基于深度神经网络和注意力机制的手势识别方法
1.本发明属于电子信息领域,是一种基于深度神经网络和注意力机制的手势识别方法,通过该方法可将普通摄像头拍摄到的手势视频数据归类为对应文本含义。
背景技术:
2.手势是人际交往的重要组成部分,也是一种重要的人机交互(human computer interaction,hci)方式。通过检测人体手势可以帮助机器更好的理解人体指令,进而完成相应辅助任务。例如,在智能家居环境中就可以通过手势动作控制空调的开关、切换电视屏道;智能驾驶过程中也可以通过手势动作控制汽车内部的一些功能,进而让驾驶员把更多注意力集中于道路本身、降低交通事故的发生。
3.目前手势识别方法的研究多通过深度传感器或特殊体感设备完成。例如,可以通过数据手套和电极腕带捕获人体手势的运动数据,然后再将该数据传输到计算机的手势识别系统获取对应的手势分类。该类方法虽然具有更好的精准性和稳定性,却需要昂贵的设备;另外,对特定设备的依赖也导致了手势交互环境的限制,因此该类方法只能适用于特殊场景,并不能满足大多数场景下的手势识别任务需求。
4.基于普通摄像机的视觉手势识别方法具有适用性广、成本较低等优点,并且在许多公共空间也配有监控摄像机,交互环境更多,因此该类方法具有更好的通用性。近年来,深度神经网络的一些方法在计算机视觉领域的几个问题上取得了最优效果。其中,双流算法(two stream)在几个标准动作数据集和手势数据集上获得了较好的识别效果,但是该方法仍旧需要较高的计算力支持并且对相似手势的辨别仍旧尚存不足。
5.注意力机制能够增强深度神经网络对关键信息的学习,弥补双流算法对相似手势识别不足的问题。因此,本发明考虑对双流算法进行改进,建立一种较为通用的基于深度神经网络和注意力机制的手势识别模型。
技术实现要素:
6.为了解决传统手势识别方法所需设备昂贵、交互场景受限、计算量大的问题,本发明考虑结合有效通道注意力算法(efficient channel attention,eca)和单阶段目标检测算法(single shot multibox detector,ssd)改进双流算法,进而建立一种较为通用的基于视觉的手势识别模型。另外,通过网络传输协议把移动端或其它客户端拍摄到的手势视频数据发送给配有该模型的远程服务器即可获取对应的手势分类。
7.本发明的主要内容包括如下三个方面:
8.(1)建立了一种较为通用的动态手势识别模型。首先,设计利用eca注意力为双流算法的输入数据(手势帧集合和光流帧集合)赋予不同的初始权重;其次,选用ssd目标检测技术从权重最高的手势帧中提取手部姿态特征;最后,将手部姿态特征与双流算法提取的人体姿态特征、手势时序特征融合,进而分类不同手势;
9.(2)对手势识别算法的时效性做出改进。改进双流算法的光流提取技术和特征提
取网络架构,进而提升整体的手势识别速度;
10.(3)对比分析不同特征融合策略的手势识别效果。通过实验证明三维卷积和三维池化的特征融合方式具有更好的手势识别效果。
11.发明效果
12.本发明的效果可以应用于一般的手势识别场景。例如,可以在一些特定的服务器环境中搭建该手势识别模型并且为普通用户提供离线使用该功能的移动端软件,这样就可以在一些社交场景中帮助普通用户理解聋哑人士的简单手势动作含义。
13.发明难点
14.本发明主要有如下两个难点:
15.(1)如何对识别算法的时效性做出改进。一个手势视频的识别速度应该满足实时性的要求并且在用户的正常接受范围之内。本发明使用的双流算法需要较高的计算力支持、手势识别速度较慢。因此,难点一在于如何提高该方法的特征提取速度,进而保证整体手势识别方法的时效性。
16.(2)如何对多种手势特征进行有效融合。本发明设计利用ssd从手势关键帧中提取手部姿态特征用来增强双流算法对相似手势的识别效果。因此,难点二在于如何有效地融合ssd和双流算法提取的各类手势特征,进而保证整体手势识别的准确率。
附图说明
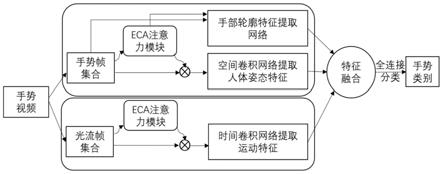
17.图1为本发明设计方法的整体架构图。
18.图2为本发明设计方法的整体流程图。
19.图3为本发明使用双流算法的结构示意图。
20.图4为eca注意力模块的结构示意图。
21.图5为本发明设计的特征融合结构示意图。
22.图6为ssd目标检测算法的结构示意图。
23.本发明核心算法
24.动态手势表达过程中的空间特征主要包括:人体姿态特征、手部姿态特征,而时序特征可利用相邻视频帧之间的光流位移场向量表示。因此,本发明首先设计利用双流算法从手势帧和光流帧集合中提取人体姿态特征、手势时序特征;其次,设计利用eca为手势帧和光流帧赋予初始权重;最后,设计利用ssd从初始权重最高的手势帧中提取手部姿态特征(增强双流算法对相似手势的识别效果)。
25.本方法的整体架构和算法流程分别如图1、图2所示,以下将依次介绍该方法中涉及到的核心算法。
26.(1)利用双流算法提取动态手势的人体姿态特征、手势时序特征
27.a)人体姿态特征提取
28.本方法使用的双流算法架构如图3所示。对于一个输入宽为w、高为h的手势视频,首先按照该视频的开始时间和结束时间从中平均选取t帧手势图x
τ
,x
2τ
…
x
tτ
,将其堆叠作为双流算法中空间卷积网络的输入,用来提取动态手势的人体姿态特征g。其中,x
τ
,x
2τ
…
x
tτ
表示选取的手势帧集合,下标τ表示每选取两帧手势图之间相隔的帧数。
29.原有双流算法中的空间卷积网络使用开源的vgg16实现,由于最新提出的
mobilenet v3特征提取网络具有更好的特征检测效果,因此本发明改用开源的mobilenet v3实现(实现细节参见具体实施步骤一)。
30.b)手势时序特征提取
31.手势的浅层时序特征可利用相邻视频帧之间的光流位移场向量表示。原有双流算法使用tvl1技术提取光流,为了提高手势的识别速度,本发明改用开源的denseflow方法提取光流。
32.光流是相邻视频帧中所有像素点位移矢量信息的一种表示,其中第t和第t+1连续视频帧之间的位移矢量信息可定义为d
t
,而d
t
的水平分量和垂直分量则分别表示手势在相邻视频帧中沿水平和垂直方向的运动轨迹。
33.为了从光流数据中获取更深层次的手势运动变化规律,本发明参考原有双流算法设计:针对选取手势帧集合x
τ
,x
2τ
…
x
tτ
中的每一帧,将其左右邻域内的光流图叠加,并将叠加后的光流图作为双流算法时间卷积网络(使用开源的mobilenet v3特征提取网络实现)的输入,用来提取动态手势的时序特征s。其中,每个手势帧获取光流的左右视频帧邻域数本发明设置为5,实现细节参见具体实施步骤一。
34.(2)利用eca注意力为手势帧和光流帧集合赋予初始权重
35.原有的双流算法使用均匀分布为手势帧和光流帧生成随机的初始权重。动态手势的表达是一个时序过程,注重手势表达过程中易于区分的关键性姿态更能增强手势的识别效果。因此,本发明设计在双流算法的数据输入层后面引入开源的eca注意力模块为手势帧和光流帧集合赋予初始权重,进而提升手势关键帧(具有标志性人体姿态和手部姿态的视频帧)的学习。
36.eca模块的结构如图4所示:该方法首先使用全局平局池化操作将每个通道的特征图映射为单一变量;然后再使用大小为1
×
1、填充幅度为k
‑
1的一维卷积操作求取变量间的线性映射关系(本发明设置k为5);最后再使用sigmoid激活函数得到每个特征图通道的初始权重,如式(1)所示:
[0037][0038]
其中,c表示需要加权的特征图通道集合,c
i
表示c中的第i层特征图通道,函数gap(
·
)表示全局平均池化操作,l
i
表示特征图通道c
i
全局平均池化后的单一变量,表示第i个变量1
×
1卷积内的第j个变量(α
j
表示该变量的系数),σ表示sigmoid激活函数,w
i
表示特征图通道c
i
对应的初始权重。
[0039]
至此,识别动态手势关键帧的注意力模块已建立。将输入双流算法中的手势帧与光流帧集合在通道维度上进行堆叠,则每个手势帧和光流帧都可以看作一个特征图通道;然后再将手势帧集合和光流帧集合分别代入到公式(1)中的c,则可求对应通道的初始权重,进而增强手势关键帧的学习。
[0040]
(3)利用ssd从初始权重最高的手势帧中提取手部姿态特征
[0041]
由于手势表达过程中一些特定的手部形态可以帮助区分不同手势,因此本发明设计利用开源的ssd目标检测技术从初始权重最高的手势帧中提取手部姿态特征o,用来增强
双流算法对相似手势的识别效果(ssd的实现方法参见具体实施步骤二)。
[0042]
这里只从关键帧中提取手部姿态特征的考虑是:手势表达的初始阶段和结束阶段包含信息不多,如果对每一帧的手势都提取手部姿态特征,作用性不强也增加计算复杂度,因此本发明设计只提取关键帧中的手部姿态特征。
[0043]
其中,手部姿态特征o共包含o
left
、o
right
两部分,分别表示关键帧中左右手预测为不同手部姿态类型的置信度集合。例如,表示左手属于第i类手部姿态的置信度,o
left
、o
right
中置信度最高的即为对应的左右手类别。在此基础上,将左右手姿态特征o与双流算法中提取的人体姿态特征g和手势时序特征s融合即可构成最终的手势时空上下文特征f。
[0044]
(4)特征融合及手势分类
[0045]
双流算法提取的人体姿态特征g和手势时序特征s具有像素级的对应关系。以刷牙和梳头两个动作为例,如果一只手在某个空间位置周期性地移动,那么时间卷积网络就能识别其运动轨迹,而空间卷积网络就可以识别其形态(牙齿或毛发),将其组合就可以辨别动作。因此,本发明首先在通道维度上堆叠特征g、s用来满足特征图层的像素级对应关系;然后使用三维卷积(三维卷积核大小设置为3*3*3)和三维池化(池化大小设置为2*2*2,最大池化)进一步融合特征g、s;最后设计在全连接层拼接手部姿态特征o,如式(2)所示:
[0046][0047]
其中,表示向量拼接或通道堆叠,ψ(
·
)表示对变量进行三维卷积和三维池化,r(
·
)表示将变量转换为一维向量。最后,特征f通过全连接层即可计算当前视频属于每一类手势的预测概率,预测概率最大的即为最终的手势类型。特征融合结构的示意图如图5所示。
具体实施方式
[0048]
本发明的具体实施分为以下四步:
[0049]
1)数据加载及双流算法实现
[0050]
2)ssd手部姿态检测网络实现
[0051]
3)在公开数据集进行整体训练
[0052]
4)实验结果分析
[0053]
(1)数据加载及双流网络实现
[0054]
本方法设置从手势视频数据中平均选取3个视频帧作为双流算法空间卷积网络的输入,然后又分别从这3个视频帧左右各5个邻域帧中提取光流数据作为双流算法时间卷积网络的输入。另外,为加强手势识别方法的泛化性,本方法对手势帧进行随机剪裁,每个手势帧都需要预先剪裁到512
×
512的分辨率大小。
[0055]
原有双流算法的空间卷积网络和时间卷积网络均采用开源的vgg16特征提取网络实现。由于最新提出的mobilenet v3特征提取网络具有更高的时效性和特征提取速度,因此本发明改用开源的mobilenet v3实现双流算法,另外光流提取技术也改用denseflow方法实现。
[0056]
目前也已有开源的denseflow方法实现,并且可以作为一种工具直接在服务器环境中利用opencv计算机视觉库进行编译安装。
[0057]
(2)ssd手部姿态检测网络训练
[0058]
本方法使用ssd从手势关键帧中提取手部姿态特征。具体实施分为以下三个小步骤:
[0059]
a)设置多个尺度的特征图层
[0060]
原有ssd目标检测算法的基础网络架构使用vgg16实现,为加快手势的识别速度,本发明改用mobilenet v3方法实现,如图6所示。另外,本发明参考原有ssd算法设计,在mobilenet v3后面拼接了4个不同尺度的特征图层,作用是可以从视频图片中检测出具有不同规模大小的用户手部姿态。
[0061]
b)设置多个默认候选框,预测每个候选框中的手部姿态类型
[0062]
为有效的标中手部区域,本发明参考原有的ssd算法,在拼接的4个不同尺度特征图层的每个单元处都设置了5个默认候选框,然后使用多个卷积过滤器预测每个候选框中的手部姿态类型。
[0063]
具体来说,若一个特征图层的大小为m
×
n
×
c(m表示特征图层的宽,n表示特征图层的高,c表示特征图层的通道数),那么当前特征图层共包含m
×
n
×
5个候选框。其中,每一个候选框都需要预测距离手部中心坐标的偏移量(利用候选框左上角、右下角两个顶点坐标表示,一共需要计算四个偏移量)以及手部姿态类型。因此,可以利用m
×
n
×5×
(p
hand
+4)个卷积过滤器预测当前特征图层中每一个候选框的预测结果。其中,p
hand
表示手部姿态类型个数。(本发明设置该卷积过滤器的大小为3
×3×
c)。
[0064]
c)利用非极大值抑制算法得到最终的手部姿态类型
[0065]
本发明参考原有ssd算法思想,使用非极大值抑制算法(non
‑
maximum suppression,nms)设置重叠度(intersection over union,iou)阈值用来过滤识别效果不好的手部检测框,进而得到最终的手部姿态类型检测结果(本方法设置重叠度阈值为0.5)。
[0066]
(3)在公开数据集进行整体训练
[0067]
本发明选择公开的chalearn2013意大利手势数据集进行训练。该数据集使用kinect传感器以每秒20帧的速度记录了27个用户在不同背景下的手势词汇表达,其中共包含20个手势分类,每个手势的时长在50帧左右,并提供rgb、rgb
‑
d、骨架、用户轮廓多种模态信息。另外,该数据集共计13858个视频样本,其中训练集7754个、验证集3362个、测试集2742个。本发明仅使用该数据集的rgb模态数据与其它仅使用rgb信息的动态手势识别方法进行对比。
[0068]
(4)实验结果分析
[0069]
本发明参考chalearn2013意大利手势数据集规定,使用编辑距离(levenshtein distance)作为实验效果的评价标准。其中,耦合隐式马尔科夫算法(coupled hidden markov model,chmm)仅使用rgb视频信息在该数据集上获得了之前的最佳手势识别效果,实验准确率为60.07%。本发明的实验准确率为66.23%,相较之前的算法有了有效改进,并且比原有的双流算法提升了1.66%的识别准确率。
[0070]
另外,在处理器为intel xeon es、显卡为nvidia titan x的服务器环境中,ssd目标检测算法识别关键帧中的手部姿态特征约耗时50ms,相邻两帧之间的光流计算约耗时11ms,识别一个手势的总体延迟时间在200ms以内,因此本方法可基本满足手势识别的实时性需求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1