基于分割和图卷积神经网络的表格图像跨模态信息提取方法
本发明涉及的是一种图像处理领域的技术,具体是一种基于分割和图卷积神经网络的表格图像跨模态信息提取方法。
背景技术:
表格识别在很多领域都是一个很常见的工作,目前存在许多对表格进行识别的方法包括:使用基于预定义布局的方法,使用基于规则的方法以及利用通过离线训练获得模型的统计方法后将估计的参数用于实际表提取,但这些现有技术缺点包括:不能包涵所有的表格类型,而且需要人为指定表格类型;在金融业等许多领域,表格往往是以非结构化的数字文件公开的,如pdf和图片格式,这些文件难以直接进行人工提取和处理。因此现阶段急需能够自动提取表格信息的方法。
技术实现要素:
本发明针对现有技术在面对无边框表格的使用情景时性能表现会进一步下降的不足,提出一种基于分割和图卷积神经网络模型的表格图像跨模态信息提取方法,收集整理金融场景中经常使用的无边框表格作为训练数据集,提出了新的利用多模态信息进行表格识别的方法,开发了相应模型,提高了对表格特别是对无边框表格的识别准确率。
本发明是通过以下技术方案实现的:
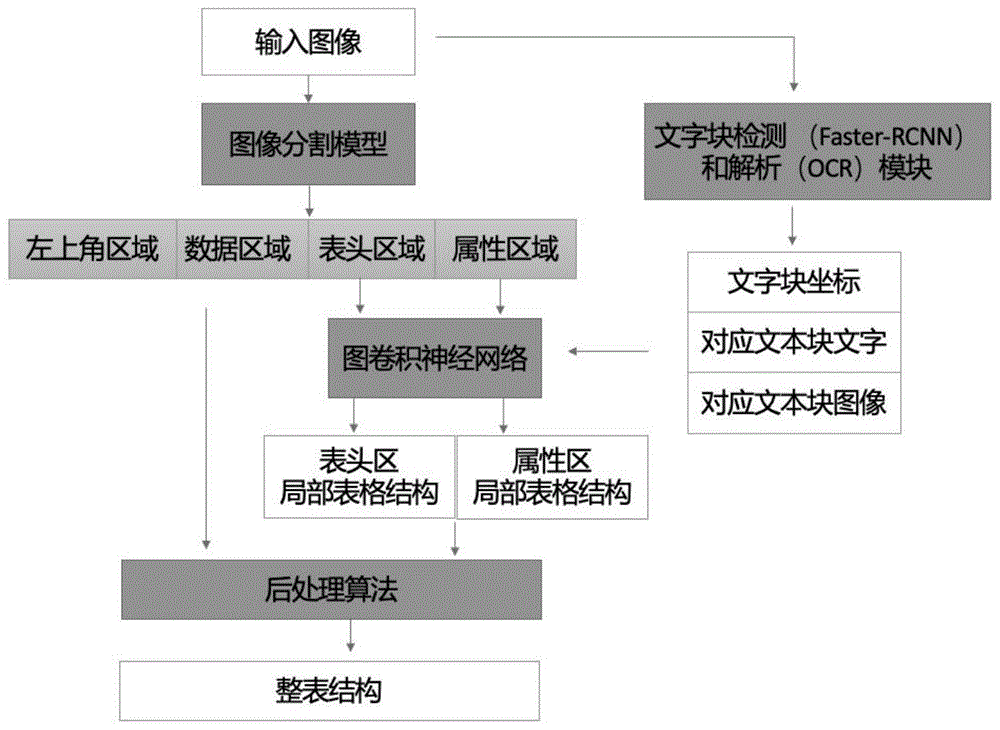
本发明涉及一种基于分割和图卷积神经网络模型的表格图像跨模态信息提取方法,包括以下步骤:
步骤一、使用深度学习目标检测方法,获得表格中各个节点的定位角点坐标,并使用得到的角点坐标以及ocr接口获得表格各个节点中的文字信息;
所述的深度学习目标检测方法是指:通过faster-rcnn模型得到每个表格节点的文本块位置(roi),然后使用ocr对相应位置进行解析,得到对应文本块的文字。
步骤二、使用图像分割模型,根据表格图像的特征,对表格的表头区域(header)、属性区域(attribute)、数据区域(data)和左上角区域(corner)进行功能区域划分;
所述的图像分割模型采用卷积神经网络模型(cnn)回归得到表格四个部分的水平和垂直分割线交点,该cnn模型包括三层卷积-池化层,其中:卷积层的卷积核大小均为3x3,激活函数均采用relu函数;池化层都采用max_pooling,隐藏层通道大小都为64,最后回归得到交点的x和y坐标占图像高度和高度的比例。
步骤三、对表头和属性区域的节点,利用各个节点的文本、坐标、图像等多模态信息特征,通过图卷积深度模型(gcn)推测节点间的边关系,提取出表格节点间的拓扑关系;
所述的拓扑关系是指:表格各单元格节点之间的连接关系,即各节点之间是同行、同列或不同行不同列的关系。利用图卷积深度模型(gcn)预测节点间的边关系,使表格节点的拓扑结构从全连接状态变为能确定表格结构的拓扑关系。
所述的图卷积深度模型(gcn)根据输入的文本位置、文本内容、节点局部图像、整表全局图像的多模态信息特征,经过图节点的卷积计算,预测出用于重建出表的结构的各节点间的边关系(同行、同列、不同行不同列)。
步骤四、通过拓扑关系还原出表头以及属性区域的图模型结构;分别根据表头和属性区域图结构最下一层的节点数目获得数据区的行数和列数,并使用数据区节点对表格数据区域的进行填充;
步骤五、根据表头与属性区域的节点图结构以及表格区域的重建结果,对整个表格的结构进行重建。
本发明涉及一种实现上述方法的系统,包括:图像分割单元、文字块检测单元、图卷积网络单元和后处理单元,其中:文字解析和检测模块由图像得到文字块坐标和对应的文字信息;图像分割单元根据表格图像划分表格;图卷积神经网络模块预测表格的表头区域和属性区域的结构;后处理模块根据图神经网络预测的结果和数据区域文字块的坐标信息重建整张表格的结构。
技术效果
本发明整体解决了现有技术对复杂结构表格和对无边框表格解析效果差的不足;与现有技术相比,本发明只需要对表头和属性区域进行图结构构建,降低问题的复杂度,提高了模型预测的准确率,也减少了计算的开销。节点信息中嵌入了文本信息、节点坐标信息、节点图像等多模态信息,同时使用了整个表格的图像特征,提高了模型在无边框情况下的对表格结构的识别准确率。
附图说明
图1为本发明流程图;
图2为图卷积深度模型(gcn)示意图;
图3~图7为实施例操作过程示意图。
具体实施方式
如图1所示,为本实施例涉及一种基于图像分割和图卷积神经网络模型的表格图像跨模态信息提取方法,包括以下步骤:
步骤一、使用深度学习目标检测方法,获得表格中各个节点的定位角点坐标,并使用得到的角点坐标以及ocr接口获得表格各个节点中的文字信息,具体步骤包括:
1.1使用faster-rcnn模型对表格图像中的文字块进行提取,得到各个文字块的坐标(roi);
1.2利用faster-rcnn得到的各个文字块的坐标,使用ocr对文本块进行解析,得到对应文本块中的文本内容;
1.3将faster-rcnn得到的文本块坐标以及ocr得到的文本块内容保存在json文件中;
步骤二、使用卷积神经网络模型(cnn)对图像进行分割,根据表格图像的特征,对表格的表头(header)、属性栏(attribute)、数据(data)进行表格功能区域的划分,具体步骤包括:
2.1将表格图像输入cnn模型中,回归得到四个区域水平和垂直分割线交点的坐标;
2.2将分割线坐标保存在json文件中;
步骤三、对表头和属性栏区域的节点,利用各个节点的文本、坐标、图像等多模态信息特征,通过图卷积网络模型(gcn),提取出节点之间的拓扑关系,通过拓扑关系还原出表头区域和属性区域的图结构,具体步骤包括:
3.1读取步骤一和二中生成的json文件,分别将表头区域和属性区域的节点信息(文本坐标、文本块内容、文本块图像等)输入到图卷积模型(gcn)中,预测得到各节点之间的边关系(同行,同列,不同行不同列);
3.2根据模型预测的结果,利用节点间边关系,使用极大图算法,分别重建出表头区域和属性区域节点间的图结构;
步骤四、根据重建出的图结构,获得数据区域的行数和列数,然后使用数据区节点对表格数据区域的进行填充,具体步骤包括:
4.1根据步骤三中对表头区域和属性区域的重建结果,表头区域最下层节点个数作为数据区域行数,属性区域最下层节点个数作为数据区域列数;
4.2确定数据区域的行列数目之后,根据数据区域节点的坐标位置,确定节点所在的行列中的位置;
4.3如果存在数据区域节点不能找到其对应的行或列,则根据其坐标插入一行或者一列,相应地数据区域的行或列数目递增一;
步骤五、根据表头与属性区域的节点图结构,以及数据区域的重建结果,对表格的整体结构进行重建,具体步骤包括:
5.1根据步骤三中对表头区域和属性区域的重建结果,表头区域图结构的水平层数加上数据区域行数之和就是整个表格区域的总行数,属性区域图结构的竖直层数加上数据区域列数增整个表格的总列数;
5.2根据总的列数,对步骤三和四种的三个区域(表头区域、属性区域、数据区域)中节点的结构位置进行更新,然后加上左上角区域的节点,得到整个表格的结构;
5.3将得到的结构信息保存在json文件中,可以转化为html等格式使得表格结构能够可视化;
本方法在表格结构识别任务中加入图像分割模块,使得分割之后重建更加精细,局部的建模结果比整表一次性建模的结果准确率更高,问题的规模变小,也可以并行处理表头区域和属性区域的重建任务;在图卷积神经网络模型(gcn)中输入四种特征(文本位置、文本内容、节点局部图像、整表全局图像),公开的文献中相关模型没有使用全部这些特征,该技术提高了模型预测的准确率;
通过在ubuntu14.04+anaconda的开发环境,使用pytorch深度学习框架搭建的模型中,得到在自己整理数据集上重建后节点间边关系的预测准确率是98%;可见本方法表格节点之间预测准确率更高,表格重建的结果更好。
综上,本方法是一种端到端的表格结构识别技术,输入结构为表格的图像,输出结果为表格结构,不需要使用其他外部工具;本方法在对表格节点结构进行重建前,先对表格进行了区域划分,减少了重建的规模,降低了计算的开销,提高了准确度,而且经过表格功能区域划分后,相当于使用了先验知识,使得后续的图模型构建更准确;本方法中的图卷积模型(gcn)使用了节点的多模态特征(文本、坐标、图像等)和表格图像的整体特征,对无边框表格有较高的识别准确率。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!