基于分割图像特征提取的推荐方法
1.本发明属于服装推荐领域,尤其是涉及基于分割图像特征提取的服装推荐方法。
背景技术:
2.电子商务极大地促进了时尚产业和服装制造业,面对大量的商品信息,如何最快最准确地检索消费者感兴趣的产品成为了各大商品检索服务平台拉开差距的重要方面。因此也产生了高效个性化商品检索的巨大需求,其中服装商品信息受到研究者的广泛重视,大量的服装检索、服装匹配算法被提出。
3.服装推荐系统的信息常常是基于卖家给出的产品信息,然而这是带有欺诈风险的。消费者无法直接触摸衣物,有些企业为此夸大了衣物质量,影响了消费者对衣物质量的判断。监管者应当通过实体照片以及其它买家提供的照片反馈对商品信息进行更正,但这在海量数据面前是几乎无法完成的,当前成熟的图像处理技术可以解决这一需求,通过对服装的分别分析可以帮助对不实信息进行监控。
4.服装图像的分割由于遮挡复杂一直都是难题,相关的图像分割技术经过了fasterr
‑
cnn再到mask r
‑
cnn的发展,对图像的分割效果精度不断上升,hybrid taskcascade在精度上又实现了新突破。然而,现有的服装推荐方法依然面临着服装商品图像中包含多个服装难以针对性检索的问题,在图像噪声、复杂图像干扰下的精度受限。
技术实现要素:
5.本发明针对服装商品图像中包含多个服装难以针对性检索的问题,提出了一套自动辅助分割服装实例,分别做特征提取和服装推荐检索的方法,对于图像噪声、复杂的服装干扰下仍保持着出色的识别和分割能力,同时在推荐系统中能高效地对分割后的服装分别检索出相似的服装作推荐,去除了背景干扰实现效果的提升。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种基于分割图像特征提取的推荐方法,包括以下步骤:
8.(1)收集全身图像、图像中衣物的实体掩码、实体掩码对应的类型标签作为第一数据集,以及收集单品图像、描述标签作为第二数据集,所述的描述标签包括类型标签、质料标签、部件标签、形状标签、纹理标签;
9.(2)构建并训练基于混合任务级联式神经网络的服装分割分类模型,训练时采用第一数据集作为训练集;
10.(3)构建并训练基于残差网络的五个特征提取模型,训练时采用第二数据集作为训练集;
11.(4)对目标服装图像进行服装实体分割并提取特征,获得分割得到的目标单品服装图像特征;
12.(5)把单品服装图像数据集作为用于推荐的服装图像库,提取每件单品服装图像的特征;根据服装图像库中的单品服装图像的特征建立树结构,依据所分割得到的目标单
品服装图像特征,在服装图像库内获取相似服装图像作为推荐。
13.与现有技术相比,本发明的优势在于:
14.(1)本发明利用混合任务级联式神经网络的服装分割分类模型对图像中的单品服装进行分割,在分割后得到二维矩阵格式的掩码,从原始目标图像中提取出不包含背景信息的单品服装图像,对于图像噪声、复杂的服装干扰下具有出色的识别和分割能力。
15.(2)本发明对分割后的服装实例分别做特征提取和服装推荐检索,由于分割出的服装实例克服了背景干扰,显著提升了特征提取的效果;此外,本发明分别从类型、质料、部件、形状、纹理五个属性中提取特征,更加全面的特征信息保证了推荐的准确性。
16.(3)本发明在对比目标单品服装特征与推荐库中单品服装特征时,通过对用于推荐的单品服装图像特征建立树结构,在查找的时使用分割得到的目标单品服装图像特征遍历用于推荐的单品图像特征的森林,不断地对森林中树的中间结点的超平面信息做比较,确定这个节点是在这棵树的哪一个分支,最后到叶子节点确定推荐的单品服装图像集合,这种查找方式大大提升了在大量单品服装中查找推荐服装的速度。
附图说明
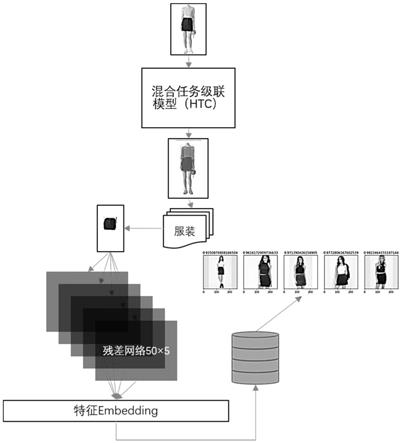
17.图1为该图像分割的服装推荐方法的整体流程示意图;
18.图2为基于图像分割的服装推荐方法的结果示意图。
具体实施方式
19.下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
20.如图1所示,一种基于分割图像特征提取的推荐方法,包括以下步骤:
21.s01,收集服装图像数据集作为训练集
22.(1.1)将imaterialist 2019服装数据集作为第一训练集,由时尚全身图像、图像中衣物的实体掩码、实体掩码对应的类型标签构成;在第一数据集中,训练数据属性包括图像编号、实体掩码、高度、宽度、分类编号。
23.将deepfashion(cuhk)服装数据集作为第二训练集,由单品图像和描述标签构成;所述的描述标签包括类型标签、质料标签、部件标签、形状标签、纹理标签。
24.本实施例中,由于imaterialist 2019服装数据集和deepfashion(cuhk)服装数据集中原有的标签过多,仅描述标签就有一千余个,为了均衡数据分布,提高模型的训练效果,以deepfashion(cuhk)服装数据集为例,删除了服装配件和面积较小的标签,服装类别被剪裁至33个类型属性,描述标签被剪裁后分别映射到质料fabric、部件 parts、形状shape、纹理texture四个属性中。
25.(1.2)对第一训练集进行预处理:针对第一训练集中的每一张图像,基于其实体掩码和高度,计算每一个掩码像素点,得到图像类型标签对应的掩码矩阵。
26.在本实施例的数据集中,服装的实体掩码以游程编码rle(run
‑
length encoding) 形式无损储存。实体掩码的游程编码先纵后横,像素被一索引并从上到下编号,然后从左到右编号:1是像素(1,1),2是像素(2,1),依此类推。从图片实体像素点(x, y)开始,然后存储其后的二值像素点的长度:“x1*height+y1 l1 x2*height+y2 l2x3*height+y3 l3
…
xi*
height+yi li”,其中,height为高度。
27.该数据结构表明:在(x1,y1)像素点后l1位,在(x2,y2)像素点后l2位,在(x3,y3)像素点后l3位皆为1,为实体区域。例如,”1 3 10 5”表示像素1,2, 3,10,11,12,13,14将被包括在掩码中。以此交替,存储实体掩码区域。在用于分割图像实体时,游程编码被转换为掩码矩阵。
28.具体的,将实体掩码转换为掩码矩阵的过程为:
29.针对某实体掩码“x1*height+y1 l1 x2*height+y2 l2 x3*height+y3l3
…
xi*height+yi li”和已知的高度值height,分别转储游程编码字符串为两列表[x1*height+y1,x2*height+y2,x3*height+y3
…
xi*height+yi]和[l1,l2,l3
…
li],这两列表分别为编码对的起始掩码值和对应的长度;然后两列表相加得到终止掩码值 [x1*height+y1+l1,x2*height+y2+l2,x3*height+y3+l3
…
xi*height+yi+li]。
[0030]
对掩码值xi*height+yi,除以height,商为xi,余数为yi,可得对应坐标位点(xi, yi)。新建与图像长度、宽度一致的二值矩阵,对起止坐标,即(xi,yi)到(xi,yi+li) 之间的点赋值,得到存储有该掩码所包含的所有像素位点的掩码矩阵。
[0031]
s02,构建并训练基于混合任务级联式神经网络的服装分割分类模型
[0032]
具体的,建立服装图像分割分类模型:本实施例采用基于混合任务级联式区域卷积神经网络hybrid task cascade(简称htc模型)。该模型通过建立渐进式细化的级联管道,在每个阶段,先执行边界框分支,再将回归过的边界框交由掩码分支预测掩码,语义分割的特征和原始的边界框/掩码分支融合,增强特定的前后关系。此外,在不同阶段的掩码分支之间引入直接连接,然后每个阶段的掩码特征将被嵌入并馈送到下一个阶段。最终输出所预测的服装实体掩码矩阵和对应的类型。
[0033]
将预处理后的第一训练集中的时尚全身图像作为htc模型的输入,得到预测的服装实体掩码矩阵;根据预测的服装实体掩码矩阵与实际计算得到的掩码矩阵之间的损失对htc模型进行训练,得到训练好的htc模型。
[0034]
在本发明的一项具体实施中,还包括对预处理后的第一训练集中的时尚全身图像进行albumentations增强图像的处理步骤,然后使用多尺度训练:在每次迭代中,从 [600,1200]中随机采样短边的比例,长边的比例固定为1900,batch_size为8。
[0035]
在本发明的一项具体实施中,所述的htc模型采用coco预训练后的模型,使用动量momentum为0.9、权重下降为0.0001的随机梯度下降。学习率在第10、18epoch 时分别减小9/10,使用4块nvidia v100模型训练48小时。
[0036]
s03,构建并训练基于残差网络的五个特征提取模型
[0037]
首先建立五个结构相同的resnet50模型,分别用于预测单品服装的类型、质料、部件、形状和纹理。
[0038]
具体的,将第二训练集中的单品图像和类型标签作为第一个resnet50模型的输入,根据预测得到的类型与实际类型标签作比较,对第一个resnet50模型进行训练;
[0039]
将第二训练集中的单品图像和质料标签作为第二个resnet50模型的输入,根据预测得到的质料与实际质料标签作比较,对第二个resnet50模型进行训练;
[0040]
以此类推,根据5种不同属性的标签分别训练得到一个相对应的resnet50模型。
[0041]
在本发明的一项具体实施中,训练过程中应用1
‑
cycle原则:将学习率从 lrmax/
divfactor逐步提高到lrmax,同时将模型学习动力从最大动量逐渐降低到最小动量。然后做相反的过程:将学习率从lrmax逐渐降低到lrmax/divfactor,与此同时,将动力从最小动量逐步提高到最大动量。进一步将学习率从lrmax/divfactor降低到lrmax/ (divfactor*100),并保持动量稳定在最大动量。学习速率逐步上升,直到动量下降到最小动量,学习速率开始下降,动量逐渐上升到最大动量。
[0042]
此外,使用f
β
数值作损失度量,计算预测结果和目标标签的误差损失,
[0043][0044]
其中β=2,即准确率和召回率在融合的时候,召回率的权重是准确率的2倍。在计算预测时使用0.1作为阈值参数。
[0045]
训练结束后得到五个模型文件。训练后的模型在实际使用时并不计算最终的分类结果,而是使用每一个模型中的全连接层输出的向量直接建立用于生成推荐的特征数据。
[0046]
s04,对目标服装图像进行服装实体分割并提取特征
[0047]
(4.1)将目标图像输入到步骤s02训练好的htc模型中,输出所预测的服装实体掩码矩阵;根据掩码矩阵从目标图像中分割出对应的目标单品服装图像;
[0048]
(4.2)把分割后的目标单品服装图像分别输入到步骤s03训练好的五个resnet50 模型中,通过pytorch的hook工具可以钩取每一个resnet50模型的全连接层的特征数据。
[0049]
(4.3)把由五个模型得到的全连接层的特征数据连接起来,得到大小为(2560,) 的embedding向量作为目标单品服装图像特征。
[0050]
s05,计算相似度进行推荐
[0051]
(5.1)把单品服装图像数据集作为用于推荐的服装图像库,对每件单品服装图像通过步骤s03中训练好的五个resnet50模型提取图像特征,该过程具体步骤与s04 相似,最终得到服装图像库中每张单品图像对应的大小为(2560,)的embedding向量作为用于推荐的单品服装图像特征。
[0052]
(5.2)根据用于推荐的单品服装图像特征建立树结构:
[0053]
该过程使用随机投影,创建多个点,执行k
‑
means聚类过程,确定点集聚类的两个质心,以它们为根节点建立分支,不断迭代构建一棵树。最后在树中的每个中间节点,都有一个随机超平面将空间分成两个子空间。通过从子空间中采样两个点并选择与它们等距的超平面来选择此超平面。使用聚类中心是为了让最终建立的树尽量平衡。
[0054]
在该过程中,通过遍历所有的节点,一边判定节点所属的分支,一边更新中心节点的位置,直到找到二聚类的中心,确定超平面,并在超平面划分的子空间继续这一过程,直到所有二叉树叶子节点都只包含小于k个向量,除了叶子结点以外的其它节点都记录着划分超平面的信息,得到用于推荐的单品图像特征的森林结构。因为建立树结构的限制,并不能保证这里检索到的是全局k近邻的;如果做全局k近邻则需要对全局进行遍历,在实际应用中使用精确度来换速度。
[0055]
最后,通过使用汉明距离(hamming distance)将森林结构处理成底层编码,通过计位查找函数可以大幅度提升速度。
[0056]
本实施例中,用上述方法做n=10次得到了一片包含10个二叉树的“森林”,其中 n可以通过精度和性能之间的权衡关系来调整。
[0057]
(5.3)依据所分割得到的目标单品服装图像特征,在推荐库内获取相似服装图像作为推荐:
[0058]
在查找的时候使用包含目标分割图像特征的embedding向量(分割得到的目标单品服装图像特征)遍历用于推荐的单品图像特征的森林,不断地对森林中树的中间结点的超平面信息做比较,确定这个节点是在这棵树的哪一个分支,最后到叶子节点确定推荐的单品服装图像集合。
[0059]
在建树划分超平面的过程中,可能出现两个非常近的点被划分到两个不同的子树上的情况,本实施例中可以采取在查找时访问尽量多次树的方法,一般默认是访问所需查询的最临近个数n
top
乘以树的数量n
tree
个树。在高维度和大量索引树的森林情况下,该过程会占用比较多时间,但其表现出色。如图2所示,为基于图像分割的服装推荐方法的结果示意图,对服装自动实体分割为pants和sweater两部分,对这两个目标单品分别做特征提取和服装推荐检索。对于图像噪声、复杂的服装干扰下仍保持着出色的识别和分割能力。
[0060]
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1