基于机器学习的大米品种快速识别方法
本发明属于食品检测技术领域,尤其涉及一种基于机器学习的大米品种快速识别方法。
背景技术:
在亚洲地区,人们主要以大米为主食。我国是稻谷生产大国,稻米产量居世界首位。国内将大米分为3类:籼米、粳米和糯米。籼米的米粒细而长,较长的达到7毫米以上,由籼型非糯性稻谷制成,蒸煮后粘性较小,出饭率高;粳米与之相反,米粒一般圆而短,由粳型非糯性稻谷碾制而成,蒸煮后粘性较大,出饭率低;糯米为人们所熟知,每逢节日制作粽子、汤圆或是各式各样的糕点常需要用到它。当前,大米市场行业的发展虽然总体上趋好,但也面临以下问题:大米品种鉴别方法不够完善,从而导致一些不法商家将品种混卖去谋取高额利益。这不仅扰乱了大米市场秩序,还使得消费者的利益遭受到了损失。因此,有效鉴别大米品种对维护消费者权益、保障合理市场秩序以及降低食品安全隐患具有重要意义。
综上所述,为了拓展大米品种检测在食品领域中的应用,急需开发一种快速、简单的便于现场实时检测大米品种的方法。
技术实现要素:
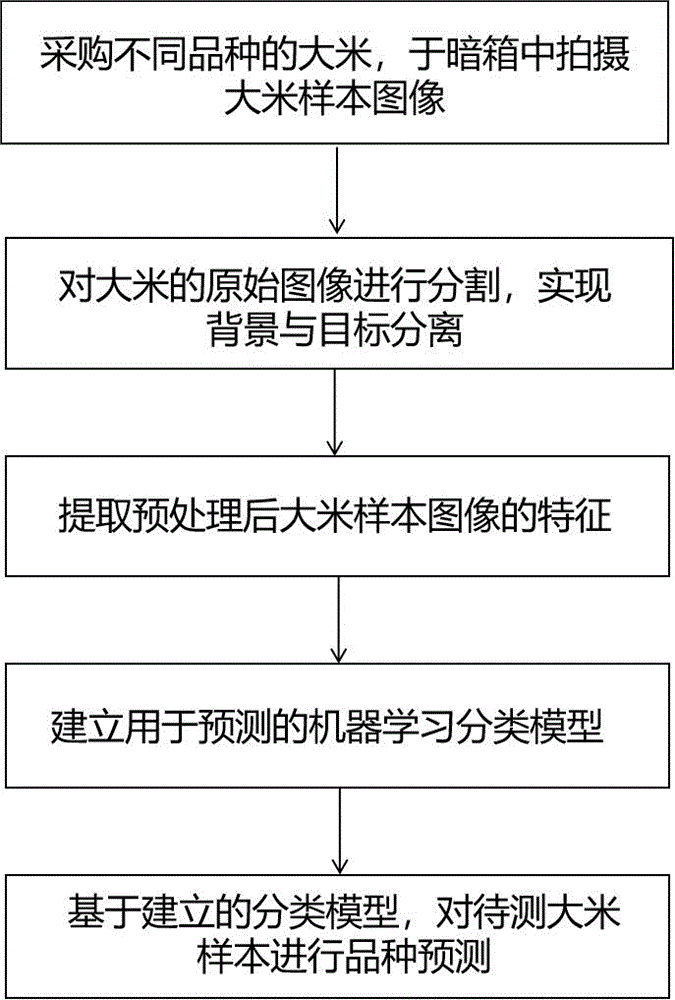
针对现有技术的空白,本发明提出了一种基于机器学习的大米品种快速识别方法,采用不同品种的大米,作为实验样本;将不同品种的大米置于暗箱中拍照,作为原始数据集;对大米的原始图像进行分割,实现背景与目标分离;提取预处理后大米样本图像的特征;基于所获得的特征信息,以此建立用于预测大米品种的机器学习分类模型;基于所建立的分类模型,对待测大米样本进行品种识别。该方法有利于简单、快捷地检测出大米的品种。
本发明具体采用以下技术方案:
一种基于机器学习的大米品种快速识别方法,其特征在于:采用不同品种的大米样本图像作为数据集训练大米品种的机器学习分类模型;并通过训练获得的分类模型进行大米品种快速识别。
进一步地,包括以下步骤:
步骤s1:选择不同品种的大米作为样本;
步骤s2:将不同品种的大米置于暗箱中拍照,将获取的图像作为原始数据集;
步骤s3:对大米的原始图像进行分割,实现背景与目标分离;
步骤s4:提取预处理后大米样本图像的特征;
步骤s5:基于步骤s4获得的特征信息,以此建立用于预测大米品种的机器学习分类模型;
步骤s6:基于步骤s5建立的分类模型,对待测大米样本进行品种识别。
进一步地,在步骤s2中,以培养皿作为载物台,将大米摊平后进行拍摄。
进一步地,在步骤s3中,基于直方图对大米图像进行分割,以实现背景与目标分离。
进一步地,在步骤s4中,基于卷积神经网络中的卷积核进行卷积运算实现不同品种大米图像的特征提取。
进一步地,在步骤s5中,建立的机器学习分类模型为:高斯朴素贝叶斯模型或k近邻学习模型或线性判别分析模型或随机森林模型。
进一步地,在步骤s5中,建立的机器学习分类模型为支持向量机模型。
进一步地,在步骤s6中,对待测大米样品进行品种识别的过程为:
取待测大米样本,用培养皿盛装并摊平,置于暗箱中拍摄照片,将照片进行分割与特征提取,最后将大米的特征信息输入训练好的svm模型,svm模型预测出该待测大米样本属于哪个品种,并将其作为输出。
相较于现有技术,本发明及其优选方案具有以下有益效果:通过在暗箱中拍摄不同品种的大米样本图像,作为原始数据集,以此构建了五种机器学习分类模型(gnb、knn、lda、rf、及svm),模型能有效识别出大米品种。该方法简单、快捷,可以显著提升检测效率,为简化大米品种识别提供了新的方法,具有很强的实用性和广阔的应用前景。其解决了机器学习方法在大米品种识别的应用的问题。
附图说明
下面结合附图和具体实施方式对本发明进一步详细的说明:
图1是本发明实施例的方法实现流程图。
图2是本发明实施例中大米样本的原始图像。
图3是本发明实施例中大米样本的分割图像。
图4是本发明实施例中建立的主成分分析(pca)模型测试结果示意图。
图5是本发明实施例中建立的gnb模型测试结果示意图。
图6是本发明实施例中建立的knn模型测试结果示意图。
图7是本发明实施例中建立的lda模型测试结果示意图。
图8是本发明实施例中建立的rf模型测试结果示意图。
图9是本发明实施例中建立的svm模型测试结果示意图。
具体实施方式
为让本专利的特征和优点能更明显易懂,下文特举实施例,作详细说明如下:
本实施例提供了一种基于机器学习的大米品种快速识别方法,如图1所示,包括以下步骤:
(1)于超市购得不同品种的大米,作为实验样本。
在本实施例中,所购大米包括粳米、糯米及籼米,其中粳米:东北米和田趣长粒香,糯米:长糯米和圆糯米,籼米:福粥米、金针银粘米、月牙米、软丁优米、国泰香米及泰国茉莉香米,共计10个品种。
(2)将不同品种的大米置于暗箱中拍照,作为原始数据集。
在本实施例中,用培养皿作为载物台,每次将大米摊平后即可进行拍摄。
(3)对大米的原始图像进行分割,实现背景与目标分离。
在本实施例中,基于直方图对大米图像进行分割,最终实现背景与目标分离。
(4)提取预处理后大米样本图像的特征。
在本实施例中,基于cnn中的卷积核进行卷积运算来实现不同品种大米图像的特征提取。它涵盖了大米样本图像的所有特征信息,包括颜色、大小、纹理、形状等特征。
(5)基于步骤(4)获得特征信息,以此建立用于预测大米品种的机器学习分类模型。
在本实施例中,建立的机器学习分类模型为:gnb、knn、lda、rf、及svm;所述分类模型中,gnb在测试集上识别的准确率为81.00%,knn在测试集上识别的准确率为85.33%,lda在测试集上识别的准确率为92.67%,rf在测试集上识别的准确率为93.33%,svm在测试集上识别的准确率为96.67%,结果表明,svm模型表现最好。
(6)基于建立的机器学习分类模型,对待测大米样本进行品种预测。具体方法为:
取待测大米样本少许,用培养皿盛装并摊平,置于暗箱中拍摄照片,将照片导入预先编写好的程序中,程序会自动对图像进行分割与特征提取,最后将大米的特征信息输入训练好的svm模型,svm模型会预测出该待测大米样本属于哪个品种,并将其作为输出。
下面以具体实施例对本发明作进一步说明。
1、如图2所示为不同品种大米的原始图像,每个品种拍摄150张,总样本量150×10=1500张,拍摄完成后及时将照片导入计算机,运用matlab2019b编写程序进行后续的建模分析。
2、基于直方图对大米样本图像进行分割,分割效果如图3所示。
3、基于cnn中的卷积核进行卷积运算来实现不同品种大米图像的特征提取。它涵盖了大米样本图像的所有特征信息,包括颜色、大小、纹理、形状等特征。
4、将数据集(1500张照片)按8:2随机划分为训练集和测试集,1200张用于训练模型,剩余300张用于评估模型。
5、如图4所示为10个品种(共1500个样本)大米样本图像的pca投影图,从图中可以看出,同一品种的大米样本出现良好的聚集现象,表明不同品种的大米间存在着差异,但图中所示差异并不十分明显,需进一步构建机器学习分类模型进行分析。
6、如图5所示为gnb模型的混淆矩阵图。横坐标为预测标签,纵坐标为真实标签。从图中可以看出,东北米:8个样本误判成田趣长粒香;福粥米:10个样本误判成金针银粘米;国泰香米:1个样本误判成金针银粘米,3个样本误判成软丁优米,1个样本误判成月牙米;金针银粘米:6个样本误判成福粥米,1个样本误判成软丁优米;软丁优米:1个样本误判成福粥米,8个样本误判成国泰香米,1个样本误判成金针银粘米,2个样本误判成泰国茉莉香米;长糯米:没有误判;泰国茉莉香米:2个样本误判成金针银粘米,3个样本误判成软丁优米;田趣长粒香:1个样本误判成东北米;圆糯米:没有误判;月牙米:5个样本误判成国泰香米,4个样本误判成软丁优米。
7、如图6所示为knn模型的混淆矩阵图。横坐标为预测标签,纵坐标为真实标签。从图中可以看出,东北米:1个样本误判成田趣长粒香;福粥米:1个样本误判成国泰香米,1个样本误判成金针银粘米,1个样本误判成泰国茉莉香米,1个样本误判成月牙米;国泰香米:5个样本误判成软丁优米,2个样本误判成田趣长粒香;金针银粘米:2个样本误判成福粥米;软丁优米:10个样本误判成国泰香米,1个样本误判成金针银粘米;长糯米:没有误判;泰国茉莉香米:4个样本误判成软丁优米;田趣长粒香:3个样本误判成东北米;圆糯米:没有误判;月牙米:1个样本误判成福粥米,2个样本误判成国泰香米,7个样本误判成软丁优米。
8、如图7所示为lda模型的混淆矩阵图。横坐标为预测标签,纵坐标为真实标签。从图中可以看出,东北米:没有误判;福粥米:1个样本误判成软丁优米,1个样本误判成泰国茉莉香米;国泰香米:3个样本误判成软丁优米;金针银粘米:3个样本误判成福粥米;软丁优米:1个样本误判成福粥米,3个样本误判成国泰香米,1个样本误判成金针银粘米;长糯米:没有误判;泰国茉莉香米:2个样本误判成软丁优米;田趣长粒香:1个样本误判成东北米,1个样本误判成月牙米;圆糯米:没有误判;月牙米:2个样本误判成软丁优米。
9、如图8所示为rf模型的混淆矩阵图。横坐标为预测标签,纵坐标为真实标签。从图中可以看出,东北米:1个样本误判成田趣长粒香;福粥米:1个样本误判成国泰香米,3个样本误判成金针银粘米;国泰香米:没有误判;金针银粘米:2个样本误判成国泰香米,1个样本误判成软丁优米;软丁优米:1个样本误判成福粥米,3个样本误判成国泰香米,1个样本误判成金针银粘米;长糯米:没有误判;泰国茉莉香米:2个样本误判成福粥米,1个样本误判成软丁优米;田趣长粒香:1个样本误判成东北米,1个样本误判成国泰香米;圆糯米:没有误判;月牙米:2个样本误判成软丁优米。
10、如图9所示为svm模型的混淆矩阵图。横坐标为预测标签,纵坐标为真实标签。从图中可以看出,东北米:1个样本误判成田趣长粒香;福粥米:1个样本误判成金针银粘米;国泰香米:没有误判;金针银粘米:没有误判;软丁优米:2个样本误判成福粥米,2个样本误判成国泰香米;长糯米:没有误判;泰国茉莉香米:没有误判;田趣长粒香:1个样本误判成东北米;圆糯米:没有误判;月牙米:1个样本误判成福粥米,2个样本误判成软丁优米。
最后,就可以用得到的机器学习分类模型对未知大米样本图像进行品种预测了。
专利不局限于上述最佳实施方式,任何人在本专利的启示下都可以得出其它各种形式的基于机器学习的大米品种快速识别方法,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本专利的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!