类网络给出给类别的时候一同提供该车辆的检测框位置;第二部分为分割网络,用于提取第一部分的检测框中的车辆掩膜;第三部分为匹配网络,利用前两个网络提取出的图像特征,由于不同对象之间的关联度会比统一对象的关联度,通过设置阈值可以找出不同图片中的同一车辆。
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,通过相机拍摄能够快速获的汽车的行驶速度的方法,操作简单便捷,适用范围广,适合其更好的推广使用。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明实例的整体流程示意图;
图2是标定物示意图;
图3是车辆三维模型示意图;
图4是汽车关键点示意图;
图5是汽车掩膜点示意图;
图6是汽车检测框分类示意图;
图7是汽车关键点估计与误差示意图;
图8是汽车掩膜估计与误差示意图;
图9是汽车姿态估计示意图;
图10汽车位移及速度示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例:如图1所示,本发明提供技术方案,一种通过三维测量技术测算汽车行驶速度的方法,包括以下步骤:
通过监控摄像头a得到一张汽车a的图片,该图片需要包含标定物、汽车a、三维坐标原点o;
通过网络搜集不同种类的汽车三维模型,并将其缩放至车辆实际大小;
选定汽车的关键点,分别为前挡风玻璃的4个边角、后挡风玻璃的4个边角,左右两个后视镜,和汽车车头左右最外沿两个点和车位最外沿两个点,关键点示意图见图4;
通过标定技术对标定物进行检测和计算相机的内、外参和畸变参数;
通过监控摄像头a得到待测汽车b和待测汽车c的时长为1分钟的行驶视频,并将视频每隔10秒截取一次图片,得到6张图片;
将图片分别进行畸变校正;
将6张图片分别经过神经网络模型,得到每辆汽车的关键点位置、掩膜,和分类结果,见图4,5,6,7,8;
将6张图片分别经过神经网络模型,得到每辆汽车的关键点位置、掩膜,和分类结果,见图4,5,6,7,8;
使用姿态估计算法,根据获取到的相机参数和关键点二维信息、车辆的三维关键点信息、车辆的三维模型,计算当前模型的姿态,姿态示意图见图9;
将6张图片上的检测框按照视频时间顺序分别输入检测框匹配网络模型中进行匹配,根据匹配度的高低进行筛选,阈值设置为0.5;
根据匹配结果,以及每个检测框的汽车的三维坐标,计算每两张图片之间汽车的位移,由于截图间隔为5秒,根据位移和时间,可以计算汽车在该段时间内的平均速度,位移示意图见图10;
根据6张图片得到每辆车的5个平均速度,可以计算出待测汽车在整个视频时间内的速度。
上述步骤的第1步,将棋盘格贴在纸箱上,测量每个角点的三维坐标,标定方法使用opencv库提供的aruco方法,该方法,标定物检测示意图见图2;
上诉步骤的第4步,关键点的选取应该是其本身具有一定特点并且最好是同种类车中都具有的点;
上述步骤的第6步,畸变校正采用opencv库的undistort方法;
上述步骤的第7步,将流程中的分类网络和关键点检测网络合并,网络在检测车辆的同时将关键点也检测出来,通过cascadercnn网络可以实现,本方法采用detectron2框架的实现;在训练过程中,需要大量的车辆图片和关键点的标注;
上述步骤的第8步和第9步,关键点的验证需要对每一个可能的模型计算一次姿态估计,然后根据姿态信息来逆向评估该关键点是否可行;
上述步骤的第10步,检测框的匹配,采用多目标追踪(mot)网络模型的匹配部分模型re-id,在经过一段时间的训练之后,其网络模型能够给出输入检测框之间的匹配度,选取大于0.5的最高匹配度的对应框为其对应框,由此则可以得到一辆车在不同图片的不同位置,再结合上一步得到的车辆的三维坐标即可得到该车在间隔时间内的位移;
上述步骤第11步,计算的是两张图片之间的车辆的位移,由于截图间隔是已知且固定的,所以顺序不可混乱,否则计算的速度是非常不准确的,截图间隔时间越短,速度的精确度越高。
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!